まえがき
序文がまだ必要なようです。 この命令を書く理由は2つあります。 1つ目は、全員に完全に再現可能な例を提供することです。 2つ目は、すでに発生した質問に答えることです。 これは、この問題の解決策に取り組むための私の方法に過ぎず、間違いなく唯一の方法ではなく、間違いなく最善の方法でもないことに留意してください。
必要条件
Python 3.x (データの受信と前処理)とR (実際には問題の解決)の両方を使用するので、両方をインストールするのが理にかなっています。 Rパッケージの要件は次のとおりです。
- MXNet このパッケージは、この記事で使用するモデル、実際には深い畳み込みニューラルネットワークを提供します。 GPUバージョンは必要ありません。このタスクにはCPUで十分ですが、動作は遅くなります。 この場合は、GPUバージョンを使用してください。
- EBImage このパッケージには、イメージを操作するための多くのツールが含まれています。 彼と一緒に画像を扱うことは喜びであり、ドキュメントは非常に明確で非常に簡単です。
Python 3.xの場合、 NumpyとScikit-learnの両方をインストールします 。 おそらく、 データ分析と機械学習のための事前にインストールされた多くの人気のあるパッケージがあるAnacondaディストリビューションもインストールする必要があります。
すべての作業が完了したら、開始できます。
データセット
Olivettiセットの顔を使用します。 このデータセットは、0〜256グレースケールの64 x 64ピクセルの画像のコレクションです。
データセットには、40人の画像が400枚含まれています。 10個のインスタンスでは、通常、各人に対して非制御アルゴリズムまたは半 制御アルゴリズムが使用されますが、特定の制御方法を試して使用します。
最初に、0から1のスケールで画像をスケーリングする必要があります。これは、データセットをロードするために使用する関数によって自動的に実行されます。 独自の画像を使用する場合は、0から1(または-1; 1)のスケールで事前にスケーリングしてください。 以下は、データセットをロードするために実行する必要があるPythonスクリプトです。 パスを値に変更して、IDEまたはターミナルから実行するだけです。
# -*- coding: utf-8 -*- # from sklearn.datasets import fetch_olivetti_faces import numpy as np # Olivetti olivetti = fetch_olivetti_faces() x = olivetti.images y = olivetti.target # print("Original x shape:", x.shape) X = x.reshape((400, 4096)) print("New x shape:", X.shape) print("y shape", y.shape) # numpy np.savetxt("C://olivetti_X.csv", X, delimiter = ",") np.savetxt("C://olivetti_y.csv", y, delimiter = ",", fmt = '%d') print("\nDownloading and reshaping done!") ################################################################################ # ################################################################################ # # Original x shape: (400, 64, 64) # New x shape: (400, 4096) # y shape (400,) # # Downloading and reshaping done!
実際、このコードは次のことを行います。データをロードし、Xの画像のサイズを変更し、numpy配列を.csvファイルに保存します。
x配列は、サイズ(400、64、64)のテンソル(テンソルは多次元マトリックスの美しい名前)です。これは、x配列に64 x 64マトリックスの400インスタンス(読み取りイメージ)が含まれることを意味します。 疑わしい場合は、単にテンソルの最初の要素を出力し、既に知っていることに基づいてデータ構造を把握してください。 たとえば、データセットの説明から、400のインスタンスがあることがわかります。各インスタンスは64 x 64ピクセルの画像です。 テンソルxをサイズ400 x 4096の行列に平滑化します。つまり、各64 x 64行列(画像)は、長さ4096の水平ベクトルに変換(平滑化)されます。
yに関しては、これはすでにサイズ400の垂直ベクトルです。変更する必要はありません。
結果の.csvファイルを見て、すべての変換が明確であることを確認します。
Rでの少しの前処理
次に、 EBImageを使用して画像を28 x 28ピクセルにサイズ変更し、トレーニングデータセットとテストデータセットを生成します。 画像のサイズを変更する理由を尋ねるかもしれません。 何らかの理由で、私のコンピューターは64 x 64ピクセルの画像が好きではなく、データを使用してモデルを実行するたびにエラーが発生します。 残念だ。 しかし、小さな写真でも良い結果が得られるため、これは許容範囲です(ただし、このような問題がなければ、もちろん64〜64ピクセルで実行できます)。 だから:
# 64 64 28 28 # rm(list=ls()) # EBImage require(EBImage) # X <- read.csv("olivetti_X.csv", header = F) labels <- read.csv("olivetti_y.csv", header = F) # rs_df <- data.frame() # : for(i in 1:nrow(X)) { # Try-catch result <- tryCatch({ # ( ) img <- as.numeric(X[i,]) # 64x64 ( EBImage) img <- Image(img, dim=c(64, 64), colormode = "Grayscale") # 28x28 img_resized <- resize(img, w = 28, h = 28) # ( , !) img_matrix <- img_resized@.Data # img_vector <- as.vector(t(img_matrix)) # label <- labels[i,] vec <- c(label, img_vector) # rs_df rbind rs_df <- rbind(rs_df, vec) # print(paste("Done",i,sep = " "))}, # ( ). ! error = function(e){print(e)}) } # . - , - . names(rs_df) <- c("label", paste("pixel", c(1:784))) # #------------------------------------------------------------------------------- # . . # set.seed(100) # df shuffled <- rs_df[sample(1:400),] # train_28 <- shuffled[1:360, ] test_28 <- shuffled[361:400, ] # write.csv(train_28, "C://train_28.csv", row.names = FALSE) write.csv(test_28, "C://test_28.csv", row.names = FALSE) # ! print("Done!")
出力がどのように見えるかわからない場合、この部分は十分に明確でなければなりません。rs_dfデータセットを見てください。 次のような400x785データセットである必要があります。
ラベル、pixel1、pixel2、...、pixel784
0、0.2、0.3、...、0.1
モデル構築
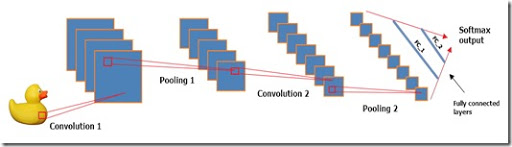
楽しい部分のために、モデルを作成しましょう。 以下は、モデルのトレーニングとテストに使用されたスクリプトです。 以下は、コードに対する私のコメントと説明です。
# rm(list=ls()) # MXNet require(mxnet) # #------------------------------------------------------------------------------- # train <- read.csv("train_28.csv") test <- read.csv("test_28.csv") # train <- data.matrix(train) train_x <- t(train[, -1]) train_y <- train[, 1] train_array <- train_x dim(train_array) <- c(28, 28, 1, ncol(train_x)) test_x <- t(test[, -1]) test_y <- test[, 1] test_array <- test_x dim(test_array) <- c(28, 28, 1, ncol(test_x)) # #------------------------------------------------------------------------------- data <- mx.symbol.Variable('data') # conv_1 <- mx.symbol.Convolution(data = data, kernel = c(5, 5), num_filter = 20) tanh_1 <- mx.symbol.Activation(data = conv_1, act_type = "tanh") pool_1 <- mx.symbol.Pooling(data = tanh_1, pool_type = "max", kernel = c(2, 2), stride = c(2, 2)) # conv_2 <- mx.symbol.Convolution(data = pool_1, kernel = c(5, 5), num_filter = 50) tanh_2 <- mx.symbol.Activation(data = conv_2, act_type = "tanh") pool_2 <- mx.symbol.Pooling(data=tanh_2, pool_type = "max", kernel = c(2, 2), stride = c(2, 2)) # flatten <- mx.symbol.Flatten(data = pool_2) fc_1 <- mx.symbol.FullyConnected(data = flatten, num_hidden = 500) tanh_3 <- mx.symbol.Activation(data = fc_1, act_type = "tanh") # fc_2 <- mx.symbol.FullyConnected(data = tanh_3, num_hidden = 40) # . , .. - . NN_model <- mx.symbol.SoftmaxOutput(data = fc_2) # #------------------------------------------------------------------------------- # mx.set.seed(100) # . CPU. devices <- mx.cpu() # #------------------------------------------------------------------------------- # model <- mx.model.FeedForward.create(NN_model, X = train_array, y = train_y, ctx = devices, num.round = 480, array.batch.size = 40, learning.rate = 0.01, momentum = 0.9, eval.metric = mx.metric.accuracy, epoch.end.callback = mx.callback.log.train.metric(100)) # #------------------------------------------------------------------------------- # predicted <- predict(model, test_array) # predicted_labels <- max.col(t(predicted)) - 1 # sum(diag(table(test[, 1], predicted_labels)))/40 ################################################################################ # ################################################################################ # # 0.975 #
トレーニングおよびテストデータセットを読み込んだ後、
data.matrix
関数を使用して各データセットを数値マトリックスに変換します。 データの最初の列は、各画像に関連付けられたラベルです。
train_array
および
test_array
からラベルを必ず削除してください。 ラベルと従属変数を分離した後、データを処理するようにMXNetに指示する必要があります。 次のコードを使用して19行目でこれを行います。トレーニングセットの場合は「dim(train_array)<-c(28、28、1、ncol(train_x))」、テストセットの場合は24行目です。 したがって、トレーニングデータは28x28サイズのncol(train_x)サンプル(360枚の写真)で構成されることをモデルに実際に伝えます。 数字の1は、画像がグレースケールであること、つまり、1つのチャンネルしかないことを示します。 画像がRGBの場合、1を3に置き換える必要があります。非常に多くのチャンネルに画像があります。
モデルの構造に関しては、これはLeNetモデルのバリエーションで、「Relu」(変換された線形ノード)の代わりに双曲線正接を活性化関数として使用します。
各畳み込み層は5x5コアを使用し、フィルターの固定セットに適用されます。 畳み込み層について学ぶには、 この素晴らしいビデオをご覧ください。 サブサンプリングレイヤーは、従来の「最大マージ」アプローチを使用します。
私のテストでは、 tanhはシグモイドやReluよりもはるかに優れていることが示されましたが、必要に応じて他のアクティベーション機能を試すことができます。
モデルのハイパーパラメーターについては、トレーニングのレベルは通常よりもわずかに高くなりますが、期間数は480でありながら正常に機能します。40のシリーズサイズも適切に機能します。 これらのハイパーパラメーターは試行錯誤によって取得されます。 重複するバンドで検索を行うことはできましたが、コードをやり直したくなかったため、実証済みの方法(試行錯誤)を使用しました。
最終的には、0.975の精度が得られます。
おわりに
一般に、このモデルの構成と実行は非常に簡単でした。 CPUで起動した場合、トレーニングには4〜5分かかります。実験する場合は少し長くなりますが、仕事には受け入れられます。
何らかの方法でデータパラメーターを操作せず、最も単純で最も一般的な前処理ステップのみを実行したという事実を考えると、得られた結果は非常に良いように思えます。 もちろん、より高い「真の」精度を達成するためには、さらに多くのクロスチェックを行う必要があります(必然的に多くの時間がかかります)。
読んでくれてありがとう、そしてこの記事がこの特定のモデルを設定して実行する方法を理解するのに役立つことを願っています。
データセットのソースは、AT&T Laboratories Cambridgeが作成したOlivettiフェイスパックです。