初期状態-私は民間の医療会社で実装とサポートサービスを管理していました。 単一システムで動作する、地域の支店の支店ネットワーク。 同様の機器がすべての施設で使用されています。 実際、すべての機器はシステムに接続され、データを提供します(透析機、実験室分析装置、超音波機器および心電計、重量および圧力計、水処理、換気システム、温度および湿度センサー)。
ブランチネットワークは常に拡大しています。 各部門にはITスペシャリストがいます。 このスペシャリストは、さまざまな分野で常に有能ではありません。 このタスクは、システムの実装の点から非常に複雑な可用性を確保するために非常に野心的でした。
問題
サポートの第1レベルの専門家によるインシデントの説明。 これは、誰もが彼が望んだように、彼が望んだように、できる限り最高の同じ間違いを説明したことを意味します。 また、インシデントを解決する時間を短縮したいと考えました。 特に、すでに発生して記述されているもの。 つまり、十分な速度と品質で、第1のサポートレベルでインシデントを最大限に閉鎖することが必要でした。
私は知識ベースを記述する既存の方法が好きではありません。 同じエラーがさまざまな理由で発生する可能性があるためです。 したがって、ソリューションの説明は複数にする必要があります。 本当にそうではない。 また、必要なステップ数という点では、ソリューション自体の検索にはかなり時間がかかります。 概して、通常、ナレッジベースはファイルのコレクションです。
ソリューションの説明の正確さも重要です。 「ベストプラクティス」の概念を考慮することが重要です。 例を挙げてください。 午前中に、事前構成されたセルフサービスポストが部分的に機能しなくなったとき-タッチスクリーンが機能しなくなったとき、ITスペシャリストは2時間5分かけてインシデントを解決しました。 私は特に、行動を観察して結果を見るために介入しませんでした。 その理由は、看護師がタッチスクリーンUSBケーブルをモップで少し拭いたためです。 アルゴリズムを使用して、この問題は最大5分以内に修正されました。
したがって、特定の大規模な問題を解決できるDSSに基づいた自動化ソリューションを利用したかったのです。 同時に、プラクティスをすべての部門に拡大します。 特に、新しく開設されたオフィスと新しいITプロフェッショナルに関連しています。 時間が経つにつれて、システムがより複雑になり、より多くの異なる機器がそれに接続されたためです。
私は、システムの利点を活用したかった-アルゴリズムのステップを記述するプロトコルの形成。 つまり、インシデントを均一に記述する方法の問題を解決するために-プロトコルをアプリケーションにコピーして貼り付けます。
実装
Algorithm Designerでは、アルゴリズムの主要な構造が作成されました。ここには、以下を説明するセクションが作成されました。
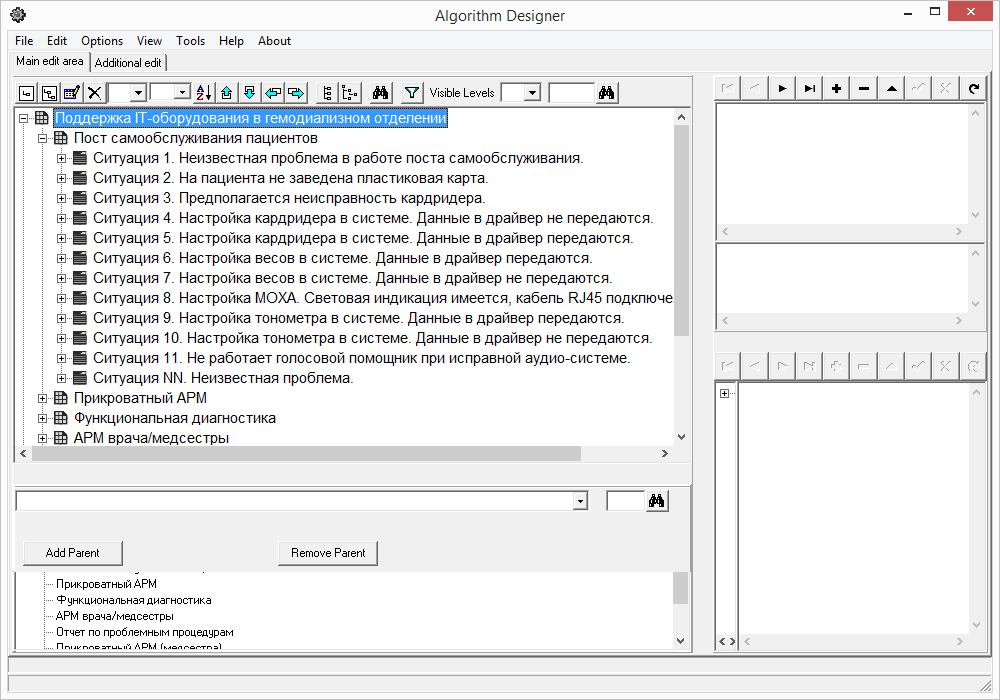
まず、患者のセルフケアポストが選択されました。 なぜなら、各シフトの開始時と終了時の患者がこの投稿を通過したからです。 また、セルフサービスポストで障害が発生すると、各シフトが遅れる可能性があります。
患者セルフサービスポスト:
•システムユニット
•タッチスクリーンで監視する
•スピーカー(音声アシスタントに使用)
•カードリーダー(患者の識別に使用)
•スケール
•圧力計
•プリンター
•音声シンセサイザー
•MaximusDriverプログラム。接続されているすべての機器を管理します。
•セルフサービスポストモードで動作するMaximusプログラム
天びんおよび血圧モニターはCOMポートを介してデータを送信するため、接続のバリエーションがありました。
•COMポート経由
•MOXAの使用
•USB-COMアダプター経由
したがって、これらの変動を考慮する必要がありました。 同様に、天秤座と血圧計のモデルも変更される可能性があります。
空き時間があったため、アルゴリズムは満杯になり、どのように機能するかが実現しました。 インシデントの直後にいくつかの決定が下され、インシデントが解決されました。
最初の状況は、問題を特定することを可能にしました。
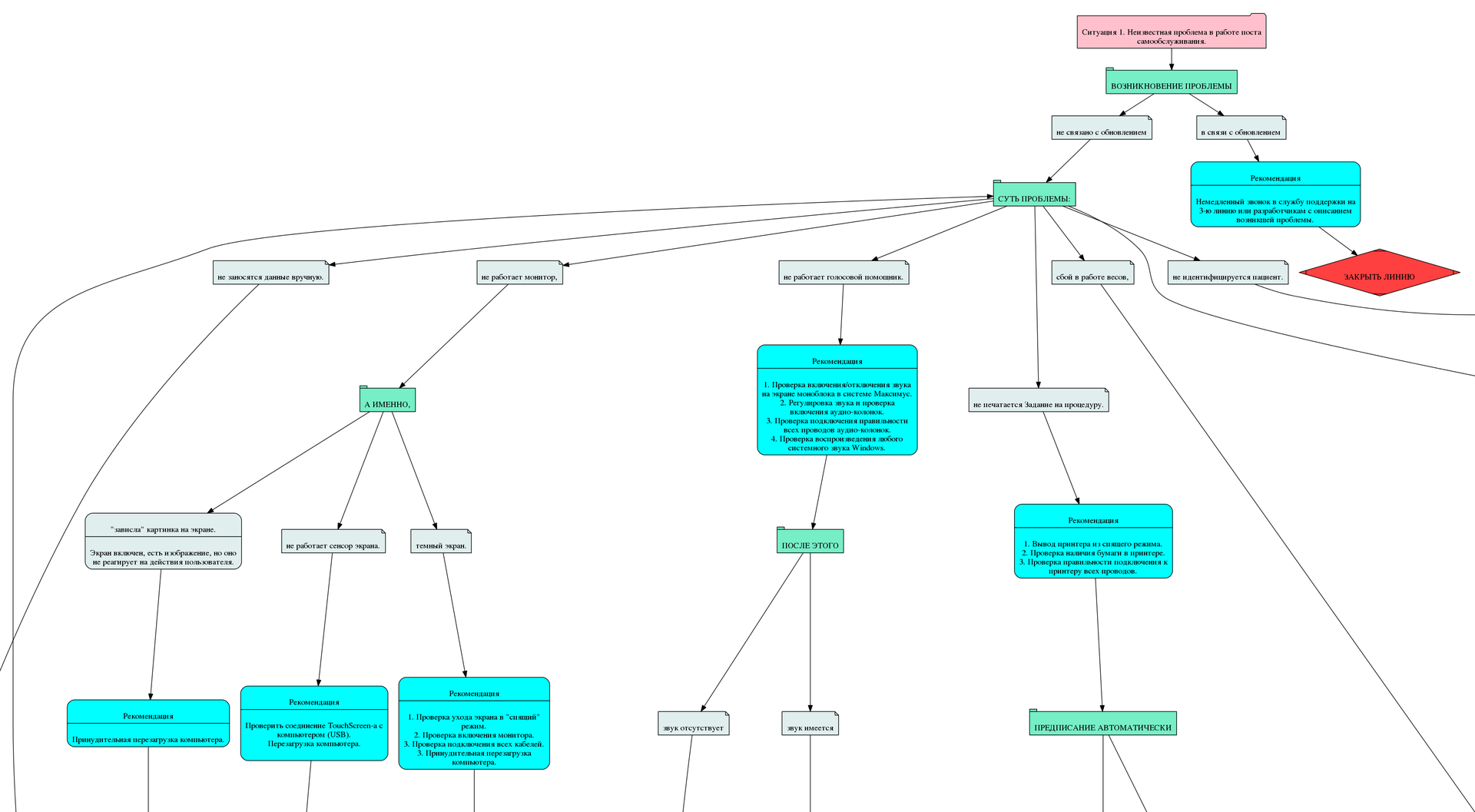
他の状況では、特定のローカライズされた問題をすでに解決できました。
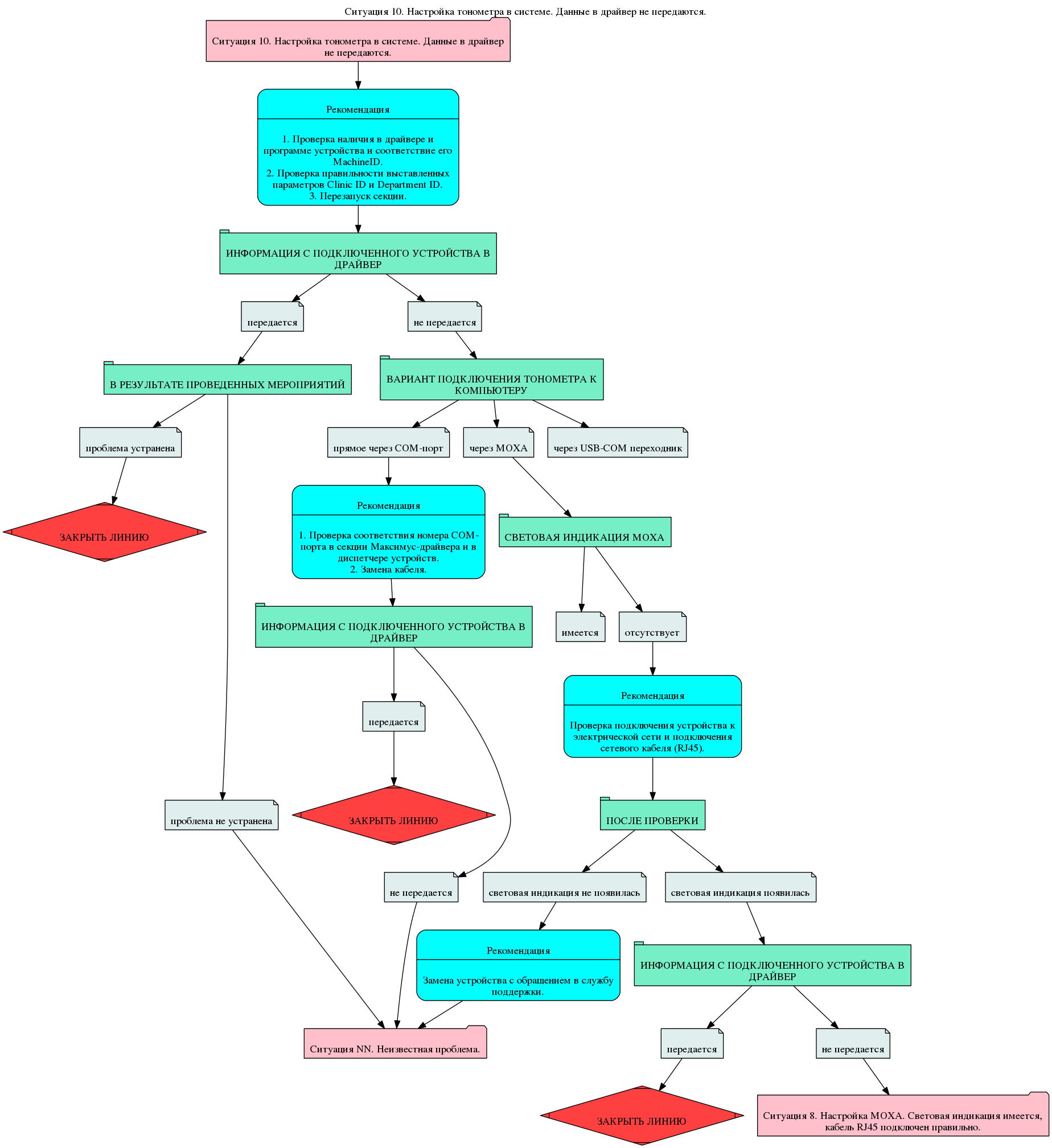
仕事の原理。
最初に診断するとき、システム更新の結果としてエラーが発生したかどうかの事実が確立されます。 理由を説明します。 実際、システムの更新はすべての部門で同時に行われました。 したがって、全員が同じバージョンのデータベースと同じバージョンのバイナリファイルを使用していました。 つまり、システムのエラーも一般的でした。 1つのブランチで検出および修正されたエラーは、すべてのブランチに自動的に中継されました。
問題のローカライズの状況はより広いことが判明しました。 状況自体は、決定により簡潔です。
スタブ状況も提供されました。 つまり、説明されているすべての診断方法と解決策が役に立たなかった場合、システムはこのスタブに対処します。 次のレベルのサポートに移行するための推奨事項が含まれています。
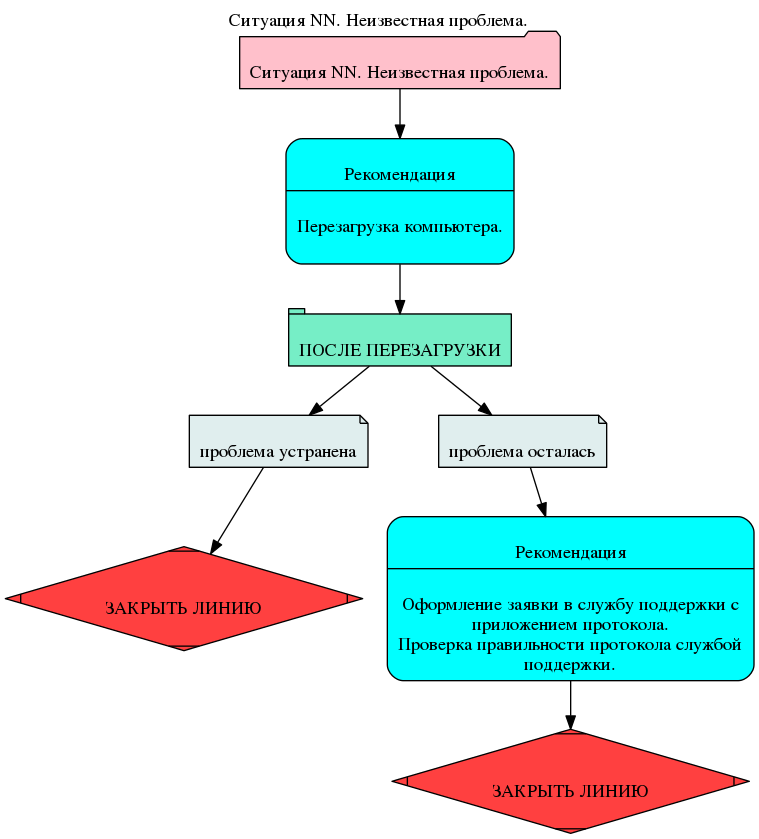
一般に、DSSを作成する方法論では、まだ説明されていないケースのスタブを作成できます。 これにより、セクションの説明がない場合にエラーが発生するリスクなしに、すぐにシステムを実際に使用できます。
アルゴリズム図の印刷機能により、一連のアクションと推奨事項を視覚的に評価することができました。
また、逸脱を制御する能力を実現したいという要望もありました。 これはどういう意味ですか? 通常、障害、ダウンタイムなどの分析。 1か月または1週間の結果に基づきます。 これは純粋に統計情報を提供します。 もちろん、管理上の決定を下すことは可能であり、必要です。 しかし、客観的には効果がありません。
理想主義者と呼んでください。 しかし、ここでは完全に通常の制御と管理の方法について話しています。 つまり、インシデントを特定する機能と、それを排除するために介入または接続する機能です。 それはダウンタイムの予防を食い物にします。 このため、アルゴリズムのローカルITスペシャリストによる現在のウォークスルーが表示されるインターフェイスが計画されました。 つまり、プロトコルの形式で、どのようなインシデントが発生し、そのソリューションのどの段階でスペシャリストがいるかを確認できます。 それに応じて応答し、中央オフィスからの追加の力を接続します今日、そのようなパネルが開発されました。
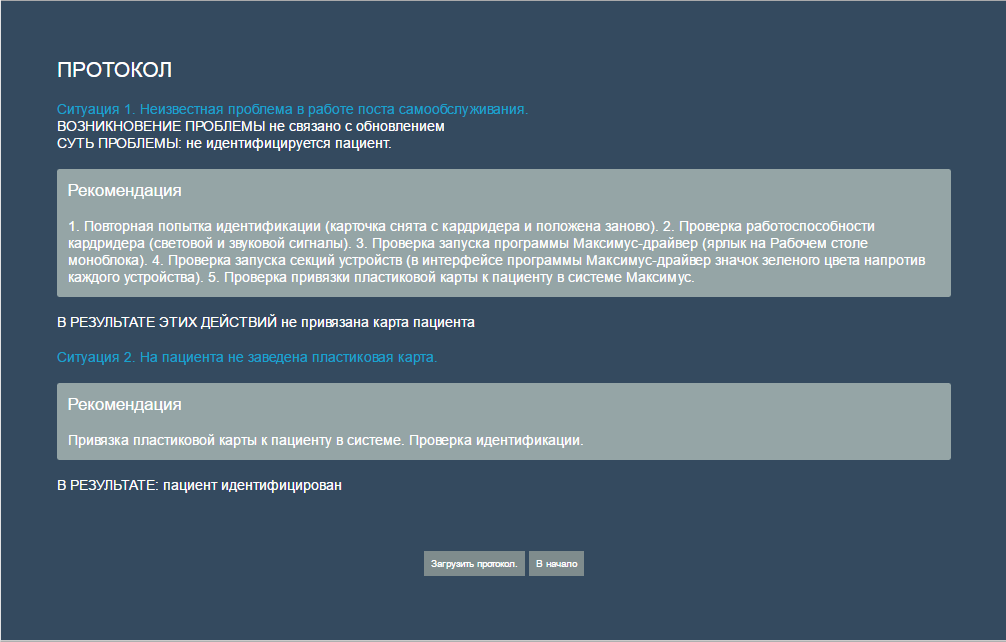
アルゴリズムを通過した後の受信プロトコルの例:
パート3の DSSコアで実行されるTelegramチャットボットの例DSSロジックコア上のTelegramチャットボット : @DSSUABot