ここでVMを長時間同期しているので、最近読んだものについて話す時間がある。
たとえば、GoogLeNetについて。
GoogLeNetは、いわゆるInceptionアーキテクチャの最初の化身であり、その参照は誰にも明らかです。

(ちなみに、それへのリンクは記事リファレンスのリストの最初で、男は燃えています)
彼女は、2014年にImageNet認識チャレンジで6.67%のトップ5エラーを獲得しました。 トップ5エラーは、アルゴリズムが画像クラスの5つのバリアントを生成できるメトリックであり、これらすべてのオプションの中に正しいものがない場合はエラーがカウントされることを思い出させてください。 テストデータセットには150Kの写真と1000のカテゴリがあります。つまり、タスクは非常に重要です。
なぜ、どのように、なぜGoogLeNetが配置されるのかを理解するために、いつものように、ちょっとしたコンテキストがあります。
免責事項:投稿はclosedcircles.comの編集されたチャットログに基づいて書かれているため、プレゼンテーションスタイルと明確な質問です。
2012年に画期的なイベントが開催されます-ImageNetチャレンジが深い畳み込みネットワークを獲得
そして、勝つだけでなく、2位のほぼ半分のエラーを示します(15%対26%top5エラー)
(地域の発展を示すために、現在の最高の結果は3%です)
このグリッドは、ヒントンの学生であるアレックスクリジェフスキーの名前でAlexNetと呼ばれています。 8つのレベル(たたみ込み5つと完全に接続された3つ)しかありませんが、一般的には厚く太い-最大60Mのパラメーターです。 彼女のトレーニングは3GBのメモリを備えた1つのGPUには適合せず、アレックスはすでに2つのGPUでこれをトレーニングする方法を考え出す必要があります。
そのため、Googleの人々はそれをより実用的にするために取り組んでいます。
たとえば、より小さなデバイスで一般的に使用できるようにします。
GoogLeNetは、精度でさえも、モデルのサイズの効率と必要な計算数の点であまり好きではありません。
論文自体-http://arxiv.org/abs/1409.4842
彼らが持っている主なアイデアは次のとおりです。
- 最初のAlexNetは、多くのパラメーターを必要とする大きな畳み込みを行いました。多くのレールを使用して、より小さい畳み込みを実行してみましょう。
- そして、より厚い層を補正するために、測定の数を積極的に減らします。 巧妙に、これは1x1コンボリューションを使用して行うことができます-実際、現在の測定数を取得し、それらをより小さなものに線形的に混合するために画像全体に適用される線形フィルター。 彼も勉強しているので、とても効果的です。
- 各レベルで、異なるサイズの特徴を引き出すために、異なるサイズのいくつかの畳み込みカーネルを実行します。 スケールが現在のレベルに対して大きすぎる場合、次のレベルで認識されます。
- FCレイヤーには多くのパラメーターがあるため、非表示のFCレイヤーは一切行いません。 代わりに、最後のレベルで、グローバルな平均プールを作成し、出力層に直接フックします。
これは、1つの開始モジュールがどのように見えるかです:
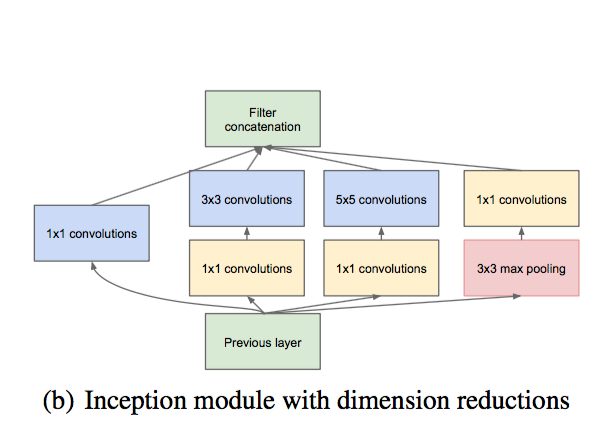
異なるサイズの同じカーネルが表示され、1x1の畳み込みが表示されて次元が縮小されます。
そして今、ネットワークは9つのそのようなブロックで構成されています。 このような設計には、AlexNetの約10倍のパラメーターがあり、次元削減がうまく機能するため、計算も高速になります。
そして、彼女が実際に写真をよりよく分類することも判明しました-上で書いたように、6.65%のtop5エラー。
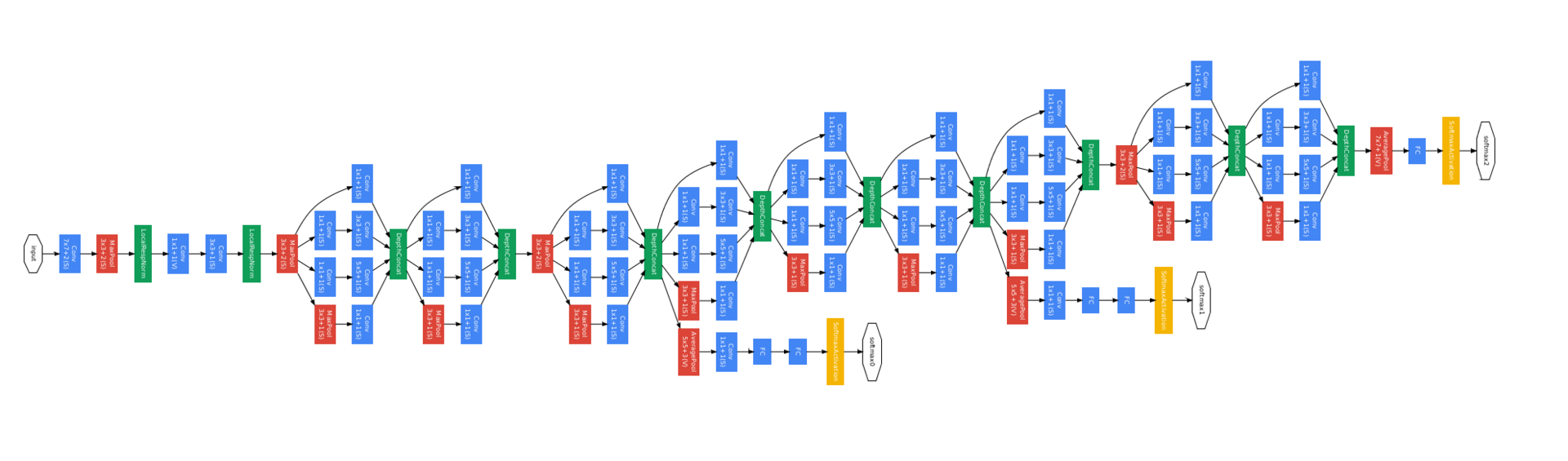
完全なネットワークの写真を次に示します。 怖いように見えますが、これらが繰り返しブロックであることに気付くと、簡単になります。
他に何を伝えるべきか...
彼女には3つのトレーニングヘッド(黄色の四角)があります。これは、このような深いネットワークのトレーニングを容易にするために行われました。 追加の各トレーニングヘッドには、低レベルに基づいて同じクラスを予測するいくつかのFCレイヤーがあり、信号がより低いレベルに速く到達するようにします(ただし、以下の作業では、追加の正則化であるため、より役立つことがわかりました)。
このリリースでは、補助トレーニングヘッドにつながるすべてのものが破棄されます。 このような手法は文献の他の場所で使用されていますが、それ以来、ディープネットをより良くトレーニングすることを学んできたため、すでに必要になっています。
このようなアーキテクチャは、GoogLeNet自体に加えて、Inception-v1と呼ばれます。
Inception-BNも同じグリッドであり、 バッチ正規化を使用してのみトレーニングされます(ここでは、指について説明します)。
そして、Inception-v2以降はすでに複雑なアーキテクチャです。これについては次回お話しします。
GoogLeNetの「Le」は、LeNet 5のリファレンスです。LeNet5は、ディープラーニングが問題になる前にLeCuneが最初に公開したグリッドです。
最近、ネットワーク圧縮についても読みました。 彼らはそこにネットワークを取り、それから余分な重みを切り取り、ネットワークは百回に一度減少し、精度はほとんど影響を受けません。 つまり、ギガバイトからメガバイトまで、携帯電話のメモリに押し込めるようなものです。 私はさらに10年を感じ、各カメラは実際に見え始めます。
ところで、もし興味があるなら、圧縮ページャーについて-http://arxiv.org/abs/1510.00149 。
うん。 これらはわずかに異なるレベルのゲームです。
アーキテクチャとトレーニングのレベルで最適化できますが、低レベルで最適化できます-学習済みの重みで既に動作します。
ほとんどの場合、実際には両方が必要です。
ところで、問題は宇宙にあります。
そして、これらすべてからグローバルな結論を引き出すことができますか?
なぜこれがすべて機能するのですか? または少なくとも-この経験に基づいてネットワークを設計する最善の方法は?
すばらしい質問です。これについては、ストーリーの次の部分で多くの肉があります。 お楽しみに!