この記事は、Visual C ++コンパイラの最適化に関するものです。 コンパイラーがそれらを正しく適用するために適用しなければならない最も重要な最適化手法とソリューションについて説明します。 私の目標は、コードを手動で最適化する方法を説明することではなく、自分でコードを最適化するためにコンパイラを信頼する必要がある理由を示すことです。 この記事は、Visual C ++コンパイラが行う最適化の完全なセットの説明ではなく、知っておくべき本当に重要なもののみを示します。 コンパイラが実行できない他の重要な最適化があります。 たとえば、非効率的なアルゴリズムを効果的なアルゴリズムに置き換えたり、データ構造のアライメントを変更したりします。 この記事では、このような最適化については説明しません。
コンパイラーの最適化の定義
最適化とは、コードの速度とサイズが最も重要な特性を改善するために、コードを元のコードと機能的に同等な別のコードに変換するプロセスです。 その他の特性には、コード実行ごとの消費エネルギー量とコンパイル時間(結果のコードがJITを使用する場合のJITコンパイル時間)が含まれます。コンパイラは常に改善されており、そのアプローチは改善されています。 それらが完全ではないという事実にもかかわらず、多くの場合、最も正しいアプローチは、手動で行うよりも低レベルの最適化をコンパイラに任せることです。
コンパイラーが最適化をより効率的に実行するのに役立つ4つの方法があります。
- 保守しやすい読み取り可能なコードを作成します。 Visual C ++のさまざまなOOP機能をパフォーマンスの最悪の敵と考えないでください。 Visual C ++の最新バージョンでは、OOPオーバーヘッドを最小限に抑えることができ、場合によってはそれらを完全に取り除くこともできます。
- コンパイラディレクティブを使用します。 たとえば、デフォルトよりも速い関数呼び出し規約を使用するようコンパイラーに指示します。
- コンパイラに組み込まれている関数を使用します。 これらは、コンパイラーによって実装が自動的に提供される特別な関数です。 コンパイラは、指定されたソフトウェアアーキテクチャ上でコードができるだけ速く実行されるように、マシン命令のシーケンスを効率的に配置する方法について深い知識を持っていることに注意してください。 現在、Microsoft .NET Frameworkは組み込み関数をサポートしていないため、マネージ言語はそれらを使用できません。 ただし、Visual C ++はそのような機能を広範囲にサポートしています。 ただし、コードのパフォーマンスは向上しますが、読みやすさと移植性に悪影響を与えることを忘れないでください。
- プロファイルに基づく最適化(PGO)を使用します。 このテクノロジーのおかげで、コンパイラーは、操作中のコードの動作についてより多くのことを認識し、それに応じて最適化します。
この記事の目的は、非効率的であるが読み取り可能なコードに適用される最適化を実行するコンパイラーを信頼できる理由を示すことです(最初の方法)。 また、プロファイルガイドによる最適化の概要を説明し、ソースコードの一部を改善できるコンパイラディレクティブについても説明します。
コンパイラーの最適化には、折りたたみ定数などの単純な変換から、コマンドのスケジューリングなどの複雑な変換まで、さまざまな手法があります。 この記事では、コードのパフォーマンスを大幅に向上させる(2桁のパーセント)ことができ、関数(関数のインライン化)、COMDAT最適化、およびループ最適化を置き換えることでサイズを削減できる最も重要な最適化に限定します。 次のセクションで最初の2つのアプローチについて説明し、Visual C ++で最適化のパフォーマンスを制御する方法を示します。 結論として、.NET Frameworkで使用されるこれらの最適化について簡単に説明します。 記事全体を通して、すべての例でVisual Studio 2013を使用します。
リンク時コード生成
リンク時コード生成(LTCG)コード生成は、C / C ++コードのプログラム全体の最適化(プログラム全体の最適化、WPO)を実行するための手法です。 C / C ++コンパイラは、各ソースコードファイルを個別に処理し、対応するオブジェクトファイルを発行します。 つまり、コンパイラーは、プログラム全体を最適化するのではなく、単一のファイルのみを最適化できます。 ただし、一部の重要な最適化はプログラム全体にのみ適用される場合があります。 リンカはプログラムを完全に理解しているため、これらの最適化はリンク中にのみ使用でき、コンパイル中には使用できません。LTCGが有効な場合(フラグ
/GL
)、コンパイラドライバー(
cl.exe
)はフロントエンド(
c1.dll
または
c1xx.dll
)のみを呼び出し、リンクまでバックエンド(
c2.dll
)を延期します。 結果のオブジェクトファイルには、マシンコードではなくC中間言語(CIL)が含まれます。 次に、リンカー(
link.exe
)が呼び出されます。 彼は、オブジェクトファイルにCILコードが含まれていることを確認し、バックエンドを呼び出します。バックエンドは、WPOを実行してバイナリオブジェクトファイルを生成し、リンカーがそれらを接続して実行可能ファイルを形成できるようにします。
フロントエンドは、最適化のオン/オフに関係なく、いくつかの最適化(折りたたみ定数など)も実行します。 ただし、重要な最適化はすべてバックエンドによって実行され、コンパイルキーを使用して制御できます。
LTCGを使用すると、バックエンドで多くの最適化を積極的に実行できます(
/O1
または
/O2
および
/Gw
とともに
/GL
コンパイラキー、および
/OPT:REF
および
/OPT:ICF
リンクキーを使用)。 この記事では、インライン化とCOMDAT最適化のみについて説明します。 LTCG最適化の完全なリストは、ドキュメントに記載されています。 リンカは、ネイティブ、ネイティブ管理、および純粋に管理されたオブジェクトファイル、および安全な管理オブジェクトファイルとsafe.netmodulesでLTCGを実行できることを知っておくと役立ちます。
2つのソースコードファイル(
source1.c
および
source2.c
)とヘッダーファイル(
source2.h
)のプログラムを使用します。
source1.c
および
source2.c
を以下のリストに示します。すべての
source2.c
関数のプロトタイプを含むヘッダーファイルは非常に単純なので、説明しません。
// source1.c #include <stdio.h> // scanf_s and printf. #include "Source2.h" int square(int x) { return x*x; } main() { int n = 5, m; scanf_s("%d", &m); printf("The square of %d is %d.", n, square(n)); printf("The square of %d is %d.", m, square(m)); printf("The cube of %d is %d.", n, cube(n)); printf("The sum of %d is %d.", n, sum(n)); printf("The sum of cubes of %d is %d.", n, sumOfCubes(n)); printf("The %dth prime number is %d.", n, getPrime(n)); }
// source2.c #include <math.h> // sqrt. #include <stdbool.h> // bool, true and false. #include "Source2.h" int cube(int x) { return x*x*x; } int sum(int x) { int result = 0; for (int i = 1; i <= x; ++i) result += i; return result; } int sumOfCubes(int x) { int result = 0; for (int i = 1; i <= x; ++i) result += cube(i); return result; } static bool isPrime(int x) { for (int i = 2; i <= (int)sqrt(x); ++i) { if (x % i == 0) return false; } return true; } int getPrime(int x) { int count = 0; int candidate = 2; while (count != x) { if (isPrime(candidate)) ++count; } return candidate; }
source1.c
ファイルには、整数の2乗を計算する2乗関数と、プログラム
main
main関数の2つの関数が含まれています。 メイン関数は、正方形関数と、
source2.c
を除く
source2.c
すべての関数を
isPrime
ます。
source2.c
ファイルには、整数を3
cube
ための
cube
、1から特定の数までの整数の
sum
を計算するための合計、1から特定の数までの整数のキューブの合計を計算するための
getPrime
、簡単にするために数を確認するための
isPrime
、
isPrime
5つの関数が含まれます指定された数の素数を取得します。 この記事では興味がないので、エラー処理をスキップしました。
コードは非常にシンプルですが、便利です。 単純な計算を行ういくつかの関数があり、それらのいくつかはループを含んでいます。
getPrime
関数は、その中に
getPrime
関数を呼び出す
while
が含まれている
getPrime
、最も複雑です。 このコードを使用して、コンパイラーの最適化といくつかの追加の最適化をインライン化する重要な関数の1つを示します。
3つの異なる構成でのコンパイラーの結果を検討してください。 自分でサンプルを扱う場合は、実行されるCOMDAT最適化を調べるために、アセンブラー出力ファイル(コンパイラーキー
/FA[s]
を使用して取得)およびマップファイル(リンカー
/MAP
キーを使用して取得)が必要です(リンカーはそれらを報告します)
/verbose:icf
および
/verbose:ref
/verbose:icf
を含める場合)。 すべてのキーが正しいことを確認し、記事を読み続けます。 C(
/TC
)コンパイラーを使用して、生成されたコードを学習しやすくしますが、記事に記載されているものはすべてC ++コードにも適用されます。
デバッグ構成
デバッグ構成が主に使用されるのは、/GL
スイッチなしで
/Od
スイッチを指定すると、すべてのバックエンド最適化がオフになるためです。 この構成では、結果のオブジェクトファイルには、ソースコードと完全に一致するバイナリコードが含まれています。 結果のアセンブラ出力ファイルとマップファイルを調べて、これを確認できます。 この構成は、Visual Studioのデバッグ構成と同等です。
コンパイル時コード生成リリース構成
この構成は、リリース構成(/O1
、
/O2
または
/Ox
スイッチを指定)に似ていますが、
/GL
スイッチは含まれていません。 この構成では、結果のオブジェクトファイルには最適化されたバイナリコードが含まれますが、プログラム全体のレベルの最適化は実行されません。
source1.c
生成されたアセンブリリストファイルを
source1.c
、2つの重要な最適化が行われていることが
source1.c
ます。
square
関数の最初の呼び出しである
square(n)
、コンパイル時に計算された値に置き換えられました。 これはどのように起こりましたか? コンパイラーは、関数の本体が小さいことに気付き、その内容を呼び出しに置き換えることにしました。 次に、コンパイラーは、値の計算に既知の初期値を持つローカル変数
n
があり、初期割り当てと関数呼び出しの間で変化しないという事実に注意を引きました。 したがって、彼は乗算演算の値を計算し、結果を置き換えることが安全であるという結論に達しました(
25
)。
square
関数の2番目の呼び出し
square(m)
もインラインでした。つまり、関数の本体が呼び出しに置き換えられました。 ただし、変数mの値はコンパイル時には不明であるため、コンパイラは事前に式の値を計算できませんでした。
それでは、
source2.c
アセンブリリストファイルを
source2.c
みましょう。
sumOfCubes
関数の
cube
関数の呼び出しはインラインでした。 これにより、コンパイラはループの最適化を実行できます(これについては、「ループの最適化」セクションで詳しく説明します)。
isPrime
関数は、SSE2命令を使用して、
sqrt
呼び出されたときに
int
を
double
に変換し、
sqrt
から結果を取得するときに
double
から
int
に変換しました。 実際、ループの開始前に
sqrt
1回呼び出されました。
/arch
スイッチは、x86がデフォルトでSSE2を使用することをコンパイラーに通知することに注意してください(ほとんどのx86プロセッサーおよびx86-64プロセッサーはSSE2をサポートします)。
リンク時コード生成リリース構成
この構成は、Visiual Studioのリリース構成と同じです。最適化が有効になり、/GL
コンパイラキーが指定されます(
/O1
または
/O2
明示的に指定することもできます)。 したがって、アセンブリオブジェクトファイルの代わりにCILコードでオブジェクトファイルを生成するようコンパイラーに指示します。 これは、上記のように、リンカがコンパイラのバックエンドを呼び出してWPOを実行することを意味します。 ここで、LTCGの大きな利点を示すために、いくつかのWPOについて説明します。 この構成用に生成されたアセンブリコードのリストは、オンラインで入手できます。
関数のインライン化がオンになっている間(最適化をオンにするとオンになる
/Ob
スイッチ)、
/GL
スイッチを使用すると、コンパイラーは
/Gy
スイッチに関係なく他のファイルで定義された関数をインライン化できます(後で詳しく説明します)。
/LTCG
オプションであり、リンカーにのみ影響します。
source1.c
アセンブリリストファイルを
source1.c
、
scanf_s
を除くすべての関数の呼び出しがインラインであることが
source1.c
ます。 その結果、コンパイラは関数
cube
、
sum
および
sumOfCubes
を計算できました。
isPrime
関数のみ
isPrime
インライン化
isPrime
ませんでした。 ただし、
getPrime
で手動でインライン化した
getPrime
、コンパイラーは
getPrime
でインライン
getPrime
を実行します。
ご覧のとおり、関数のインライン化は、関数呼び出しが最適化されるだけでなく、コンパイラーが多くの追加の最適化を実行できるため重要です。 インライン化は通常、コードのサイズを増やすことでパフォーマンスを向上させます。 この最適化を過度に使用すると、コードの膨張と呼ばれる現象が発生します。 したがって、関数を呼び出すたびに、コンパイラーはコストと利点を計算し、関数をインライン化するかどうかを決定します。
インライン化の重要性により、Visual C ++コンパイラはインライン化を強力にサポートします。
auto_inline
ディレクティブを使用して、関数セットをインライン化しないようにコンパイラーに指示できます。
__declspec(noinline)
を使用して、指定された関数またはメソッドをコンパイラーに伝えることもできます。 関数を
inline
でマークし、コンパイラーにインラインを実行するようにアドバイスすることもできます(ただし、コンパイラーは、それが悪いと判断した場合、このアドバイスを無視することもできます)。
inline
は、C ++の最初のバージョンから使用可能であり、C99で登場しました。 CとC ++の両方にMicrosoftの
__inline
コンパイラキーワードを使用できます。これは、このキーワードをサポートしない古いバージョンのCを使用する場合に便利です。
__forceinline
(CおよびC ++の場合)は、可能であれば、コンパイラーが常に関数をインライン化するように強制します。 最後に、
inline_recursion
こととして、
inline_recursion
ディレクティブを使用してインライン化することにより、指定した深さまたは不定の深さの再帰関数をデプロイするようコンパイラーに指示できます。 現時点では、コンパイラーは関数呼び出しの場所でインライン展開を制御する機能を持たず、その宣言の場所では機能しないことに注意してください。
/Ob0
は、インライン化を完全に無効にします。これは、デバッグ中に役立ちます(このスイッチは、Visual Studioのデバッグ構成で機能します)。
/Ob1
は、
inline
、
/Ob1
inline
、
/Ob1
マークされた関数のみを
__forceinline
候補と見なすようコンパイラーに指示します。
/Ob2
は、指定された
/O[1|2|x]
でのみ動作し、インライン化のためにすべての関数を考慮するようコンパイラーに指示します。 私の意見では、
inline
および
__inline
を使用する唯一の理由は、
/Ob1
キーのインライン化を制御することです。
コンパイラは常に関数をインライン化できるわけではありません。 例えば、仮想関数の仮想呼び出し中:コンパイラーはどの関数が呼び出されるかを正確に知らないため、関数をインライン化することはできません。 別の例:関数は、名前を介した呼び出しではなく、関数へのポインターを介して呼び出されます。 インライン化が可能になるように、このような状況を避けるようにしてください。 そのようなすべての条件の完全なリストは、MSDNで見つけることができます。
プログラムのレベルで全体として適用できる最適化は、関数のインライン化だけではありません。 ほとんどの最適化は、このレベルで最も効果的に機能します。 この記事の残りの部分では、COMDAT最適化と呼ばれる特定のクラスの最適化について説明します。
デフォルトでは、モジュールのコンパイル中、すべてのコードは結果のオブジェクトファイルの単一セクションに保存されます。 リンカはセクションレベルで動作します。セクションの削除、結合、並べ替えができます。 これにより、実行ファイルのサイズを縮小し、パフォーマンスを向上させる3つの非常に重要な最適化(2桁のパーセント)を実行できなくなります。 1つ目は、未使用の関数とグローバル変数を削除します。 2番目は、同一の関数とグローバル定数を折りたたみます。 3番目の関数は、実行時に物理メモリフラグメント間の遷移が短くなるように、関数とグローバル変数を並べ替えます。
これらのリンカ最適化を有効にするには、コンパイラキー
/Gy
(リンク関数レベル)および
/Gw
(グローバルデータの最適化)を使用して、関数と変数を別々のセクションにパックするようコンパイラに依頼する必要があります。 これらのセクションはCOMDATと呼ばれます。
__declspec( selectany)
を使用して特定のグローバル変数をマークし、COMDATで変数をパッケージ化するようコンパイラーに指示することもできます。 さらに、
/OPT:REF
リンカキーを使用すると、未使用の関数とグローバル変数を削除できます。 キー
/OPT:ICF
は、同一の関数とグローバル定数を折りたたむのに役立ちます(ICFは同一のCOMDATフォールディングです)。
/ORDER
スイッチにより、リンカは特定の順序で結果のイメージにCOMDATを配置します。 すべてのリンカ最適化には
/GL
キーが必要ないことに注意してください。
/OPT:REF
および
/OPT:ICF
スイッチは、明らかな理由でデバッグ中にオフにする必要があります。
可能な限りLTCGを使用する必要があります。 LTCGを放棄する唯一の理由は、結果のオブジェクトファイルとライブラリファイルを配布するためです。 マシンコードの代わりにCILコードが含まれていることを思い出してください。 開発者がファイルを使用するには同じバージョンのコンパイラを使用する必要があるため、CILコードは、生成された同じバージョンのコンパイラとリンカでのみ使用できます。これは大きな制限です。 この場合、コンパイラのバージョンごとにオブジェクトファイルの個別のバージョンを配布したくない場合は、代わりにコード生成を使用する必要があります。 バージョン制限に加えて、オブジェクトファイルは、対応するアセンブラオブジェクトファイルよりも何倍も大きくなります。 ただし、CILコードを持つオブジェクトファイルの大きな利点を忘れないでください。これはWPOを使用する機能です。
ループ最適化
Visual C ++コンパイラは、いくつかのタイプのループ最適化をサポートしていますが、ループアンロール、自動ベクトル化、およびループ不変コードモーションの3つのみについて説明します。source1.c
のコードを変更して、nではなくmが
sumOfCubes
に渡されるようにした場合、コンパイラーはパラメーターの値を計算できなくなります。任意の引数で機能するように関数をコンパイルする必要があります。 結果の関数は大きく最適化されるため、コンパイラーはインライン化されません。
/O1
スイッチを使用してコードをコピーすると、
sumOfCubes
最適化は適用され
sumOfCubes
。
/O2
スイッチを使用してコンパイルすると、速度が最適化されます。 この場合、
sumOfCubes
関数内のループが巻き戻されてベクトル化される
sumOfCubes
、コードサイズが大幅に増加します。 キューブ関数をインライン化しないとベクトル化ができないことを理解することは非常に重要です。 さらに、サイクルを巻き戻すことは、インライン化なしではそれほど効果的ではありません。 最終コードの簡略化されたグラフィカルな表現を次の図に示します(このグラフはx86とx86-64の両方に有効です)。
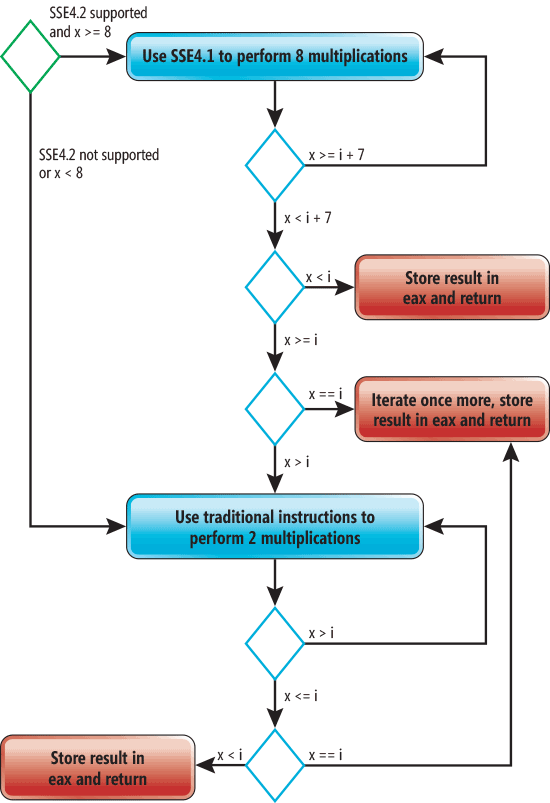
この図では、緑色の菱形は入口点を示し、赤色の長方形は出口点を示します。 青い菱形は、
sumOfCubes
関数が
sumOfCubes
れたときに実行される条件ステートメントを表します。 SSE4がサポートされ、xが8以上の場合、SSE4命令を使用して一度に4つの乗算を実行します。 複数の変数に対して同じ操作を実行するプロセスは、ベクトル化と呼ばれます。 コンパイラはこのループを2回ほどほどします。 これは、ループの本体が各反復で2回繰り返されることを意味します。 結果として、乗算の8つの演算のパフォーマンスは1回の反復で発生します。
x
8未満の場合、最適化されていないコードが関数の実行に使用されます。 コンパイラーは1つではなく3つの出口点を挿入することに注意してください。したがって、遷移の数が減ります。
サイクルの巻き戻しは、新しい(巻き戻された)サイクルの1回の繰り返し内でサイクルの本体を数回繰り返すことによって実行されます。 これにより、サイクル自体の操作の実行頻度が低くなるため、生産性が向上します。 さらに、これにより、コンパイラーは追加の最適化(ベクトル化など)を実行できます。 巻き戻しループの欠点は、コードの量とレジスタの負荷が増加することです。 しかし、それにもかかわらず、サイクルの本体に応じて、このような最適化は生産性を2桁の割合で高めることができます。
x86プロセッサとは異なり、すべてのx86-64プロセッサはSSE2をサポートしています。 さらに、
/arch
スイッチを使用して、IntelおよびAMDの最新のx86-64モデルでAVX / AVX2命令を利用できます。
/arch:AVX2
指定することにより、FMAおよびBMI命令も使用するようコンパイラーに指示します。
現在、Visual C ++コンパイラでは、ループの巻き戻しを制御できません。 ただし、
no_vector
オプションを指定した
loop
ディレクティブを使用して、影響を与えることができます(後者は、指定されたループの
no_vector
ベクトル化を無効にします)。
生成されたアセンブラコードを見ると、追加の最適化を適用できることがわかります。 とにかく、コンパイラーはとにかく素晴らしい仕事をしてくれたので、マイナーな最適化を適用するために分析するのに多くの時間を費やす必要はありません。
someOfCubes
関数
someOfCubes
、ループが解かれた唯一のもので
someOfCubes
ません。 コードを変更して
n
代わりに
m
を
sum
関数に渡すと、コンパイラーはその値を計算できず、コードを生成する必要があり、ループが2回巻き戻されます。
結論として、サイクル不変量の除去などの最適化を検討します。 次のコードを見てください。
int sum(int x) { int result = 0; int count = 0; for (int i = 1; i <= x; ++i) { ++count; result += i; } printf("%d", count); return result; }
行った唯一の変更は、追加の変数を追加することです。この変数は各反復で増加し、最後にコンソールに表示されます。 このコードは、増分された変数をループ外に移動することで簡単に最適化されることがわかります
x
を割り当てるだけです。 この最適化は、ループ不変コードモーションと呼ばれます。 「不変」という言葉は、コードの一部がループ変数を含む式から独立している場合にこの手法が適用可能であることを示しています。
: , . ? ,
x
. ,
count
. x count, ! ,
x
,
count
. , . , Visual C++ , ,
x
.
, , , , . .
O1
,
/O2
,
/Ox
,
optimize
:
#pragma optimize( "[optimization-list]", {on | off} )
optimization list , :
g
,
s
,
t
,
y
.
/Og
,
/Os
,
/Ot
,
/Oy
.
c
off
.
on
.
/Og
, , , .
LTCG
,
/Og
WPO.
optimize
, , : , . , , profile-guided- (PGO), , , . , . Visual Studio , , .
.NET
.NET , . (C# compiler) JIT-. . , . JIT-. JIT- .NET 4.5 SIMD. JIT- .NET 4.5.1 ( RyuJIT) SIMD.RyuJIT Visual C++ ? , RyuJIT , , Visual C++ . , ,
true
, . RyuJIT . , SSE4.1, JIT- SSE4.1
subOfCubes
, . , RyuJIT , . . JIT- . Visual C++ , . Microsoft .NET Native Visual C++. Windows Store.
. C# Visual Basic
/optimize
. JIT-
System.Runtime.CompilerServices.MethodImpl
MethodImplOptions
.
NoOptimization
,
NoInlining
,
AggressiveInlining
( .NET 4.5) JIT- , .