この記事では、VPSの標準プラットフォームがどのように構成されているか、およびそれを改善するために使用した技術について説明します。
標準のVDSテクノロジー
私たちと一緒に仮想サーバーをホストすることは次のとおりです。
ラックには、ほぼ次の構成の単一ユニットサーバーが装備されています。
- CPU-2 x Intel Xeon CPU E5-2630 v2 @ 2.60GHz
- マザーボード:Intel Corporation S2600JF
- RAM:64 Gb
- ディスク:2 x HGST HDN724040ALE640 / 4000 GB、INTEL SSDSC2BP480G4 480 GB
サーバーの1つがメインです。 VMmanagerがインストールされ、ノードがそれに接続されます-追加サーバー。
VMmanagerに加えて、クライアント仮想サーバーはメインサーバーにあります。
各サーバーは、そのネットワークインターフェイスで世界を「見」ます。 また、ノード間のVDS移行の速度を上げるために、サーバーは個別のインターフェイスで相互接続されます。
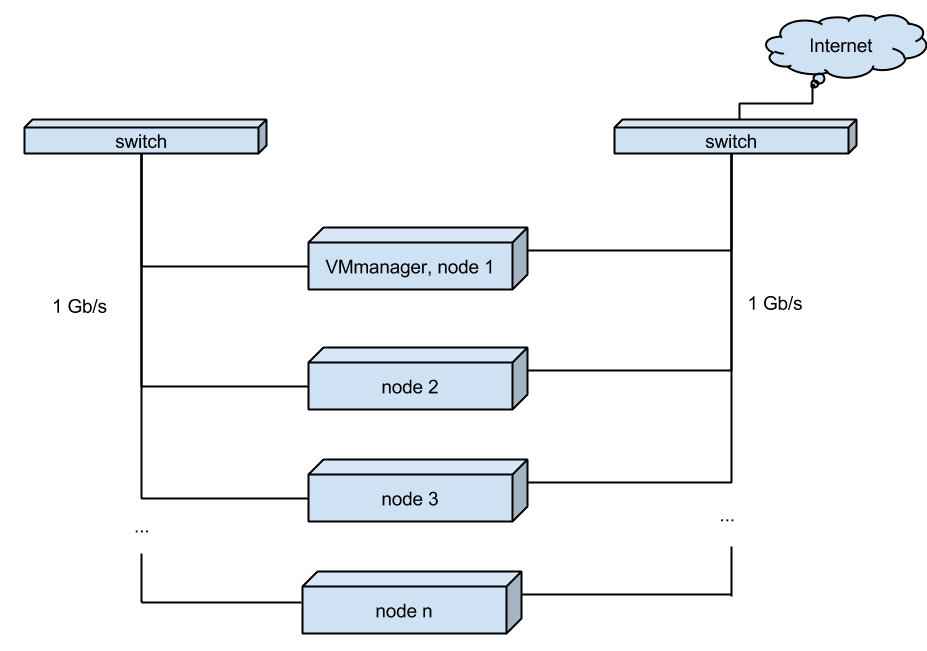
(図1.現在の仮想サーバーホスティングスキーム)
すべてのサーバーは互いに独立して動作し、いずれかのサーバーでパフォーマンスの問題が発生した場合、すべての仮想サーバーを隣接ノードに分散(VMmanagerの移行機能)するか、新しく追加したノードに転送できます。
サーバーがクラッシュする状況(カーネルパニック、ディスクの流出、PSUの停止など)には、クライアント仮想マシンが使用できないことが含まれます。 もちろん、監視システムは問題について直ちに責任ある専門家に通知し、彼らは原因を見つけて事故を排除し始めます。 ケースの90%で、故障したコンポーネントの交換作業は1時間以内で完了し、さらにサーバーの緊急シャットダウンの結果(ストレージ同期、ファイルシステムエラーなど)を排除するのに時間がかかります。
もちろん、これはすべて私たちとお客様にとって不快ですが、シンプルなスキームにより、不必要な費用を避け、価格を低く抑えることができます。
新しいクラウドVDS
Uptimeサーバーが重要である最も要求の厳しい顧客を満足させるために、可能な限り高い信頼性を備えたサービスを作成しました。
そのため、新しいソフトウェアとハードウェアが必要でした。
すでにISPsystem製品を扱っているので、論理的なステップはVMmanager-Cloudを調べることでした。 このパネルは、フォールトトレランスの問題を解決するために作成されたばかりで、現時点では適切に設計されており、一定の安定性に達しています。 彼女は私たちに合い、私たちは代替案を考慮しませんでした。
Cephは、分散ファイルシステムとして無条件に受け入れられました。 これは、柔軟でスケーラブルな無料で成長している製品です。 他のストレージシステムを試しましたが、ストレージ要件を完全に満たした製品はCephだけです。 最初は複雑に見えましたが、いくつかの試みで最終的に理解しました。 そして、それを後悔しませんでした。
新しいクラスターのノードは、稼働中のVMmanagerクラスターと同じハードウェア上で組み立てられますが、わずかな変更が加えられています。
電源バックアップを使用してマルチ冗長性に切り替えました。
クラスターノード間の切り替えには、通常のギガビット接続の代わりに、Infinibandを使用しました。 接続速度を56Gbに上げることができます(IBカードMellanox Technologies MT27500ファミリーConnectX-3、スイッチ-Mellanox SX6012)
CentOS 7ディストリビューションがクラスターノードのオペレーティングシステムとして選択されましたが、上記のすべてを連携させるには、カーネルをアセンブルし、qemuを再構築し、VMmanager-Cloudの改善を要求する必要がありました。
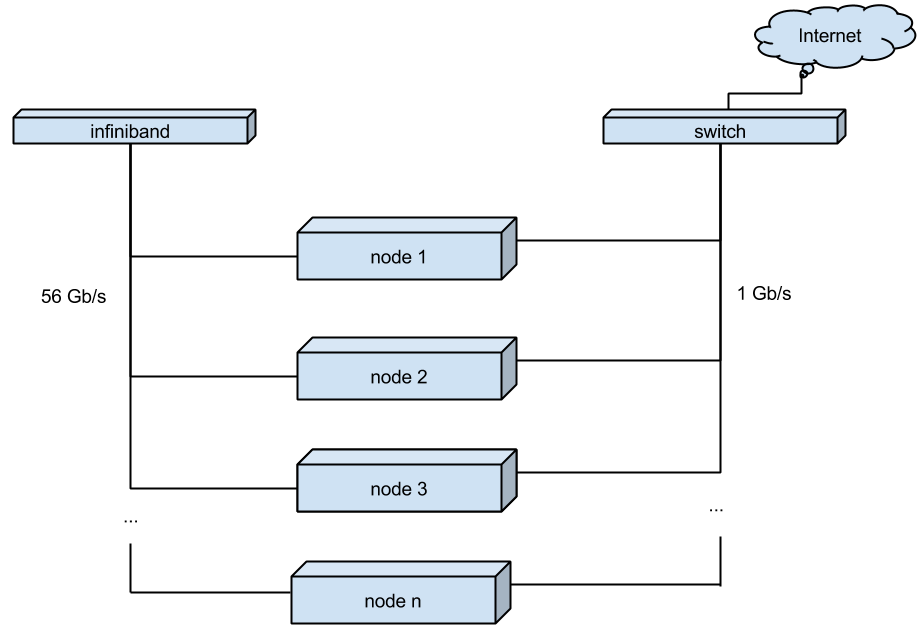
(図2.仮想サーバーのクラウドホスティングの新しいスキーム)
新しいテクノロジーを使用する利点
その結果、次のようになりました。
- 稼働率の高いさらにプロフェッショナルな仮想サーバーサービス。 その安定性は、クラスターノードのハードウェアの問題に依存しません。
- 複数のコピーを保存する分散ファイルシステムにより、データストレージの信頼性が向上しました。
- 仮想マシンの高速移行。 ノードからノードへの動作中のVPSの転送は、パケットとpingを失うことなくほぼ瞬時に発生します。 必要に応じて、これにより、メンテナンスのためにノードがすばやく解放されます。
- ノードに障害が発生すると、クライアント仮想マシンは他のノードで自動的に起動します。 クライアントにとっては、電源オン時の予定外の再起動のように見え、ダウンタイムはOSの再起動時間に等しくなります。
昨年12月の初めから、クラスターは戦闘モードで動作しており、現時点では数百のクライアントにサービスを提供していますが、この間に多くのレーキを踏んでボトルネックを整理し、必要なチューニングを実行し、すべての緊急事態をシミュレートしました。
テストを続けながら、経済学者はコストを考慮します。 追加の冗長性とより高価なテクノロジーの使用により、以前のクラスターよりも高いことが判明しました。 これを考慮して、最も要求の厳しい顧客向けに新しい関税を開発しています。
閉鎖することのできない多くのリスクが残っています。これはデータセンターと外部通信チャネルの電源です。 このような問題を解決するために、通常、地理的に分散したジオクラスターが実行されます。これは、おそらく次の調査の1つになるでしょう。
上記のテクノロジーの実装の技術的な詳細に興味がある場合は、コメントでそれらを共有するか、議論の後に別の記事を作成する準備ができています。