
Nutanixハイパーコンバージドシステムを使用してフォールトトレラントなデータセンターを構築するというトピックは非常に広範囲に及ぶため、先頭にスキップしないようにし、退屈にならないようにするために、2つの部分に分けます。 最初は、理論と「古典的な」複製方法を検討し、2番目は、新しい機能であるいわゆるメトロアベイラビリティ、データセンター間で最大400キロメートルの距離で同期して複製されるメトロクラスター(大都市圏、大都市規模など)を構築する機能です。
今日では、「最初から始めて」、バックアップデータセンターが必要な理由を説明することはすでに非常にまれです。 今日、一方ではデータセンターに保存される情報の量と価値が増大し、他方では、分散データのストレージと処理を整理するための多くのソリューションがより安価で普及しているため、通常、企業がバックアップデータセンターを必要とする理由を説明する必要はなくなりました。 しかし、それがどのようであり、どのように必要であるかを見なければなりません。
Nutanixは、若い企業であり、「ニーズの最先端」で台頭し、バックアップデータセンターと適切な多機能レプリケーションを備えた最新のデータセンターの必要性に直ちに焦点を合わせました。 そのため、すべてのNutanixシステムに付属し、価格に含まれている最年少のライセンス (スターターと呼ばれます)にも、フル機能のレプリケーションツールが既に存在します。 これにより、Nutanixは多くの従来のシステムと区別されます。従来のシステムでは、多くの場合、複製がオプションであり、非常に多くの費用がかかります。
そうではありません。 Nutanixにはすでに双方向非同期レプリケーションがあります。 ちなみに、双方向性は、両方のデータセンターをアクティブ/アクティブモードで使用できるようにします(通常のようにアクティブ予約モードではありません)。
レプリケーション方式の世界では、いわゆる「同期」レプリケーションと「非同期」レプリケーションという2つの基本的な作業原理を区別するのが一般的です。
同期複製は簡単です。 各ディスク書き込み操作は、同じ書き込み操作が転送され、リモートシステムのディスクで完了するまで完了したと見なされません。 データブロックが到着し、ブロックがローカルストレージデバイスのディスクに書き込まれましたが、アプリケーションは「ready、recording!」という応答をまだ受信していません。 その間、データブロックはリモートシステムに転送され、このブロックの記録プロセスが開始されました。 そして、ブロックがリモートシステムに記録された後でのみ、成功を報告し、システムはブロックが記録されたアプリケーション、ローカルの最初のシステムに記録の完了を通知します。

同期レプリケーションの利点は明らかです。 データは、できる限り安全な方法でローカルおよびリモートシステムに書き込まれます;バックアップデータセンターのコピーは、ローカルデータセンターのコピーと常に完全に同一です。 ただし、マイナスはありますが、マイナスではありますが、巨大です。
同期レプリケーションで接続された2つのシステムがある場合、アプリケーションのローカルのアクティブなシステムの速度は、ローカルシステムとリモートシステム間のデータチャネルの速度に等しくなります。 リモートシステムが書き込み用のデータブロックを受信して書き込むまで、ローカルシステムは待機するためです。 アプリケーションからローカルシステムのディスクに16G FCがあり、ローカルシステムからリモートに-複数のルーターを介したプロバイダーのチャネルを介した1GBイーサネットの場合、ローカルディスクへの書き込みはこのギガビットイーサネットチャネルの速度を超えません。
このオプションが自分に合わない場合は、非同期複製を検討する必要があります。
それどころか、非同期レプリケーションには多くの欠点がありますが、1つプラスです。 でも大きい。 :)
非同期複製では、リモートシステムの状態に関係なく、ローカルデバイスのドライブで記録が行われ、確立された頻度で、それらはこのリモートシステムに転送され、操作ではなく単にローカルデータソースシステムのドライブの状態をコピーします。 これは、パフォーマンスとチャネル使用率の点でより有益です。 多くの場合、たとえば、アプリケーションがアクティブなデータ領域を常に読み取り、変更する場合、数百および数千の連続した変更よりも、結果を1回転送する方がはるかに簡単です。 悲しいことに、これは、非同期コピーが厳密に言えばアクティブシステムのデータに完全に対応することはなく、レプリケーションサイクルを要する数分間は常に遅れているという事実を伴う大きなプラスです。
ただし、実際には、非同期複製が広く使用されています。 「コピーの不正確さ」をどうするか? まず最初に、システムの書き込みパフォーマンスと低レイテンシ値は、15分間のデータ変更が失われる可能性よりも重要であると考えて評価できます(そして頻繁に起こります)。 または、すべてのアプリケーションの一般的な非同期レプリケーションに加えて、一般的なデータストレージではなく、特定のアプリケーションのレベルでデータ保護の手段を使用します(たとえば、Microsoft製品にあるさまざまなツール、MS Exchangeの可用性グループ、または同様のツールMS SQL Server)。
基本的に、Nutanixはここで新しいものを発明しませんでした。 Nutanixシステムでは、いわゆるMetro Availabilityが実装されている同期と、あるDCのNutanixクラスタから別のDC(通常は別のDC)への非同期レプリケーションの両方があります。 非同期複製はディスクストレージの「スナップショット」を転送することで行われますが、同期複製はもう少し複雑で奇妙です。
いくつかの用語の引用についてのいくつかの言葉。
「クラスター」という言葉は、今日では誰もが連続して使用しているため、誤解ではないにしても、ある程度の困難につながる可能性があります。 実際、今日のIT業界では、「クラスター」という言葉は、本質的に非常に異なるものだけでなく、主に高可用性を提供する構造にも適用されます。 そして、多くの場合、「クラスター」という言葉は正確に「HAクラスター」のみを意味するために使用されます。
これは常にそうではありません。
まず、「クラスター」とは何ですか?
クラスターは、いくつかの要素を組み合わせて、高次の特定の一般的なエンティティに組み込み、独立したユニットとして既存および管理します。 ご覧のとおり、この定義ではフォールトトレランスについては何もありません。 存在する場合と存在しない場合があり、クラスターは常に「HAクラスター」とは限りません。
「Nutanixクラスターのノードをさまざまなサイトに分散させることはできますか?信頼性があるでしょうか?」という質問にしばしば答えなければなりません。
ここでの答えは次のとおりです:理論上-はい、もちろん、サイトを介したクラスタ内通信のために10Gチャネルのペアを拡張する必要があることを忘れないでください。しかし、これは今日でも可能です) 「あなた自身はしたくない。」 なんで?
類推のために、NutanixクラスタはFCアレイ接続アレイ内のディスクのグループであると想像してみましょう。 ここにサイトAがあり、その上にJBODシェルフがあり、その中にFCにダースのドライブがあり、サイトBに同じシェルフとダースのドライブがあり、すべて共有FCネットワークに含まれています。 そして、これら20個のディスクすべてからRAID-5または6にRAIDグループを作成することにしました。原則として、理論的には、できません。 各JBODは、個別のFCデバイス、マージと見なされます。 しかし、質問はRAIDに何が起こるかです。掘削機が私たちを通り抜けると、サイト間のネットワークに何かが起こりますか?
良いものはありません。 参加者の半分、または少なくとも3分の1が一度に失われても、RAID、または同様の状況ではNutanixクラスターに耐えられない可能性が高いでしょう。
そのため、クラスターやNutanixについてユーザーと話すときは、混乱を最小限に抑える必要があります。ここでは、「Nutanixクラスター」と言い、ここで「クラスター」とは「VMware HA-cluster」を意味し、Real Application Cluster(RAC )Oracleデータベース。 そして、これらはすべて異なるクラスターであり、多くの場合、上下に階層的に配置され、これは完全に正常です。
したがって、フォールトトレランスを確保するために、サイトの1つのNutanixクラスターのノードを分散させることはできません。 しかし、1つのサイトにある「Nutanixクラスター」のノードを別のサイトに他の(「Nutanixクラスター」)ノードに配置し、それらを必要な方向、例えばメインDCからバックアップ、本社から支店に複製された関係に結合することができます(およびその逆)、または完全に両方向です。
さらに、それが「同期」メトロクラスターである場合、そのような同期複製クラスターのペアの上に、理想的には最大400キロメートルの距離に配置できることを思い出します(または、技術用語を話すと、IPサイト間で往復する必要があります)パッケージは5ミリ秒を超えませんでした)、このメトロペアの上に1つの VMwareクラスターを作成できます。 その中に、作成するDRSポリシーに従って、仮想マシンが共通の単一ディスクストレージとして再起動および移行されます。 しかし、これについては次のシリーズで詳しく説明します。
あるサイトから別のサイトへの非同期データ複製では、Nutanixは内部Vmcaliberスナップショットメカニズムを使用します。 これらを使用すると、ディスクコンテナボリュームのコンテンツの一種である差分部分のみが、2つのサイト間のデータチャネルを介して送信されます。 前の送信からの差分はソースシステムから取得され、リモート複製受信サイトに送信され、そこでロールされます。 現在、Nutanixの非同期複製の送信間隔は15分です。 つまり、最悪の場合、失われる可能性があるデータはわずか15分ですが、同期レプリケーションとは異なり、プロセスはパフォーマンスを低下させず、データを操作する際の遅延を増加させません。
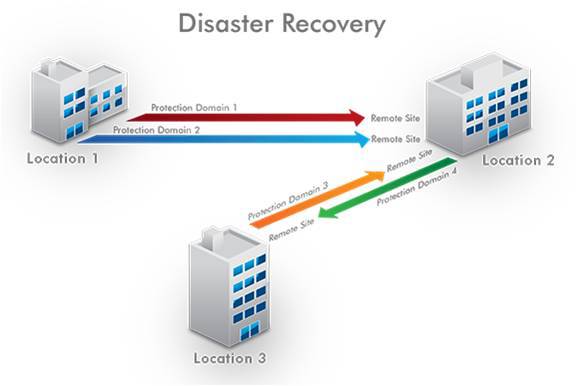
したがって、DRサイトで15分ごとにメインシステムのディスクの差分が残され、そこで関連性を維持しながら自動的に拡張およびロールされます。 「メイン」DCでシステムを失うと、最悪の場合、15分でデータの変更が失われます。
しかし、15分のラグが長すぎて、同期レプリケーションが必要な場合はどうでしょうか。
これを行うには、次の投稿である技術Metro Availabilityを使用できます。