まず、すべてのユーザーIDをダウンロードするのは非常に簡単です。有効なIDのリストはVKontakteユーザーディレクトリにあります。 私たちのタスクは、指定された深さに応じて、選択されたユーザーIDの友人とその友人のリストを再帰的に任意の深さで取得することです。
この記事で公開されているコードは時間とともに変化するため、 Githubの同じプロジェクトで最新バージョンを見つけることができます。
実装方法:
- 必要な深さを設定します
- ソースデータまたは特定の深さで探索する必要があるIDを送信します
- 答えを得る
使用するもの:
- Python 3.4
- VKのストアドプロシージャ
必要な深さを設定します
最初に必要なのは、作業の深さを示すことです。 settings.pyですぐにこれを行うことができます :
deep = 2 #
深い 1に等しい私たちの友人、2は私たちの友人の友人などです。 その結果、キーがユーザーIDで、値が友人のリストである辞書を取得します。
急いで大きな深度を設定しないでください。 私の元の友人が14人、深さが2の場合、辞書のキーの数は2427でした。深さが3の場合、スクリプトの動作が完了するのを待つ忍耐がありませんでした。その時点で辞書は223,908のキーをカウントしました。 このため、頂点がキーになり、エッジが値になるため、このような巨大なグラフは視覚化しません。
データを送信する
必要な結果を得るには、既知のfriends.getメソッドが役立ちます。これは、次の形式のストアドプロシージャに配置されます。
var targets = Args.targets; var all_friends = {}; var req; var parametr = ""; var start = 0; // while(start<=targets.length){ if (targets.substr(start, 1) != "," && start != targets.length){ parametr = parametr + targets.substr(start, 1); } else { // , id req = API.friends.get({"user_id":parametr}); if (req) { all_friends = all_friends + [req]; } else { all_friends = all_friends + [0]; } parametr = ""; } start = start + 1; } return all_friends;
ストアドプロシージャはアプリケーション設定で作成でき、 実行のようにVkScriptで記述され、ドキュメントはこことここで読むことができます 。
次に、その仕組みについて説明します。 カンマで区切られた25のIDの文字列を取得し、1つのIDを取得してfriends.getにリクエストを送信すると、必要な情報が辞書に格納されます。キーはidで、値はこのidのフレンドリストです。
最初の起動時に、ストアドプロシージャに現在のユーザーの友人のリストを送信します。このユーザーのIDは設定で指定されています。 リストはいくつかの部分に分割されます(N / 25はリクエストの数です)。これは、VKontakte APIの呼び出し数の制限によるものです。
応答を受け取る
受信したすべての情報は、たとえば次のような辞書に保存されます。
{1:(0, 2, 3, 4), 2: (0, 1, 3, 4), 3: (0, 1, 2)}
キー1、2、および3は、深さ1で取得されました。これらはすべて、指定されたユーザー(0)の友達であると想定します。
深さが1より大きい場合、セットの差を使用します。最初のセットは辞書の値で、2番目のセットはキーです。 したがって、キーにないID(この場合は0と4)を取得し、それらを再び25の部分に分割して、ストアドプロシージャに送信します。
その後、2つの新しいキーが辞書に表示されます。
{1:(0, 2, 3, 4), 2: (0, 1, 3, 4), 3: (0, 1, 2), 0: (1, 2, 3), 4:(1, 2, ….)}
deep_friends()メソッド自体は次のようになります。
def deep_friends(self, deep): result = {} def fill_result(friends): for i in VkFriends.parts(friends): r = requests.get(self.request_url('execute.deepFriends', 'targets=%s' % VkFriends.make_targets(i))).json()['response'] for x, id in enumerate(i): result[id] = tuple(r[x]["items"]) if r[x] else None for i in range(deep): if result: # , + id:None fill_result(list(set([item for sublist in result.values() if sublist for item in sublist]) - set(result.keys()))) else: fill_result(requests.get(self.request_url('friends.get', 'user_id=%s' % self.my_id)).json()['response']["items"]) return result
もちろん、これは、ストアドプロシージャを使用せずにfriends.get oneで1つのidをスローするよりも高速ですが、それでも多くの時間がかかります。
friends.getがusers.getに似ている場合 、つまり、 user_idsをパラメーターとして使用できます。つまり、idを1つだけではなく、友達のリストを返す必要があるコンマで区切られたidを使用できます。要求の数は何倍も少なかった。
遅すぎる
記事の最初に戻って、繰り返しますが、非常にゆっくりです。 ストアドプロシージャは保存されません。alxpyマルチスレッドソリューション(彼の貢献と参加に感謝
igrishaevから賢明なアドバイスを受けました -何らかのマップリデューサーが必要です。
実際、VKontakteはexecuteを介して25のAPIリクエストを許可しているため 、異なるクライアントからリクエストを行う場合、有効なリクエストの数を増やすことができます。 5台の手押し車-これは1秒あたり125リクエストです。 しかし、これはそうではありません。 将来を見据えて、それは可能であり、さらに高速であると言えます。(各マシンで)次のようになります。
while True: r = requests.get(request_url('execute.getMutual','source=%s&targets=%s' % (my_id, make_targets(lst)),access_token=True)).json() if 'response' in r: r = r["response"] break else: time.sleep(delay)
エラーメッセージを受け取った場合は、指定された秒数後に再度リクエストを行います。 この手法はしばらくは機能しますが、VKontakteはすべての応答でNoneの送信を開始するため、各リクエストの後に正直に1秒待機します。 これまで。
次に、新しいツールを選択するか、独自の計画を作成して計画を実行する必要があります。 その結果、水平方向にスケーラブルなシステムを取得する必要があります。仕事の原理は次のように思えます。
- メインサーバーは、クライアントからVKontakte IDとオペレーションコードを受け取ります。すべての一般的な友人を引き出すか、指定された深さの友人のリストを再帰的に調べます。
- さらに、どちらの場合でも、サーバーはVKontakte APIにリクエストを送信します。ユーザーのすべての友達のリストが必要です。
- ストアドプロシージャの機能を最大限に活用するためにすべてが完了しているため、ここでは、友人のリストをそれぞれ25の連絡先に分割する必要があります。 実際、75。これについては少し低い。
- メッセージブローカーを使用して多くのパーツを取得し、各パーツを特定の受信者(プロデューサー-コンシューマ)に配信します。
- 受信者は連絡先を受け入れ、すぐに要求を行い、結果をサプライヤーに返します。 はい、RPCについて正しく考えました。
そして、あなたがこの絵を見たなら、あなたは私がほのめかしているメッセージブローカーを理解します。
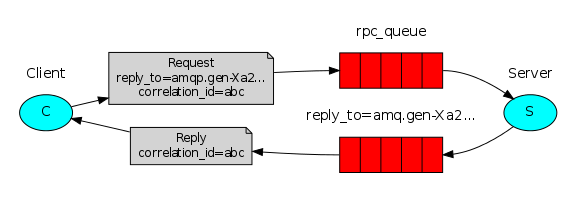
すべての回答が受け入れられると、それらを1つにまとめます。 さらに、結果を画面に表示するか、完全に保存することができます。詳細については、後で説明します。
コードが変更されることは注目に値します。プロジェクトの前のバージョンを使用する必要がある場合は、変更されませんでした。 以下のコードはすべて、新しいリリース用です。
RabbitMQをメッセージブローカー、 Celery 、非同期分散タスクキューとして使用します 。
それらに遭遇したことがない人のために、私はあなたが読むことをお勧めする資料へのいくつかの有用なリンクがあります:
セロリ
理解することを恐れないでください。「1台のコンピューターではなく、複数のコンピューターで考える」ときに頭を回すことができると言われていますが、そうではありません。
著者などのMacを使用している場合、 RabbitMQは Homebrewを使用してスマートにインストールされます。
brew update brew install rabbitmq
3番目のPythonブランチを使用すると、 Celeryはさらに簡単になります。
pip3 install Celery
Linux MintにCeleryを 、MacにRabbitMQをインストールしています。 Windowsでは、いつものように、問題
次に、 仮想ホストを作成し、ユーザーに権限を付与します。
rabbitmqctl add_vhost vk_friends rabbitmqctl add_user user password rabbitmqctl set_permissions -p vk_friends user ".*" ".*" ".*"
RabbitMQ構成では、インストール先のホストのIPを指定する必要があります。
vim /usr/local/etc/rabbitmq/rabbitmq-env.conf NODE_IP_ADDRESS=192.168.1.14 //
ここにいくつかの可能な構成がありますが、どれを選択するか-あなたが決めます。
ルーターなどがある場合は、 RabbitMQが5672ポートを使用していることを知っておくと、デバイスの設定をリダイレクトできます。 ほとんどの場合、テストすると、異なるマシンにワーカーが分散し、ブローカーを使用する必要があります。ネットワークを正しくセットアップしないと、 Celeryは RabbitMQに到達しません 。
非常に良いニュースは、VKontakteを使用すると、1つのIDから1秒あたり3つのリクエストを作成できることです。 これらのリクエストにVKontakte APIの可能な呼び出し数(25)を掛けると、1秒あたりの処理済み連絡先の最大数(75)が得られます。

多くの労働者がいる場合、許容限度を超えて移動し始めるときが来ます。 したがって、 トークン変数( settings.py内 )は、異なるIDを持つ複数のトークンを含むタプルになります 。 スクリプトは、VKontakte APIへの各リクエストで、ランダムにそれらのいずれかを選択します。
def request_url(method_name, parameters, access_token=False): """read https://vk.com/dev/api_requests""" req_url = 'https://api.vk.com/method/{method_name}?{parameters}&v={api_v}'.format( method_name=method_name, api_v=api_v, parameters=parameters) if access_token: req_url = '{}&access_token={token}'.format(req_url, token=random.choice(token)) return req_url
この点で、VKontakteに複数のアカウントを持っている場合(友人や家族に負担をかけることができます)、4トークンと3ワーカーで問題はありませんでした。
いいえ、 time.sleep() 、またはwhileを使用した上記の例を使用することを誰も気にしませんが、エラーメッセージを受信する準備をします(通常は空の回答が可能です-id :None)、またはもっと長く待ちます。
call.pyファイルから最も興味深いもの:
def getMutual(): all_friends = friends(my_id) c_friends = group(mutual_friends.s(i) for i in parts(list(all_friends[0].keys()), 75))().get() result = {k: v for d in c_friends for k, v in d.items()} return cleaner(result) def getDeep(): result = {} for i in range(deep): if result: # , + id:None lst = list(set([item for sublist in result.values() if sublist for item in sublist]) - set(result.keys())) d_friends = group(deep_friends.s(i) for i in parts(list(lst), 75))().get() result = {k: v for d in d_friends for k, v in d.items()} result.update(result) else: all_friends = friends(my_id) d_friends = group(deep_friends.s(i) for i in parts(list(all_friends[0].keys()), 75) )().get() result = {k: v for d in d_friends for k, v in d.items()} result.update(result) return cleaner(result)
ご覧のとおり、2つの関数でgroups()を使用します。これはいくつかのタスクを同時に実行し、その後、答えを「接着」します。 deep_friends()が最初をどのように見ていたか覚えています(非常に古い例があります-マルチスレッドがなくても)。 意味は同じままです-セットの違いを使用します。
そして最後に、 tasks.py 。 いつかこれらの素晴らしい機能は一つに統合されます:
@app.task def mutual_friends(lst): """ read https://vk.com/dev/friends.getMutual and read https://vk.com/dev/execute """ result = {} for i in list(parts(lst, 25)): r = requests.get(request_url('execute.getMutual', 'source=%s&targets=%s' % (my_id, make_targets(i)), access_token=True)).json()['response'] for x, vk_id in enumerate(i): result[vk_id] = tuple(i for i in r[x]) if r[x] else None return result @app.task def deep_friends(friends): result = {} for i in list(parts(friends, 25)): r = requests.get(request_url('execute.deepFriends', 'targets=%s' % make_targets(i), access_token=True)).json()["response"] for x, vk_id in enumerate(i): result[vk_id] = tuple(r[x]["items"]) if r[x] else None return result
すべてが設定されたら、次のコマンドでRabbitMQを実行します。
rabbitmq-server
次に、プロジェクトフォルダーに移動し、ワーカーをアクティブにします。
celery -A tasks worker --loglevel=info
さて、一般的なまたは「深い」友達のリストを取得して保存するには、コンソールでコマンドを実行するだけです:
python3 call.py
測定結果について
最初のパートで私にインスピレーションを与えた記事の著者である343人の友人 (共通の友人へのリクエスト)は119秒で「処理」されたことを思い出させてください。
前の記事からの私のバージョンは9秒で同じことをしました。
作成者の友人の数は308になりました。最後の8つのIDに対して追加の要求を1つ行い、貴重な1秒を費やす必要がありますが、同じ1秒で75 IDを処理できます。
ワーカーが1人の場合、スクリプトには4.2秒かかり 、ワーカーは2人-2.2秒かかりました 。
119が120に丸められ、2.2が2に丸められると、私のオプションは60倍速くなります。
「深い友達」(私の友達の友達など+待機時間を減らすために別のIDでテストする)については、深さ2で、辞書のキーの数は1,251でした。
記事の冒頭に記載されているコードの実行時間は17.9秒です。
ワーカーが1人の場合、スクリプトの実行時間は15.1秒で 、ワーカーは8.2秒です。
したがって、 deep_friends()は約2.18倍高速になりました 。
はい、結果は必ずしもそれほどバラ色ではありません.VKontakteでの1つの要求に対する回答は、10秒と20秒待機する必要がある場合があります(ただし、1つのタスクの頻繁な実行時間は1.2-1.6 秒です )。これはおそらく、サービスの負荷によるものです。宇宙だけではありません。

結果として、より多くのワーカーを実行すればするほど、結果はより速く処理されます。 ハードウェアのパワー、追加のトークン、ネットワーク(たとえば、作成者がiPhoneをアクセスポイントとして使用したときにスクリプトの実行時間を大幅に延長した)などの要素を忘れないでください。
結果を保存する
はい、多くのグラフ指向データベースがあります。 将来的に(そしてそうなる場合)、得られた結果を分析し、分析自体までそれらをどこかに保存する必要がある場合は、これらの結果をメモリにアンロードし、いくつかのアクションを実行する必要があります。 プロジェクトが商業的である場合、どのような種類のsubdを使用しても意味がありません。たとえば、特定のユーザーのグラフがどうなるか興味があります。はい、グラフ指向のデータベースがここで必要ですが、「ホームコンディション」の分析に従事するため「 ピクルスで十分です。
辞書を保存する前に、値がNoneであるキーを削除することは論理的です。 これらはブロックまたは削除されたアカウントです。 簡単に言えば、これらのidは他の誰かがそれらを友人に持っているので、グラフに存在しますが、辞書のキーの数を節約します:
def cleaner(dct): return {k:v for k, v in dct.items() if v != None} def save_or_load(myfile, sv, smth=None): if sv and smth: pickle.dump(smth, open(myfile, "wb")) else: return pickle.load(open(myfile, "rb"))
ご覧のとおり、結果をどこかに保存した場合は、IDを再度収集しないように、どこかに結果をロードする必要があります。
グラフ分析
あなたの自転車を書かないために、かなりよく知られているnetworkxを使用します。これは、すべての
pip3 install networkx
グラフの分析を始める前に、グラフを描きます。 networkxには、このためにmatplotlibが必要です。
pip3 install matplotlib
次に、グラフ自体を作成する必要があります。 一般的に、2つの方法があります。
1つ目は、大量のRAMと時間を消費します。
def adder(self, node): if node not in self.graph.nodes(): self.graph.add_node(node) self.graph = nx.Graph() for k, v in self.dct.items(): self.adder(k) for i in v: self.adder(i) self.graph.add_edge(k, i)
そして、これは心から生き残った著者ではありません。 同様の例が、ライス大学のページの見出し「 ディクショナリグラフ表現をnetworkxグラフ表現に変換」で提供されています 。
def dict2nx(aDictGraph): """ Converts the given dictionary representation of a graph, aDictGraph, into a networkx DiGraph (directed graph) representation. aDictGraph is a dictionary that maps nodes to its neighbors (successors): {node:[nodes]} A DiGraph object is returned. """ g = nx.DiGraph() for node, neighbors in aDictGraph.items(): g.add_node(node) # in case there are nodes with no edges for neighbor in neighbors: g.add_edge(node, neighbor) return g
私の言葉を聞いてください。グラフは夜中に作成されていたのに、すでに300,000を超えるピークがあったので、私の忍耐は断ち切れました。
はい、有向グラフの例が示されていますが、本質は同じままです-最初にキーを追加して頂点にし、頂点の値を作成し、次にグラフにまだない場合はエッジに接続します(私のバージョンでは)。
そして、2番目の方法はすべてを数秒で行います:
self.graph = nx.from_dict_of_lists(self.dct)
コードはgraph.pyファイルにあり、相互の友人のグラフを描画するには、このスクリプトを実行するか 、 VkGraph()クラスのインスタンスをどこかに作成してから、そのdraw_graph()メソッドを呼び出します。
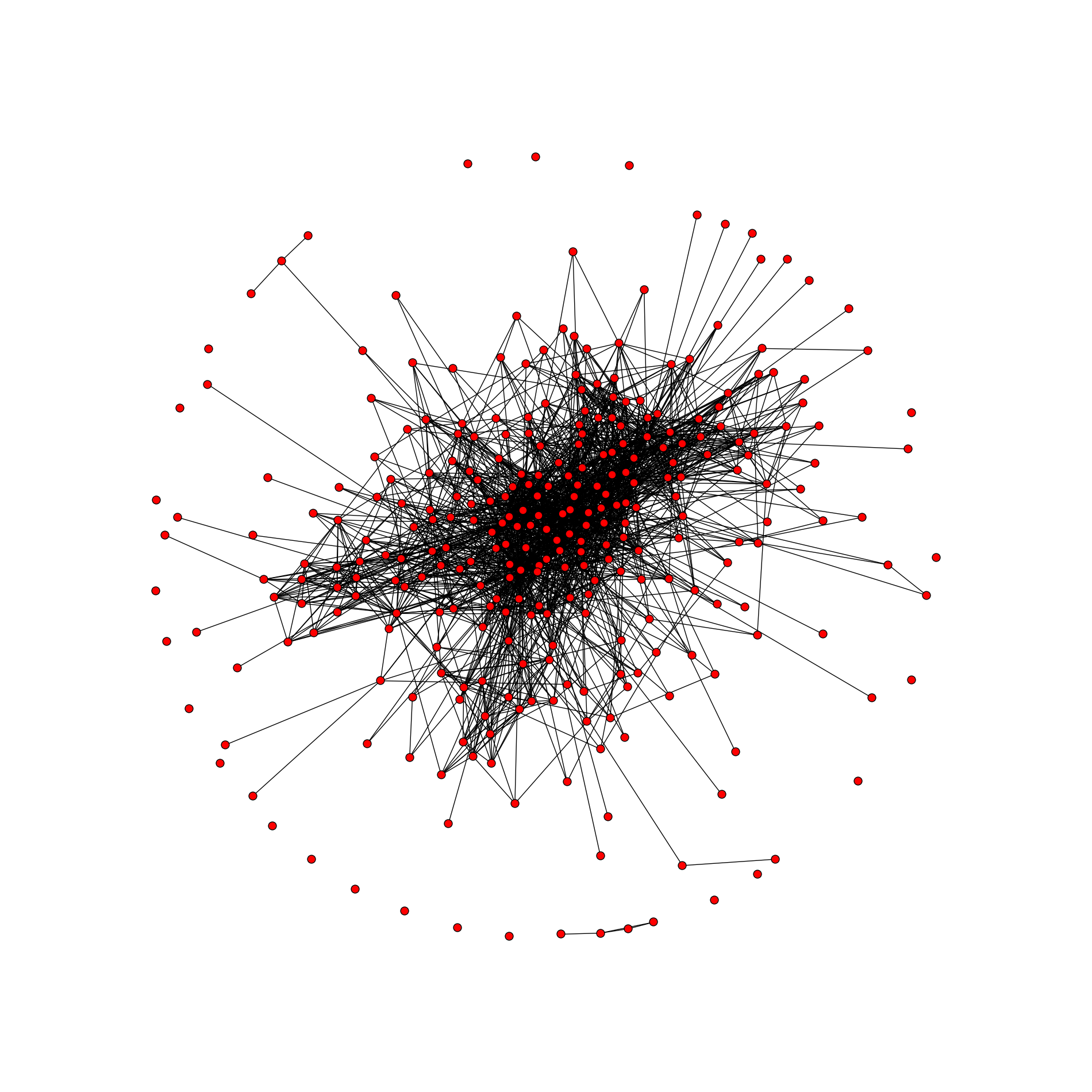
これは、合計306のピークと2096のrib骨を持つ、共通の友人のグラフです。 残念ながら、私はデザイナーになったことはありません(ほとんどすべての設定が標準です)が、グラフのスタイルはいつでも「自分用」にすることができます。 以下にいくつかのリンクを示します。
そして、メソッド自体は次のようになります。
def draw_graph(self): plt.figure(figsize=(19,19), dpi=450,) nx.draw(self.graph, node_size=100, cmap=True) plt.savefig("%s graph.png" % datetime.now().strftime('%H:%M:%S %d-%m-%Y'))
その結果、プロジェクトフォルダーにpicture date graph.pngが表示されます。 深い友人のためにグラフを描くことはお勧めしません。 308人の友人と2の深さで、辞書は145,000以上のキーであることが判明しました。 しかし、値もあります-idを持つタプルは、小さいとは考えられません。
長い間、私はVKontakteで最も目立たない友人のプロフィールを探していましたが、ここでより重要なのは友人と友人です。 最初の10人の友人(そのうち1人はブロックされ、自動的に削除されます)、標準の深さ(2)で、辞書には1234キーと517 174 id(値から)がありました。 約419人の友人が1つのIDを持っています。 はい、そこには一般的な友人がいます。グラフを作成するときに、これを理解します。
deep_friends = VkGraph(d_friends_dct) print(' :', deep_friends.graph.number_of_nodes()) print(' :', deep_friends.graph.number_of_edges())
戻ります:
: 370341 : 512949
このようなビッグデータがあれば、いろいろ試してみるといいでしょう。 Networkxには、グラフに適用できるアルゴリズムの非常に大きなリストがあります。 それらのいくつかを分析します。
接続グラフ
まず、接続されたグラフがあるかどうかを判断しましょう。
print(' ?', nx.is_connected(deep_friends.graph))
接続グラフは、頂点のペアがルートで接続されているグラフです。
ところで、深さが1の同じidには、1268の頂点と1329のエッジを含むこのような美しいグラフがあります。
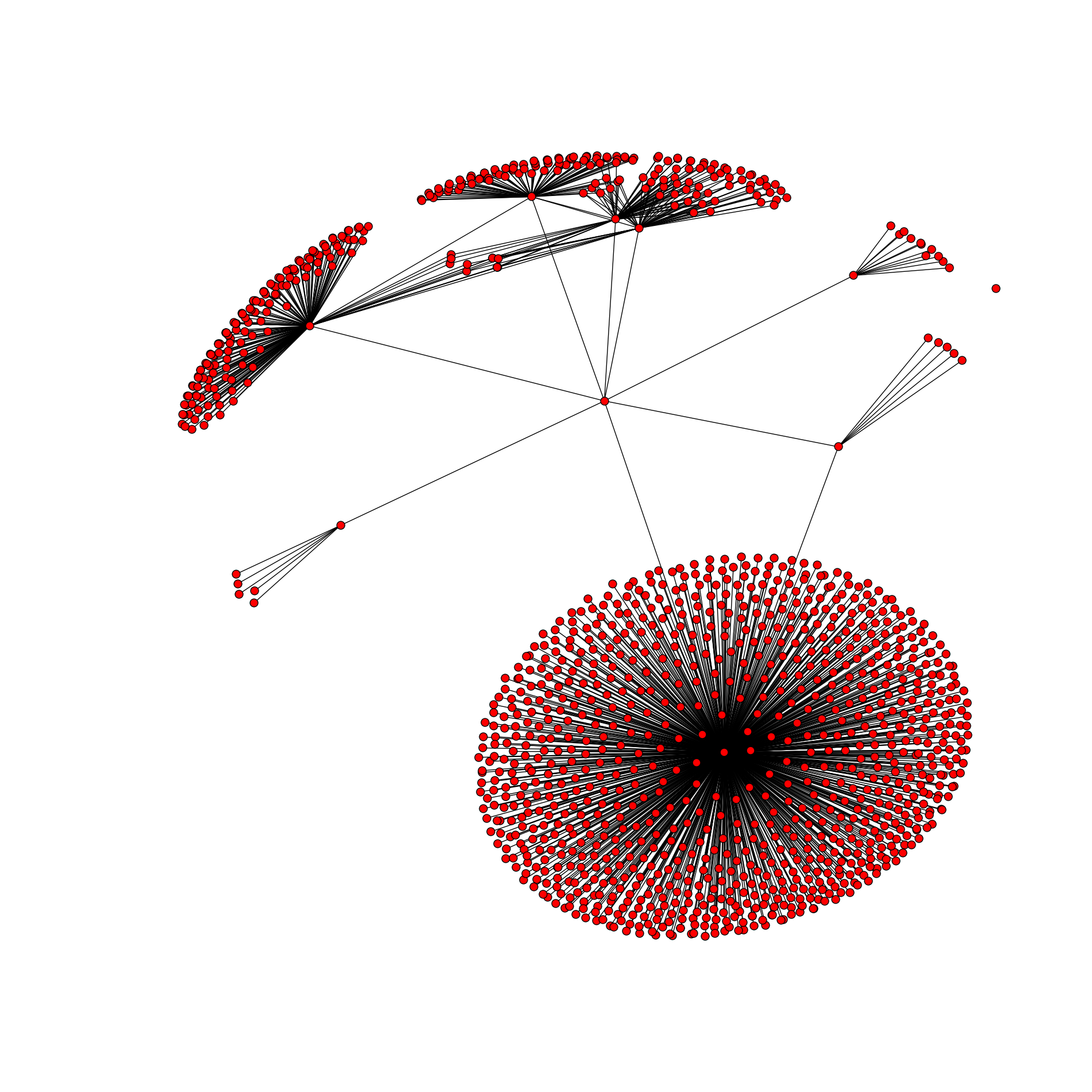
愛好家への質問。 友人と友人のグラフを取得するため、何らかの方法で接続する必要があります。 既存のピークに接続されていないピークがどこからともなく現れることはあり得ません。 ただし、右側には、どの頂点にも接続されていない頂点が1つあります。 なんで? 最初に考えてください。真実を知ることはもっと面白いでしょう。
正解
それを理解しましょう。 まず、友人のリストを取得します。IDXがあることがわかります。そのため、グラフは一貫性がありません。 次に、このXの友人にリクエストを行います(結局のところ)。 Xがすべての友人を非表示にしている場合、辞書にエントリがあります。
グラフが作成されると、正直に頂点Xを追加しますが、エッジはありません。 はい、純粋に理論的には、頂点Xにはsettings.pyでidが指定された頂点を持つエッジが必要ですが、注意深く読んでください-辞書にあるものだけを追加します。 したがって、深さが2の場合、設定で指定された辞書IDが取得されます。 そして、頂点Xにエッジがあります。
{X:(), ...}
グラフが作成されると、正直に頂点Xを追加しますが、エッジはありません。 はい、純粋に理論的には、頂点Xにはsettings.pyでidが指定された頂点を持つエッジが必要ですが、注意深く読んでください-辞書にあるものだけを追加します。 したがって、深さが2の場合、設定で指定された辞書IDが取得されます。 そして、頂点Xにエッジがあります。
このような状況は発生しないと想定しています。つまり、ほとんどの場合Trueが表示されます 。
直径、中心および半径
グラフの直径は、 2つの頂点間の最大距離であることを思い出してください。
print(' :', nx.diameter(deep_friends.graph))
グラフの中心は、頂点から最も遠い頂点までの距離が最小になるような頂点です。 グラフの中心は、1つの頂点または複数の頂点です。 または簡単。 グラフの中心は、離心率(この頂点から最も遠い頂点までの距離)が半径に等しい頂点です。
print(' :', nx.center(deep_friends.graph))
グラフの中心にある頂点のリストを返します。 中心がsettings.pyで指定されたIDであっても驚かないでください。
グラフの半径は、すべての頂点の最小の離心率です。
print(' :', nx.radius(deep_friends.graph))
機関またはページランク
これはあなたが考えたのと同じページランクです。 原則として、アルゴリズムはWebページまたはリンクでリンクされた他のドキュメントに使用されます。 ページへのリンクが多いほど、重要です。 しかし、グラフにこのアルゴリズムを使用することを禁止する人はいません。 この記事から、より正確で適切な定義を借用します。
ソーシャルグラフの権限は、さまざまな方法で分析できます。 最も簡単な方法は、参加者を着信エッジの数でソートすることです。 より多くを持っている人はより権威があります。 この方法は、小さなグラフに適しています。 インターネット検索では、Googleはページの信頼性の基準の1つとしてPageRankを使用します。これは、ノードがページであるグラフをランダムにさまようことによって計算され、ノード間のエッジは、あるページが別のページにリンクしている場合です。ランダムウォーカーはグラフ上を動き回り、時々ランダムノードに移動して、再び歩き始めます。PageRankは、放浪期間全体にわたって、あるノードに滞在する割合に等しくなります。大きいほど、ノードの信頼性は高くなります。
import operator print('Page Rank:', sorted(nx.pagerank(deep_friends.graph).items(), key=operator.itemgetter(1), reverse=True))
クラスタリング係数
ウィキペディアの引用:
クラスタリング係数は、特定の個人に関連付けられた2人の異なるユーザーが接続される確率の度合いです。
print(' ', nx.average_clustering(deep_friends.graph))
ご覧のとおり、複雑なことは何もありません。また、networkxはグラフに適用できるさらに多くのアルゴリズム(著者は148を数えました)を提供します。必要なアルゴリズムを選択し、graph.pyファイルで適切なメソッドを呼び出すだけです。
まとめ
私たちは、分散システムは、それが提案されているよりも、(勤労者の数に応じて)あなたは60倍高速に動作VKontakte、で共通の友人カウントを構築することができなかったバージョンのHimura全て「深い友人」を要求するために、分析する能力を追加- 、また、新しい機能を実装します構築されたグラフ。
追加のソフトウェアをインストールしたくない場合で、前の記事の共通の友人の美しいグラフを作成する必要がある場合は、古いリリースがあなたのサービスにあります。その中には、ユーザーの友達リストを任意に深く再帰的に取得する古いバージョンもあります。
これは制限ではなく、プログラムの速度を上げ続けます。
特にデータの視覚化に関与している場合は、プルリクエストをプルするのを待っています。 ご清聴ありがとうございました!