
はじめに
あまり安定していない精神を持つ人として、このような写真を見れば、パニック発作を始めるのに十分です。 しかし、私は自分だけに苦しむことにしました。 この記事の目的は、Hadoopがそれほど怖く見えないようにすることです。
この記事の内容:
- フレームワークの構成要素とその必要性を分析します。
- 簡単なクラスター展開の問題を調べます。
- 特定の例を見てください。
- Hadoop 2の新機能(Namenode Federation、Map / Reduce v2)について少し触れます。
この記事には含まれないもの:
- したがって、一般的なレビュー記事、難なく;
- 生態系の微妙なところに行かないようにしましょう。
- APIのジャングルを深く掘り下げないでください。
- devopsの問題に関するすべてを検討するわけではありません。
Hadoopとは何か、なぜ必要なのか
Hadoopはそれほど複雑ではなく、カーネルはHDFSファイルシステムと、このファイルシステムからのデータを処理するMapReduceフレームワークで構成されています。
「なぜHadoopが必要なのか」という質問を見ると、大企業での使用という観点から多くの答えがあり、それらは「強く」から「非常に反対」までさまざまです。 ThoughtWorksの記事をご覧になることをお勧めします。
技術的な観点から同じ質問を見ると、Hadoopを使用する必要があるタスクについては、ここもそれほど単純ではありません。 マニュアルでは、まず、単語数とログ分析という2つの主要な例を理解します。 さて、単語数またはログ分析がない場合はどうなりますか?
また、何とか簡単に答えを決定するのもいいでしょう。 たとえば、SQL-構造化されたデータが大量にあり、実際にデータとやり取りしたい場合に使用する必要があります。 未知の性質と形式の前に、できるだけ多くの質問をしてください。
長い答えは、多数の既存のソリューションを調べて、Hadoopが必要な条件をサブ皮質で暗黙的に収集することです。 ブログを調べてみてください。MahmoudParsianの著書Data Algorithms:Recipes for Scaling up with Hadoop and Sparkを読むこともお勧めします。
簡単に答えようとします。 Hadoopは次の場合に使用する必要があります。
- 計算は構成可能である必要があります。つまり、データのサブセットで計算を実行し、結果をマージできる必要があります。
- 大量の非構造化データ-1台のマシンに収まらないデータ(数テラバイトを超えるデータ)を処理する予定です。 ここでプラスになるのは、Hadoopの場合にクラスターに汎用ハードウェアを使用できることです。
Hadoopは使用しないでください:
- 非コンポーネントタスクの場合-たとえば、繰り返しタスクの場合。
- データ全体が1台のマシンに収まる場合。 大幅な時間とリソースを節約します。
- Hadoop全体は、バッチ処理用のシステムであり、リアルタイム分析には適していません( Stormシステムがここで役立ちます)。
HDFSアーキテクチャと典型的なHadoopクラスター
HDFSは他の従来のファイルシステムに似ています:ファイルはブロックに保存され、ブロックとファイル名のマッピングがあり、ツリー構造がサポートされ、権利ベースのファイルアクセスモデルがサポートされます。
HDFSの違い:
- 大量の(10GBを超える)ファイルを格納するように設計されています。 1つの結果は、他のファイルシステムと比較して大きなブロックサイズです(> 64MB)
- データへの高ストリーミング読み取りアクセスをサポートするように最適化されているため、ランダムデータ読み取り操作のパフォーマンスが低下し始めます。
- 多数の安価なサーバーの使用に焦点を当てています。 特に、サーバーはRAIDの代わりにJBOB構造(ディスクの束)を使用します。ミラーリングとレプリケーションは、個々のマシンのレベルではなく、クラスターレベルで実行されます。
- 分散システムの従来の問題の多くは設計に組み込まれています。すでにデフォルトでは、個々のノードのすべての障害は完全に正常で自然な動作であり、異常ではありません。
Hadoopクラスターは、NameNode、Secondary NameNode、Datanodeの3種類のノードで構成されています。
Namenodeはシステムの頭脳です。 原則として、クラスターごとに1つのノード(Namenode Federationの場合はそれ以上ですが、この場合は船外に残します)。 すべてのシステムメタデータを保存します-ファイルとブロック間の直接マッピング。 ノード1の場合は、単一障害点でもあります。 この問題は、 Namenode Federationを使用したHadoopの2番目のバージョンで解決されました。
セカンダリNameNode-クラスターごとに1つのノード。 「Secondary NameNode」は、プログラムの歴史の中で最も不幸な名前の1つであると言うのが習慣です。 実際、セカンダリNameNodeはNameNodeのレプリカではありません。 ファイルシステムの状態は、fsimageファイルおよびファイルシステムへの最新の変更を含む編集ログファイルに直接保存されます(RDBMSの世界のトランザクションログと同様)。 セカンダリNameNodeは、fsimageと編集を定期的にマージすることにより機能します-セカンダリNameNodeは、編集のサイズを妥当な制限内に維持します。 セカンダリNameNodeは、NameNodeに障害が発生した場合にNameNodeをすばやく手動で回復するために必要です。
実クラスタでは、NameNodeとセカンダリNameNodeはメモリとハードディスクを必要とする別個のサーバーです。 そして、主張されている「商品ハードウェア」はすでにDataNodeの例です。
DataNode-クラスターにはこのようなノードが多数あります。 ファイルのブロックを直接保存します。 ノードは、NameNodeに定期的にそのステータス(まだ生きていることを示す)および1時間ごとに送信します-レポート、このノードに保存されているすべてのブロックに関する情報 これは、レプリケーションの望ましいレベルを維持するために必要です。
データがHDFSに書き込まれる方法を見てみましょう。
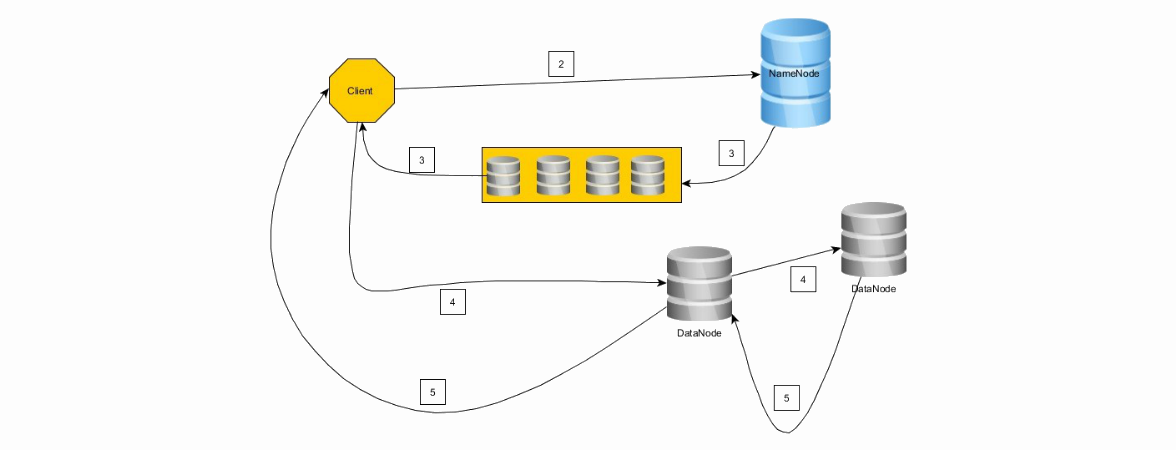
1.クライアントはファイルをブロックサイズのチェーンに分割します。
2.クライアントはNameNodeに接続して書き込み操作を要求し、ブロック数と必要なレベルのレプリケーションを送信します
3. NameNodeは、DataNodeのチェーンで応答します。
4.クライアントはチェーンの最初のノードに接続します(最初のノードでうまくいかなかった場合、2番目のノードなどがまったくうまくいかなかった場合-ロールバック)。 クライアントは、最初のノートに最初のブロックを記録し、2番目に最初のノートを記録し、以下同様に記録します。
5.逆順(4-> 3、3-> 2、2-> 1、1->クライアント)で記録が完了すると、記録の成功に関するメッセージが送信されます。
6.クライアントは、ブロックの正常な記録の確認を受信するとすぐに、NameNodeにブロックの記録を通知し、次にDataNodeのチェーンを受信して2番目のブロックなどを記録します。
クライアントは、ブロックを少なくとも1つのノードに正常に書き込むことに成功した場合、ブロックの書き込みを続行します。つまり、レプリケーションは「最終」のよく知られた原則に従って動作し、将来的にはNameNodeが希望のレベルのレプリケーションを補正して達成します。
HDFSとクラスターのレビューを終えて、Hadoopのもう1つの優れた機能であるラック認識について見ていきます。 NameNodeがどのノードがどのラックにあるかを把握できるようにクラスターを構成することにより、 障害に対する保護を強化できます。
Mapreduce
作業単位は、マップ(並列データ処理)およびリデュース(マップからの結論を組み合わせた)タスクのセットです。 マップタスクはマッパーによって実行され、リデューサーによって削減されます。 ジョブは少なくとも1つのマッパーで構成され、レデューサーはオプションです。 ここでは 、タスクをマップとリデュースに分割する問題について説明します。 「map」と「reduce」という言葉が完全に理解できない場合、このトピックに関する古典的な記事を見ることができます。
MapReduceモデル
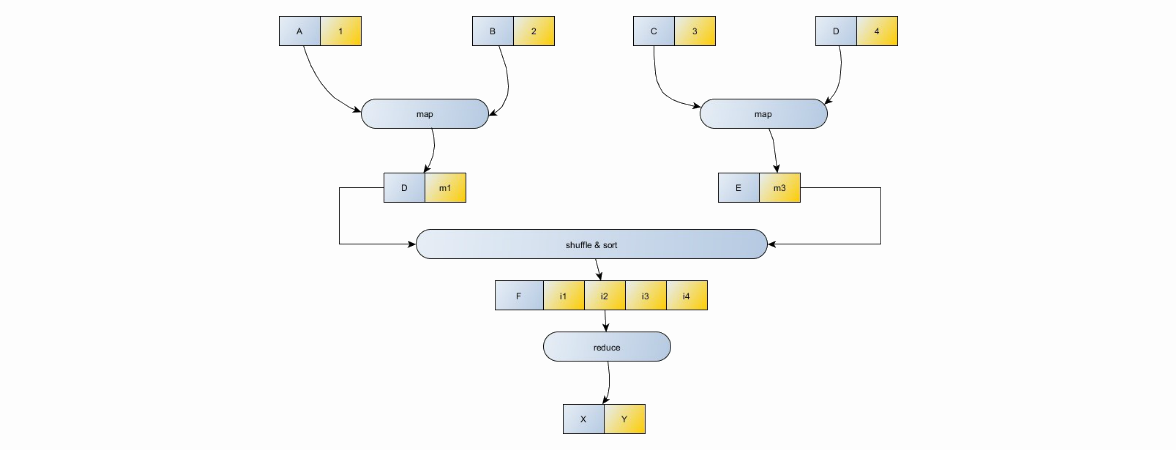
- データの入力/出力はペア(キー、値)の形式で発生します
- 2つのマップ関数が使用されます:(K1、V1)->((K2、V2)、(K3、V3)、...)-キーと値のペアを特定のキーと値の中間セットのセットにマッピングし、さらに削減します:(K1 、(V2、V3、V4、VN))->(K1、V1)、特定の値のセットをマッピングし、共通のキーをより小さな値のセットにマッピングします。
- シャッフルとソートは、レデューサーの入力をキーでソートするために必要です。つまり、値(K1、V1)と(K1、V2)を2つの異なるレデューサーに送信しても意味がありません。 それらは一緒に処理する必要があります。
MapReduce 1のアーキテクチャを見てみましょう。まず、JobTrackerとTaskTrackerという2つの新しい要素をクラスターに追加して、hadoopクラスターの理解を深めます。 JobTrackerはクライアントから直接リクエストし、TaskTrackerでマップを管理/タスクを削減します。 JobTrackerとNameNodeは異なるマシンに分散されていますが、DataNodeとTaskTrackerは同じマシンにあります。
クライアントとクラスターの相互作用は次のとおりです。
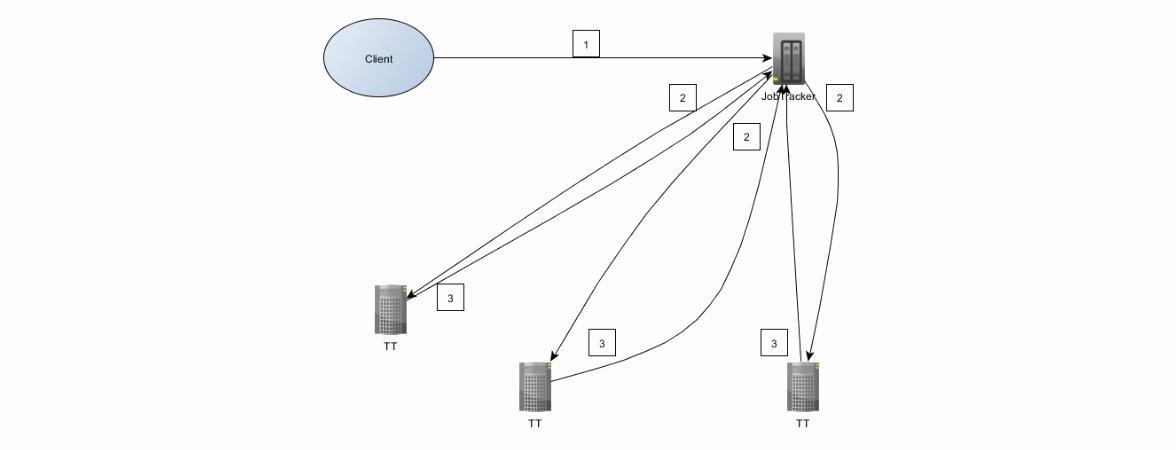
1.クライアントはジョブをJobTrackerに送信します。 ジョブはjarファイルです。
2. JobTrackerは、データの局所性に基づいてTaskTrackerを検索します。 HDFSのデータを既に保存しているものを優先します。 JobTrackerはマップを割り当て、タスクをTaskTrackersに減らします
3. TaskTrackerは、進捗レポートをJobTrackerに送信します。
失敗したタスクの実行-予想される動作、失敗したタスクは他のマシンで自動的に再起動します。
Map / Reduce 2(Apache YARN)はJobTracker / TaskTrackerの用語を使用しなくなりました。 JobTrackerはResourceManager-リソース管理とApplication Master- アプリケーション管理に分けられます(その1つはMapReduceに直接あります)。 MapReduce v2は新しいAPIを使用します
環境設定
市場には、Cloudera、HortonWorks、MapRなど、人気の高いHadoopディストリビューションがいくつかあります。 ただし、特定の分布の選択には焦点を当てません。 分布の詳細な分析については、 こちらをご覧ください 。
Hadoopを無痛で最小限の労力で試すには、2つの方法があります。
1. Amazon Clusterは本格的なクラスターですが、このオプションには費用がかかります。
2.仮想マシンをダウンロードします( マニュアル番号1またはマニュアル番号2 )。 この場合、マイナスはすべてのクラスターサーバーが同じマシン上で回転していることです。
苦しい方法に移りましょう。 Windows上のHadoopの最初のバージョンでは、Cygwinのインストールが必要です。 ここでプラスになるのは、開発環境(IntellijIDEAおよびEclipse)との優れた統合です。 この素晴らしいマニュアルの詳細。
2番目のバージョンから、HadoopはWindowsサーバーエディションもサポートします。 ただし、HadoopとWindowsを実稼働環境だけでなく、一般的に開発者のコンピューターの外部で使用することはお勧めしませんが、これには特別なディストリビューションがあります。 現在、Windows 7および8はベンダーをサポートしていませんが、チャレンジが好きな人は手動で挑戦することができます。
また、Springのファンには、 Spring for Apache Hadoopのフレームワークがあることに注意してください。
簡単になり、Hadoopを仮想マシンにインストールします。 開始するには、仮想マシン(VMWareまたはVirtualBox) の CDH-5.1 配布キットをダウンロードしてください。 ディストリビューションのサイズは約3.5 GBです。 ダウンロード、解凍、VMへのロードなどがすべてです。 すべてあります。 今度は、お気に入りのWordCountを作成しましょう!
具体例
データサンプルが必要です。 bruteforce'aパスワード用の辞書をダウンロードすることをお勧めします。 私のファイルはjohn.txtという名前になります。
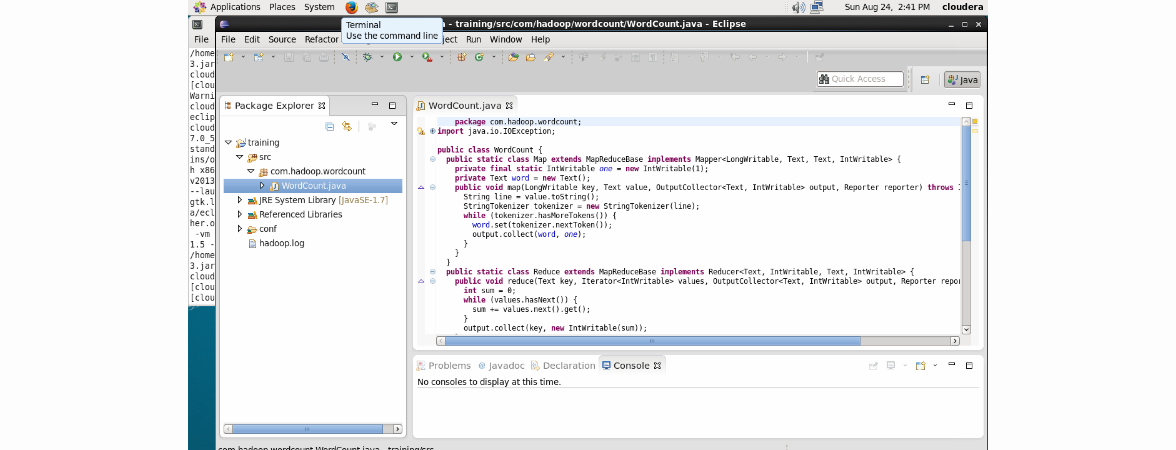
Eclipseを開きます。すでに作成済みのトレーニングプロジェクトがあります。 プロジェクトには、開発に必要なすべてのライブラリがすでに含まれています。 Clouderのスタッフが注意深くレイアウトしたすべてのコードを捨てて、次のコードをコピーして貼り付けましょう。
package com.hadoop.wordcount; import java.io.IOException; import java.util.*; import org.apache.hadoop.fs.Path; import org.apache.hadoop.conf.*; import org.apache.hadoop.io.*; import org.apache.hadoop.mapred.*; import org.apache.hadoop.util.*; public class WordCount { public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); } } } public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { JobConf conf = new JobConf(WordCount.class); conf.setJobName("wordcount"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Map.class); conf.setCombinerClass(Reduce.class); conf.setReducerClass(Reduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); } }
ほぼ次の結果が得られます。
メニューの[ファイル]-> [新規ファイル]を使用して、john.txtメールをトレーニングプロジェクトのルートに追加します。 結果:
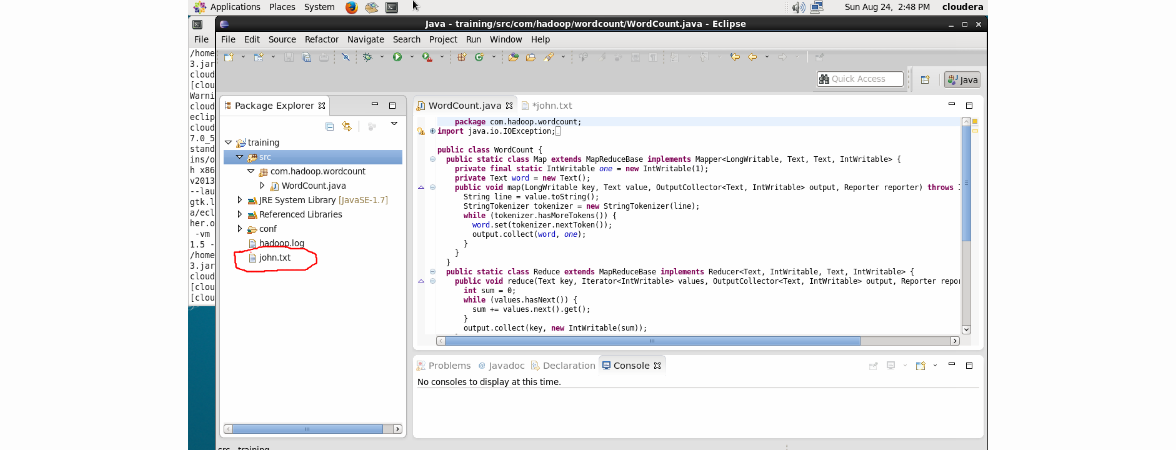
[実行]-> [構成の編集]をクリックし、input.txtとoutputをプログラム引数としてそれぞれ入力します。
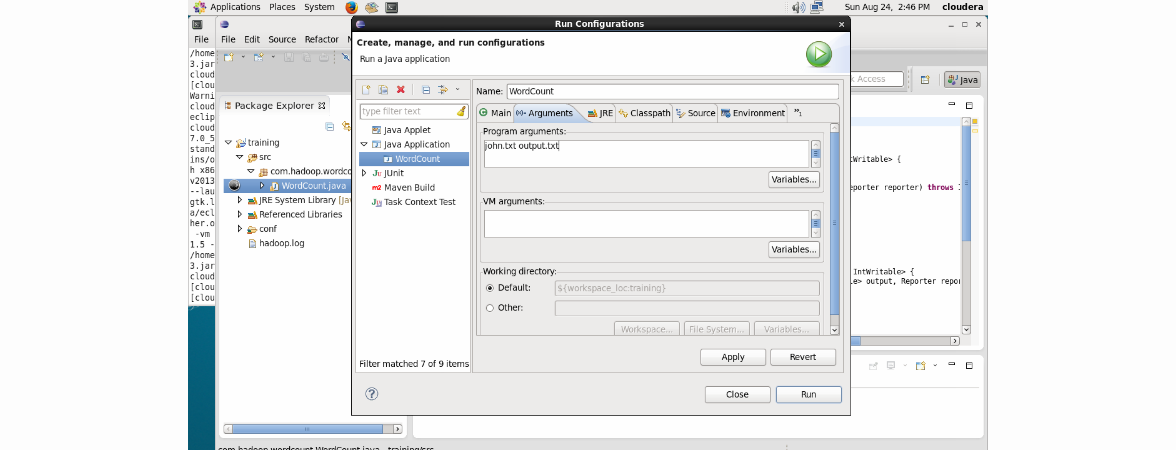
[適用]、[実行]の順にクリックします。 作業は正常に完了します。
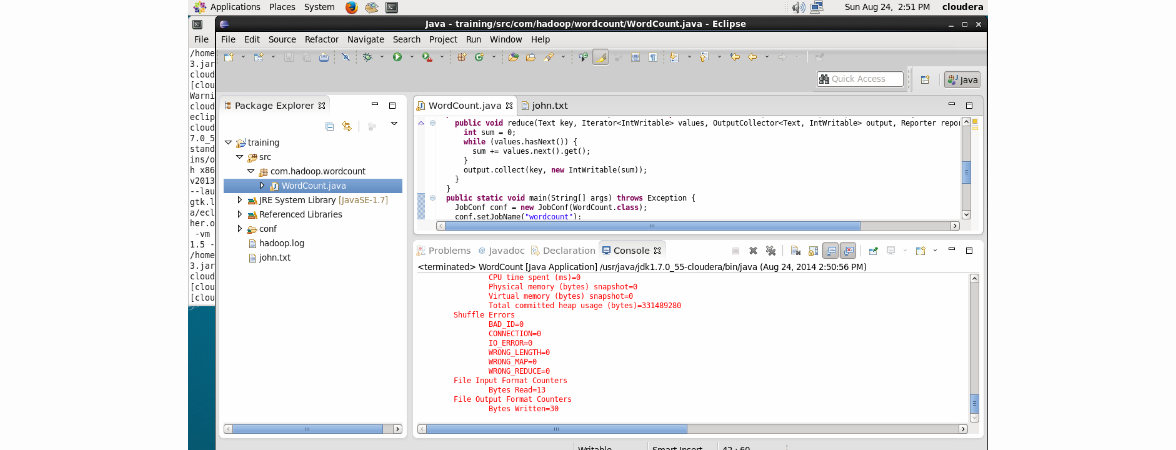
そして、結果はどこにありますか? これを行うには、Eclipseでプロジェクトを更新します(F5ボタンを使用):
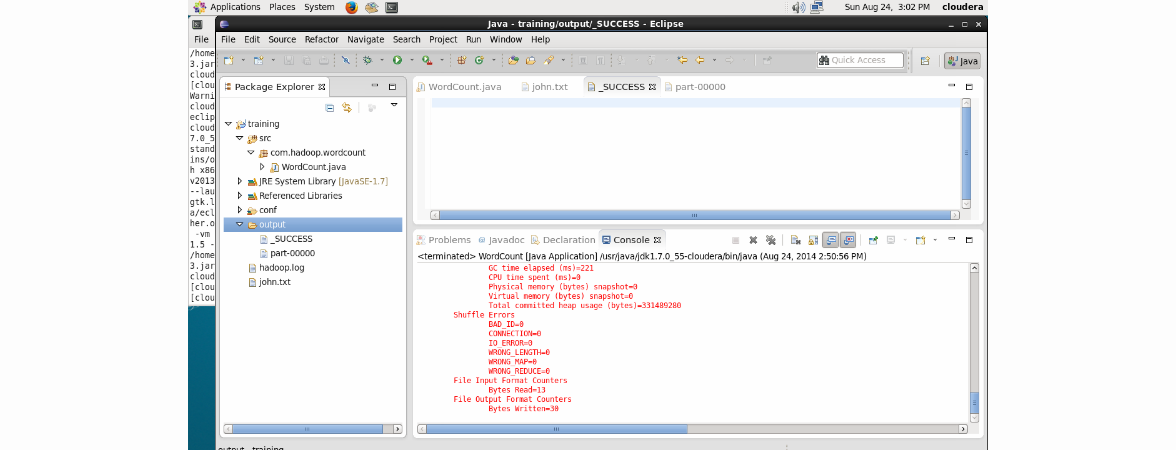
出力フォルダーには、作業が成功したことを示す_SUCCESSと、結果を直接示すpart-00000という2つのファイルがあります。
もちろん、このコードは借方に記入することなどができます。ユニットテストのレビューで会話を終了しましょう。 実際、Hadoopでの単体テストの作成にはMRUnitフレームワーク(https://mrunit.apache.org/)しかありませんが、Hadoopには遅れています。Hadoopの最新の安定バージョンは2.5.0ですが、現在サポートされているのはバージョン2.3.0までです。
エコシステムブリッツ:ハイブ、ブタ、ウージー、スクープ、フルーム
一言で言えば、すべてについて。
ハイブ&ブタ 。 ほとんどの場合、Pure JavaでMap / Reduceジョブを作成することは、時間がかかりすぎて耐えられず、意味のある意味で、すべての可能なパフォーマンスを引き出すだけです。 HiveとPigは、この場合の2つのツールです。 HiveはFacebookで、PigはYahooが大好きです。 HiveにはSQLに似た構文があります( SQL-92との類似点と相違点 )。 ビジネス分析とDBAの経験を持つ多くの人々がビッグデータキャンプに移りました。彼らにとって、Hiveは多くの場合選択のツールです。 PigはETLに焦点を当てています。
Oozieは、ジョブのワークフローエンジンです。 Java、Hive、Pigなど、さまざまなプラットフォームでジョブを構築できます。
最後に、システムへの直接データ入力を提供するフレームワーク。 とても短い。 Sqoop-構造化データ(RDBMS)との統合、 Flume-非構造化。
文献とビデオコースのレビュー
Hadoopに関する文献はまだ多くありません。 2番目のバージョンについては、特にHadoop 2 Essentials:An End-to-End Approachに焦点を当てた本を1つだけ見つけました。 残念ながら、この本は電子形式で入手できず、うまくいきませんでした。
生態系の個々の構成要素(Hive、Pig、Sqoop)に関する文献は考慮しません。なぜなら、それはいくぶん時代遅れであり、最も重要なこととして、そのような本はカバーツーカバーで読まれる可能性が低く、むしろそれらが参照ガイドとして使用されるからです。 そして、それでもあなたはいつでもドキュメントを手に入れることができます。
Hadoop:The Definitive GuideはAmazonのトップブックであり、多くの肯定的なレビューがあります。 この資料は古いものであり、2012年であり、Hadoop 1について説明しています。さらに、多くの肯定的なレビューがあり、エコシステム全体をかなり広範囲にカバーしています。
Lublinskiy B. Professional Hadoop Solutionは、この記事で多くの資料を取り上げた本です。 やや複雑ですが、実際の実例がたくさんあります。ソリューションを構築する際の特定のニュアンスに注意が払われます。 製品の機能の説明を読むよりもずっといい。
Sammer E. Hadoop Operations-本の約半分は、Hadoopの構成を説明することに専念しています。 2012年の本を考えると、まもなく廃止されます。 もちろん、主にdevOpsを対象としています。 しかし、システムが開発されただけで悪用されていない場合、システムを理解して感じることは不可能であると私は考えています。 この本は、バックアップ、監視、およびクラスタベンチマークの標準的な問題がレビューされたという事実により、私にとって有用であると思われました。
Parsian M.「データアルゴリズム:HadoopとSparkでスケールアップするためのレシピ」 -主な重点は、Map-Reduceアプリケーションの設計です。 科学的方向への強いバイアス。 MapReduceの包括的で深い理解と応用に役立ちます。
Owens J. Hadoop Real World Solutions Cookbook-タイトルに「Cookbook」という単語が含まれる他の多くのPacktブックと同様に、質問と回答に分割された技術文書です。 これもそれほど簡単ではありません。 自分で試してみてください。 大まかな概要を読むことは価値があり、参照として使用されます。
O'Reillyの2つのビデオコースに注目する価値があります。
Hadoopの学習 -8時間。 それは表面的すぎるように思えた。 しかし、私にとっては、いくつかの付加価値があります。 Hadoopでプレイしたいのですが、ライブデータが必要です。 そして、彼はここにいます-データの素晴らしいソース。
Hadoopクラスターの構築 -2.5時間。 タイトルからわかるように、Amazonでクラスターを構築することに重点が置かれています。 私はコースが本当に好きでした-短くて明確です。
私のささやかな貢献が、Hadoopを学び始めたばかりの人たちを助けることを願っています。