2012年のTED会議でのMax Little(PVIの創設者)によるスピーチから。
こんにちは、Habrahabr。 この一連の記事は、音声障害の可能性を検討し、オープンソースのユニバーサルアナライザーを構築することに専念します。
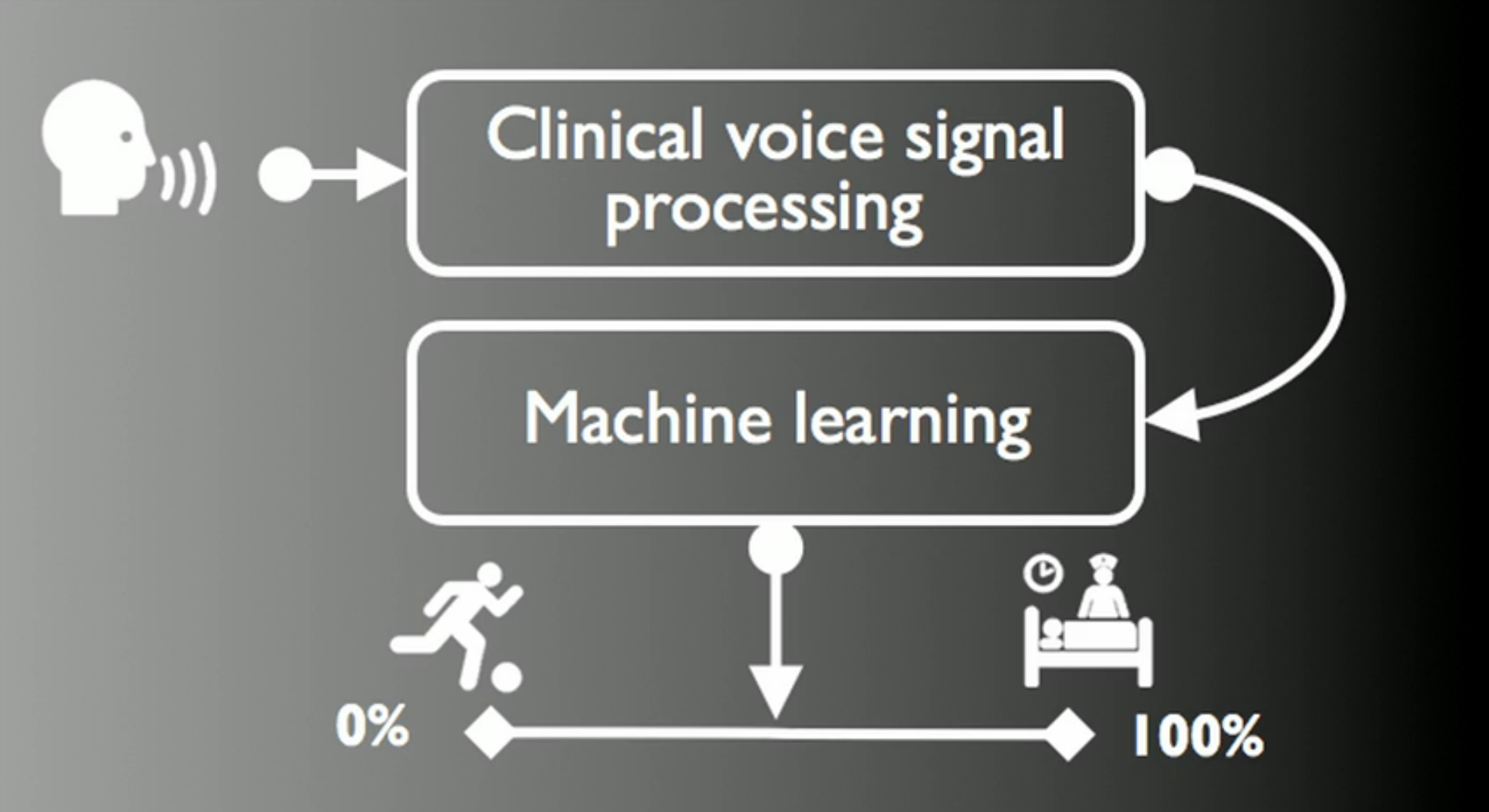
この記事では、音声によるパーキンソン病の早期診断に特化したパーキンソン音声イニシアチブプロジェクトについて説明します(電話で30秒で認識成功率は98.6±2.1%)。
その中で使用される機能選択アルゴリズム(BO)の精度が比較されます-機能選択アルゴリズム-LASSO、mRMR、RELIEF、LLBFS。
ランダムフォレスト(RF)とサポートされているベクターマシン(SVM)の間で、この種のアプリケーションで最高のアナライザーのタイトルをめぐる戦い。
開始する
音声の合成と認識に関する記事を読んで、病気が声を変えるという言及を見つけました。 私が病気の診断に音声認識の使用を最初に推測したわけではないという事実の証拠を確認した後(最初の臨床医はいくつかの特徴を特定しました-特に前世紀の40年代に、テープに記録し、その後手動で分析しました)、Googleリンクを追跡しました。 最初の1つはPVIプロジェクトを指しています。

2012年のTED会議での創設者のスピーチを見た後( イリーナ・ザンダロワからのロシア語の字幕が利用可能です )、私は自分自身、医師と患者、そしてプログラマーのために、そのようなプロジェクトを支持する必要な議論を見つけました。
2012年まで、パーキンソン病のバイオマーカーはありませんでしたが、既存のバイオマーカーは、一次診断よりも発達のダイナミクスを決定するためのものでした。 さらに、その入手可能性、価格、結果を得るまでの時間、および複雑さの問題は未解決のままです。

2012 TEDプレゼンテーションからの抜粋(ロシア語の字幕はIrina Zhandarovaから)。
引数
| 特徴 | 神経科医 | 音声チェック |
|---|---|---|
| 非侵襲性 | + | + |
| 既存のインフラストラクチャの使用 | + | + |
| 精度 | + | + |
| 遠隔性 | + | |
| 非専門的使用 | + | |
| 高速結果 | + | |
| 非常に低コスト | + | |
| 拡張性 | + |
また、病気の存在を頻繁に確認することもできます。
他の病気に対して同じアナライザーを簡単に作成し、[ サイエンス ]タブをクリックして、このアナライザーが2006年に開始したことを確認できました。 開発期間は熱意のレベルを幾分低下させましたが、欲求を撃退しませんでした。
彼らがそのような正確な分析器を持っているのに、なぜこのサイトは医学的なアドバイスをしないのですか?
これにはいくつかの理由が考えられます(病気の分析に適しています):
- 法的規制。 彼らは医学的アドバイスをするために責任をとらなければなりません。
- 彼らは十分なデータを収集したかどうかはわかりません。
- 病気の偽陽性および偽陰性の定義;
- この病気は、言語障害が現れ始めるほど深刻ではない場合があります(つまり、後に発症する場合があります)。
- 最後に、特定の数の人々では、重症度によってはまったく現れない症状もあります(回復するか、早く死ぬ)。
- いくつかの病気との類似性はまだあります(たとえば、このプロジェクトでは、この本性振戦はパーキンソン病とは異なる種類の振戦です)。
どうやら、データを正しく評価できる医師や研究者が利用できます。
以下に見ることができる人々の声のユニークな録音の成長率。 Twitter Max Little @MaxALittleに基づく2012年(プログラム開始から8年後)のデータは、テストを受ける人の数が、他の場所と同様に、メディアやソーシャルネットワークの報道により依存していることを示しています。
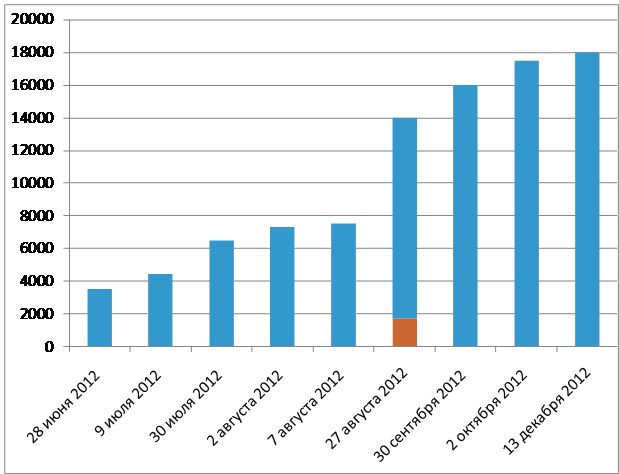
列の上部の境界線は、PVIプロジェクトの音声テストに合格した合計人数です。 8月27日に、14,000人の署名者のうち1,700人(約12%がパーキンソン病である)が赤いバーであるというデータが公開されました。
アーロン・シュワルツを記念して、彼は出版物を無料で公開し、誰もがそれらに精通し、技術的な詳細を見て、作品を開発できるようにしました。
アーロン・スワルツの記憶を称えるために、これまでの私のすべての出版物を無料で: www.maxlittle.net/publications #pdftribute
マックス・リトル@MaxALittle 1月14日 2013年

パーキンソンボイスイニシアチブプロジェクトの創設者である彼のエルドス番号は4です。
サイトに投稿された2012年の最新のMax Littleの研究 -「パーキンソン病の高精度分類のための音声信号処理の新しいアルゴリズム」では、4つの特徴選択アルゴリズム(BO)が比較されています。 この研究に基づいたデータには、対照群の発声(10人から61の記録)およびパーキンソン病の人(33人から202の記録)を含む132の特徴と263の記録が含まれていました。
技術的な詳細
この研究で学習したすべての機能を使用して、10回の交差検証-交差検証(PP)を100回繰り返したSVMは97.7±2.8%の精度を示し、 RFを使用した場合は10回の交差検証を繰り返し100回-達成された精度は90.2±5.9%でした。
それ以前の文献に記載されている最高の結果は、 GP-EMアルゴリズム(遺伝的プログラミングおよび期待値最大化アルゴリズム-遺伝的プログラミングおよび期待値最大化)を使用した22の特徴のサンプルの分類で93.1±2.9%の精度に達しました。
予測の品質を向上させ、研究における音声信号の処理の複雑さを軽減するために、10個の特徴のサブセットを作成することが決定されました。 すべての可能なサブセットを包括的に検索するのはマシンタイムが非常に高価であるため、機能のセットを減らすための迅速で原則的なアプローチを提供するVOアルゴリズムが開発されました。
各ケースで、PPアプローチを使用して、PPの各反復でトレーニング情報のみを使用して、機能のサブセットが選択されました。 彼らはPPプロセスを全部で10回繰り返し、そのたびに(VOアルゴリズムごとの)特徴が選択の降順で現れました。 理想的には、毎回同じ注文を取得する必要がありますが、実際にはこれは起こりません。
安心
RELIEFは 、256個の発声データで10個の機能(132個中)のみを使用して、 SVMで98.6±2.1%の精度(真の陽性:99.2±1.8%、真の陰性:95.1±8.4%)とRFで 93.5%の精度を示しました。
RELIEFは、異なるクラスからサンプルを分離する機能を強化する機能の「重み」の決定に基づくアルゴリズムです。 これは、アルゴリズムの修正力の最大化と相関しており、k-Nearest-Neighbor分類器に割り当てられています。 mRMRアルゴリズム(以下で説明)とは異なり、 RELIFEは機能選択プロセスの不可欠な部分として偶発事象を使用します。
LLBFS
2番目は、97.1±3.7%(真の陽性:99.7±1.7%、真の陰性:89.1±13.9%)の精度を持つLLBFS (Local Learning-Based Feature Selection)アルゴリズムによって取得されました。
LLBFSは、HEの扱いにくい組み合わせの問題を、局所学習を通じて一連の局所線形問題に分解することを目的としています。 最初のフィーチャには、分類問題の重要性を反映する重みが割り当てられ、その後、それらから最大の重みを持つフィーチャが選択されました。 LLBFSはRELIEFの拡張として考えられており、分布密度の核推定と補正機能の最大化の概念に基づいています。
なげなわ
寸法を縮小する可能性がある線形モデルのパラメーターを推定する方法である最小絶対収縮および選択演算子(LASSO)は、94.4±4.4%(真の正:97.5±3.4%、真の負:86.5±14.3%)の精度で3位になりました。
LASSOは、線形回帰で設定された係数の絶対数に対して罰金を科します。 これにより、それらの一部がゼロになり、それらに関連する機能が効果的に表示されます。 LASSOは、機能が高度に共役されていない場合、スパースインストールで予測機能(答えの予測に寄与するすべての「正しい」機能を正しく識別)を示しました。 同時に、機能が相関している場合、「ノイズの多い」機能(答えに寄与しない)を選択することができ、結果を予測するためにいくつかの有用な機能が除外されました。
mRMR
最小冗長性最大関連性(mRMR) 、(最小冗長性-最大関連性)は、調査されたVOアルゴリズムの中で、94.1±3.9(真の正:97.6±3.3、真の負:84.3±13.2)の精度で最後になりました。
mRMRアルゴリズムは、ヒューリスティック基準を使用して、最大の関連性(回答に対する機能の強度の関係)と最小の超過(機能のペア間の接続)のバランスを確立します。 これは貪欲なアルゴリズム(1パスでの1つの機能の選択に基づく)であり、ペアごとの冗長性のみに焦点を合わせ、共役(応答を予測する機能の論理接続による接続)を無視します。
SVM対 RF
この調査では、 SVMがRFよりも優先されました。 この研究の著者は、 RFチューニングパラメーター(各ツリーブランチを構築するために検索を実行する必要がある機能の数)を変更しようとしましたが、これは全体的なRF精度に関して著しく異なる結果を生成しませんでした。
研究の著者によって提案された可能な改善:
SVMおよびRFは、他のクラスに割り当てる可能性が特定の事前定義された機能を下回っている場合、追加のクラスを導入することで「わからない」を出力するように構成できます。これにより、判定の精度が向上し、医師はこのケースをより詳しく見る機会を得ることができます
次のパートでは、このようなすばらしい結果を得るための機能について説明します。
PSこのトピックに興味があり、開発を手伝う準備ができているなら、書いてください。