背景
少し前、つまり6月5日にalan008という名前のハーバーマンが質問をしました 。 詳細を求めないように、ここに彼を連れてきます。
助けが必要です!
数年にわたり、さまざまなクライアント(主にuTorrent)によって、さまざまな便利なコンテンツの多くのギガバイトがさまざまなトラッカー(主にrutrackerを使用)からダウンロードされてきました。 ダウンロードされたファイルは、その後手動であるドライブから別のドライブに移動され、uTorrentはそれに応じてそれらを表示しません。 多くの.torrentファイルはそれ自体では古くなっています(たとえば、シリーズの配布は、.torrentファイルを置き換えて新しいシリーズを追加することにより実行されました)。
さて、質問自体:コンピューター上の.torrentファイルとコンピューターの異なる論理ドライブに散在するコンテンツとの間の対応を自動的に(手動ではなく)確立する方法はありますか? 目的:不要な(無関係な).torrentファイルを削除し、実際のファイルでは-配布物にすべてを置きます。 誰がアイデアを持っていますか? :)
必要に応じて(必要な場合)、同じ論理ドライブ上の1つのディレクトリにすべてのデータファイルを再度配置できます。
議論は、これができるのであれば、ペンでしかできないことに同意した。 この質問は私にとっては面白そうで、休暇から戻った後、時間をかけて整理しました。
.torrentファイル形式の解析に合計1週間を費やし、解析用の作業ライブラリを探して、上記の質問で発生した問題を解決するプログラムの作成を開始しました。
始める前に、いくつかの点に注意する価値があります。
- 多くのことが判明しましたが、すべてではありませんでした。
- .torrentファイル形式では、必要な説明のみが提供されます。
- 時々低品質のコードに敏感な人は私を許してください-多くの方がより良く、より最適に、エラーなしで書けることを知っています。
技術的な詳細と落とし穴-猫の下で、それから来たものに興味がある人のために。
この場合、それを解決するための素晴らしい方法があります-再びポンプでくみます。 しかし、私たちは簡単な方法を探していません。そのようなオプションが提案されました! したがって、困難なタスクを解決します- ダウンロードしないでください 。
プログラムの作成を開始するときは、まずその操作の少なくとも基本的なアルゴリズムについて考える必要があります。 この場合、アルゴリズムは基本的に2つのステップで構成されます。
- すべての.torrentファイルを見つけて読み取ります。
- .torrentで説明されているものと一致するファイルヒープを探し、.torrentのパスに対応するフォルダーに移動します。
私のアイデアを実装するために、私はC#を使用しましたが、ベンコード形式のファイルを読み込むためのライブラリを備えた言語はこれに適しており、SHA-1ハッシュを読み込むことが可能です。
さて、タスクの解決策に進みましょう。
トレントを探して読む
デバイスの.torrent-filesを見つけた後、このすべての奇跡を解析するという問題に直面しました。 このテーマでインターネットを精査して、このビジネスのためのいくつかの.NETライブラリを発見しました。 BencodeLibraryライブラリで選択を選択しましたが、多かれ少なかれ明確で、すぐに使用できますが、後でニーズに少し追加する必要がありましたが、それについては後で詳しく説明します。
.torrentを読むという最も単純な瞬間から始めましょう。
.torrentファイルの構造は非常に単純です。これは、 ベンコード形式の辞書です。 この辞書では、 情報キーとのペア、つまりファイル記述ブロックのみに関心があります。 これも辞書であり、ファイルの名前、サイズに関する情報が含まれています。 さらに、多くの人が知っているように、急流はファイルを完全にではなく、特定の長さの断片にハッシュします。これはこれらのファイルのサイズに依存します。 この作品のサイズに関する情報も情報辞書に含まれています。
読み取ったファイルからの情報を保存するには、次の
Torrent
クラスを使用します。
クラス急流
public class Torrent { public Torrent(string name, List<LostFile> files, int pieceLength, char[] hash, string fileName) { Name = name; Files = files; PieceLength = pieceLength; Hash = hash; FileName= fileName; } public string Name; public int PieceLength; public char[] Hash; public List<LostFile> Files; public string FileName; ... }
ここで、フィールドには次の情報が格納されます。
*
Name
-トレント名(一般的に言えば-フォルダー名またはファイル名)
*
Files
-今後検索する必要があるファイルのリスト
*
PieceLength
これらのピースのサイズ、考慮すべきハッシュ
*
Hash
-すべてのファイルのハッシュ文字列
*
FileName
ディスク上の.torrentファイルの名前
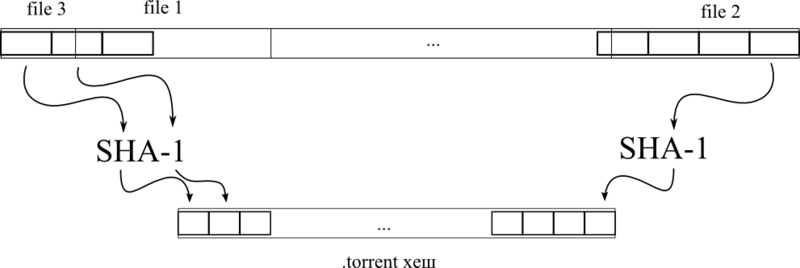
ハッシュラインに注目する価値があります。 非常に簡単に構成されています。 すべてのファイルは次々と(事実上)接着され、1つのBIGOOOOOOOYの仮想ファイルを形成します。 この架空のファイルでは、
PieceLength
の長さの断片を取得し、SHA1ハッシュを考慮し、ハッシュを行に入れ、次の断片を取得し、ハッシュを考慮し、前の断片のハッシュで行の末尾に追加します。 つまり、すべてのピースのハッシュの通常の連結です。
注意深い読者が気付くように、クラス内のファイルは単なるファイルではなく、
LostFile
型の特定の構造によってファイルが記述される特別なデータ型です。 ここにあります:
クラスLostFile
public class LostFile { public LostFile(string name, long length, long beginFrom) { Name = name; Length = length; BeginFrom = beginFrom; } public string Name; public long Length; public long BeginFrom; . . . }
ここではすべてが簡単です。ファイルの名前とサイズです。 さらに、このクラスには、
BeginFrom
別のフィールドが含まれています。 その大きな想像上のファイルでこのファイルの始まりを説明しています。 ハッシュを計算するには、ファイルの正しい部分を取得する必要があります-ファイルの長さが断片の長さの倍数になることは非常にまれです。

必要な情報を保存するための構造を準備したら、それらを埋めることができます。
インターネットにあるBencodeLibraryライブラリを使用して、.torrentファイルを読み取り、そこから情報ブロックをルートします。
List<LostFile> files = new List<LostFile>(); // , BDict torrent = (BDict)BencodingUtils.DecodeFile(filename, Encoding.UTF8); BDict fileInfo = (BDict)torrent["info"];
次に、このブロックから、トレントの名前、ピースのサイズに関するデータを収集する必要があります。
string name = ((BString)fileInfo["name"]).Value; int pieceLength = (int)((BInt)fileInfo["piece length"]).Value;
ハッシュの読み取りに問題がありましたが、その解決策はあまり好きではありませんが、うまくいきます。 実際、仕様によれば、.torrentファイルのすべての行はUFT8にある必要があります。 仕様に従って、UTF8文字列としてベンコード文字列の形式で記述されたハッシュを読み取ると、比較の問題が発生します-同一の断片のハッシュは一致しません。 提案されたエンコードコードページ437のトレントを読むと、パス内のロシア文字に問題があります。 異なるエンコーディングで2回読むという、2日間の速度を落とすような状況から抜け出す方法を見つけました。
torrent = (BDict)BencodingUtils.DecodeFile(filename, Encoding.GetEncoding(437)); char[] pieces = ((BString)((BDict)torrent["info"])["pieces"]).Value.ToCharArray();
この時点で、エンコード情報を2番目のパラメーターとして `BencodingUtils.DecodeFile`メソッドに渡します。 これはまさに、ライブラリにメソッドを1つ追加しなければならなかった瞬間です-最初はcodepage-437がコードに縫い付けられていました。
この部分で最も興味深いポイントに到達しました-ファイル情報の読み取り。 トレントファイルには2つのタイプがあります。 これらのタイプは、それらに記述されているファイルの数が異なります。 .torrentで1つのファイルのみを記述する場合、その名前とサイズが書き込まれます。
最初に、1つのファイルの説明を使用して.torrentを分析します。
long Length = ((BInt)fileInfo["length"]).Value; files.Add(new LostFile(name, Length, 0)); // files -
ここではすべてが単純です-トレントの名前はファイル名と同じです。 ディストリビューションに多数のファイルがある場合、それらを入れるフォルダーの名前が名前フィールドに書き込まれます(実際には、何でも構いませんが、何らかの理由で、誰もがこれらのファイルが作成時に配置されたフォルダーの名前を書き込みます)。 さらに、各ファイルに関する情報(パスとサイズ)を含むファイルのリストが表示されます。 サイズが整数の場合、ファイルパスは文字列(ディレクトリ名)のリストであり、このファイルを介して表示されます。
これは、例によって最もよく説明されます。 ファイル
level_1\level_2_1\file_1.txt
および
level_1\level_2_2\file_2.txt
場合、それらを配布する場合、 名前フィールドには最上位フォルダーの名前(
"level_1"
)が含まれ、ファイルの1つのパスリストは次のようになります:
{"level_2_1", "file_1.txt"}
および
{"level_2_2", "file_2.txt"}
別の。
複数のファイルを含む.torrentの場合、各ファイルへのパスを1行で収集する必要があります。 さらに、各ファイルの先頭をそのBOLSHOOOOMに保存する必要があります(忘れないでください、本当に?!)。
BList filesData = (BList)fileInfo["files"]; long begin = 0; foreach (BDict file in filesData) { BList filePaths = (BList)file["path"]; long length = ((BInt)file["length"]).Value; string fullPath = name; foreach (BString partOfPath in filePaths) { fullPath += @"\" + partOfPath.Value; } files.Add(new LostFile(fullPath, length, begin)); // files - begin += length; }
BOLSHOOOOOMファイル内のファイルの順序は任意であり、必ずしもアルファベット順またはサイズではないことに注意することが非常に重要です。 ただし、 ファイルリスト内のファイルの順序はまったく同じになります。 これは、ハッシュの原理を理解するための鍵です。 たとえば、最初の図に示す状況では、ファイルのリストは次のようになります:
{"file_3","file_1", ..., "file_2"}
。 したがって、あるファイルのハッシュを考慮すると、次に取得する必要があるファイルがわかります。
このすべてを読んでカウントしたら、
Torrent
コピーを作成して返しましょう。
new Torrent(name, files, pieceLength, pieces, filename);
.torrentファイルのすべての読み取り値と分析をまとめて収集すると、次のようになります。
ReadTorrent
static Torrent ReadTorrent(string filename) { List<LostFile> files = new List<LostFile>(); BDict torrent = (BDict)BencodingUtils.DecodeFile(filename); BDict fileInfo = (BDict)torrent["info"]; string name = ((BString)fileInfo["name"]).Value; int pieceLength = (int)((BInt)fileInfo["piece length"]).Value; torrent = (BDict)BencodingUtils.DecodeFile(filename, Encoding.GetEncoding(437)); char[] pieces = ((BString)((BDict)torrent["info"])["pieces"]).Value.ToCharArray(); if (fileInfo.ContainsKey("files")) // Multifile torrent { BList filesData = (BList)fileInfo["files"]; long begin = 0; foreach (BDict file in filesData) { BList filePaths = (BList)file["path"]; long length = ((BInt)file["length"]).Value; string fullPath = name; foreach (BString partOfPath in filePaths) { fullPath += @"\" + partOfPath.Value; } files.Add(new LostFile(fullPath, length, begin)); begin += length; } } else // Singlefile torrent { long Length = ((BInt)fileInfo["length"]).Value; files.Add(new LostFile(name, Length, 1)); } return new Torrent(name, files, pieceLength, pieces, filename); }
必要なデータがすべて揃ったので、最も興味深いこと、つまりファイルの検索の準備ができました。
ファイルを探しています
アルゴリズムの2番目のステップの実装に近づきました。 これを行うには、次のフォームの
FindFiles
メソッドを使用します。
void FindFiles(Torrent torrent, List<FileInfo> files, string destinationPath) {}
ここで、
files
は検索対象のファイルのリスト
files
は、見つかったファイルが配置される宛先フォルダーへのパスです。
.torrentの各ファイルについて、ヒープからすべてのファイルを反復処理し、それらを比較します。 ハッシュのチェックは非常に高価なので、最初に左側のファイルを明示的にクリアする必要があります。 さて、自分で判断してください。ディスコグラフィーを.mp3にダウンロードして移動しても、明らかにファイル拡張子は変更しませんでした。 名前は変更できますが、拡張子はほとんどありません。
FileInfo fileOnDisk = files[j]; if (fileOnDisk.Extension != Path.GetExtension(fileInTorrent.Name)) continue;
ファイルの長さも確認する価値がありますが、これはすでに疑わしいものであり、誤検知を引き起こす場合があります。 拡張子によって明示的に残されたファイルをふるいにかけた後にのみ、ハッシュのチェックを開始できます。
if (!torrent.CheckHash(i, fileOnDisk)) continue;
検証が完了し、ファイルが探しているものと一致することを確認した後、正しいパスで宛先フォルダーに移動します。 移動する前に、ディレクトリの存在を自然に確認し、そのようなファイルがすでにあるかどうかも確認します。
copyFile
ユーザーがフォームから渡した変数、その目的は誰にでも明らかだと思います。
FileInfo fileToMove = new FileInfo(destinationPath + @"\" + fileInTorrent.Name); if (!Directory.Exists(fileToMove.DirectoryName)) Directory.CreateDirectory(fileToMove.DirectoryName); if (!fileToMove.Exists) { // - if (copyFile) File.Copy(fileOnDisk.FullName, fileToMove.FullName); else File.Move(fileOnDisk.FullName, fileToMove.FullName); // files.Remove(fileOnDisk); // torrent.Files.RemoveAt(i--); break; // , torrent }
上記のコードで説明する重要な3つのポイントがあります。 最後の2つから始めましょう-これらの行:
files.Remove(fileOnDisk); torrent.Files.RemoveAt(i--);
ソート済みのファイルを考慮から除外することは非常に論理的であることがわかりました。これにより、検索の実行時間がわずかに短縮されます。 2行目には、構成
.RemoveAt(i--);
が含まれてい
.RemoveAt(i--);
現在の要素はコレクションから削除されるため、次の要素がループを通過するのではなく、ループの次の反復で取得されるように、ポインターを戻す必要があります。
最初の瞬間について。 リストに
foreach
が存在することは知っていますが、それを使用する場合、このスピーカーを変更することはできません。つまり、既に不要な要素を削除することはできません。 したがって、上記のすべてを1つの方法で収集すると、次のようになります。
ReadTorrent
public static void FindFiles(Torrent torrent, List<FileInfo> files, string destinationPath, bool copyFile) { for (int i = 0; i < torrent.Files.Count; i++)// (LostFile fileInTorrent in torrent.Files) { LostFile fileInTorrent = torrent.Files[i]; for (int j = 0; j < files.Count; j++) { FileInfo fileOnDisk = files[j]; // if (fileOnDisk.Extension != Path.GetExtension(fileInTorrent.Name)) continue; // if (fileOnDisk.Length != fileInTorrent.Length) continue; // if (!torrent.CheckHash(i, fileOnDisk)) continue; // . // FileInfo fileToMove = new FileInfo(destinationPath + @"\" + fileInTorrent.Name); if (!Directory.Exists(fileToMove.DirectoryName)) Directory.CreateDirectory(fileToMove.DirectoryName); if (!fileToMove.Exists) { if (copyFile) File.Copy(fileOnDisk.FullName, fileToMove.FullName); else File.Move(fileOnDisk.FullName, fileToMove.FullName); // files.Remove(fileOnDisk); // torrent.Files.RemoveAt(i--); break; } } } }
よくここに! 最もおいしい。
ハッシュチェック
上記のコードからわかるように、ハッシュを確認するために、ディスク上のファイル名とトレントファイルのリスト内のファイル番号を転送します。 これは、ファイルのリストで検索を開始するのではなく、既知であるため、すぐに番号で検索するために必要です(ループの別の「+1」)。
public class Torrent { public string Name; public int PieceLength; public char[] Hash; public List<LostFile> Files; public string FileName; public bool CheckHash(int index, FileInfo fileOnDisk) {} }
それでは、ハッシュ検証メソッドの実装に取り掛かりましょう。 この段階で、トレントファイルのリストの番号とディスク上のファイルへのパスがわかります。
LostFile checkingFile = this.Files[index]; if (checkingFile.Length < this.PieceLength * 2 - 1) return false;
原則として、任意のファイルのハッシュを考慮することができますが、タスクを少し簡単にしましょう。 長さが
PieceLength * 2 - 1
以上のファイルのみを使用します。 このような制限により、検証のために少なくとも1つの部分を分離できます。これは完全にファイル内にあります。 このアプローチには、いくつかの重要な利点があります。
- ディスク上の隣接ファイルを追加で検索する必要はありません。
- ハッシュチャンクの長さが2〜4 MBを超えることはめったにありません。これにより、パフォーマンスと時間の点で、ディスク上のファイルを探すよりもはるかに簡単にダウンロードできます。
この段階で、私たちはやらなければならないことの中で最も困難なこと-検証のための適切なピースを見つけることになりました。 プログラミングから少し離れて、数学に目を向けて、補助的な問題を定式化しましょう。
トレントクライアントがファイルをハッシュすると、ハッシュが順番に考慮されますが、1つ以上のファイルが存在しないことが起こります。 次に、トレントクライアントは、次のピースを取得し、次に使用可能なファイルのどこから開始するかを知る必要があります。 これらの2桁を計算するには、次のコードを使用します
firstChunkNumber
変数には、このファイルに完全に含まれる最初のピースの番号と、
bytesOverhead
ファイルの先頭からこのピースの先頭までのバイト数が含まれます。 この点をよりよく理解するには、コードの後の説明図をご覧ください。
long start = 0; long firstChunkNumber = 0; long bytesOveload = checkingFile.BeginFrom % this.PieceLength; if (bytesOveload == 0) // { start = checkingFile.BeginFrom; firstChunkNumber = checkingFile.BeginFrom / this.PieceLength; } else { firstChunkNumber = checkingFile.BeginFrom / this.PieceLength + 1; start = firstChunkNumber * this.PieceLength - checkingFile.BeginFrom; }

「その開始がファイルの開始と一致する場合と、ピースが内部にある場合とではなぜピース番号が異なるのか」という質問に対する答えは、独立して提案されています。
ピースの番号がわかったら、次の構成を使用してトレントからハッシュを取得する必要があります。
char[] hashInTorrent = new char[20]; // 20 - SHA1 Array.Copy(this.Hash, firstChunkNumber * 20, hashInTorrent, 0, 20);
その後、ファイルからピースを読み取り、そのハッシュを計算する必要があります。
char[] fileHash = new char[this.PieceLength]; using (BinaryReader fs = new BinaryReader(new FileStream(fileOnDisk.FullName, FileMode.Open))) { using (SHA1CryptoServiceProvider sha1 = new SHA1CryptoServiceProvider()) { byte[] piece = new byte[this.PieceLength]; fs.BaseStream.Position = start; fs.Read(piece, 0, this.PieceLength); fileHash = Encoding.GetEncoding(437).GetString(sha1.ComputeHash(piece)).ToCharArray(); } }
さて、最も重要なことはそれをチェックすることです。 何らかの理由で、私にとっては、
Equals()
メソッドが見つからなかったため、次の方法でチェックします。
for (int i = 0; i < fileHash.Length; i++) { if (fileHash[i] != hashInTorrent[i]) return false; }
興奮した脳の作成をまとめると、次の内容のメソッドが得られます。
チェックハッシュ
public bool CheckHash(int index, FileInfo fileOnDisk) { LostFile checkingFile = this.Files[index]; if (checkingFile.Length < this.PieceLength * 2 - 1) return false; long start = 0; long firstChunkNumber = 0; long bytesOveload = checkingFile.BeginFrom % this.PieceLength; if (bytesOveload == 0) { start = checkingFile.BeginFrom; firstChunkNumber = checkingFile.BeginFrom / this.PieceLength; } else { firstChunkNumber = checkingFile.BeginFrom / this.PieceLength + 1; start = firstChunkNumber * this.PieceLength - checkingFile.BeginFrom; } char[] hashInTorrent = new char[20]; Array.Copy(this.Hash, firstChunkNumber * 20, hashInTorrent, 0, 20); char[] fileHash = new char[this.PieceLength]; using (BinaryReader fs = new BinaryReader(new FileStream(fileOnDisk.FullName, FileMode.Open))) { using (SHA1CryptoServiceProvider sha1 = new SHA1CryptoServiceProvider()) { byte[] piece = new byte[this.PieceLength]; fs.BaseStream.Position = start; fs.Read(piece, 0, this.PieceLength); fileHash = Encoding.GetEncoding(437).GetString(sha1.ComputeHash(piece)).ToCharArray(); } } for (int i = 0; i < fileHash.Length; i++) if (fileHash[i] != hashInTorrent[i]) return false; return true; }
この素晴らしいメモで、方法とアルゴリズムの物語は終わり、私たちはこの創造の実生活における実現の物語に移ります。 この問題が解決するために私によって解決されたのではなく、実現するために解決されたことは非常に明らかです。 したがって、私は、上に書かれたものすべてを実装する私の創造物を公開裁判所に持ち込みます。
プログラム
プログラムは、C#で既に述べたように書かれています。 作業中はあまり気まぐれではなく、.NET 2.0のみが必要です。 ただし、その使用には1つの制限があります。トレントファイルとコレクションを論理ドライブのルートから削除することをお勧めします。 この制限の理由は、ディレクトリをスキャンするときに「SearchOption.AllDirectories」パラメータを使用するためです。これは、ごみ箱や「システムボリューム情報」などの閉じたディレクトリを読み取ろうとするとクラッシュします(知識のある人がこれを回避する方法を教えてくれたら、とても感謝しています)。 もちろん、宛先フォルダーには特別な制限はありません。主なことは、それが収まることであり、それに書き込むことができます。そうしないとクラッシュします(シミュレートしませんでしたが、論理的に)。
プロセスでは、次のファイルの処理後、結果が表示されます-ディスク上の.torrentファイルの名前と処理されたファイルの数。
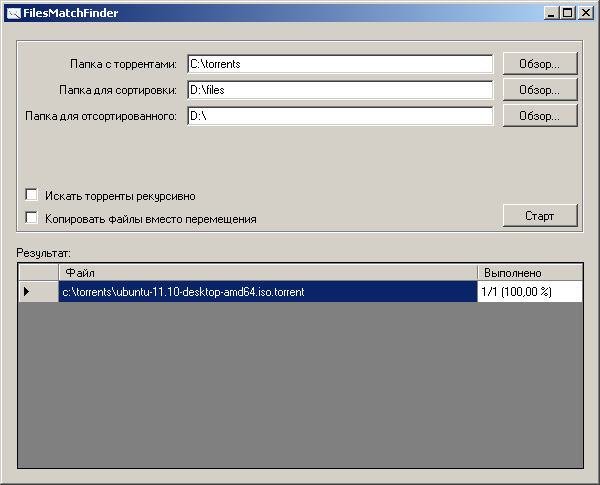
スキャンを開始するには、3つのディレクトリ(.torrentファイル、並べ替え用のファイル、および並べ替え用のフォルダ)を選択し、オプションで2つのオプションを指定してスキャンを開始する必要があります。
パフォーマンスについて。 まだ低い:10個の大きなトレントファイルの処理には約5分かかりました。
アプリケーションは1つのスレッドで動作するため、実行時にインターフェイスがフリーズしますが、作業中です。 また、ハッシュを検証できないため、小さなファイル(2メガバイト未満)は移動されないことをお知らせします。 誤
firstChunkNumber
、番号
firstChunkNumber
下の1つのピースのみ
firstChunkNumber
されるという事実が原因である可能性が非常に高いです。 これまでのところ、すべてのピースをチェックするのは非常に高価ですが、計画があります。
ディスクのルートで収集されたトレントを再帰的に検索しないでください。
コピーには時間がかかるため、インターフェイスがフリーズする可能性があります。心配しないでください。
この4funプログラムは書かれているので、コードの品質は私が望んでいるものとは少し異なりますが、私にとってはうまくいきます。 このプログラムはテストされておらず、明らかなエラーのみが修正されたため、隠れている可能性がありますが、隠れているバグがあります。 このプログラムを使用すると、あなたは自分の責任でそれを使用します。
ソースはgithubで入手できます 。 GPLv2で配布。 実行可能ファイルを含むアーカイブがあります。 作業にはBencode Libraryが必要ですが、元のライブラリは必要ありませんが、私が修正しました( リポジトリにあり、サブモジュールで接続されています )。
忍耐を示し、この記事を最後まで読んでくれた皆さんに感謝します。 あなたの質問を聞いて喜んで、アルゴリズム、特にコードを改善するためのあらゆる種類の助けを歓迎します。
ソース: BitTorrentSpecification
UPD1。 議論の結果に基づいて、配布用のファイルを引っ張って既存のコレクションを壊さずに、むしろ正しいコレクション内のファイルへの配布用の適切な場所にハードリンクを作成する方が正しいことが明らかになりました(例えば、映画やディスコグラフィー)。 将来、プログラムはそのように機能します。
UPD2。 このユーティリティを使用した人が機能やバグレポートに関して他に希望がある場合は、問題トラッカーのgithubに残してください。