
パート1
第二世代のフレームワーク
この世代は、自動化されたテストフレームワークの中間レベルであり、その中には非常に単純なフレームワークがあり、非常に適切に設計されたフレームワークがある場合があります。 このようなフレームワークは、自動テストのサポートが重要な要素である場合に考慮する必要があります。 第三世代のフレームワークはこのレベルのフレームワークの概念に基づいているため、この世代のフレームワークをよく理解することが重要です。第二世代のフレームワークには、データ指向のフレームワークと機能分解を使用するフレームワークが含まれます。 このレベルのほとんどのフレームワークはハイブリッドであり、両方のアプローチを使用しますが、どちらか一方のみを使用することが可能であるため、これらのアプローチは互いに独立して考慮されます。
機能分解
広義の機能分解とは、これらのコンポーネントを組み合わせて自動テストシナリオを作成できるように、モジュールコンポーネント(ユーザー定義関数)を作成するプロセスです。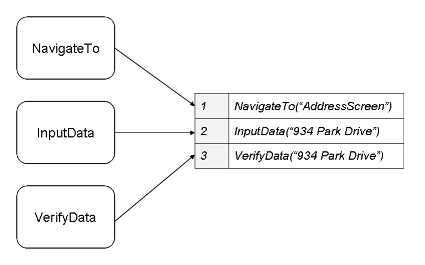
モジュール化は、テストでテスト対象のアプリケーションの機能を実装するためによく使用されますが、作成できるユーザー定義関数は他にもあります。 これらの機能は次のとおりです。
- ユーティリティ -これには、フレームワークの主要なメカニズムに関連する機能や、テスト対象のアプリケーションの基本機能へのアクセスを提供する機能が含まれます。 たとえば、アプリケーションの入力を担当する機能は、ユーティリティ機能と見なすことができます。 これらの機能は、要件から決定するか、自動化のために設計されたテストグループに関連付けられた「手動」テストケースに基づいて決定できます。
- ナビゲーション機能 -ほとんどのアプリケーションにはいくつかの主要な領域があり、テスト中の移行は繰り返し実行されます。 遷移の実装は基本的なコンポーネントであり、自動化プロセスの最初に簡単に決定できます。
- エラー処理関数 -テスト中に発生する可能性のある予期しない状況で動作するように作成されました。
- 他のすべての機能は、上記のどのカテゴリにも属していません。
機能的分解の利点
- コードの再利用の増加 -関数に分解されたコードのセクションはさまざまなテストでアクセスできるため、機能分解を適用した後、再利用の量が大幅に増加します。 ソースコードの冗長性は、作成された関数の抽象化レベルに応じて、1つのアプリケーションのすべてのテストと異なるアプリケーションのテストの両方で削減できます。 再利用量が増えると、サポートも容易になります。
- スクリプトの独立性 -機能分解フレームワークは外部コンポーネントを使用できますが、個々のテストは再利用されません。 これにより、スクリプトの独立性を維持しながら再利用を実装できます。
- 初期のスクリプト開発 -場合によっては、機能分解により、アプリケーションの準備が整う前に自動テストの開発を開始できます。 要件または他のドキュメントから取得した情報を使用して、トップダウンアプローチを使用してセルフテストを開発するために使用できるコンポーネントテンプレートを作成できます。
- 読みやすさ -スクリプトを論理コンポーネントに分割するとき、スクリプトを使用するときにどの結果が得られるかを視覚的に判断するだけで十分であるため、自動テストの保守が容易になります。
- 標準化の成長 -再利用可能なコンポーネントの数の増加に伴い、標準化が増加し、コードとそのサポートを記述する際の直感的なアクションの数が減少するため、自動テストの開発に役立ちます。
- エラー処理の簡単な実装 -さまざまなスクリプトのローカルエラー処理ソリューションは、追加および保守時に問題を引き起こします。 再利用可能なコンポーネントを使用すると、複数のスクリプトにまたがるエラー処理を実装できます。 最終的に、これにより自動テストの効率が向上します。
機能分解の欠点
- 技術的な知識が必要です。自動テストのフレームワークが第一世代のフレームワークよりも多くの技術的ソリューションを使用し始めた後、その設計、開発、サポートには、より技術的に有能な専門家が必要です。 これは、機能分解を使用するフレームワークに当てはまります。
- 直感的なアクションからの影響が少ない -高度なフレームワークを効果的に使用するには、直感への依存を減らし、標準への依存を増やす必要があります。 標準化は、機能的な分解のプラスの結果ですが、同時に、標準に関するデータのソースを提供し、標準を理解し、それらを適用できるようにする必要が生じます。 ほとんどの場合、フレームワークの機能を理解するには、それらを説明するドキュメントが必要です。
- サポートプロセスはより複雑になっています。フレームワークの複雑さが増すにつれて、自動テストをサポートする複雑さも増大しています。 線形スクリプトを使用する場合、修正は、動作を停止した自動テストのみに影響します。 これは冗長性につながる可能性がありますが(テスト対象のアプリケーションの1つの変更が一度に複数の自動テストの失敗につながる可能性があるため)、線形スクリプトを使用することでメンテナンスの複雑さが軽減されます。 機能分解を使用する場合、多くの場合、フレームワーク自体とそれを使用するスクリプトの両方のサポートが必要です。 これにより、サポート活動の範囲が縮小される可能性がありますが、同時に自動テストのサービスの複雑さが増します。
データの向き
このアプローチを使用して作成されたフレームワークは、スクリプトで使用されるコンポーネントのほとんどが主にこれらのスクリプト内にあるという点で、第1世代のフレームワークに似ています。 違いは、データの操作方法にあります。 データ指向フレームワークは通常、スクリプトの外部にあるソースに情報を保存します。 アプリケーションデータを入力し、外部データを対応するパラメーターに添付するためのフィールドをパラメーター化することにより、テストデータはスクリプト自体の内部に配置されません。以下は線形スクリプトの例です。
このスクリプトのデータ指向バージョンは、以下に示すような外部ソース(スプレッドシート、データベース、XMLファイルなど)からの情報を使用します。
- 「John」をユーザー名テキストボックスに入力します
- 「パスワード」テキストボックスに「JPass」を入力します
- [ログイン]ボタンをクリックします
- 「ようこそ画面」が存在する場合
- テストに合格する
- その他
- テストに不合格
- 終了する 場合
| 名前パラメータ | パスワードパラメータ |
|---|---|
| ジョン | JPass |
| スー | バイパス |
| ランディ | RPass |
| トリーナ | TPass |
データがスクリプトから削除され、パラメーターに置き換えられていることに注意してください。
- オープンデータテーブル
- Usernameテキストボックスに<NameParameter>を入力します
- パスワードテキストボックスに<PasswordParameter>を入力します
- [ログイン]ボタンをクリックします
- 「ようこそ画面」が存在する場合
- テストに合格する
- その他
- テストに不合格
- 終了する 場合
- データテーブルを閉じる
このアプローチにより、異なるコードで同じコードを使用できます。 多くの場合、データへの方向付けはフレームワークに反する手法と見なされますが、その使用は異なる情報を使用して同じスクリプトを再利用するのに役立ちます。 このアプローチは、線形シナリオに固有の問題の多くを解決しませんが、役に立つ場合があります。
データ指向の利点
- 再利用 -このアプローチにより、自動化されたテストを比較的簡単に再利用できます。 コードの一部をさまざまなデータで使用すると、スクリプト作成フェーズを最小限に抑えながら多くの自動テストを実行できます。
- 実装のシンプルさ -シンプルさは、既存のスクリプトへの最小限の更新のみが必要であり、多くの場合、既存のテストの本体をパラメーター化してループ内に含めるだけで構成されるという事実にあります。
データの向きの欠点
このアプローチの欠点には、線形スクリプトから継承された次の側面が含まれます( パート1を参照)。- 冗長性。
- 一次元性。
- 読むのが難しい。
- サポートするには、より高いレベルの知識が必要です。