
LDAモデルは、テキスト分析の古典的なタスクを解決します。つまり、大量のテキストの確率モデルを作成することです(たとえば、情報の取得や分類のため)。 私たちはすでに素朴なアプローチを知っています:テーマは隠された変数であり、単語は離散分布で独立して固定トピックで取得されます。 クラスタリングベースのアプローチも同様に機能します。 モデルを少し複雑にしましょう。
明らかに、単一のドキュメントにはいくつかのトピックがあります。 トピックに関するドキュメントをクラスター化するアプローチでは、これは考慮されません。 LDAは、2つのレベルで構成される階層型ベイジアンモデルです。
- 最初のレベル-コンポーネントが「テーマ」に対応する混合物。
- 2番目のレベルでは、文書内の「トピックの分布」を定義する先験的ディリクレ分布を持つ多項変数。
モデルのグラフを次に示します( ウィキペディアからの写真):
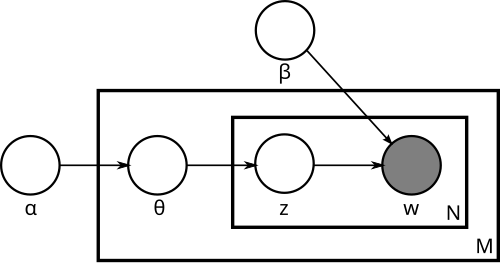
多くの場合、複雑なモデルは次のように理解するのが最も簡単です。モデルが新しいドキュメントを生成する方法を見てみましょう。
- ドキュメントの長さNを選択します(これはグラフに描画されません-モデルのその部分ではありません)。
- ベクトルを選ぶ
 -このドキュメントの各トピックの「表現度」のベクトル。
-このドキュメントの各トピックの「表現度」のベクトル。 - N個の単語wごとに:
- トピックを選択してください
 配布による
配布による  ;
; - 言葉を選ぶ
 βで与えられた確率で。
βで与えられた確率で。
- トピックを選択してください
簡単にするために、トピックの数kを固定し、βが単なるパラメーターのセットであると仮定します
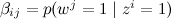 推定する必要があり、Nの分布について心配する必要はありません。共同分布は次のようになります。
推定する必要があり、Nの分布について心配する必要はありません。共同分布は次のようになります。
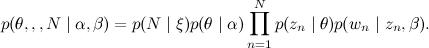
先験的ディリクレ分布または通常の単純ベイズを使用した従来のクラスタリングとは異なり、ここではクラスターを1回選択せず、このクラスターから単語をラップし、各単語について最初に分布によってトピックθを選択し、このトピックでこの単語の概要を説明します。
出力では、LDAモデルをトレーニングした後、各ドキュメントでトピックがどのように分布しているかを示すθベクトルと、特定のトピックでどの単語がより可能性が高いかを示すβ分布を取得します。 したがって、LDAの結果から、各ドキュメントについて、そのドキュメント内で見つかったトピックのリスト、および各トピックについて、そのドキュメントに特徴的な単語のリスト、つまり、 実際にはトピックの説明。 注:教師なしのこのすべてのトレーニング(教師なし学習)では、テキストからデータセットをマークアウトする必要はありません!
このすべてがどのように機能するかについては、正直に認めます。短いハブの投稿では、LDAに関する元の作業の結論がどのように整理されたかを伝えることができるとは思いません。 これは、モデルの分布に対する変分近似の検索に基づいていました(タイを壊すことでモデルの構造を単純化しますが、最適化するための自由変数を追加します)。 ただし、ギブスのサンプリングに基づいたはるかに簡単なアプローチがすぐに開発されました。 いつかサンプリングについて話をするときにこのトピックに戻るかもしれませんが、今ではこれにはフィールドが狭すぎます。 ここでMALLETへのリンクを残しましょう-最も人気があり、私が知る限り、LDAの最高の既製の実装です。 MALLETは、インターネット全体からトピックを分離する場合を除き、ほとんどすべての場合に十分です。MALLETクラスタでは、動作方法がわからないようです。
また、推奨システムにLDAを適用する方法について説明します。 この方法は、「格付け」がアスタリスクの長いスケールではなく、単にサーフィングバードのようなバイナリの「承認の表現」で与えられる状況に特に適しています。 アイデアは非常に単純です。 ユーザーを、好きな製品で構成されるドキュメントと考えてみましょう。 同時に、製品はLDAの「言葉」となり、ユーザーは「ドキュメント」となり、その結果、ユーザーの好みの「テーマ」が際立ちます。 さらに、特定のトピックに最も特徴的な製品を評価できます。つまり、対応するユーザーグループに最も関連性のある製品グループを選択し、ユーザーとトピックの分布からの製品の両方からの距離を入力することもできます。
この分析をSurfingbird.ruデータベースに適用しました 。 そして、多くの興味深いトピックを入手しました。ほとんどすべての場合、1つのトピックで結ばれ、互いに非常に似ているサイトのグループが際立っています。 以下の写真では、LDAを使用して取得したいくつかのトピックのページでよく見られる単語の統計を描画しました(LDA自体はページテキストでは機能しませんが、ユーザー設定でのみ機能します!)。 ページ自体へのリンクは、念のために切り取ります。
 |  |  |
 |  |  |