
検索エンジンが最初の一歩を踏み出した瞬間から、開発者はドキュメントの編成、ナビゲーション、検索の改善に多大な努力を費やしています。 現在、おそらく最もよく使用されている手法はキーワード検索であり、ユーザーは特定のトピックに関する情報を見つけることができます。 同時に、インターネットの世界的な拡大は、キーワードのみを使用して検索するときに人が見つける情報の量が多すぎるという事実につながります。 検索バーに同じ単語を入力すると、人によって結果が異なる場合があります。
図は、ノボシビルスクとエカテリンブルグの都市に住んでいるユーザーから尋ねられた同じクエリの様子を示しています。 検索エンジンに「空港」という単語を尋ねると、人々は都市空港ターミナルのウェブサイトのアドレスを取得したいことは明らかです。
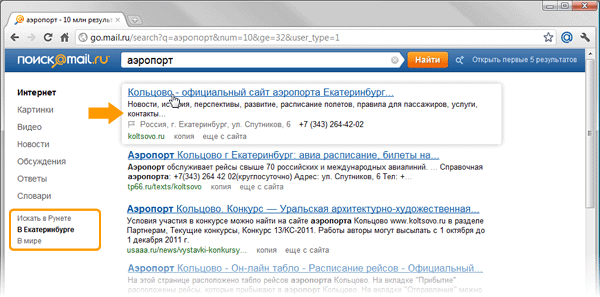

キーワード検索を使用してこのような問題を解決することは不可能です。 同時に。 これは、そのような情報を見つけるために使用できる高レベルのセマンティッククエリの形成の出発点になります。 したがって、これを使用して、追加のメタデータをページに添付できます。 検索エンジンの応答の品質を改善します。 たとえば、地理依存クエリの場合、そのようなメタデータはリソースの地理的位置に関する情報になります。 目的のオブジェクトが物理的にどこにあるかを知り、ユーザーの位置を知っていれば、これらのデータを関連付けて、目的のオブジェクトに関する情報を個人に提供できます。
一般的な場合、タスクは2つの部分に分けることができます。
a)ユーザーの場所を決定する。
b)探しているリソースの場所を決定する。
この記事では、問題の2番目の部分に対する解決策を提案します。 インターネットリソースの場所を特定する方法。
サイトの地理に関する情報を取得できるソースは多数あります。 これらには、WHOISベース、ディレクトリ、ページコンテキストなどが含まれます。この記事では、ページコンテキストの分析に基づいて、サイトを地理にリンクする方法を検討します。
サイトのページのコンテンツを分析します
原則として、地理に関する情報を提供できるソースは、場所のデータ(住所と電話番号)が公開されている組織のサイトです。 私たちの場合の情報抽出の問題の解決策は、いくつかの部分に分けます。
•組織の場所に関する情報を投稿できる標準サイトテンプレートの定義。
•サイトを地理情報にバインドするための候補を抽出する。
•候補者のフィルタリング。
標準パターンを定義します
この段階では、提案された住所が存在するページの検索パターンのセットを決定しようとします。 連絡先情報の最も一般的な場所の1つはルートページです。 同時に、このページは常に信頼できる情報源ではありません。たとえば、読みやすいアドレスを含む広告を掲載するサイトがあり、その一部はメインページに移動できるため、今後メインページから抽出されたアドレスをフィルタリングします。 連絡先情報の別の一般的な場所は、連絡先ページです。 原則として、メインページからのリンクがあり、ほとんどの場合、多くのルールが適用されます。 たとえば、リンクのテキストには、「contacts」、「About us」などの単語が含まれる場合があります。
さまざまな組織のサイト構造を分析した後、住所を見つけることができる最も一般的な典型的なページテンプレートを選択します。 簡単に言うと、次の3つの手順を書き留めることができます。
•サイトのルートページでアドレスを検索します。
•連絡先ページへのリンクを検索します。
•連絡先ページで住所を検索します。
住所の取得
上記で述べたように、最初の段階では、連絡先情報を配置できる最も可能性の高いページを取得します。 これらのページから、住所に非常によく似たものを抽出できます。 なぜ「非常に似ている」のか?なぜなら、抽出には隠れマルコフモデルを使用するからです。
モデルの構築を開始する前に、データを決定し、物事を少し単純化するようにします。 まず、ロシアの重要な都市の数は有限であり、それに応じて辞書で説明できると判断します。 最初の簡略化を取得しました-都市の辞書を使用して、ページ上の参照ポイントを見つけることができます。 最も可能性の高い連絡先ページにいる場合、見つかった都市が住所に含まれている可能性があります。
どうぞ エントリポイントから左または右に移動する場合。 アドレスを取得することはできますが、アドレスに含まれている可能性が高い文字のシーケンスを評価するシステムが必要です。 HMMまたは非表示のマルコフモデルがこれに役立ちます。 しかし、モデルを構築するには、次のデータを決定する必要があります。
•セットに属するモデルの状態
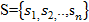 つまり、状態と間違われる可能性のあるもの。
つまり、状態と間違われる可能性のあるもの。
•セットに属するシーケンスvの要素
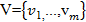 ; つまり、シーケンスの要素として解釈できるもの。
; つまり、シーケンスの要素として解釈できるもの。
たとえば、アドレス:654007、ノボクズネツク、st。 Ordzhonikidze、36、およびシーケンスVおよび状態Sの要素を選択します。
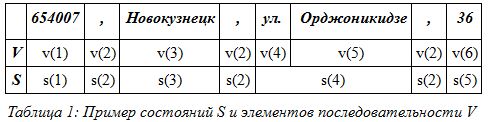
表1からわかるように、シーケンスの6つの要素とモデルの5つの状態を取得しました。 したがって、個々の単語をシーケンスの要素として使用すると、モデルを計算するときにこれが何につながるかを想像できます。 ただし、いくつかの単純化を行って、セットSの状態の数とセットVのシーケンスの要素の数を減らします。表1をよく見ると、状態s(2)の要素とシーケンスv(2)の要素が繰り返されていることがわかります。 アドレスのすべての要素がタイプに分割されている場合、これによりモデルの状態が低下します。 たとえば、すべてのストリート修飾子を1つの要素に結合できます。 この場合、通り、高速道路、車線...は、シーケンスの要素を形成します
 。 したがって、2番目の簡略化-よく知られている多くの地理的な名前のシーケンスの1つの要素への変換を取得します。 テーブル形式で例を示します。
。 したがって、2番目の簡略化-よく知られている多くの地理的な名前のシーケンスの1つの要素への変換を取得します。 テーブル形式で例を示します。

したがって、セットVの19個の型付き要素のみを取得します。同じことが、セットSでも、つまりモデルの状態でも実行できます。 たとえば、分析中にモデルが道路に関する情報を提供する場合、モデルが州S(道路)にあると言い、モデルが都市に関する情報を提供する場合、私たちは言います。 モデルが状態T(市)にあること。 モデル状態の3番目の簡略化を取得します。 表3に例を示します。

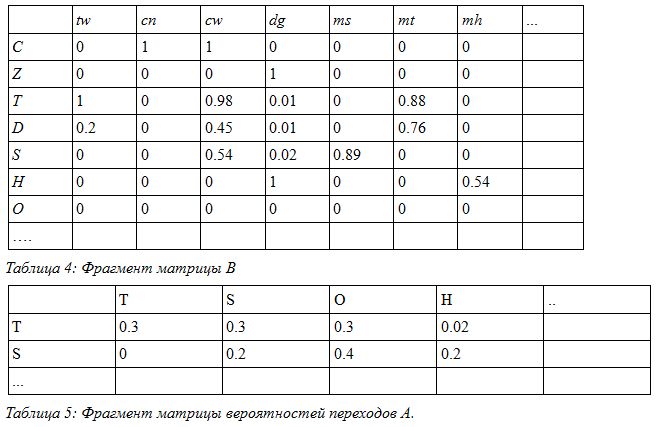
これで、モデルの状態とシーケンス要素の説明がわかったので、モデルが構築されるトレーニングセットを作成します。 トレーニングセットから、遷移確率行列AおよびBを、モデルが状態sにある時点でセットVからデータを受け取る確率行列として取得する必要があります。
たとえば、この場合、マトリックスBとAのフラグメントは次のようになります。
図を完成させるために、初期分布も考慮する必要があります
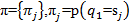 。 そして今、モデルを構築したとき、短い記録では次のようになります
。 そして今、モデルを構築したとき、短い記録では次のようになります 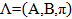 見つかった都市を囲むシーケンスDを取得し、単語、つまりデータがモデルに類似している確率を見つけます。 確率を考慮します。
見つかった都市を囲むシーケンスDを取得し、単語、つまりデータがモデルに類似している確率を見つけます。 確率を考慮します。
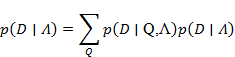
この問題では、都市の近くでアドレスシーケンスが出現する確率を計算するだけでよいため、「フォワードバックワード」アルゴリズムを使用してそれを解決します。
受信したデータをフィルタリングします
抽出されたアドレスはフィルタリングされます。 フィルタリングの最初の段階では、電話などの追加情報もページから抽出され、ページから取得された1つ以上のアドレスにマップされます。
比較の1つは、電話番号で示された地域コードを、住所で指定された都市と照合することです。
フィルタリングの2番目の段階には、選択したアドレスに重ねられる一連の経験則が含まれます。 たとえば、このようなルールには、家番号に含まれる桁数の制限が含まれます。 多数のルールを適用した後、抽出された住所は、組織の場所を説明する住所の1つとして受け入れられるか、拒否されます。
何を得たの?
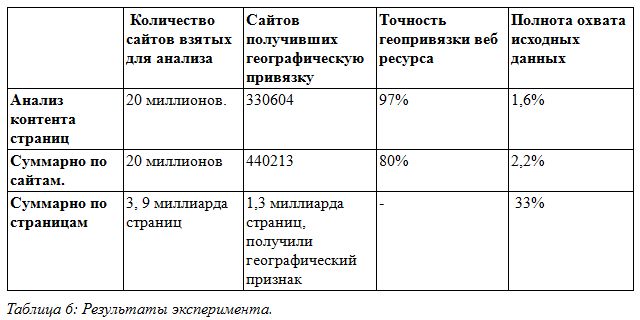
実験のために、インターネットからダウンロードしたページのデータベースを取得しました。これには、約2,000万のサイトと39億のページが含まれています。 このデータから、ページのコンテンツの分析に基づいて、サイトは上記のアルゴリズムを使用して地理参照されました。 結果を表6に示します。
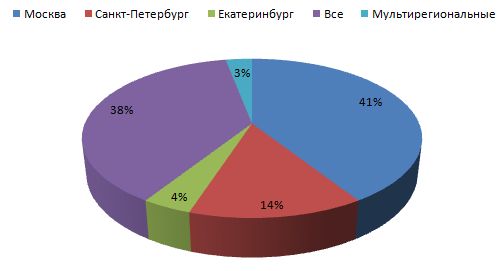
実験が示したように、説明された方法は非常に正確です。 彼の場合、精度は97%に達します。 これは、いくつかの制限によるものです。つまり、事前に定義されたテンプレートを使用して、アドレスのあるページを検索します。 都市の辞書を使用します。 一致する電話番号と都市、および住所を記録するための既存の正式なルール。 これらすべての制限により、Webリソースの地理を決定するときに高い精度を実現できます。 一方、これらの制限は、連絡先ページが既知の検索テンプレートに記載されていない住所にある場合、住所が都市の直接の表示なしで、または未知の都市で記録される場合、完全性の低下につながります。 図1は、地域ごとのサイトの分布を示しています。図からわかるように、モスクワはサイトが属する最大の地域です。
現在、サイトの地理参照に関する情報を抽出し、検索エンジンのインデックスに追加する方法の1つとして、説明されている方法を使用しています。 したがって、人は自分の地域のサイトで情報を検索できます。 また、抽出された住所は住所スニペットに表示できます。
ドミトリー・ソロヴィヨフ
検索開発者: Mail.Ru