「理解の複雑さ」の順序で最適化を構築しようとしますが、これは非常に主観的です。
そしてもう1つ:一部の名前と用語は確立されておらず、「誰かのように」使用されるため、いくつかのオプションを提供しますが、英語の用語を使用することを強くお勧めします。
エントリー
(スキップする最適化タイプについての理論のかなりの部分)
優れたアイデアとアルゴリズムに飛び込む前に、理論に少し飽きてみましょう。最適化とは何か、それらは何のためにあるのか、何が最適なのか、そうでないのかを理解します。
まず、定義を示しましょう( ウィキペディアから ):
プログラムコードの最適化とは、機能を変更せずにパフォーマンスやコンパクトさなどの特性を改善するために、最適化コンパイラまたはインタープリターによって実行されるプログラムの修正です。この定義の最後の3つの単語は非常に重要です。プログラムの特性の最適化がどのように改善されても、どのような条件下でもプログラムの元の意味を維持する必要があります。 たとえば、 GCCにはさまざまなレベルの 最適化があります (これらのリンクに従うことを強くお勧めします) 。
さらに進んでください:最適化はマシンに依存しない (高レベル)およびマシンに依存する (低レベル)です。 分類の意味は名前から明らかであり、マシン依存の最適化では具体的なアーキテクチャの特定の機能が使用され、高レベルの最適化ではコード構造のレベルで発生します。
最適化は、その適用分野に応じて、ローカル(オペレーター、オペレーターのシーケンス、ベースユニット)、手順内、手順間、モジュール内、およびグローバル(プログラム全体の最適化、「アセンブリ中の最適化」、 「リンク時最適化」 )に分類することもできます。
あなたは今眠りに落ちると思う、理論のこの部分を終えて、最適化自体を検討し始めましょう...
一定の折りたたみ
(定数の最小化/最小化)
コンパイラで最も単純で、最も有名で、最も一般的な最適化。 「定数の折りたたみ」のプロセスには、定数のみを含む式(または部分式)の検索が含まれます。 このような式はコンパイル段階で計算され、結果のコードの計算値に「縮小」されます。
例を考えてみましょう( 頭からその場で発明された、完全に合成された、些細な、抽象的、無意味、現実から遠い、など ...そしてすべての例はこのようになります):
| 最適化前 | 最適化後 |
|---|---|
| |
"p"
のサイズ(
sizeof
)も定数であり、コンパイラーはそれを知っているため、次のようになります。
| 展開サイズ | 崩壊を完了する |
|---|---|
| |
コードが抽象構文ツリー ( AST )として提示されている場合、すべてが非常に簡単です。 次に、数値式と部分式を見つけるには、数値のみを含む同じレベル(つまり、共通の祖先を持つ)のツリーノードを検索するだけで十分です。 次に、親(親)の値を折りたたむことができます。 わかりやすくするために、式の1つのツリーの簡単な例を考えてみましょう。
"int a = 32*32;"
:
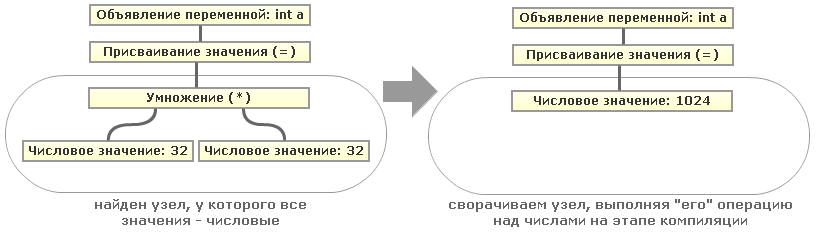
つまり、ASTツリーを再帰的に走査することで、このような定数式をすべて折りたたむことができます。 ちなみに、数字を使用した操作の代わりに、数字を使用した例が再び簡略化され、 文字列を使用した操作 (連結)または文字列と数字を使用した操作 (Pythonの「
'-' * 10
」のアナログ)またはソース言語でサポートされている他のデータ型の定数がある場合がありますプログラミング。
一定の伝播
(定数の伝播)
この最適化は、通常、「一定の折り畳み」と関連して常に説明されます(それらは互いに補完するため)が、これは別の最適化です。 「定数の伝播」のプロセスには、実行可能なあらゆるパスで定数となる式の検索(この式を使用する前)およびこれらの値での置換が含まれます。 実際、すべては見た目よりも単純です。既に使用したのと同じ例を取り上げましょう。ただし、 「定数の折りたたみ」を最適化することで、すでにその上を歩いているという事実を考慮してみましょう。
| 最適化前 | 最適化後 |
|---|---|
| |
"a"
と
"b"
の値は、宣言と計算での値
"c"
使用の間で変更できないため、コンパイラは式の値を置換して評価できます。
つまり、コンパイラーは、各式の値が常に一定であるかどうか(または、変更できるかどうか)をチェックする必要があります。 スケッチしてみましょう:
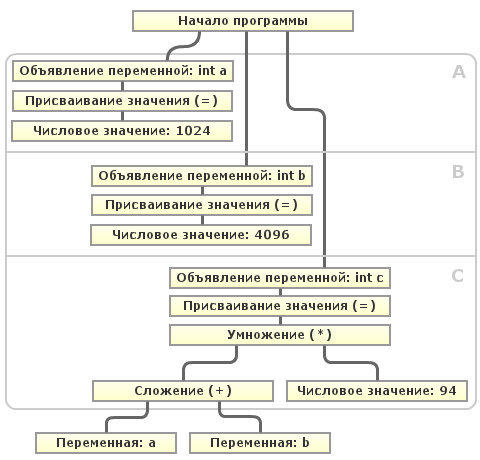
コンパイラが次回の最適化実行中に変数
"a"
と
"b"
の使用を検出したと仮定します。 図からわかるように、ブロックAの変数
"b"
とブロックBの変数
"b"
を宣言した後、どちらの変数も、使用する前に後続のブロック(A、B、C)の値を変更できません。 プログラム全体が線形であり、いわゆるベースユニット ( BB )であるため、このケースは簡単です。 しかし、基本単位の変数の「変動性」を決定するためのアルゴリズムは、決してすべてとは言えません。 プログラムには、条件付き構成、ループ、無条件ジャンプなどが含まれる場合があります。 次に、変数の「変動性」を判断するには、頂点、エッジ-ベースブロック間の制御の移動にベースブロックを持つ有向グラフを作成する必要があります。 このグラフは制御フローグラフ( CFG )と呼ばれ、多くの最適化を実装するために使用されます。 この列では、変数の初期化から使用までに必要なすべての基本ブロックを定義し、変数の値が変数内で変更できるかどうかをブロックごとに決定できます。 変更できない場合、コンパイラはその値を定数に簡単に置き換えることができます。
通常、定数伝播と定数折りたたみは、プログラムコードに変更が加えられなくなるまで数回実行されます。
コピー伝播
(コピーの配布)
これは、以前の2つの最適化のもう1つのコンパニオンです。ほぼ双子の兄弟「定数フォールディング」は非常によく似た仕事をしますが、不必要な(中間)変数割り当てを取り除き、式の中間変数を置き換えます。 これは、最も単純な例でより明確になります。
| 最適化前 | 最適化後 |
|---|---|
|
|
デッドコード除去(DCE)
(アクセスできないコードの削除/除外)
非常にシンプルですが、残念ながら、パフォーマンスの最適化に関してはほとんど改善されていません。 簡単です。プログラムで使用できないコードは削除できます。 「デッド
| 最適化前 | 最適化後 |
|---|---|
| |
printf("Hi, I'm dead code =( !");
"は、どのような状況でも達成できません
printf("Hi, I'm dead code =( !");
プログラムが無限に実行されるか、「強制的に」終了します。
| 最適化前 | 最適化後 |
|---|---|
|
|
printf("x = %d \n", &x);
"は、前の例と同様に、プログラム実行パスでは達成できず、メイン関数の最初の行で宣言された変数yは使用されません。
さて、この最適化の最後の例:
| 最適化前 | 最適化後 |
|---|---|
| |
一方、プログラム内の「デッドコード」は、制御フローグラフを使用して非常に簡単に見つけることができます 。 プログラムにデッドコードがある場合、グラフは一貫性がなく、グラフの個々のフラグメントを「捨てる」ことができます。 一方、アドレス演算やその他の多くのニュアンスを考慮する必要があります -コードが「デッド」であるかどうかを明確に判断できるとは限りません。
一般的な亜発現除去(CSE)
(共通の部分式の削除)
非常に便利で「美しい」最適化。 式の計算を2回以上使用する場合、1回計算してから、それを使用するすべての式に代入できます。 さて、例のない私たちはどこにいますか:
| 最適化前 | 最適化後 |
|---|---|
| |
PS実際、私はそれぞれの最適化のダイアグラムを提供したかったのですが、すみません、描画するのは2つだけでした。
PPS図やグラフを描くための便利なサービスを教えてください。
PPPS継続するには?