こんにちは、ハラジテリ。 GPLライセンスの下で「テキストアナライザー」( [1] )を公開したいとずっと思っていました。 最後に、手が届きました。 「テキストアナライザー」は、大学の第3、第4、第5コースで3年間開発した研究プロジェクトです。 主な目標は、ハミングまたはホップフィールドニューラルネットワークを使用して、テキスト作成者認識アルゴリズムを作成することでした。 アイデアはこれでした。これらのニューラルシステムは画像を認識し、原作者を識別するタスクは画像を認識するタスクに減らすことができます。 これを行うには、各テキストの統計を収集する必要があり、より異なる基準、より良い:文字の頻度分析、単語/文/段落の長さの分析、2文字の組み合わせの頻度分析など。 神経系は、どのテキストが最も似ているかの特徴を明らかにすることができます。 仕事がありました-シャフト。 大量のコード、トリッキーなアルゴリズム、OOP、デザインパターン。 主なタスクに加えて、「調和のカード」という別のノウハウも実装しました。 計画どおり、このようなカードには、悪い音や良い音の場所がすべて表示され、色で強調表示されます。 調和を評価するための基準は、例えば規則など、何らかの普遍的な方法で与えられるべきです。 この目的のために、特別なグラフィック言語であるRRL(Resounding Rules Language)を開発しました。 仕事がありました-シャフト。 大量のコード、トリッキーなアルゴリズム、OOP、デザインパターン。 その結果、見苦しいインターフェースを備えた大規模で複雑なプログラムが作成されました。 このプロジェクトで、私は卒業証書コンテストに勝ち、大学の会議で1位と3位になり、国際的な科学と実践の2位になりました。
2年以上が経ちましたが、どのように機能するかはほとんど覚えていません。 一緒に作者を認識するアルゴリズムの内部にあるものを把握してみましょう。 さて、次の記事のために調和カードを残しましょう。
(記事には続編とエンディングがあります。)
記事の構造:
追加資料:
- テキストアナライザープロジェクトのソース (Borland C ++ Builder 6.0)
- Excelでハミングニューラルシステムをテストする( [xls] )
- テキストをレベルに分割する宇宙船の遷移表( [xls] )
- 個々の文字の調和の計算( [xls] )
- テキストアナライザーディプロマプロジェクトのプレゼンテーション( [ppt] )
- 「Map of Harmony」プロジェクトのプレゼンテーション( [ppt] )
- これらの素材はすべて圧縮されています( [zip] 、 [7z] 、 [rar] )
1.著者分析
必要性:
- サンプルテキストと「キー」テキスト(作成者は不明)をアップロードします。
- 比較可能なサンプルテキストを特定します。
- テキストを単語、文、段落に分割し、
- 各テキストに対して同じ長さの単語、文章、段落のブロックを作成し、
- 「単語」、「文」、「段落」のレベルについて、同じサイズの比較可能なブロックのみを選択します。
- これらの3つのレベルで統計を収集します。
- Hamming神経系にデータをアップロードします。
- その助けを借りて画像認識を行います。
- 特性によってキーテキストに最も近い3つのレベルすべてのサンプルテキストを識別する。 これらのテキストの著者は、おそらくキーテキストを所有しています。
計画からの結論は次のとおりです。
- テキストに応じて、最大メガバイトまでの大量のデータを処理します。
- テキストは、ストーリーから複数巻の小説まで、まったく異なるサイズにすることができます。 したがって、さまざまな作品の基本的な比較可能性を何らかの形で保証する必要があります。
- ポイント2は、認識の精度を高め、レベルによってプロセスを区別し、テキストの基本的な比較可能性を提供するために必要です。
- テキストを単語、文、および段落に解析することは、ステートマシンのタスクです。
- さまざまな統計情報が存在する可能性があります。他の収集アルゴリズムをいつでも追加できるように、普遍的な方法で収集したいと思います。
- Hamming神経系は特定の情報でのみ機能します。つまり、収集したデータを理解できる形式に変換する必要があります。
2.コードを知る
「ウォームアップ」するために、最初にメインフォームのクラスTAuthoringAnalyserTable( [cpp] 、 [h] )を検討します。 (「ウォームアップ」が必要ない場合は、すぐに次のセクションに進むことができます。)フォーム自体はひどく使い勝手がよく、ゼロであると言えます。 しかし、私たちはボタンボタンではなくコードに興味があります。
cppファイルの最初に、クラスのインスタンス化があります。
Copy Source | Copy HTML TVCLControllersFasade VCLFasade; // 1 - VCL TAnalyserControllersFasade AnalyserFasade; // 2 - TVCLViewsContainer ViewsContainer; // 3 -
Copy Source | Copy HTML TVCLControllersFasade VCLFasade; // 1 - VCL TAnalyserControllersFasade AnalyserFasade; // 2 - TVCLViewsContainer ViewsContainer; // 3 -
Copy Source | Copy HTML TVCLControllersFasade VCLFasade; // 1 - VCL TAnalyserControllersFasade AnalyserFasade; // 2 - TVCLViewsContainer ViewsContainer; // 3 -
Copy Source | Copy HTML TVCLControllersFasade VCLFasade; // 1 - VCL TAnalyserControllersFasade AnalyserFasade; // 2 - TVCLViewsContainer ViewsContainer; // 3 -
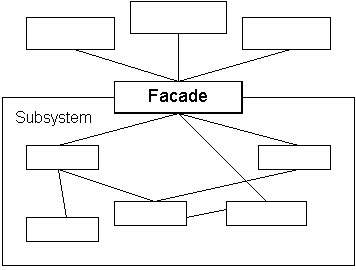
ここでは、(1)および(2)に対して「Facade」パターンが使用されます(Facade、 [1] 、 [2] 、 [3] 、 [4] )。 ファサードクラス(1)内には、VCLのビジュアルコンポーネントを操作するための大きなインターフェイスが隠されています。 「テキストのダウンロード」ボタンをクリックしたとき、テキストのリストを更新したとき、一般的にフォームからのイベントに対する反応が登録されます。 フォームは、何が起こるかを知らずにこれらの関数にアクセスします。 ファサードは、フォームから不要なものをすべて隠します。 しかし、実際には、VCLFasade( [cpp] 、 [h] )はフォームとアルゴリズムからのイベントのみを接続します。 これらのアルゴリズムはありませんが、別のファサードのどこかにあります-(2)、AnalyserFasade( [cpp] 、 [h] )。 クラス(1)は単に呼び出しをオブジェクト(2)にリダイレクトするだけで、リストの視覚コンポーネントに入力するなどの追加作業を行います。 はい、そのような巨大な構造:オブジェクト(1)はオブジェクト(2)とその機能を知っています。 彼はどうやって知っていますか? メインフォームのコンストラクターでは、少し下に、2番目のファサードによるパラメーター化があります。
Copy Source | Copy HTML
- // .......
- VCLFasade.SetAnalyserControllersFasade(&AnalyserFasade); //別のオブジェクトによる1つのオブジェクトのパラメーター化。
- // .......
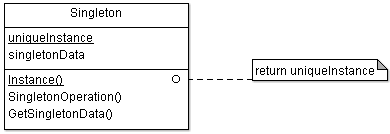
現在、クラス(1)がファサードであるかどうかはわかりません。おそらく他の何か、あるいはそれだけです。 ファサードを「シングル」パターン(シングルトン、 [1] 、 [2] 、 [3] 、 [4] )に配置するとよいでしょう。 残念ながら、2年前、私はこれを考えていませんでした。 プログラムが苦しんでいるわけではなく、いや、すべてが機能するはずです。 しかし、Lonerパターンに関連する可能性のいくつかは失われています。 結局のところ、1つのサブシステムに複数のエントリポイントを作成することはできませんか? できません。 それは禁止する価値があるでしょう。
メインフォームコンストラクターで他に興味深いものは何ですか?
Copy Source | Copy HTML
- // .......
- VCLFasade.SetViewsContainer(&ViewsContainer); //ファサード(1)で、ビューのコンテナが転送されます
- VCLFasade.SetAuthoringAnalyserTable( this ); //およびメインフォームへのポインタ。
- / *注:hファイルの周期的な包含と、 場合によっては事前決定 がどこかにあると結論付けることができます 。 もちろん、これは悪いことですが、そのようになったのです。 * /
- //レポートシステムによるファサード(2)のパラメーター化:
- AnalyserFasade.SetAuthoringAnalysisReporter(&AnalysisReporter);
- AnalyserFasade.SetResoundingAnalysisReporter(&AnalysisReporter);
- // .......
そしてさらに-視覚的なコンポーネント(コントロール)のコンテナを埋めるための大きなシート。 要素(ボタンなど)はフォームから取得され、コンテナーに入力され、独自のグループになります。
Copy Source | Copy HTML
- // .......
- TVCLViewsContainer * vc =&ViewsContainer; //名前を短くします。
- vc-> AddViewsGroup(cCurrentTextInfo); //コンポーネントのグループcCurrentTextInfo-グループのテキスト名を作成します。
- vc-> AddView(cCurrentTextInfo、LCurrentTextNumber); // LCurrentTextNumber、LCurrentTextAuthor、
- vc-> AddView(cCurrentTextInfo、LCurrentTextAuthor); // LCurrentTextTitleなどは、ビジュアルコンポーネントへのポインタです。
- vc-> AddView(cCurrentTextInfo、LCurrentTextTitle); //例:TLabel * LCurrentTextNumber;
- vc-> AddView(cCurrentTextInfo、CLBTextsListBox);
- vc-> AddView(cCurrentTextInfo、MSelectedTextPreview);
- vc-> AddViewsGroup(cKeyTextInfo); //別のグループを作成します。
- vc-> AddView(cKeyTextInfo、LKeyTextNumber);
- vc-> AddView(cKeyTextInfo、LKeyTextAuthor);
- vc-> AddView(cKeyTextInfo、LKeyTextTitle);
- vc-> AddView(cKeyTextInfo、CLBTextsListBox);
- // ...など...
かなり不思議なアプローチですが、あまり明確ではありません。 コントロールはコンテナ(3)に転送され、コンテナはファサード(1)に転送されます。 そこでは、明らかに、コントロールが何らかの形で使用されます。 クラスTVCLViewsContainer( [cpp] 、 [h] )およびTVCLView( [h] )を確認した後、コントロールで行われるすべてが更新、表示/非表示、有効化/無効化、およびグループであることが明らかになります。 名前を知っているだけで、1つのグループを完全に更新し、別のグループを非表示にすることができます。 このアプローチはカプセル化に違反します。これは、削除を含め、コントロールを使用して何でもできるためです。 それらはフォームの括弧から外され、変更されるリスクがあります。
メインフォームクラスにはこれ以上面白いものはありませんので、クラス(2)( [cpp] 、 [h] )を詳しく見てみましょう。 この2番目のファサードはジョークなしですでに本物です。ただし、名前はCではなくSで記述されていることを除きます(「ファサード」-GOF( [1] 、 [2] 、 [3 ] ))。 このクラスは、分析サブシステムとの作業を簡素化し、インターフェースの背後にある実際のクラスを隠します。 そして、3つの実際のクラスがあります。
Copy Source | Copy HTML
- TAnalyserControllersFasade クラス
- {
- TTextsController _TextsController;
- TAuthoringAnalyser _AuthoringAnalyser;
- TResoundingMapAnalyser _ResoundingAnalyser;
- // .......

TAnalyserControllersFasadeクラスの単純な関数は、3つの実際のクラスのより複雑な関数にアクセスしますが、クライアントはこの複雑さについて何も知りません。 これにより、開発と使用が簡素化されます。 テキストをロードし(関数LoadAsPrototype()、LoadAsKeyText())、アナライザー設定をロードし(LoadResoundingAnalysisRules())、分析を実行し(DoAnalysis()関数)、そこのどこかで魔法のように機能します。 DoAnalysis()関数を詳しく見ると、目的の分析がテキスト名によって呼び出されていることがわかります。 いいですね 悪いニュースは、ファサードと組み合わせると、これは非常に拡張可能なソリューションではないということです。 文法チェックなど、さらに分析を行う場合は、4番目の実際のクラスであるGrammarAnalyserを追加し、ファサードにいくつかの追加機能を記述する必要があります。 そして、万能テキスト分析ツールを作成し、そのようなアナライザーを持っている場合-闇と闇? それから私は統一されたインターフェースを考え出し、分析器よりも抽象化を上げ、実行時にアルゴリズムを変更可能にしなければなりません...それは非常に...とてもそうです。 幸いなことに、私は巨人症のマニアが少し少なくなりましたが、そのときは必要ありませんでした。
3. TAuthoringAnalyserの内部とテキストストレージ
TAuthoringAnalyser( [cpp] 、 [h] )クラス-著者の真の分析を行う実際のクラスを見てください。 h-ファイルの最初の部分では、巨大なtypedefが印象的です。
Copy Source | Copy HTML
- クラス TAuthoringAnalyser : パブリック TAnalyser
- {
- 公開 :
- typedefマップ< TTextString 、ParSentWordFSM :: TCFCustomUnitDivisionTreeItem、 less < TTextString >> TTextsParSentWordTrees;
- typedefマップ< TUInt 、TRangeMapsEqualifer :: TEqualifiedMapsContainer、 less < TUInt >> TLeveledEqualifiedMaps;
- typedefマップ< TUInt 、 TFrequencyTablesContainer 、 less < TUInt >> TLeveledFrequencyContainers;
- typedefマップ< TUInt 、 TTextString 、 less < TUInt >> TIndexToAliasAssociator ;
- typedefマップ< TUInt 、 TIndexToAliasAssociator 、 less < TUInt >> TLeveledIndexToAliasAssociators;
- // <安全でないコード> //注:このコードが安全ではない理由、覚えられない可能性が高い...
- typedefマップ< TUInt 、 TResultVector 、 less < TUInt >> TLeveledResultVectors;
- // </安全でないコード>
- // .......

これらのタイプは、すべての中間データ、計算、結果を保存するために必要です。 したがって、TTextsParSentWordTreesには明らかに構造的なテキストツリーが含まれています。「すべてのテキスト->段落->文->単語」。 TLeveledFrequencyContainersには、テキストのレベル分布頻度特性などが含まれます。 また、すべての組み込み型( [h] )が再定義されていることにも気付くことができます。 TUInt == unsigned int、TTextString == AnsiString。 いつ役立つか想像するのは難しいです。 もちろん、オーバーライドされた型は、プロジェクトファイルに変更を加えることなく、すぐに変更できますが、そのような状況はどのくらいの頻度で発生しますか? 32ビット整数が欠落していることが突然判明したときは? 突然AnsiStringが満足しなくなり、std :: stringが必要になりましたか? 状況は仮説にすぎず、これは主に不十分に設計されたプログラムで発生します。 場合によっては、タイプが再定義され、実際には干渉せず、実際に助けにならず、それに慣れる必要があります。
ファサードアナライザーの保護されたセクションで、これらのオブジェクトおよび他のタイプのオブジェクトが宣言されています。
Copy Source | Copy HTML
- // .......
- プライベート :
- TTextsConfigurator * _AllTextsConfigurator;
- TTextsConfigurator _AnalysedTextsConfigurator;
- TTextsParSentWordTrees _Trees;
- TLeveledEqualifiedMaps _LeveledEqualifiedMaps;
- TLeveledFrequencyContainers _FrequencyContainers;
- TLeveledIndexToAliasAssociators _IndexToAliasAssociators;
- // .......
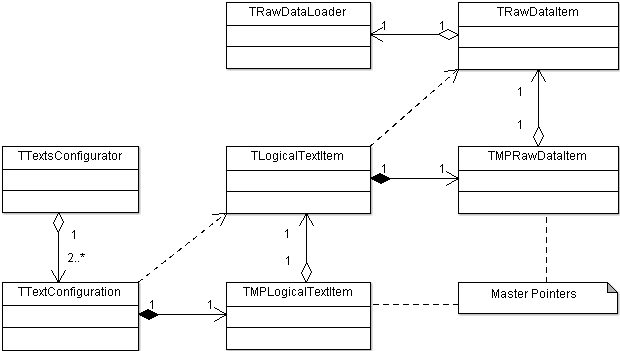
TTextsConfiguratorクラスには複雑な構造があります。 彼の仕事には、テキストのダウンロード、保存、提供があります-深いコピーなし。 パラメータで渡されたテキストが完全にコピーされた場合、プログラムは適切です。 その場合、メモリもプロセッサ時間もありません。 したがって、TTextsConfiguratorはポインターを介したアクセスを提供します。 一度読み込まれると、テキストは常に利用できると考えられています。 「Text Configurator」には追加情報も保存されます。テキストは例であるか、キーですか。 テキストがアクティブ化されているかどうか(プログラムでは分析からテキストを除外できます)、作成者、タイトルなど。 この実装方法は、クラスTTextsConfigurator( [cpp] 、 [h] )、TTextConfiguration( [cpp] 、 [h] )TLogicalTextItem && TMPLogicalTextItem( [h] )、TRawDataItem && TMPRawDataItem( [cpp] 、 [] )で見ることができます。およびTTextDataProvider( [cpp] 、 [h] )。 これらのクラスのオブジェクトが互いに埋め込まれるのはこの順序であり、一種のネストされた人形を取得します。 アイデアは、テキストの論理表現と物理表現を分離し、ソースやテキストが保存されている形式について何も知らなくても「生データ」を異なるソースからダウンロードする機能を提供することでした。 したがって、生データローダーを変更できます。 とりわけ、「マスターポインター」( [1] 、 [2] )という仮説でスマートポインターパターン(TMPRawDataItemおよびTMPLogicalTextItemクラス)を使用します。 また、テキストの物理的な表現から抽象化できるクラス階層もあります。 これはすべて私にはほとんど役に立ちませんでした。 多分私は余分な仕事をしたが、多くの経験とポジティブな感情を得た。