Hello! My name is Alexey Skorobogaty, I am a system architect at Lamoda. In February 2019, I spoke at Go Meetup while still in the team lead position of the Core team. Today I want to present a transcript of my report, which you can also see.
Our team is called Core for a reason: the area of responsibility includes everything related to orders in the e-commerce platform. The team was formed from PHP developers and specialists in our order processing, which at that time was a single monolith. We were engaged and continue to deal with its decomposition into microservices.

An order in our system consists of related components: there is a delivery unit and a basket, discount and payment units, and at the very end there is a button that sends the order to be collected at the warehouse. It is at this moment that the work of the order processing system begins, where all order data will be validated and the information aggregated.
Inside all this is complex multicriteria logic. Blocks interact with each other and influence each other. Continuous and constant changes from the business add to the complexity of the criteria. In addition, we have different platforms through which customers can create orders: website, applications, call center, B2B platform. As well as stringent SLA / MTTI / MTTR criteria (registration metrics and incident resolution). All this requires high flexibility and stability from the service.
Architectural heritage
As I already said, at the time of the formation of our team, the order processing system was a monolith - almost 100 thousand lines of code that directly described business logic. The main part was written in 2011, using the classic multi-layer MVC architecture. It was based on PHP (the ZF1 framework), which was gradually overgrown with adapters and symfony components for interacting with various services. During its existence, the system had more than 50 contributors, and although we managed to maintain a unified style of writing code, this also imposed its limitations. In addition, a large number of mixed contexts arose - for various reasons, some mechanisms were implemented in the system that were not directly related to order processing. All this led to the fact that at the moment we have a MySQL database larger than 1 terabyte.
Schematically, the initial architecture can be represented as follows:
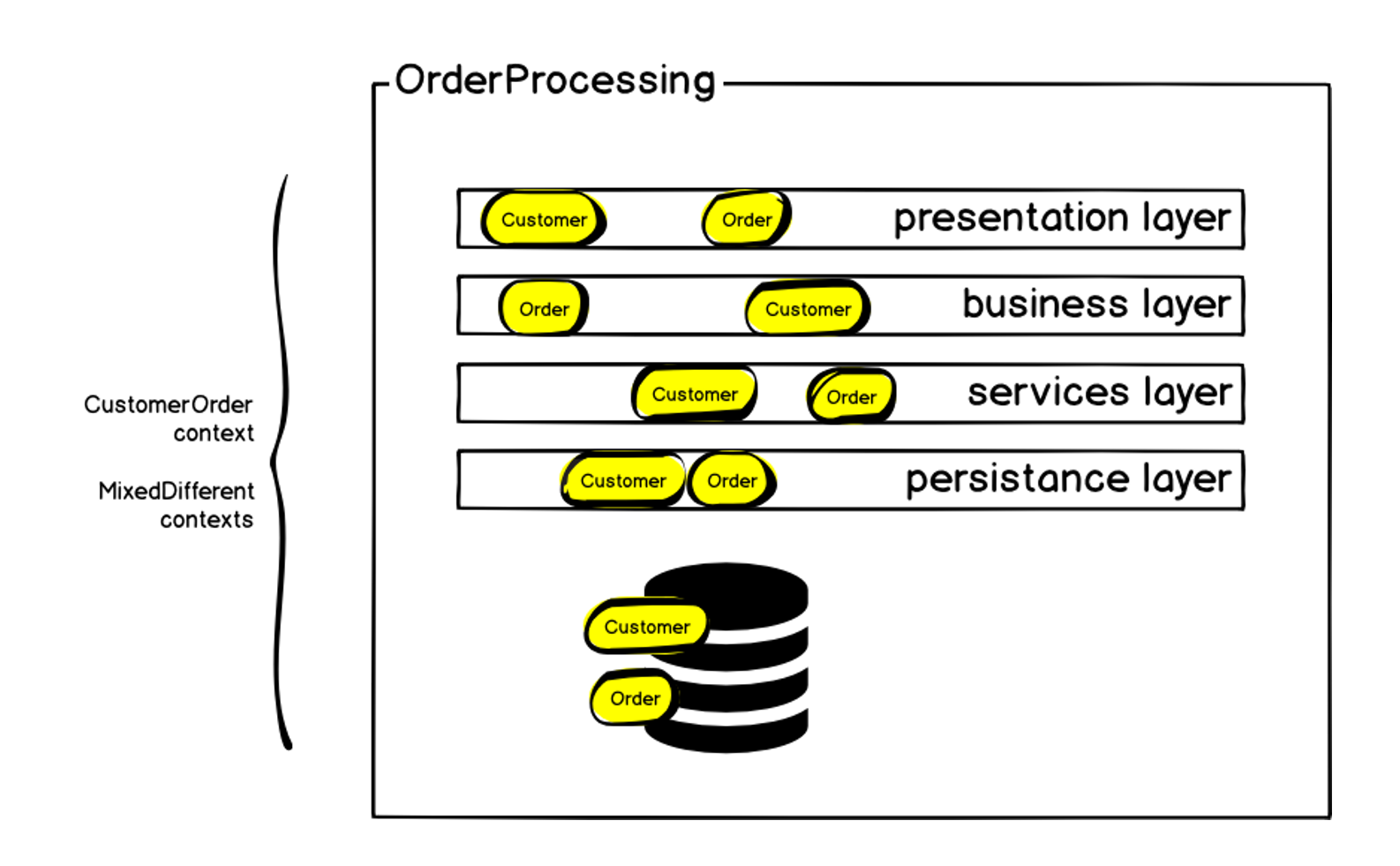
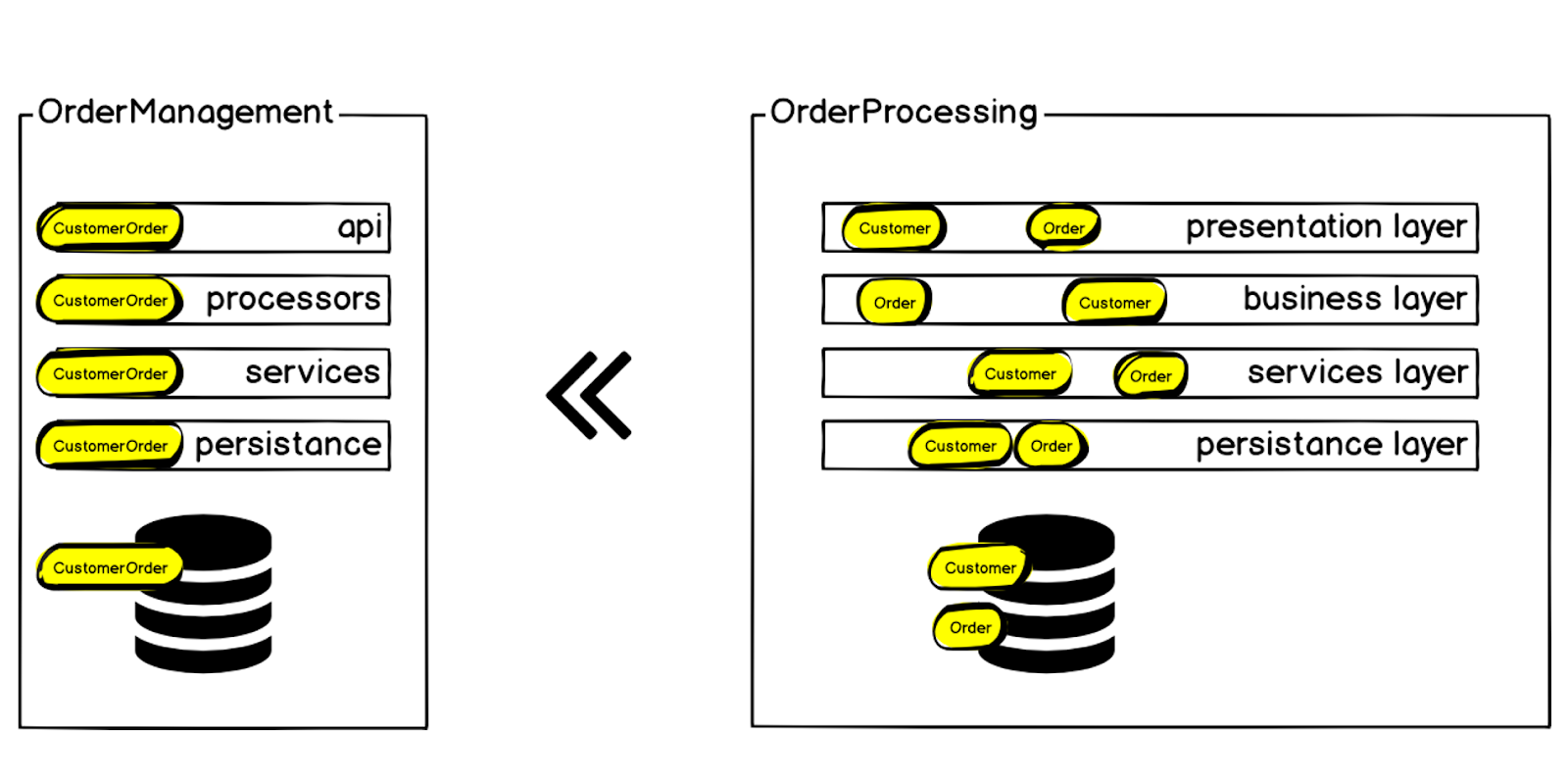
The order, of course, was on each of the layers - but in addition to the order, there were other contexts. We started by defining the bounded context of the order and calling it the Customer Order, since in addition to the order itself, there are the very blocks that I mentioned at the beginning: delivery, payment, etc. Inside the monolith, all this was difficult to manage: any changes led to an increase in dependencies, the code was delivered to the prod for a very long time, and the probability of errors and system failure increased all the time. But we are talking about creating an order, the main metric of an online store - if orders are not created, then the rest is not so important. System failure causes an immediate drop in sales.
Therefore, we decided to transfer the Customer Order context from the Order Processing system to a separate microservice, which was called Order Management.
Requirements and Tools
After determining the context that we decided to remove from the monolith in the first place, we formed the requirements for our future service:
- Performance
- Data consistency
- Sustainability
- Predictability
- Transparency
- Increment of change
We wanted the code to be as clear and easy to edit as possible, so that the next generation of developers could quickly make the changes required for the business.
As a result, we came to a certain structure that we use in all new microservices:
Bounded Context . Each new microservice, starting with Order Management, we create based on business requirements. There must be specific explanations of which part of the system and why it is required to place it in a separate microservice.
Existing infrastructure and tools. We are not the first team in Lamoda to start implementing Go, we were pioneers before us - the Go team itself, which prepared the infrastructure and tools:
- Gogi (swagger) is a swagger specification generator.
- Gonkey (testing) - for functional tests.
- We use Json-rpc and generate a client / server binding by swagger. We also deploy all this to Kubernetes, collect metrics in Prometheus, use ELK / Jaeger for tracing - all this is included in the bundle that Gogi creates for each new microservice by specification.
This is what our new Order Management microservice looks like:
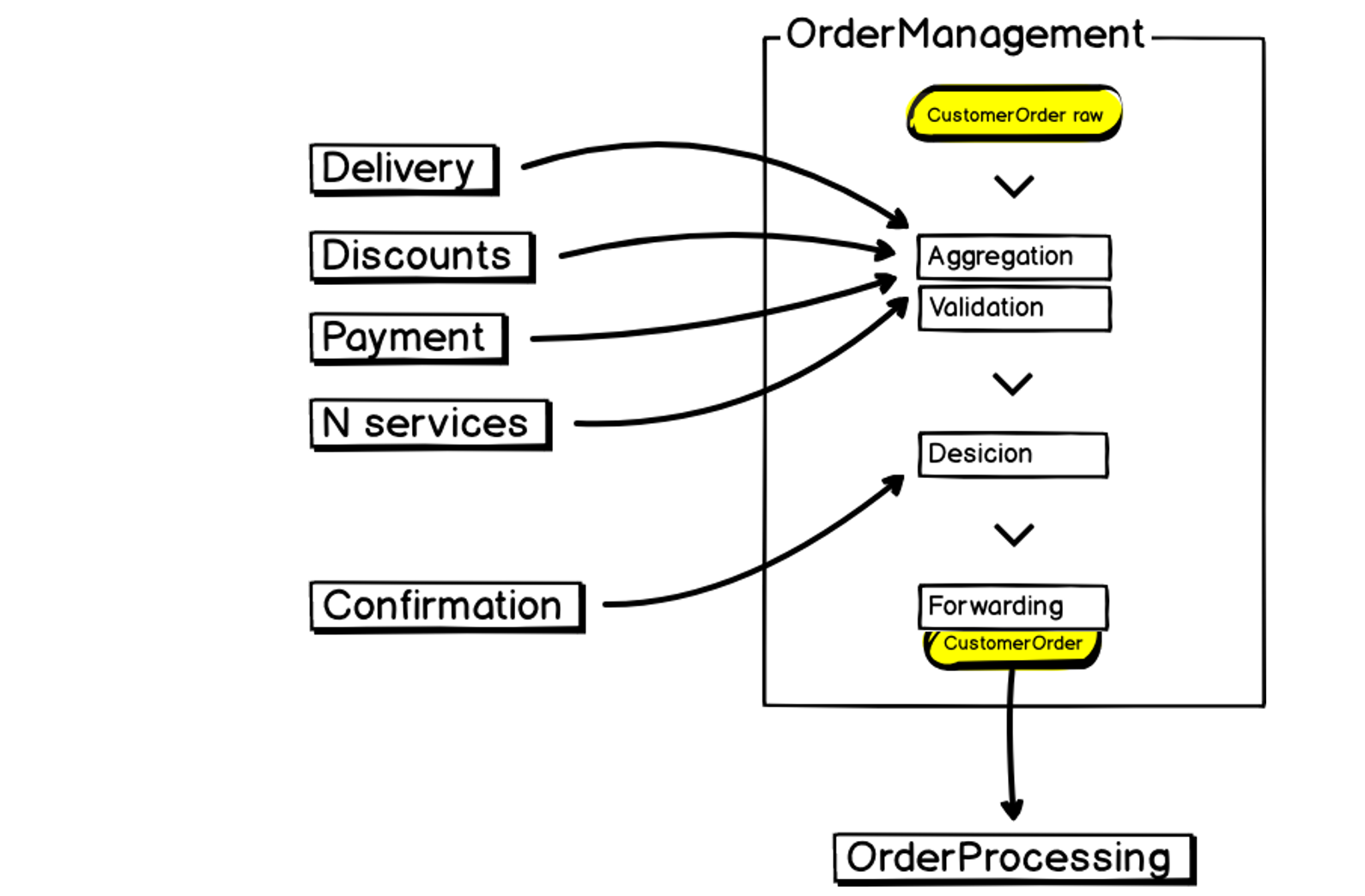
At the input, we have data, we aggregate it, validate it, interact with third-party services, make decisions and transfer the results further to Order Processing - the same monolith that is large, unstable and resource-demanding. This also needs to be considered when building a microservice.
Paradigm shift
Choosing Go, we immediately got several advantages:
- Static strong typing immediately cuts off a certain range of possible bugs.
- The concurrency model fits our tasks well, since we need to walk around and simultaneously poll several services.
- Composition and interfaces also help us in testing.
- The “simplicity" of study - it was here that not only obvious pluses were discovered, but also problems.
Go language limits the imagination of the developer. This became a stumbling block for our team, accustomed to PHP when we moved on to development on Go. We are faced with a real paradigm shift. We had to go through several stages and understand some things:
- Go is hard on building abstractions.
- Go can be said to be Object-based, but not an Object-oriented language, since there is no direct inheritance and some other things.
- Go helps write explicitly, rather than hiding objects behind abstractions.
- Go has pipelining. This inspired us to build data processor chains.
As a result, we came to understand that Go is a procedural programming language.

Data first
I was thinking how to visualize the problem we were facing and came across this picture:
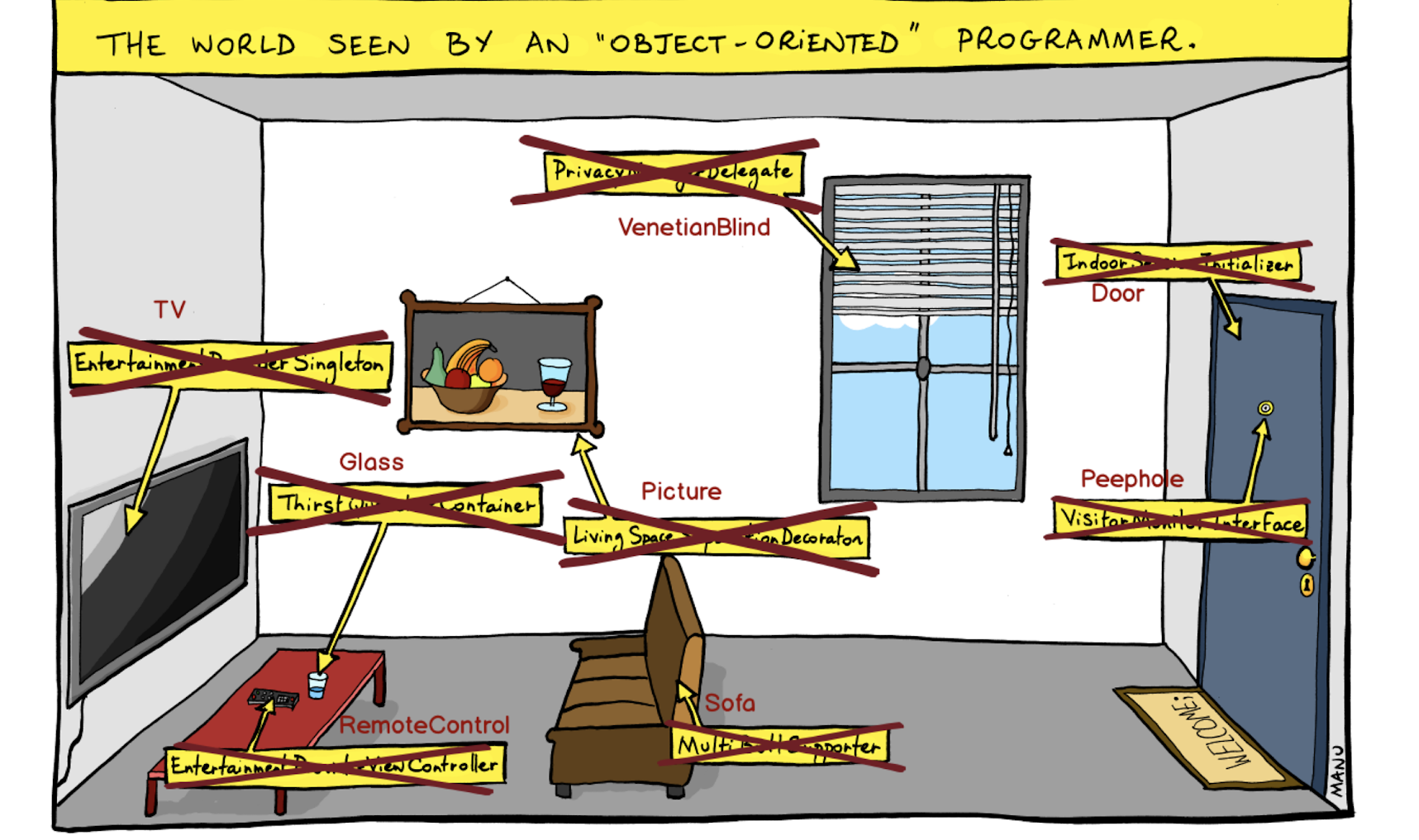
Here is an “object-oriented” view of the world where we build abstractions and close objects behind them. For example, here is not just a door, but an Indoor Session Initialiser. Not the pupil, but the Visitor Monitor Interface - and so on.
We abandoned this approach, and put entities in the first place, without becoming obscured by abstractions.
Reasoning in this way, we put data in the first place, and got such Pipelining in the service:

Initially, we define a model of data that goes into the processor pipeline. Data is mutable, and changes can occur both sequentially and concurrency. With this, we win in speed.
Back to the Future
Suddenly, developing microservices, we came to the programming model of the 70s. After the 70s, large enterprise monoliths arose, where object-oriented programming appeared, and functional programming - large abstractions that made it possible to keep code in these monoliths. In microservices, we don’t need all this, and we can use the excellent model of CSP ( communicating sequential processes ), the idea of which was put forward just in the 70s by Charles Choir.
We also use Sequence / Selection / Interation - a structural programming paradigm according to which all program code can be composed of the corresponding control structures.
Well, procedural programming, which was the mainstream in the 70s :)
Project structure

As I said, in the first place we put the data. In addition, we replaced the construction of the project “from infrastructure” with a business-oriented one. So that the developer, entering the project code, immediately sees what the service is doing - this is the very transparency that we have identified as one of the basic requirements for the structure of our microservices.
As a result, we have a flat architecture: a small API layer plus data models. And all the logic (which is limited in our context by the business requirement of a microservice) is stored in processors (handlers).
We try not to create new separate microservices without a clear request from the business - this is how we control the granularity of the entire system. If there is logic that is closely related to the existing microservice, but essentially refers to a different context, we first conclude it in the so-called services. And only when a constant business need arises, we take it out into a separate microservice, which we then turn to using an rpc call.
In order to control granularity and not to produce microservices thoughtlessly, we conclude a logic that is not directly related to this context, but is closely related to this microservice, in the services layer. And then, if there is a business need, we take it out to a separate microservice - and then use the rpc call to access it.
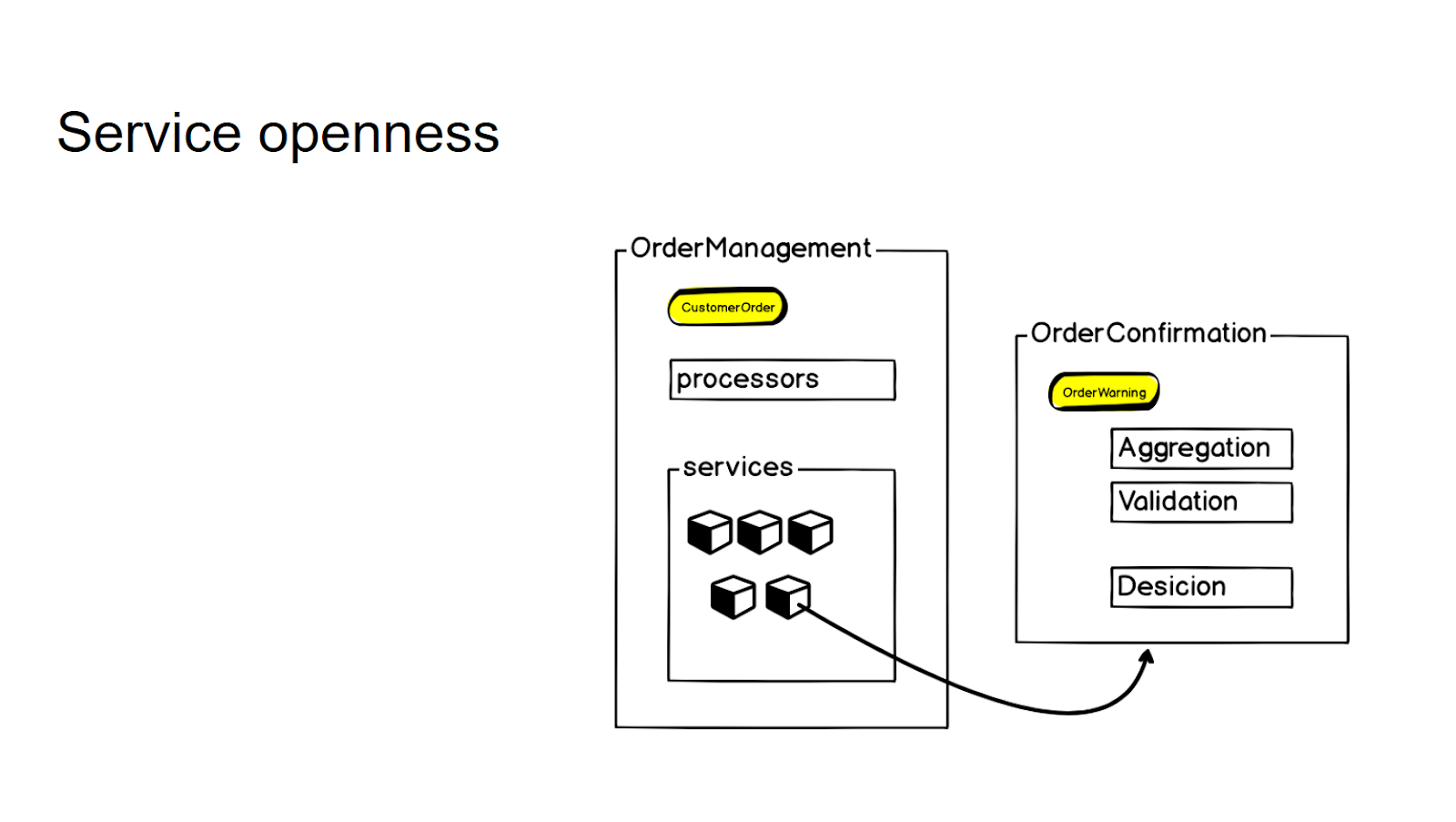
Thus, for the internal API in the processors of the service, the interaction does not change in any way.
Sustainability
We decided not to take any third-party libraries in advance, since the data we work with is quite sensitive. So we cycled a little :) For example, we ourselves implemented some classic mechanisms - for Idempotency, Queue-worker, Fault Tolerance, Compensating transactions. Our next step is to try to reuse it. Wrap in libraries, maybe side-car containers in Kubernetes Pods. But now we can apply these patterns.
We implement in our systems a pattern called graceful degradation: the service must continue to work, regardless of the external calls in which we aggregate information. On the example of creating an order: if the request got into the service, we will create an order in any case. Even if the neighboring service falls, which is responsible for some part of the information that we must aggregate or validate. Moreover - we will not lose the order, even if we cannot in the short-term refusal of order processing, where we must transfer. This is also one of the criteria by which we decide whether to put the logic in a separate service. If the service cannot provide its work when the following services are unavailable on the network, then you either need to redesign it or think about whether it should be taken out of the monolith at all.
Go to Go!
When you come to write business-oriented product microservices from a classic service-oriented architecture, in particular PHP, you are faced with a paradigm shift. And it must be passed, otherwise you can step on the rake endlessly. The business-oriented structure of the project allows us not to complicate the code once again and control the granularity of the service.
One of our main tasks was to increase the stability of the service. Of course, Go does not provide increased stability just out of the box. But, in my opinion, in the Go ecosystem it turned out to be easier to create all the necessary Reliability kit, even with your own hands, without resorting to third-party libraries.
Another important task was to increase the flexibility of the system. And here I can definitely say that the rate of introduction of changes required by the business has increased significantly. Thanks to the architecture of the new microservices, the developer is left alone with business features, he does not need to think about building clients, sending monitoring, sending tracing, and setting up logging. We leave for the developer exactly the layer of writing business logic, allowing him not to think about the whole infrastructure bundle.
Are we going to completely rewrite everything on Go and abandon PHP?
No, since we are moving away from business needs, and there are some contexts in which PHP fits very well - it doesn’t need such speed and the entire Go-go toolkit. All automation of operations for the delivery of orders and photo studio management is done in PHP. But, for example, in the e-commerce platform in the customer side, we almost rewrite everything on Go, since there it is justified.