Introduction
The company I work for writes its own traffic filtering system and protects the business with it from DDoS attacks, bots, parsers, and much more. The product is based on such a process as reverse proxying , with the help of which we analyze large volumes of traffic in real time and, in the end, let through only legitimate user requests, filtering out all malicious ones.
The main feature is that our services work with unlimited incoming traffic, so it is very important to use all the resources of workstations as efficiently as possible. A lot of development experience in modern C ++ helps us with this, including the latest standards and a set of libraries called boost.
Reverse proxy
Let's go back to reverse proxying and see how you can implement it in C ++ and boost.asio. First of all, we need two objects called server and client sessions. The server session establishes and maintains a connection with the browser, the client session establishes and maintains a connection with the service. You will also need a stream buffer that encapsulates the work with memory inside, into which the server session reads from the socket and from which the client session writes to the socket. Examples of server and client sessions can be found in the documentation for boost.asio. How to work with the stream buffer can be found there.
After we collect the reverse proxy prototype from the examples, it becomes clear that such an application will probably not serve unlimited incoming traffic. Then we will begin to increase the complexity of the code. Let's think about multithreading, wokers and pools for io contexts, as well as much more. In particular, about premature optimizations related to copying memory between server and client sessions.
What kind of memory copying are we talking about? The fact is that when filtering, traffic is not always transmitted unchanged. Look at the example below: in it we remove one header and add two instead. The number of user queries over which similar actions are performed increases with the complexity of the logic inside the service. In no case can you mindlessly copy data in such cases! If only 1% of the total request changes, and 99% remain unchanged, then you should allocate new memory only for this 1%. It will help you with this boost :: asio :: const_buffer and boost :: asio :: mutable_buffer, with which you can represent several continuous blocks of memory with one entity.
User request:
Browser -> Proxy: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Content-Length: 5888903 > Content-Type: application/x-www-form-urlencoded > ... Proxy -> Service: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Transfer-Encoding: chunked > Content-Type: application/x-www-form-urlencoded > Expect: 100-continue > ... Service -> Proxy: < HTTP/1.1 200 OK Proxy -> Browser < HTTP/1.1 200 OK
Problem
As a result, we got a ready-made application that can scale well and is endowed with all sorts of optimizations. By launching it in production, we were quite happy for how long it worked well and stably.
Over time, we began to have more and more customers, with the advent of which traffic has also grown. At some point, we were faced with the problem of lack of performance while repulsing large attacks. After analyzing the service using the perf utility, we noticed that all operations with the heap under load are in the top. Then we recreated a similar situation on the test circuit using yandex-tank and cartridges generated based on real traffic. Having picked up the service through the amplifier, we saw the following picture ...
Screenshot of amplifier (woslab):
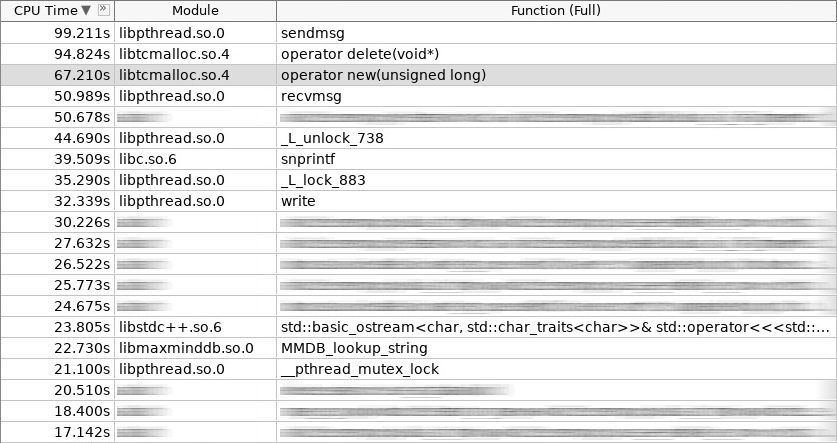
In the screenshot, operator new worked 67 seconds, and operator delete even more - 97 seconds.
This situation upset us. How to reduce application stay time in operator new and operator delete? It is logical that this can be done by abandoning constant allocations of frequently created and deleted objects on the heap. We settled on three approaches. Two of them are standard: object pool and stack allocation . Client sessions that are organized in the pool at the application start-up stage are well placed on the first approach. The second approach is used everywhere where a user request is processed from beginning to end in the same stack, in other words, in the same io context handler. We will not dwell on this in more detail. We’d better talk about the third approach, as the most difficult and interesting. It is called slab allocation or slab distribution.
The idea of slab distribution is not new. It was invented and implemented in Solaris, later migrated to the Linux kernel, and consists in the fact that often used objects of the same type are easier to store in the pool. We simply take the object from the pool when we need it, and upon completion of work we return it back. No calls to operator new and operator delete! Moreover, a minimum of initialization. In the slab core, distribution is used for semaphores, file descriptors, processes, and threads. In our case, it fell perfectly on the server and client sessions, as well as everything that is inside them.
Chart (slab distribution):

In addition to the fact that slab allocators are in the kernel, their implementations also exist in user space. There are few of them, and those that are actively developing are generally few. We settled on a library called libsmall , which is part of tarantool . It has everything you need.
- small :: allocator
- small :: slab_cache (thread local)
- small :: slab
- small :: arena
- small :: quota
The small :: slab structure is a pool with a specific type of object. The structure small :: slab_cache is a cache containing various lists of pools with a specific type of objects. The structure small :: allocator is a code that selects the necessary cache, looks for a suitable pool in it, in which the requested object is distributed. What small :: arena and small :: quota objects do will be clear from the examples below.
Wrap
The libsmall library is written in C, not C ++, so we had to develop several wrappers for transparent integration into the standard C ++ library.
- variti :: slab_allocator
- variti :: slab
- variti :: thread_local_slab
- variti :: slab_allocate_shared
The variti :: slab_allocator class implements the minimum requirements that are set forth by the standard when writing its own allocator. Inside variti :: slab classes, all work with the libsmall library is encapsulated. Why is variti :: thread_local_slab needed? The fact is that distribution slab caches are thread local objects. This means that each thread has its own set of caches. This is done in order to reduce to zero the number of blocked operations when distributing a new object. Therefore, in the memory of each thread, we place our instance of the variti :: slab class, and access to it is controlled using the variti :: thread_local_slab wrapper. About the template function variti :: slab_allocate_shared I will tell later.
Inside the variti :: slab_allocator class, everything is quite simple. He has the ability to rebind from one type to another, for example, from void to char. From interesting things, you can pay attention to the prevalence of nullptr to the exception std :: bad_alloc in the case when memory runs out of the distribution slab. The rest is forwarding calls inside the variti :: thread_local_slab wrapper.
Snippet (slab_allocator.hpp):
template <typename T> class slab_allocator { public: using value_type = T; using pointer = value_type*; using const_pointer = const value_type*; using reference = value_type&; using const_reference = const value_type&; template <typename U> struct rebind { using other = slab_allocator<U>; }; slab_allocator() {} template <typename U> slab_allocator(const slab_allocator<U>& other) {} T* allocate(size_t n, const void* = nullptr) { auto p = static_cast<T*>(thread_local_slab::allocate(sizeof(T) * n)); if (!p && n) throw std::bad_alloc(); return p; } void deallocate(T* p, size_t n) { thread_local_slab::deallocate(p, sizeof(T) * n); } }; template <> class slab_allocator<void> { public: using value_type = void; using pointer = void*; using const_pointer = const void*; template <typename U> struct rebind { typedef slab_allocator<U> other; }; };
Let's see how the variti :: slab constructor and destructor are implemented. In the constructor, we allocate a total of no more than 1 GiB of memory for all objects. The size of each pool in our case does not exceed 1 MiB. The minimum object that we can distribute is 2 bytes in size (in fact, libsmall will increase it to the minimum required - 8 bytes). The remaining objects available through our slab distribution will be a multiple of two (set by constant 2.f). Total, you can distribute objects of size 8, 16, 32, etc. If the requested object is 24 bytes in size, then an overhead will occur from memory. The distribution will return this object to you, but it will be placed in a pool that corresponds to an object of 32 bytes in size. The remaining 8 bytes will be idle.
Snippet (slab.hpp):
inline void* phys_to_virt_p(void* p) { return reinterpret_cast<char*>(p) + sizeof(std::thread::id); } inline size_t phys_to_virt_n(size_t n) { return n - sizeof(std::thread::id); } inline void* virt_to_phys_p(void* p) { return reinterpret_cast<char*>(p) - sizeof(std::thread::id); } inline size_t virt_to_phys_n(size_t n) { return n + sizeof(std::thread::id); } inline std::thread::id& phys_thread_id(void* p) { return *reinterpret_cast<std::thread::id*>(p); } class slab : public noncopyable { public: slab() { small::quota_init(& quota_, 1024 * 1024 * 1024); small::slab_arena_create(&arena_, & quota_, 0, 1024 * 1024, MAP_PRIVATE); small::slab_cache_create(&cache_, &arena_); small::allocator_create(&allocator_, &cache_, 2, 2.f); } ~slab() { small::allocator_destroy(&allocator_); small::slab_cache_destroy(&cache_); small::slab_arena_destroy(&arena_); } void* allocate(size_t n) { auto phys_n = virt_to_phys_n(n); auto phys_p = small::malloc(&allocator_, phys_n); if (!phys_p) return nullptr; phys_thread_id(phys_p) = std::this_thread::get_id(); return phys_to_virt_p(phys_p); } void deallocate(const void* p, size_t n) { auto phys_p = virt_to_phys_p(const_cast<void*>(p)); auto phys_n = virt_to_phys_n(n); assert(phys_thread_id(phys_p) == std::this_thread::get_id()); small::free(&allocator_, phys_p, phys_n); } private: small::quota quota_; small::slab_arena arena_; small::slab_cache cache_; small::allocator allocator_; };
All these restrictions apply to a particular instance of the variti :: slab class. Since each thread has its own (think of thread local), the total limit on the process will not be 1 GiB, but will be directly proportional to the number of threads in which slab distribution is used.
Chart (std :: thread :: id):
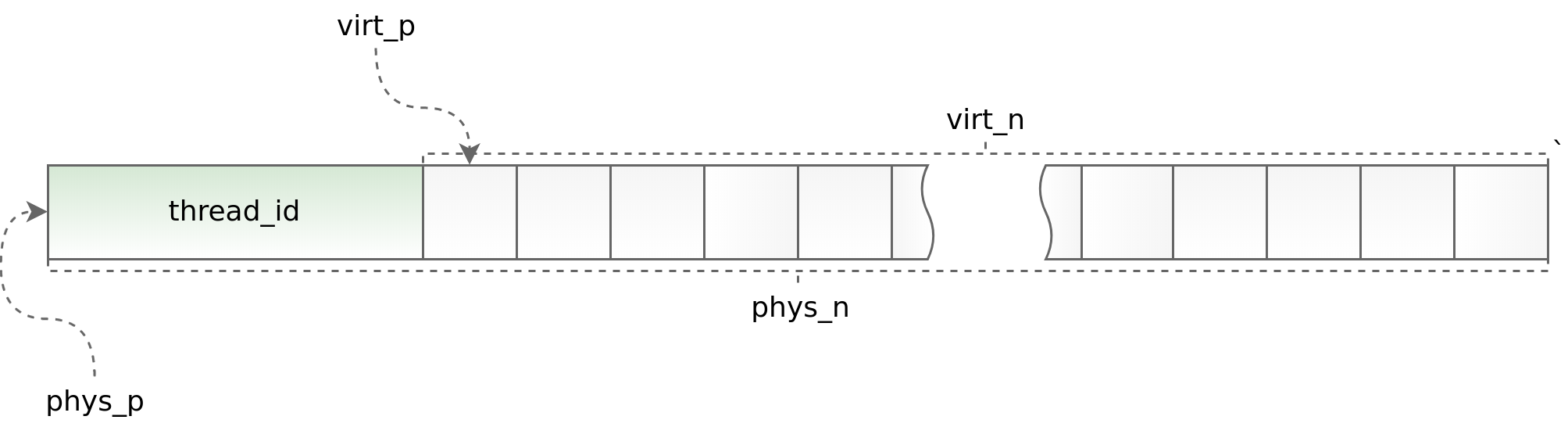
On the one hand, using thread local allows you to speed up the work of slab distribution in a multi-threaded application, on the other hand, it imposes serious restrictions on the architecture of the asynchronous application. You must request and return an object in the same stream. Doing this as part of boost.asio is sometimes very problematic. To track obviously erroneous situations, at the beginning of each object we place the identifier of the stream in which the allocate method is called. This identifier is then verified in the deallocate method. The helpers phys_to_virt_p and virt_to_phys_p help in this.
Snippet (thread_local_slab.hpp):
class thread_local_slab : public noncopyable { public: static void initialize(); static void finalize(); static void* allocate(size_t n); static void deallocate(const void* p, size_t n); };
Snippet (thread_local_slab.cpp):
static thread_local slab* slab_; void thread_local_slab::initialize() { slab_ = new slab(slab_cfg_); } void thread_local_slab::finalize() { delete slab_; } void* thread_local_slab::malloc(size_t n) { return slab_->malloc(n); } void thread_local_slab::free(const void* p, size_t n) { slab_->free(p, n); }
When control over the stream is lost (when transferring an object between different io contexts), a smart pointer allows the correct release of the object. All that he does is distribute the object, remembering its io context, and then wrap it in std :: shared_ptr with a custom divider, which does not immediately return the object to the distribution, but does it in the io context saved earlier. This works well when each io context runs on a single thread. Otherwise, unfortunately, this approach is not applicable.
Snippet (slab_helper.hpp):
template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator](T* p) { p->~T(); allocator.deallocate(p); }); return ptr; }; template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, boost::asio::io_service* io, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator, io](T* p) { io->post([allocator, p]() { p->~T(); allocator.deallocate(p); }); }); return ptr; };
Decision
After the libsmall wrapping work was completed, we first moved chun allocators inside the stream buffer to slab. This was pretty easy to do. Having received a positive result, we went ahead and applied slab allocators first to the stream buffer itself, and then to all objects inside the server and client sessions.
- variti :: chunk
- variti :: streambuf
- variti :: server_session
- variti :: client_session
At the same time, it was necessary to solve additional problems, namely: transfer simple objects, composite objects, and collections to slab allocators. And if there were no serious difficulties with the first two classes of objects (composite objects are reduced to simple ones), then when translating collections we ran into serious difficulties.
- std :: list
- std :: deque
- std :: vector
- std :: string
- std :: map
- std :: unordered_map
One of the main limitations when working with slab distribution is that the number of objects of different types should not be too large (the smaller it is, the better). In this context, some collections may well fall on the concept of slab allocators, while some may not.
For std :: list slab, allocators work great. This collection is implemented internally using a linked list, each element of which has a fixed size. Thus, with the addition of new data to the std :: list in the slab distribution, new types of objects do not appear. The condition indicated above is satisfied! The std :: map is similarly arranged. The only difference is that inside it is not a linked list, but a tree.
In the case of std :: deque, things are more complicated. This collection is implemented through a contiguous block of memory that contains pointers to chunks. While the chunks are pretty accurate, std :: deque behaves the same as std :: list, but when they end, this same block of memory is redistributed. From the point of view of slab allocators, each memory redistribution is an object with a new type. The number of objects added to the collection depends on the user and can grow uncontrollably. This situation is not acceptable, so we either preliminarily limited the size of std :: deque where it was possible, or preferred std :: list.
If we take std :: vector and std :: string, then they are still more complicated. The implementation of these collections is somewhat similar to std :: deque, except that their continuous memory block grows significantly faster. We replaced std :: vector and std :: string with std :: deque, and in the worst case with std :: list. Yes, we lost functionality and somewhere even performance, but this affected the final picture much less than the optimizations for which everything was conceived.
We did exactly the same thing with std :: unordered_map, abandoning it in favor of the self-written variti :: flat_map implemented through std :: deque. At the same time, we simply cached the frequently used keys in separate variables, for example, as is done with the http request headers in nginx.
Output
Having finished the full transfer of server and client sessions to slab allocators, we reduced the time spent working with a bunch by more than one and a half times.
Screenshot of amplifier (coldslab):
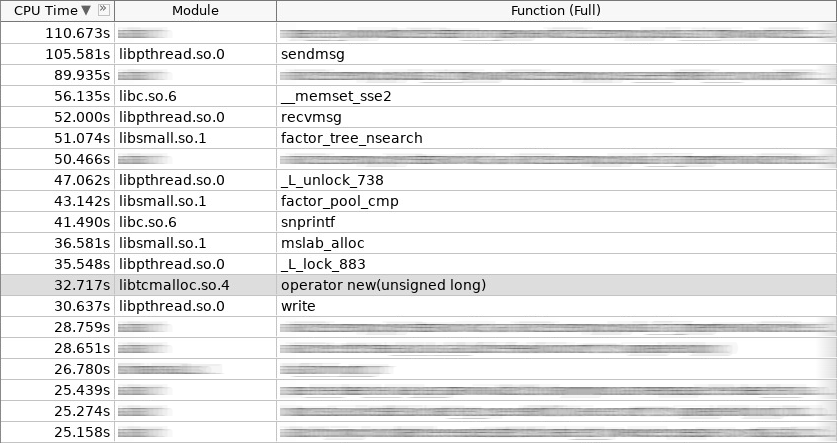
In the screenshot, operator new worked 32 seconds, and operator delete - 24 seconds. By this time, other functions for working with the heap were added: smalloc - 21 seconds, mslab_alloc - 37 seconds, smfree - 8 seconds, mslab_free - 21 seconds. Total, 143 seconds versus 161 seconds.
But these measurements were made immediately after starting the service without initializing the caches in the slab distribution. After repeated firing from a yandex-tank, the overall picture improved.
Screenshot of amplifier (hotslab):
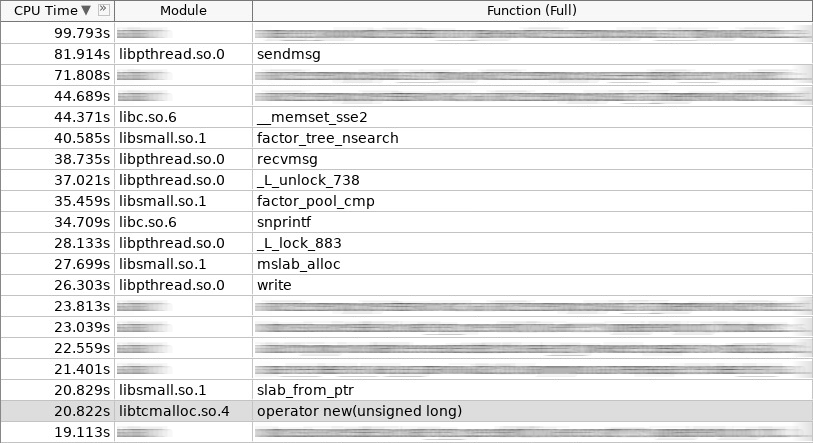
In the screenshot, operator new worked 20 seconds, smalloc - 16 seconds, mslab_alloc - 27 seconds, operator delete - 16 seconds, smfree - 7 seconds, mslab_free - 17 seconds. Total 103 seconds against 161 seconds.
Measurement Table:
woslab coldslab hotslab operator new 67s 32s 20s smalloc - 21s 16s mslab_alloc - 37s 27s operator delete 94s 24s 16s smfree - 8s 7s mslab_free - 21s 17s summary 161s 143s 103s
In real life, the result should be even better, since slab allocators not only solve the problem of long memory allocation and freeing, but also reduce fragmentation. Without slab, over time, the operation of operator new and operator delete should only slow down. With slab - it will always remain at the same level.
As we can see, slab allocators successfully solve the problem of allocating memory for frequently used objects. Pay attention to them if the issue of frequent creation and removal of objects is relevant for you. But do not forget about the limitations that they impose on the architecture of your application! Not all complex objects can simply be placed in the slab distribution. Sometimes you have to give up a lot! Well, the more complex the architecture of your application, the more often you will have to take care of returning the object to the correct cache in terms of multithreading. It can be simple when you immediately worked out the application architecture, taking into account the use of slab allocators, but it will definitely cause difficulties when you decide to integrate them at a late stage.
application
Check out the source code here !