
At the RAIF 2019 forum, which was held in Skolkovo as part of the “Open Innovations”, I talked about how the implementation of machine learning models is being implemented. In connection with the characteristics of the profession, I spend several days every week in production, introducing machine learning models, and the rest of the time developing these models. This post is a recording of a report in which I tried to summarize my experience.
Let's start with a description of the process in large strokes, gradually going into the details of each stage.
Whether we are counting on optimizing production based on the results of a full-fledged survey (ideally), or just collecting ideas, “patchwork optimization”, the result is somehow the formation of a list of initiatives . It is necessary to understand which areas of production we will optimize. This process usually takes about two months.
Then we proceed to the piloting phase, it will take three to four months - we must build a basic model and understand whether machine learning is applicable to it, and what benefits it can bring to business.
The next stage, which is much longer in time, there is not a lot of machine learning on it - implementation is when you need to integrate, build current systems and start getting the very profit that we predicted in the second stage. Implementation usually takes from six months to nine months.
The control stage completes the process. It is one thing to make a model and show, and another to maintain the model for some time. Production is changing, machine tools are being replaced. In these conditions, the model also has to constantly “spin up” and look for new opportunities for optimization.
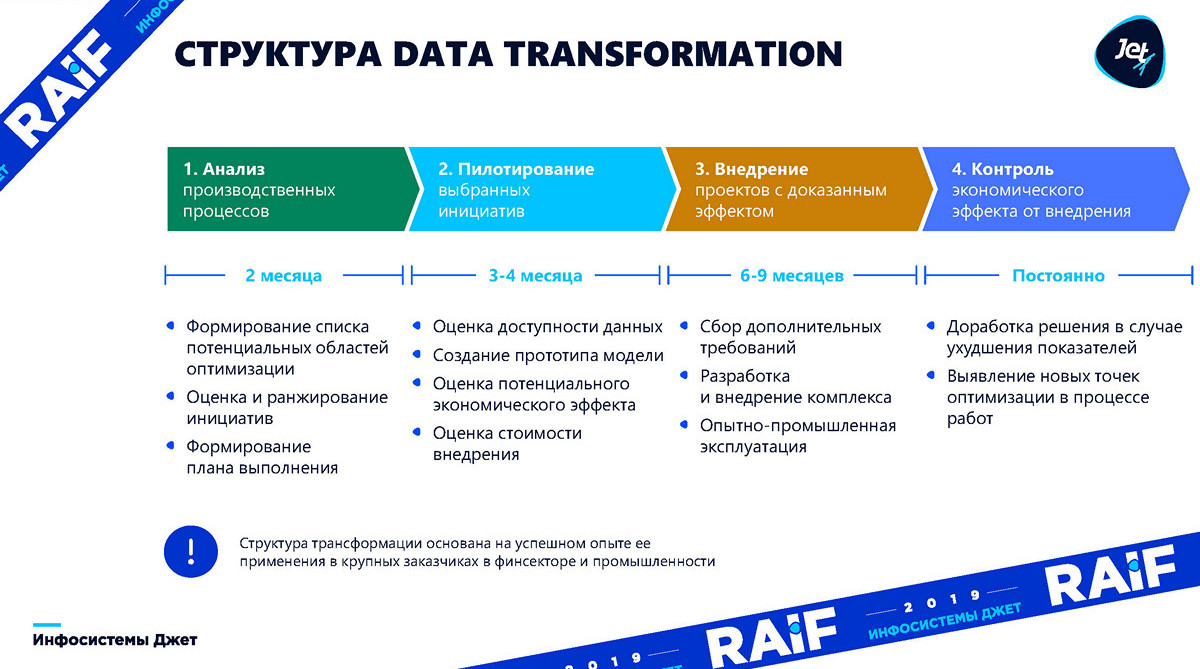
Now in more detail in order:
Looking for a hypothesis
Where does the hypothesis come from? Who will nominate her?
Usually it’s customary to go to the IT department for hypotheses, but people who can configure systems work there, know about integration and do not know anything about machine learning. In addition, they are not so well aware of production. They have no competence to understand in practice how machine learning works.
Attempt number two is to go to the production hypothesis. Indeed, specialists close to production know the technical features of the process, but ... do not know machine learning. Therefore, they cannot say where it is applicable and where not.
In this case, where can the hypothesis come from? To do this, they came up with a special position - Chief Digital Transformation Officer. This is a person who is engaged in digital transformation. Or Chief Date Officer - a person who knows the data and how it can be applied. If these two people are not in the company, then hypotheses should come from top management. That is, specialists who fully understand the business and are engaged in modern technologies.
If at the enterprise there is neither Chief Digital Transformation Officer, nor Chief Date Officer, and top management is not able to give birth to a hypothesis, then ... competitors will come to the rescue. If they have implemented something, they can’t take it away. But, an integrator company connected to the project can tell what and how to optimize.

How to choose an idea?
Four factors are important here:
- The turnover of the process to be optimized.
- Significant deviations in the process. There is a six-sigma methodology, which says that all processes should deviate by no more than six standard deviations from their results. If you have more of these deviations, then you need to parse them, and machine learning will help.
- Availability and availability of data. If, for example, you receive data from sensors on the operation of equipment after 12 months, then you will not implement machine learning.
- The complexity of implementing digitalization in the process. The cost of introducing your model, compared to the cost of what it can save.
What are the data?
The structure of the data are:
Structured: any tables, indications - everything is simple. When we want to use data from social networks, or sets of photos, we have to deal with unstructured data. It is necessary to lay that such data must also be structured, turning into numbers that machine learning can perceive. The third type of data is threaded. If we work with data that changes every millisecond, then we need to immediately think about load balancing: can our system withstand the speed of its receipt?

By origin, the data are divided into:
Automated - sensors generate some kind of numbers, we trust them or not. But they are about the same. Entered manually - here you need to understand that there may be a mistake related to the human factor. And the model must be resistant to this. External data - perhaps we will be interested in exchange rates if the implementation is related to financial transactions, or the weather forecast if we predict temperature heat exchanges. Static data is all that can be reused.

Data problems
- Completeness - the moment when some data / months can be skipped.
- The error of change - if, for example, your sensor has an error of 5 milliseconds, then the model with an accuracy of two milliseconds - you will not be able, since the input data begins to diverge.
- Accessibility online - if you want to make a forecast “right now”, the data must be ready.
- Storage time - if you want to use annual trends, and you need to forecast demand, and data is stored only for six months - you will not build a model.
Work with data
Listen to professionals, but only believe the data. You need to go to the workshop, talk to professionals, go to the factory, talk to operators, understand their business. But believe only the data. There were a lot of examples when operators say that this cannot be - we show the data - it turns out that this is really happening. An interesting example: once the model showed that the day of the week affects production. On Mondays - one coefficient, on Fridays - another.
The effect is understandable only in battle - rapid prototyping is very important. The most important thing is to quickly see how the model works in everyday life. In presentations and on local laptops, the project may look completely different from what it actually is: as a rule, in fact completely different problems come first.
Only an interpreted model has a chance of improvement. You always need to clearly understand why the model decided this way and not otherwise.
Work with metrics
In reality, the dependence of accuracy on profit can be any. Until we understand how this accuracy affects the effect, the question of accuracy is completely meaningless. You always need to translate into profit. The graphs below show that profits can vary depending on the accuracy of the model. The first chart illustrates how difficult it is to determine in advance exactly at what point the model’s accuracy is enough for profit growth:
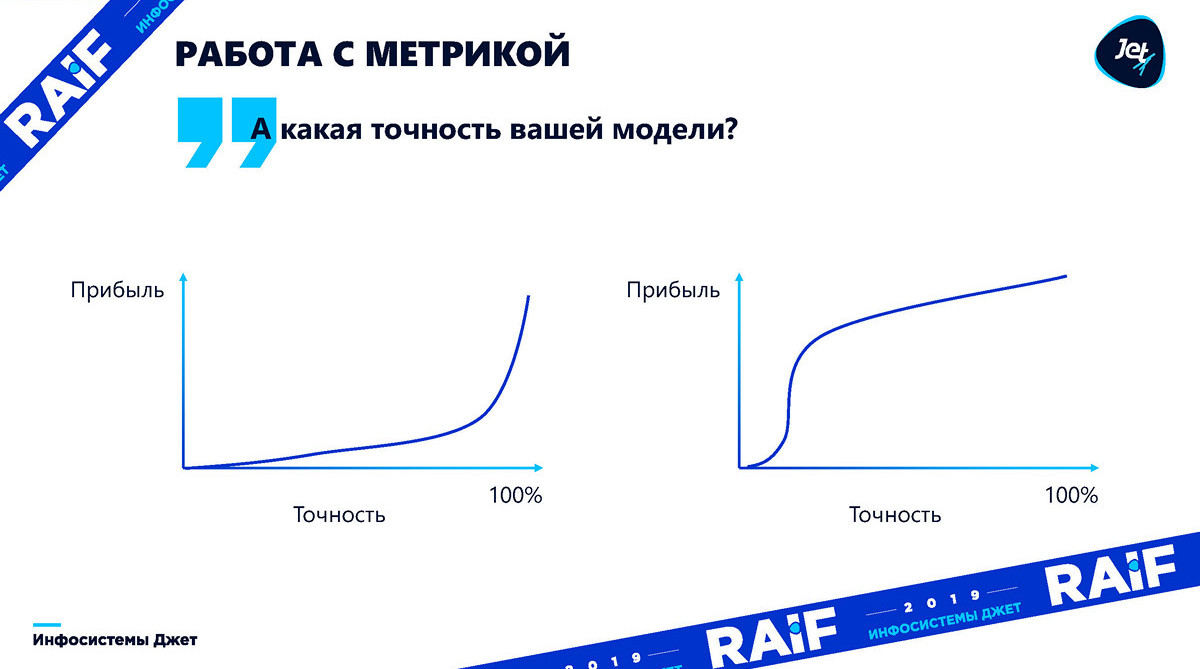
Moreover, for some cases, with insufficient accuracy of the model, it will simply bring loss:

Key points about integration:
- Integration takes more time than model development.
- New ideas. Sometimes it turns out that the project benefits where it was not expected.
- Training. People adapt faster than iron.
Another point that datasainists often forget about is the goal of introducing the model: forecast or recommendation. Usually the recommendations are based on the predictive model, but in this case the predictive model should be built especially, because it is quite difficult to find the minimum black box with sudden unpleasant effects. If we talk about performance metrics, then depending on the purpose of implementation:
- Issue a forecast - evaluate the result of applying knowledge;
- Give recommendations - evaluate the comparison with the old process.
Important nuances of the implementation phase:
Implementation / Training
- Statistical literacy - implementation is much more successful when local employees begin to operate with correct statistical terms.
- The motivation of various structural units - everyone should understand why this is happening, and not be afraid of change.
- Organizational changes - at least one employee will look at the results of the model, which means they will change their approach to the process. It often turns out that people are not ready for this.
Support
Do not forget that the conditions are changing and the model has to constantly “twist” and look for new opportunities for optimization. Here are important:
- Strategies for managing models and responding to forecasts are a bit of self-promotion: we at Jet Infosystems just thought a lot about this and developed our own JET GALATEA system.
- The human factor - the main problems of the model are often associated with its use, or human intervention, which the model could not foresee.
- Regular analysis of work with professionals from the field - it is unlikely that everything will be reduced to one number, which will indicate what needs to be improved, it will be necessary to analyze each dubious forecast or recommendation. Be prepared to learn another profession to speak the same language with technologists and device operators in the workplace.

Posted by Nikolai Knyazev, Head of the Machine Learning Group, Jet Infosystems