And now it's time to draw a physical network diagram.
If you are not on a short foot with the device of data center networks, then I highly recommend starting with an article about them .
All issues:
- 0. ADSM. Part Zero. Planning
- 1. ADSM. Part one (which is after zero). Network virtualization
- 2. ADSM. Part two. Network design
The practices described in this series should be applicable to a network of any type, any scale, with any variety of vendors (no). However, a universal example of the application of these approaches cannot be described. Therefore, I will focus on the modern architecture of the DC network: Klose Factory .
DCI will do on MPLS L3VPN.
An Overlay network from the host runs on top of the physical network (it can be OpenStack VXLAN or Tungsten Fabric, or anything else that requires only basic IP connectivity from the network).
In this case, we get a relatively simple scenario for automation, because we have a lot of equipment that is configured in the same way.
We will choose a spherical DC in a vacuum:
- One version of the design is everywhere.
- Two vendors forming two planes of the network.
- One DC is like another like two drops of water.
Content
- Physical topology
- Routing
- IP plan
- Laba
- Conclusion
- useful links
Let our LAN_DC Service Provider, for example, host training videos about survival in stuck elevators.
In megacities this is wildly popular, so there are a lot of physical machines.
First, I will describe the network approximately as I would like to see it. And then I’ll simplify it for the lab.
Physical topology
Locations
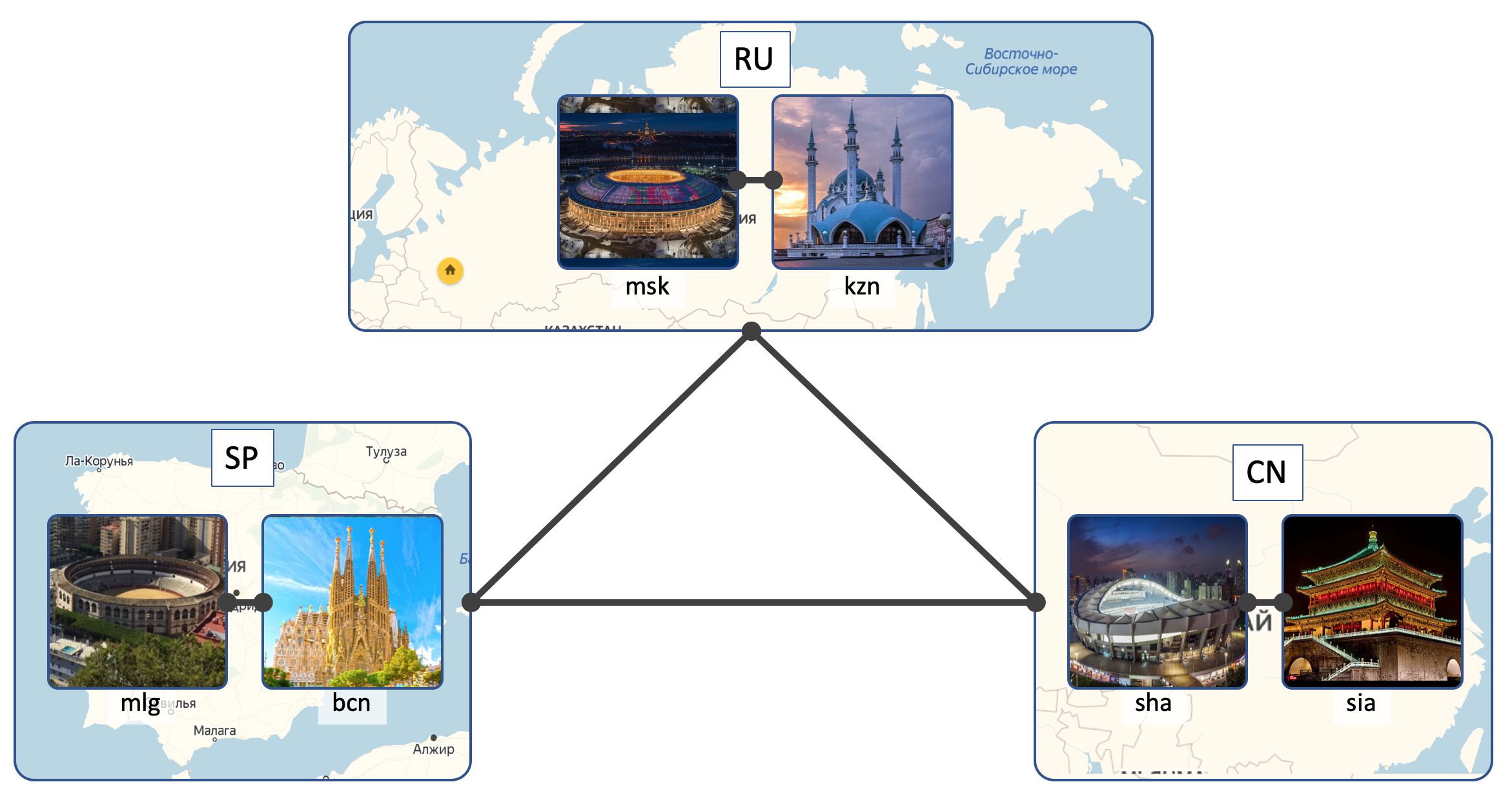
LAN_DC will have 6 DCs:
- Russia ( RU ):
- Moscow ( msk )
- Kazan ( kzn )
- Spain ( SP ):
- Barcelona ( bcn )
- Malaga ( mlg )
- China ( CN ):
- Shanghai ( sha )
- Xi'an ( sia )
Inside DC (Intra-DC)
In all DCs, identical networks of internal connectivity based on the topology of Klose.
What kind of networks are Klose and why are they in a separate article .
In each DC there are 10 racks with cars, they will be numbered as A , B , C And so on.
Each rack has 30 cars. They will not interest us.
Also, in each rack there is a switch to which all the machines are connected - this is Top of the Rack switch - ToR or else in terms of the Klose factory we will call it Leaf .

General scheme of the factory.
We will name them XXX -leaf Y , where XXX is the three-letter abbreviation DC, and Y is the serial number. For example, kzn-leaf11 .
In the articles I will allow myself to use the terms Leaf and ToR quite frivolously, as synonyms. However, one must remember that this is not so.Each ToR switch is in turn connected to four upstream aggregation switches - Spine . Under Spine'y allocated one rack in the DC. We will name it in the same way: XXX -spine Y.
ToR is a rack-mounted switch that machines connect to.
Leaf is the role of a device in a physical network or a first-level switch in terms of Clos's topology.
That is, Leaf! = ToR.
So Leaf can be an EndofRaw switch, for example.
However, within the framework of this article, we will nevertheless refer to them as synonyms.
In the same rack there will be network equipment for connectivity between DCs - 2 routers with MPLS on board. But by and large - these are the same ToRs. That is, from the point of view of Spine-switches, it does not matter whether there is a usual ToR with connected machines or a router for DCI - one hell of a step forward.
Such special ToRs are called Edge-leaf . We will call them XXX- edge Y.
It will look like this.

In the diagram above edge and leaf I really placed on the same level. Classical three-level networks have taught us to consider the uplink (the term is actually from here) as links up. And here it turns out the “uplink” of DCI goes back down, which somewhat breaks the usual logic. In the case of large networks, when data centers are further divided into smaller units - POD 's (Point Of Delivery), separate Edge-POD 's are allocated for DCI and access to external networks.
For convenience, in the future I will still draw Edge on Spine, while we keep in mind that there is no intelligence on Spine and differences when working with regular Leaf and Edge-leaf (although there may be nuances, but in general This is true).
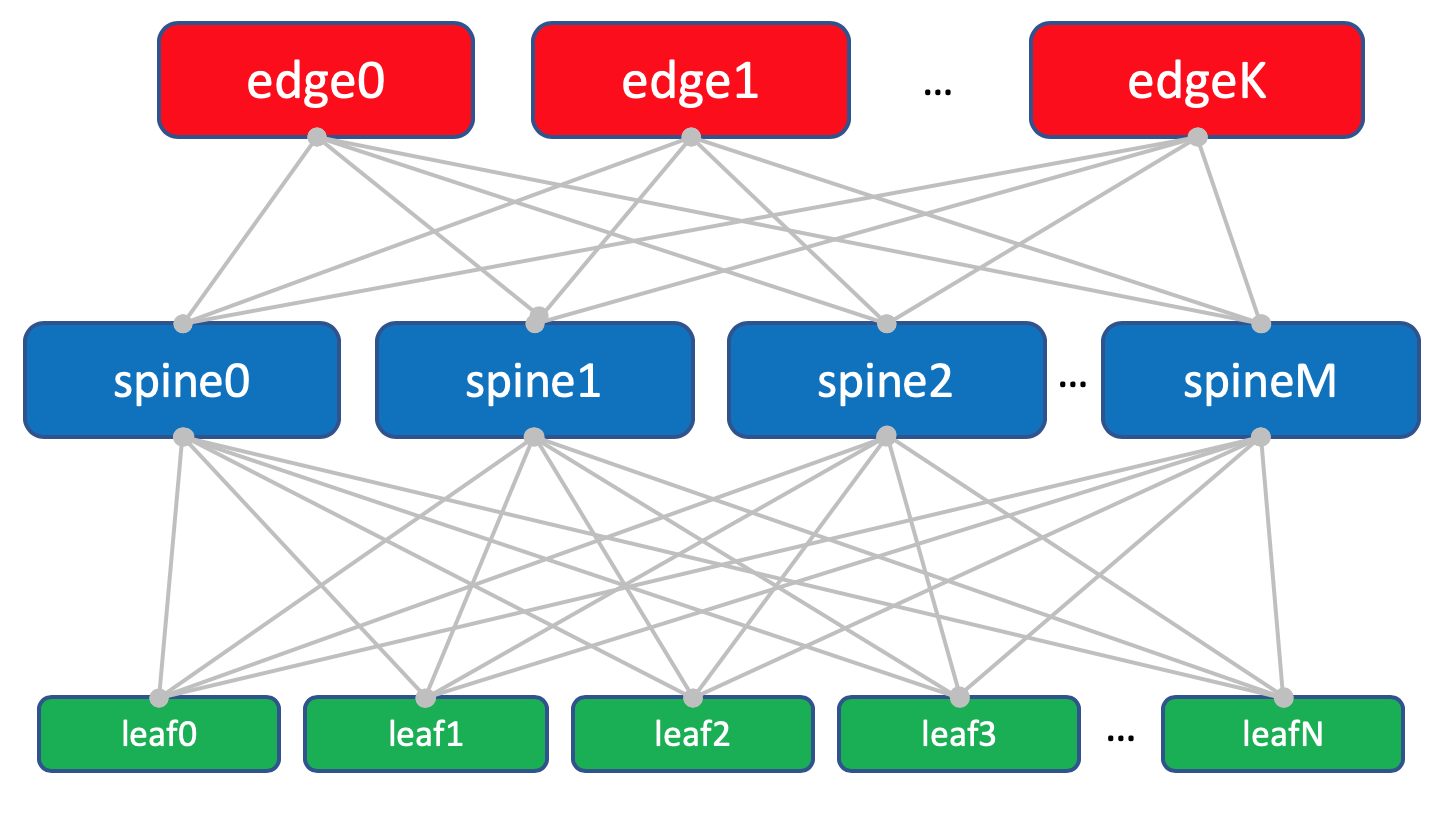
Factory layout with Edge leafs.
Trinity Leaf, Spine, and Edge form an Underlay network or factory.
The task of the network factory (read Underlay), as we already decided in the previous release , is very, very simple - to provide IP connectivity between machines both within the same DC and between.
That is why the network is called a factory, just like, for example, a switching factory inside modular network boxes, which can be found in more detail in SDSM14 .
In general, such a topology is called a factory, because fabric in translation is a fabric. And it's hard not to agree:

Factory completely L3. No VLANs, no Broadcast - these are great programmers in LAN_DC, they can write applications that live in the L3 paradigm, and virtual machines do not require Live Migration with saving the IP address.
And again: the answer to the question why the factory and why L3 - in a separate article .
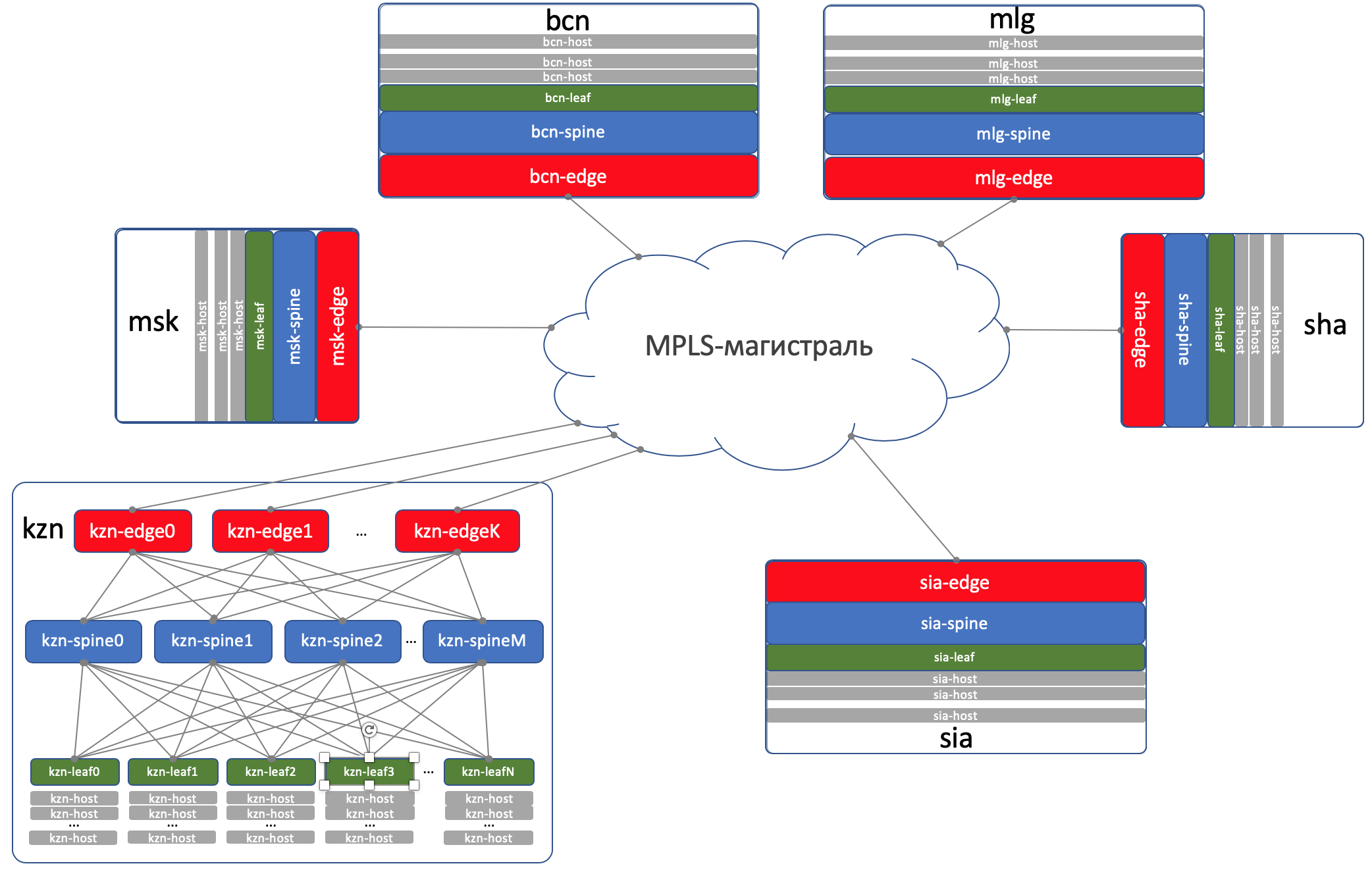
DCI - Data Center Interconnect (Inter-DC)
DCI will be organized using Edge-Leaf, that is, they are our exit point to the highway.
For simplicity, we assume that DCs are connected by direct links.
We exclude external connectivity from consideration.
I am aware that every time I remove a component, I greatly simplify the network. And with the automation of our abstract network, everything will be fine, but crutches will appear on the real one.
This is true. Nevertheless, the goal of this series is to think and work on approaches, and not heroically solve imaginary problems.
On Edge-Leafs, the underlay is placed in the VPN and transmitted via the MPLS backbone (the same direct link).
Here is such a high-level scheme.
Routing
For routing inside the DC we will use BGP.
On the OSPF + LDP MPLS Trunk
For DCI, that is, the organization of connectivity on the underside is BGP L3VPN over MPLS.

General routing scheme
There are no OSPF and ISIS in the factory (routing protocol prohibited in the Russian Federation).
And this means that there will be no Auto-discovery and shortest path calculations - only manual (in fact automatic - we are here about automation) setting up the protocol, neighborhood and policies.
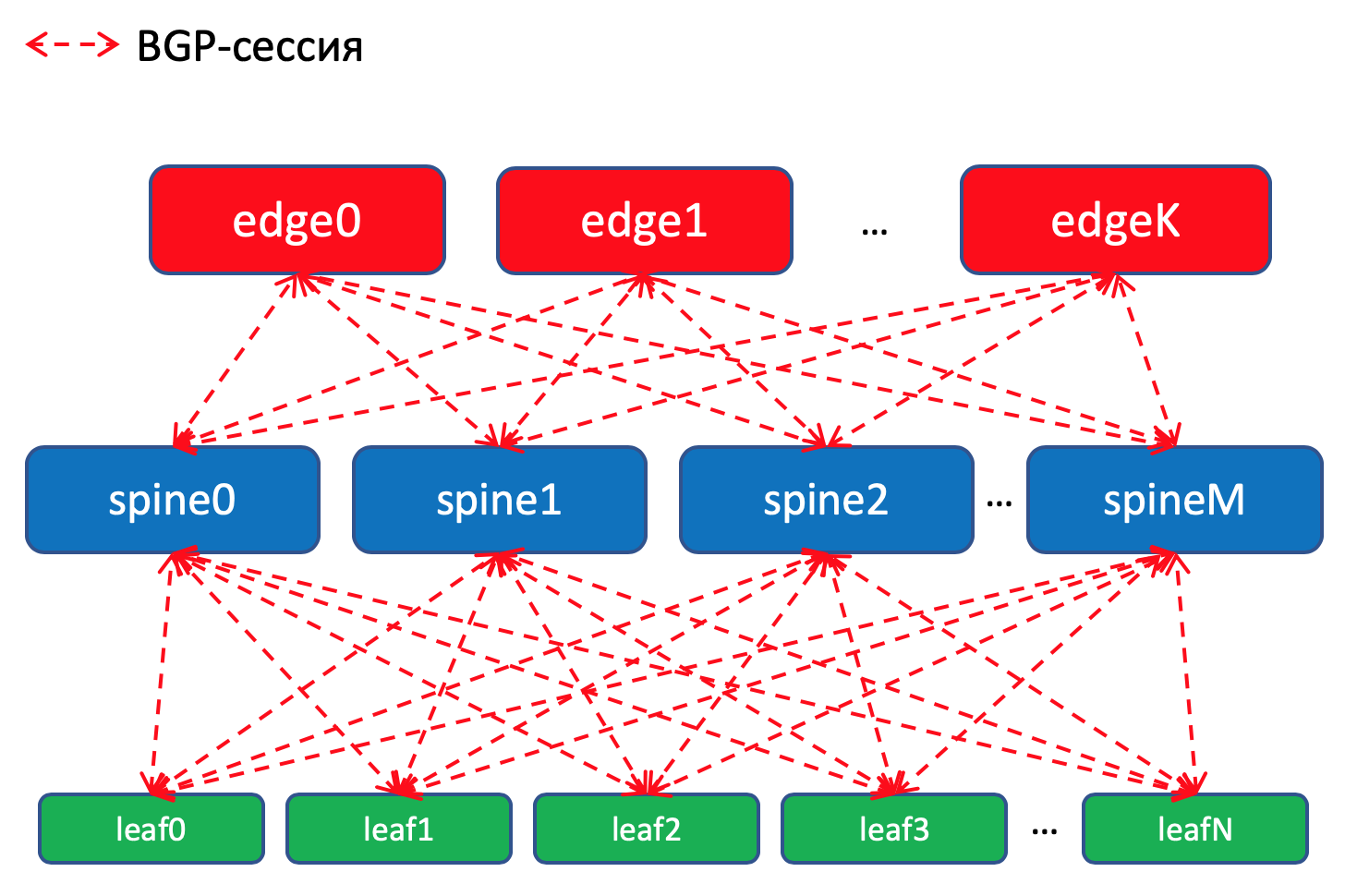
BGP routing scheme inside the DC
Why bgp?
There is a whole RFC named Facebook and Arista on this subject, which tells how to build very large networks of data centers using BGP. It reads almost like an art, highly recommend for a languid evening.
And a whole section in my article is devoted to this. Where am I sending you .
But still, in short, no IGP is suitable for networks of large data centers, where thousands of network devices count.
In addition, the use of BGP everywhere allows you not to spray on the support of several different protocols and synchronization between them.
Hand on heart, in our factory, which with a high degree of probability will not grow rapidly, OSPF would be enough for the eyes. These are actually the problems of megascalers and cloud titans. But let’s just imagine a few issues that we need, and we will use BGP, as Peter Lapukhov bequeathed.
Routing policies
On Leaf switches, we import into BGP prefixes from Underlay interfaces with networks.
We will have a BGP session between each Leaf-Spine pair, in which these Underlay prefixes will be announced on a puddle network.

Inside one data center, we will distribute the specifics that were imported to ToRe. On Edge-Leafs we will aggregate and announce them in remote DCs and lower them to ToRs. That is, each ToR will know exactly how to get to another ToR in the same DC and where is the entry point to get to the ToR in another DC.
In DCI, routes will be transmitted as VPNv4. To do this, on the Edge-Leaf, the interface to the factory will be placed in VRF, let's call it UNDERLAY, and the neighborhood with Spine on the Edge-Leaf will rise inside the VRF, and between the Edge-Leafs in the VPNv4-family.
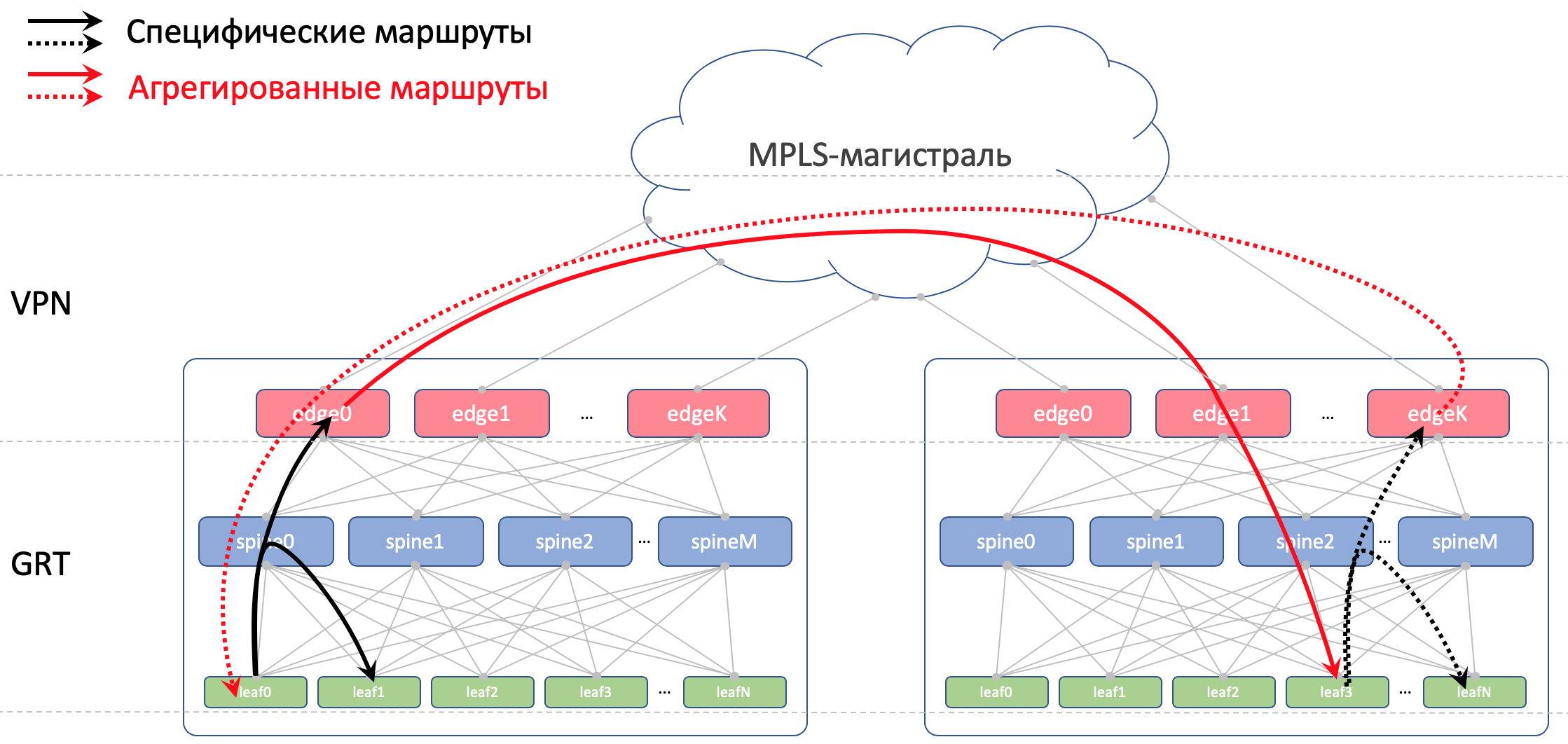
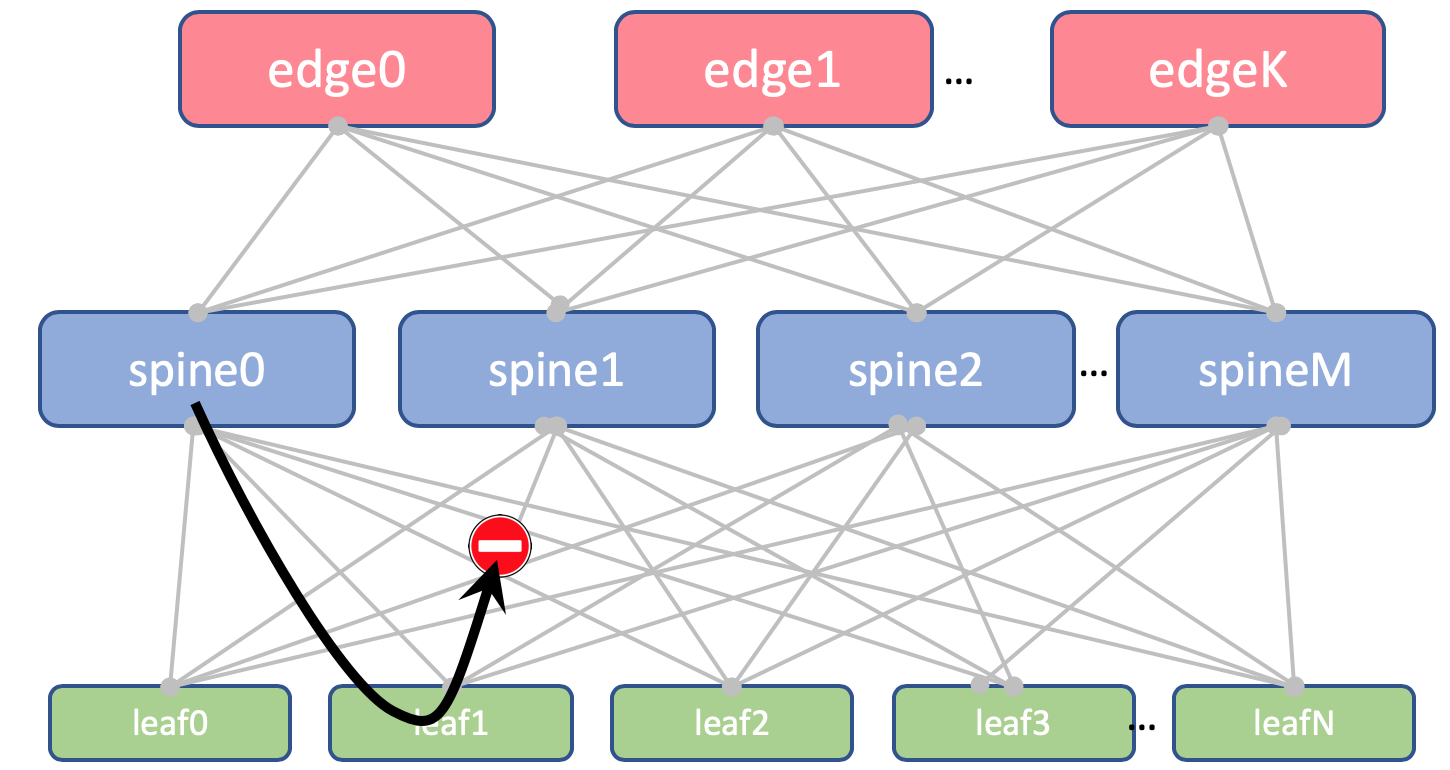
And we will also prohibit re-announcing routes received from spines, back to them.
On Leaf and Spine, we will not import Loopbacks. We need them only to determine the Router ID.
But on Edge-Leafs we import it into Global BGP. Between Loopback addresses, Edge Leafs will establish a BGP session in the IPv4 VPN family with each other.
Between the EDGE-devices we will stretch the trunk to OSPF + LDP. All in one zone. Extremely simple configuration.
Here is a picture of routing.
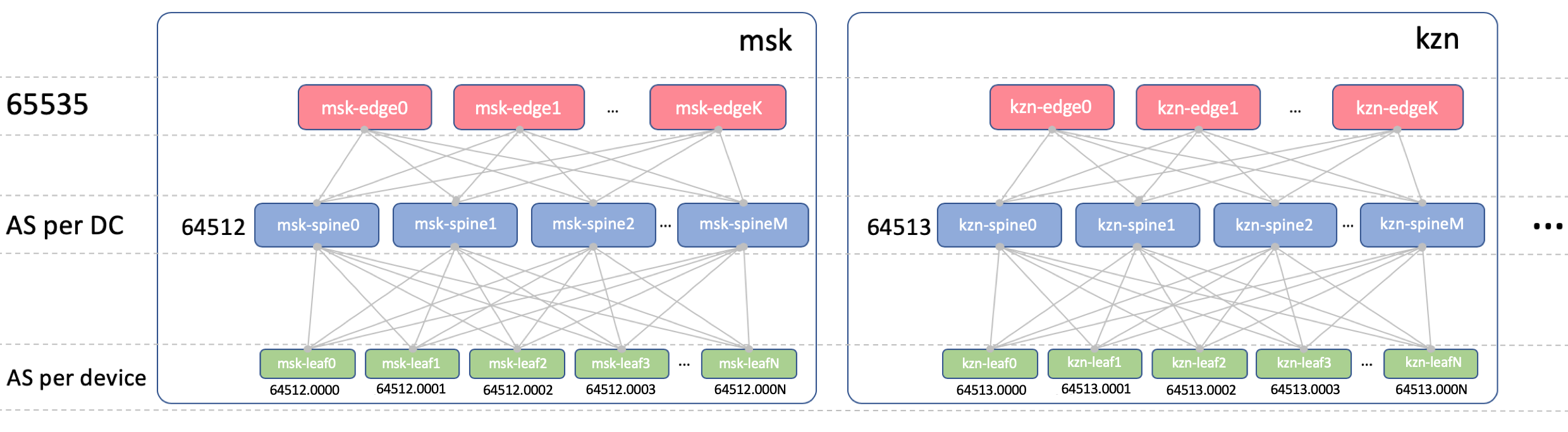
BGP ASN
Edge-Leaf ASN
On Edge-Leafs there will be one ASN in all DCs. It is important that there is iBGP between the Edge-Leafs, and that we don’t run into the nuances of eBGP. Let it be 65535. In reality, it could be a public AS number.
Spine ASN
At Spine, we will have one ASN per DC. Let's start here from the very first number from the private AS range - 64512, 64513 And so on.
Why is ASN on DC?
We decompose this question into two:
- Why are the same ASNs on all spines of the same DC?
- Why are they different in different DCs?
Why are the same ASNs on all spines of one DC
Here's what the AS-Path Anderlay route on the Edge-Leaf will look like:
[leafX_ASN, spine_ASN , edge_ASN]
If you try to announce it back to Spine, it will drop it because its AS (Spine_AS) is already on the list.
However, within the DC we are completely satisfied that the Underlay routes that climbed to Edge will not be able to go down. All communication between hosts within the DC should occur within the spine level.
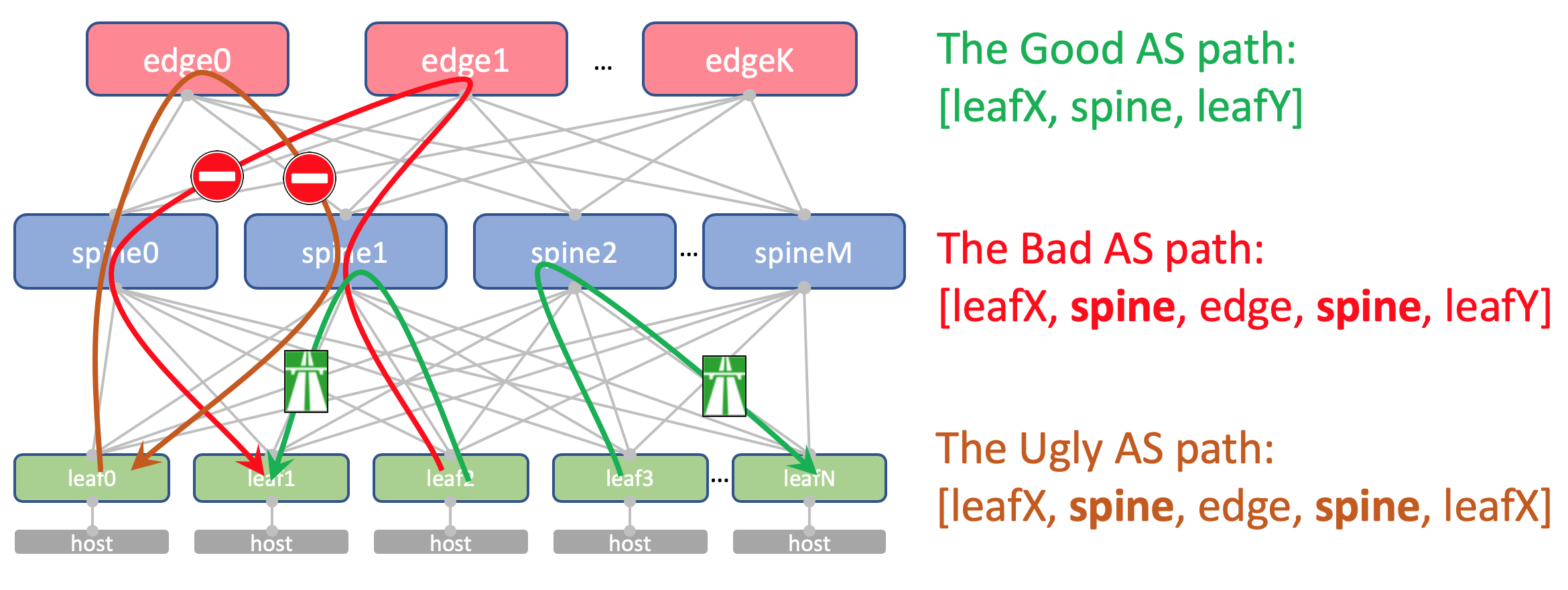
At the same time, the aggregated routes of other DCs in any case will freely reach ToRs - in their AS-Path there will be only ASN 65535 - the number of AS Edge-Leafs, because it was on them that they were created.
Why are different in different DC
Theoretically, we might need to drag Loopback and some service virtual machines between the DCs.
For example, on the host, we will run a Route Reflector or the same VNGW (Virtual Network Gateway), which will be locked with ToR via BGP and will announce its loopback, which should be available from all DCs.
So this is how his AS-Path will look:
[VNF_ASN, leafX_DC1_ASN, spine_DC1_ASN , edge_ASN, spine_DC2_ASN , leafY_DC2_ASN]
And here, there should be no duplicate ASNs anywhere.
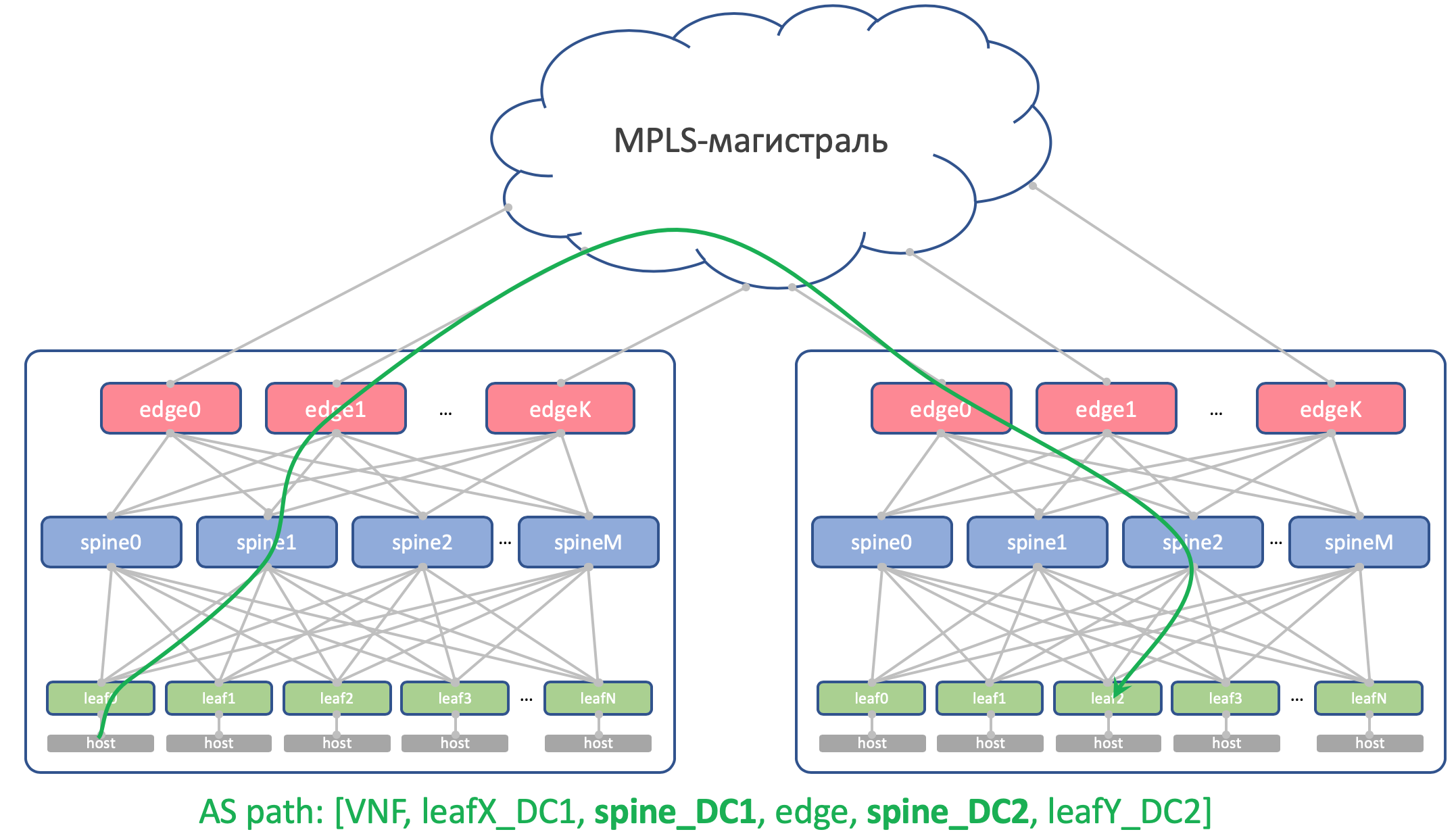
That is, Spine_DC1 and Spine_DC2 should be different, just like leafX_DC1 and leafY_DC2, which is exactly what we are approaching.
As you probably know, there are hacks that allow you to accept routes with repeating ASNs in spite of the mechanism for preventing loops (allowas-in on Cisco). And it has even quite legitimate uses. But this is a potential breach in network resilience. And I personally fell into it a couple of times.
And if we have the opportunity not to use dangerous things, we will use it.
Leaf asn
We will have an individual ASN on each Leaf switch throughout the network.
We do this for the reasons given above: AS-Path without loops, BGP configuration without bookmarks.
In order for routes between Leafs to pass unhindered, AS-Path should look like this:
[leafX_ASN, spine_ASN, leafY_ASN]
where leafX_ASN and leafY_ASN would be nice to be different.
This is also required for the situation with the announcement of the VNF loopback between DCs:
[VNF_ASN, leafX_DC1_ASN , spine_DC1_ASN, edge_ASN, spine_DC2_ASN, leafY_DC2_ASN ]
We will use the 4-byte ASN and generate it based on Spine’s ASN and Leaf-switch number, namely, like this: Spine_ASN.0000X .
Here is a picture with ASN.
IP plan
Basically, we need to allocate addresses for the following connections:
- Underlay network addresses between ToR and the machine. They must be unique throughout the network so that any machine can communicate with any other. Great for 10/8 . For each rack / 26 with a margin. We will allocate / 19 for DC and / 17 for the region.
- Link addresses between Leaf / Tor and Spine.
I would like to assign them algorithmically, that is, calculate from the names of devices that need to be connected.
Let it be ... 169.254.0.0/16.
Namely, 169.254.00X.Y / 31 , where X is the Spine number, Y is the P2P network / 31.
This will allow you to run up to 128 racks, and up to 10 Spine in the DC. Link addresses can (and will) be repeated from DC to DC. - We organize the Spine - Edge-Leaf joint on the 169.254.10X.Y / 31 subnets, where in the same way X is the Spine number, Y is the P2P network / 31.
- Link addresses from the Edge-Leaf to the MPLS backbone. Here the situation is somewhat different - the place of connecting all the pieces into one pie, so reusing the same addresses will not work - you need to select the next free subnet. Therefore, we will take 192.168.0.0/16 as the basis and we will rake free ones from it.
- Loopback Addresses. Let's give them the whole range of 172.16.0.0/12 .
- Leaf - at / 25 per DC - the same 128 racks. Allocate by / 23 to the region.
- Spine - by / 28 at the DC - up to 16 Spine. Allocate by / 26 to the region.
- Edge-Leaf - by / 29 on DC - up to 8 boxes. Allocate by / 27 to the region.
If in the DC we don’t have enough of the selected ranges (and they will not be there - we pretend to be hyper-skeylerostvo), just select the next block.
Here is a picture with IP addressing.

Loopbacks:
| Prefix | Device role | Region | DC |
| 172.16.0.0/23 | edge | ||
| 172.16.0.0/27 | ru | ||
| 172.16.0.0/29 | msk | ||
| 172.16.0.8/29 | kzn | ||
| 172.16.0.32/27 | sp | ||
| 172.16.0.32/29 | bcn | ||
| 172.16.0.40/29 | mlg | ||
| 172.16.0.64/27 | cn | ||
| 172.16.0.64/29 | sha | ||
| 172.16.0.72/29 | sia | ||
| 172.16.2.0/23 | spine | ||
| 172.16.2.0/26 | ru | ||
| 172.16.2.0/28 | msk | ||
| 172.16.2.16/28 | kzn | ||
| 172.16.2.64/26 | sp | ||
| 172.16.2.64/28 | bcn | ||
| 172.16.2.80/28 | mlg | ||
| 172.16.2.128/26 | cn | ||
| 172.16.2.128/28 | sha | ||
| 172.16.2.144/28 | sia | ||
| 172.16.8.0/21 | leaf | ||
| 172.16.8.0/23 | ru | ||
| 172.16.8.0/25 | msk | ||
| 172.16.8.128/25 | kzn | ||
| 172.16.10.0/23 | sp | ||
| 172.16.10.0/25 | bcn | ||
| 172.16.10.128/25 | mlg | ||
| 172.16.12.0/23 | cn | ||
| 172.16.12.0/25 | sha | ||
| 172.16.12.128/25 | sia |
Underlay:
| Prefix | Region | DC |
| 10.0.0.0/17 | ru | |
| 10.0.0.0/19 | msk | |
| 10.0.32.0/19 | kzn | |
| 10.0.128.0/17 | sp | |
| 10.0.128.0/19 | bcn | |
| 10.0.160.0/19 | mlg | |
| 10.1.0.0/17 | cn | |
| 10.1.0.0/19 | sha | |
| 10.1.32.0/19 | sia |
Laba
Two vendors. One network. ADSM.
Juniper + Arista. Ubuntu Good old Eve.
The amount of resources on our virtualochka in Miran is still limited, so for practice we will use such a simplified network to the limit.
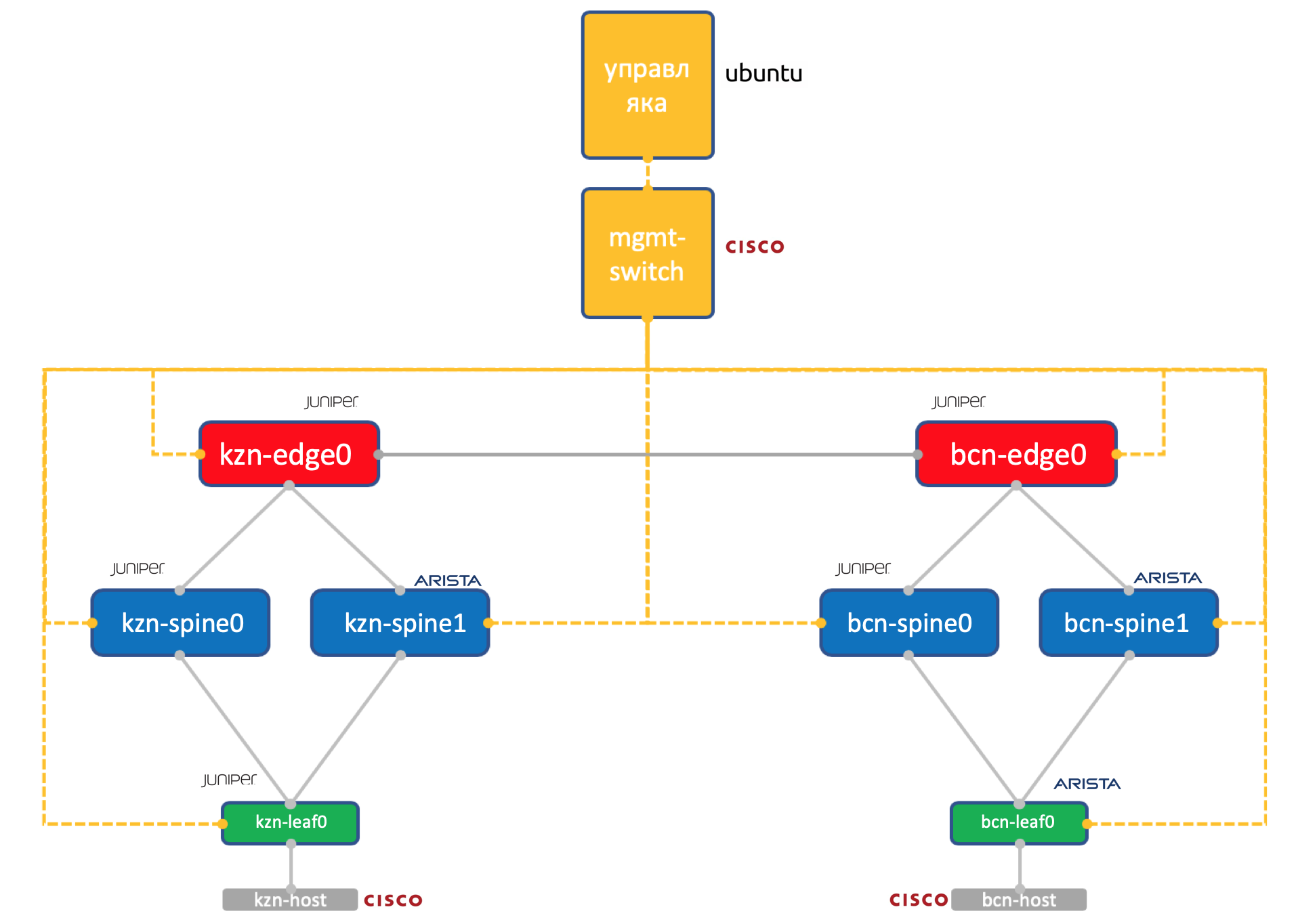
Two data centers: Kazan and Barcelona.
- Two spines in each: Juniper and Arista.
- One torus (Leaf) in each - Juniper and Arista, with one host connected (let's take the lightweight Cisco IOL for this).
- One Edge-Leaf node (only Juniper so far).
- One Cisco switch to rule them all.
- In addition to network boxes, a management virtual machine has been launched. Running Ubuntu.
It has access to all devices, IPAM / DCIM systems, a bunch of Python scripts, ansible and anything else that we may need will be spinning on it.
The full configuration of all network devices that we will try to reproduce using automation.
Conclusion
Also accepted? Under each article to make a short conclusion?
So, we chose the three-level Klose network inside the DC, because we expect a lot of East-West traffic and want ECMP.
We divided the network into physical (underlay) and virtual (overlay). In this case, the overlay starts from the host - thereby simplifying the requirements for the underlay.
We chose BGP as the routing protocol for the undeleted networks because of its scalability and flexibility of policies.
We will have separate nodes for DCI organization - Edge-leaf.
There will be OSPF + LDP on the trunk.
DCI will be implemented based on MPLS L3VPN.
For P2P links, we will calculate IP addresses algorithmically based on device names.
Lupbacks will be assigned by the role of devices and their location sequentially.
Underlay prefixes - only on Leaf switches sequentially based on their location.
Suppose we don’t have the equipment installed right now.
Therefore, our next steps will be to get them in the systems (IPAM, inventory), arrange access, generate a configuration and deploy it.
In the next article, we will deal with Netbox, the inventory and IP space management system in the DC.
Thanks
- Andrey Glazkov aka @glazgoo for proofreading and editing
- Alexander Klimenko aka @ v00lk for proofreading and editing
- Artyom Chernobay for KDPV