
Hello. My name is Alexander, I am a Java developer in the Tinkoff group of companies.
In this article I want to share my experience in solving problems associated with synchronizing the state of caches in distributed systems. We ran into them, breaking our monolithic application into
In this article, I will talk about our experience of switching to a service-oriented architecture, accompanied by a move to Kubernetes, and about solving related problems. We will consider the approach to organizing an In-Memory Data Grid (IMDG) distributed caching system, its advantages and disadvantages, because of which we decided to write our own solution.
This article discusses a project whose backend is written in Java. Therefore, we will also talk about standards in the field of temporary In-memory caching. We discuss the JSR-107 specification, the failed JSR-347 specification, and the caching features in Spring. Welcome to cat!
And let's cut the application into services ...
We’ll move on to service-oriented architecture and move to Kubernetes - that's what we decided a little more than 6 months ago. For a long time, our project was a monolith, many problems related to technical debt accumulated, and we wrote new application modules at all as separate services. As a result, the transition to a service-oriented architecture and a monolith cut was inevitable.
Our application is loaded, on average 500 rps comes to web services (at the peak it reaches 900 rps). In order to collect the entire data model in response to each request, you have to go to the various caches several hundred times.
We try to go to the remote cache no more than three times per request, depending on the required data set, and on internal JVM caches the load reaches 90,000 rps per cache. We have about 30 such caches for a variety of entities and DTO-shki. On some loaded caches, we can’t even afford to delete the value, as this can lead to an increase in the response time of web services and a crash in the application.

This is how load monitoring is removed from internal caches on each node during the day. According to the load profile, it is easy to see that most of the requests are read data. A uniform load on the record is due to updating values in the caches with a given frequency.
Downtime is not valid for our application. Therefore, for the purpose of a seamless deployment, we always balanced all incoming traffic to two nodes and deployed the application using the Rolling Update method. Kubernetes became our ideal infrastructure solution when switching to services. Thus, we solved several problems at once.
The problem of constantly ordering and setting up infrastructure for new services
We were given a namespace in the cluster for each circuit, which we have three: dev - for developers, qa - for testers, prod - for clients.
With the namespace highlighted, adding a new service or application comes down to writing four manifests: Deployment, Service, Ingress, and ConfigMap.
High load tolerance
The business is expanding and constantly growing - a year ago the average load was half the current load.
Horizontal scaling in Kubernetes allows you to level out the economies of scale with increasing load of the developed project.
Maintenance, log collection and monitoring
Life becomes much easier when there is no need to add logs to the logging system when adding each node, configure the metrics fence (unless you have a push monitoring system), perform network settings and simply install the necessary software for operation.
Of course, all this can be automated using Ansible or Terraform, but in the end, writing multiple manifests for each service is much easier.
High reliability
The built-in k8s mechanism of Liveness- and Readiness-samples allows you not to worry that the application began to slow down or completely stopped responding.
Kubernetes now controls the life cycle of hearth pods containing application containers and the traffic that is directed to them.
Along with the described amenities, we needed to resolve a number of issues in order to make the services suitable for horizontal scaling and use of a common data model for many services. It was necessary to solve two problems:
- The state of the application. When the project is deployed in the k8s cluster, pods with containers of the new version of the application begin to be created that are not related to the state of the pods of the previous version. New application pods can be raised on arbitrary cluster servers that satisfy the given restrictions. Also now, every application container running inside Kubernetes pod can be destroyed at any time if the Liveness probe says that it needs to be restarted.
- Data consistency. It is necessary to maintain consistency and data integrity with each other at all nodes. This is especially true if several nodes work within a single data model. It is unacceptable that when requests to different nodes of the application in the response to the client came inconsistent data.
In the modern development of scalable systems, Stateless architecture is the solution to the above problems. We got rid of the first problem by moving all the statics to the S3 cloud storage.
However, due to the need to aggregate a complex data model and save response time of our web services, we could not refuse to store data in In-memory caches. To solve the second problem, they wrote a library for synchronizing the state of internal caches of individual nodes.
We synchronize caches on separate nodes
As initial data we have a distributed system consisting of N nodes. Each node has about 20 in-memory caches, the data in which is updated several times per hour.
Most caches have a TTL (time-to-live) data refresh policy, some data is updated with a CRON operation every 20 minutes due to the high load. The workload on caches varies from several thousand rps at night to several tens of thousands during the day. Peak load, as a rule, does not exceed 100,000 rps. The number of records in temporary storage does not exceed several hundred thousand and is placed in the heap of one node.
Our task is to achieve the consistency of data between the same cache on different nodes, as well as the shortest possible response time. Consider what there are generally ways to solve this problem.
The first and most simple solution that comes to mind is to put all the information in a remote cache. In this case, you can completely get rid of the state of the application, not think about the problems of achieving consistency and have a single access point to a temporary data warehouse.
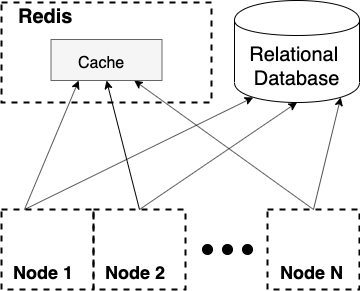
This method of temporary storage of data is quite simple, and we use it. We cache part of the data in Redis , which is a NoSQL data storage in RAM. In Redis, we usually record a web service response framework, and for each request we need to enrich this data with relevant information, which requires sending several hundred requests to the local cache.
Obviously, we cannot take out the data of internal caches for remote storage, since the cost of transmitting such a volume of traffic over the network will not allow us to meet the required response time.
The second option is to use an In-Memory Data Grid (IMDG), which is a distributed In-memory cache. The scheme of such a solution is as follows:
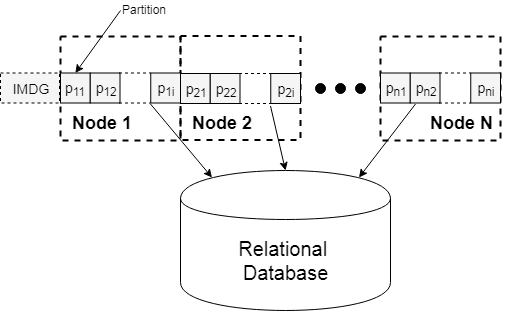
IMDG architecture is based on the principle of data partitioning of internal caches of individual nodes. In fact, this can be called a hash table distributed on a cluster of nodes. IMDG is considered one of the fastest implementations of temporary distributed storage.
There are many IMDG implementations, the most popular being Hazelcast . The distributed cache allows you to store data in RAM on several application nodes with an acceptable level of reliability and preservation of the consistency, which is achieved by data replication.
The task of building such a distributed cache is not easy, however, using a ready-made IMDG solution for us could be a good replacement for JVM caches and eliminate the problems of replication, consistency and data distribution between all application nodes.
Most IMDG vendors for Java applications implement JSR-107 , the standard Java API for working with internal caches. In general, this standard has a rather big story, which I will discuss in more detail below.
Once upon a time there were ideas to implement your interface for interacting with IMDG - JSR 347 . But the implementation of such an API did not receive sufficient support from the Java community, and now we have a single interface for interacting with In-memory caches, regardless of the architecture of our application. Whether this is good or bad is another question, but it allows us to completely disengage from all the difficulties of implementing a distributed In-memory cache and work with it as a cache of a monolithic application.
Despite the obvious advantages of using IMDG, this solution is still slower than the standard JVM cache, due to the overhead of ensuring continuous replication of data distributed between several JVM nodes, as well as backing up this data. In our case, the amount of data for temporary storage was not so large, the data with a margin fit in the memory of one application, so their allocation to several JVMs seemed to be an excessive solution. And additional network traffic between application nodes under heavy loads can greatly impact performance and increase the response time of web services. In the end, we decided to write our own solution for this problem.
We left in-memory caches as a temporary storage of data, and to maintain consistency we used the RabbitMQ queue manager. We adopted the Publisher-Subscriber behavioral design pattern, and maintained the data by removing the modified entry from the cache of each node. The solution scheme is as follows:
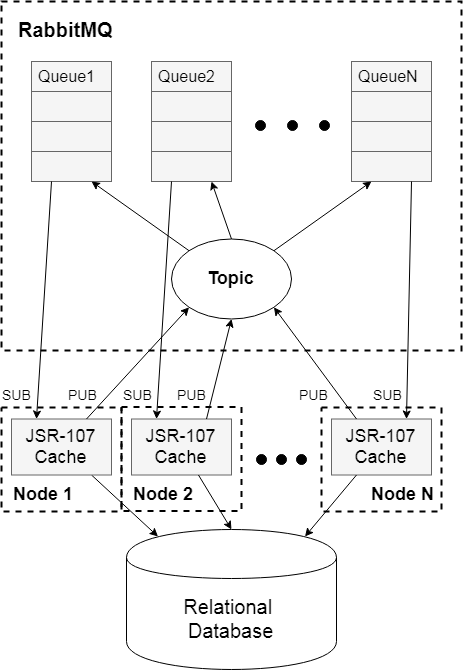
The diagram shows a cluster of N nodes, each of which has a standard In-memory cache. All nodes use a common data model and must be consistent. At the first access to the cache by an arbitrary key, the value in the cache is absent, and we put the actual value from the database into it. With any change - delete the record.
Up-to-date information in the cache response here is provided by synchronizing the deletion of an entry when it is changed on any of the nodes. Each node in the system is assigned a queue in the RabbitMQ queue manager. Recording in all queues is carried out through a common Topic-type access point. This means that messages sent to Topic fall into all queues associated with it. So, when changing the value on any node of the system, this value will be deleted from the temporary storage of each node, and subsequent access will initiate the writing of the current value to the cache from the database.
By the way, a similar PUB / SUB mechanism exists in Redis. But, in my opinion, it is still better to use the queue manager for working with queues, and RabbitMQ was perfect for our task.
JSR 107 standard and its implementation
The standard Java Cache API for temporary storage of data in memory (specification JSR-107 ) has a rather long history; it has been developed for 12 years.
Over such a long time, approaches to software development have changed, the monoliths have been replaced by microservice architecture. Due to such a long lack of specifications for the Cache API, there were even requests to develop API caches for distributed systems JSR-347 (Data Grids for the Java Platform). But after the long-awaited release of JSR-107 and the release of JCache, the request to create a separate specification for distributed systems was withdrawn.
Over the long 12 years on the market, the place for temporary data storage has changed from HashMap to ConcurrentHashMap with the release of Java 1.5, and later many open-source open source implementations of In-memory caching appeared.
After the release of JSR-107, vendor solutions began to gradually implement the new specification. For JCache, there are even providers specializing in distributed caching - the very Data Grids, the specification for which has never been implemented.
Consider what the javax.cache package consists of , and how to get a cache instance for our application:
CachingProvider provider = Caching.getCachingProvider("org.cache2k.jcache.provider.JCacheProvider"); CacheManager cacheManager = provider.getCacheManager(); CacheConfiguration<Integer, String> config = new MutableConfiguration<Integer, String>() .setTypes(Integer.class, String.class) .setReadThrough(true) . . .; Cache<Integer, String> cache = cacheManager.createCache(cacheName, config);
Here Caching is a boot loader for CachingProvider.
In our case, JCacheProvider, which is the cache2k implementation of the JSR-107 provider SPI , will be loaded from ClassLoader. For the loader, you can not specify the implementation of the provider, but then it will try to load the implementation that lies in
META-INF / services / javax.cache.spi.CachingProvider
In any case, in ClassLoader there should be a single CachingProvider implementation.
If you use the javax.cache library without any implementation, an exception will be thrown when you try to create JCache. The purpose of the provider is to create and manage the life cycle of CacheManager, which, in turn, is responsible for managing and configuring the caches. Thus, to create a cache, you must go the following way:

The standard caches created using CacheManager must have an implementation-compatible configuration. The standard parameterized CacheConfiguration provided by javax.cache can be extended to a specific CacheProvider implementation.
Today, there are dozens of different implementations of the JSR-107 specification: Ehcache , Guava , caffeine , cache2k . Many implementations are In-Memory Data Grid in distributed systems - Hazelcast , Oracle Coherence .
There are also many temporary storage implementations that do not support the standard API. For a long time in our project we used Ehcache 2, which is not compatible with JCache (implementation of the specification appeared with Ehcache 3). The need to switch to a JCache-compatible implementation appeared with the need to monitor the status of In-memory caches. Using the standard MetricRegistry without problems, it was possible to fasten monitoring only with the help of the JCacheGaugeSet implementation, which collects metrics from standard JCache.
How to choose the appropriate In-memory cache implementation for your project? Perhaps you should pay attention to the following:
- Do you need support for the JSR-107 specification.
- It is also worth paying attention to the speed of the selected implementation. Under heavy loads, the performance of internal caches can have a significant impact on the response time of your system.
- Support in Spring. If you use the well-known framework in your project, you should take into account the fact that not every JVM cache implementation has a compatible CacheManager in Spring.
If you are actively using Spring in your project, just like us, then for data caching you most likely follow the aspect-oriented approach (AOP) and use the @Cacheable annotation. Spring uses its own CacheManager SPI for aspects to work. The following bean is required for spring caches to work:
@Bean public org.springframework.cache.CacheManager cacheManager() { CachingProvider provider = Caching.getCachingProvider(); CacheManager cacheManager = provider.getCacheManager(); return new JCacheCacheManager(cacheManager); }
To work with caches in the AOP paradigm, transactional considerations must also be considered. The spring cache must necessarily support transaction management. To this end, spring CacheManager inherits the AbstractTransactionSupportingCacheManager properties, with which it is possible to synchronize put- / evict operations performed within a transaction and execute them only after a successful transaction commit.
The example above shows the use of the JCacheCacheManager wrapper for the cache specification manager. This means that any JSR-107 implementation also has compatibility with Spring CacheManager. This is another reason to choose an In-memory cache with JSR specification support for your project. But if this support is still not needed, but I really want to use @Cacheable, then you have support for two more internal cache solutions: EhCacheCacheManager and CaffeineCacheManager.
When choosing the implementation of the in-memory cache, we did not take into account the support of IMDG for distributed systems, as mentioned earlier. To maintain the performance of JVM caches in our system, we wrote our own solution.
Clearing Caches in a Distributed System
Modern IMDGs used in projects with microservice architecture allow you to distribute data in memory between all the working nodes of the system using scalable data partitioning with the required level of redundancy.
In this case, there are many problems associated with synchronization, data consistency, and so on, not to mention the increase in access time to temporary storage. Such a scheme is redundant if the amount of data used fits in the RAM of one node, and to maintain the consistency of the data, it is enough to delete this entry on all nodes for any change in the cache value.
When implementing such a solution, the idea to use some EventListener first comes to mind, in JCache there is a CacheEntryRemovedListener for the event of deleting an entry from the cache. It seems that it’s enough to add your own Listener implementation, which will send messages to the topic when the record is deleted, and the eutectic cache on all nodes is ready - provided that each node listens for events from the queue associated with the general topic, as shown in the diagram higher.
When using this solution, data on different nodes will be inconsistent due to the fact that EventLists in any JCache implementation process after an event occurs. That is, if there is no record in the local cache for the given key, and there is a record for the same key on any other node, the event will not be sent to the topic.
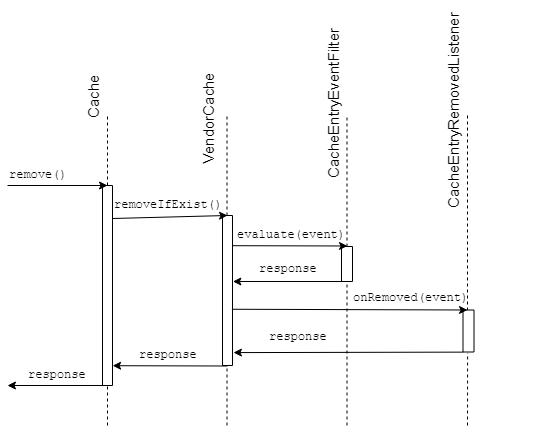
Consider what other ways there are to catch the event of a value being deleted from the local cache.
In the javax.cache.event package, next to EventListeners, there is also a CacheEntryEventFilter, which, according to the JavaDoc, is used to check for any CacheEntryEvent event before passing this event to the CacheEntryListener, whether it is a record, deletion, update or an event related to the expiration of the record in cache. When using the filter, our problem will remain, because the logic will be executed after the CacheEntryEvent event is logged and after the CRUD operation is performed in the cache.
Nevertheless, it is possible to catch the initiation of a delete record event from the cache. To do this, use the built-in tool in JCache that allows you to use the API specifications for writing and loading data from an external source, if they are not in the cache. There are two interfaces for this in the javax.cache.integration package:
- CacheLoader - to load the data requested by the key, if there are no entries in the cache.
- CacheWriter - to use writing, deleting and updating data on an external resource when invoking the corresponding cache operations.
To ensure consistency, CacheWriter methods are atomic with respect to the corresponding cache operation. We seem to have found a solution to our problem.
Now we can maintain the consistency of the response of In-memory caches on the nodes when using our implementation of CacheWriter, which sends events to the RabbitMQ topic whenever there is any change in the record in the local cache.
Conclusion
In developing any project, when searching for a suitable solution to emerging problems, one has to take into account its specificity. In our case, the characteristic features of the project data model, the inherited legacy code, and the nature of the load did not allow using any of the existing solutions to the distributed caching problem.
It is very difficult to make a universal implementation applicable to any developed system. For each such implementation, there are optimal conditions for use. In our case, the specifics of the project led to the solution described in this article. If someone has a similar problem, we will be happy to share our solution and publish it on GitHub.