
In a previous article, we examined RabbitMQ clustering for fault tolerance and high availability. Now let's dig deep into Apache Kafka.
Here, the replication unit is a partition. Each topic has one or more sections. Each section has a leader with or without followers. When creating a topic, the number of partitions and the replication rate are indicated. The usual value is 3, which means three remarks: one leader and two followers.
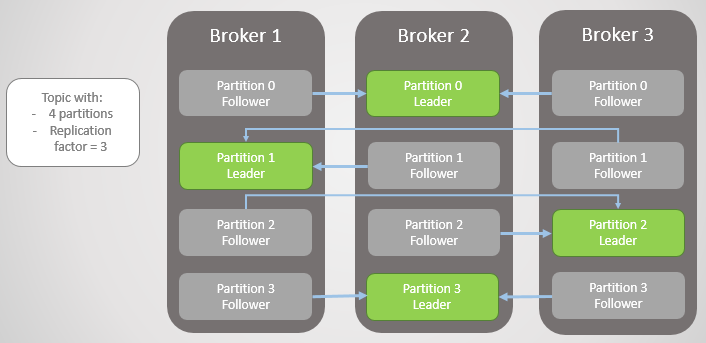
Fig. 1. Four sections are distributed among three brokers
All read and write requests go to the leader. Followers periodically send requests to the leader to receive the latest messages. Consumers never turn to followers, the latter exist only for redundancy and fault tolerance.

Section failed
When a broker falls off, leaders of several sections often fail. In each of them, the follower from another node becomes the leader. In fact, this is not always the case, since the synchronization factor also affects: whether there are synchronized followers, and if not, is the transition to an unsynchronized replica allowed. But for now, let's not complicate it.
Broker 3 leaves the network - and for section 2, a new leader on broker 2 is elected.

Fig. 2. Broker 3 dies and his follower on broker 2 is elected as the new leader of section 2
Then broker 1 leaves and section 1 also loses its leader, whose role goes to broker 2.
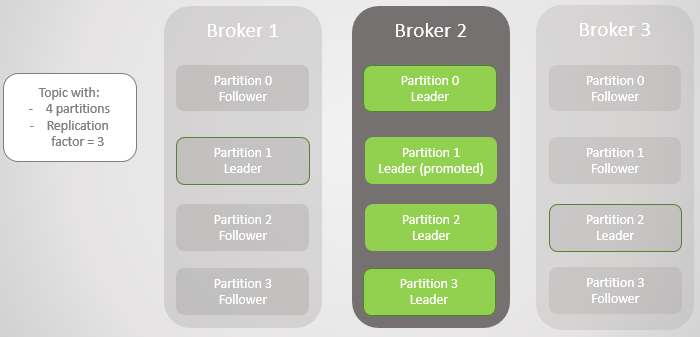
Fig. 3. There is only one broker left. All leaders are on the same zero redundancy broker.
When broker 1 returns to the network, he adds four followers, providing some redundancy to each section. But all the leaders still remained on broker 2.

Fig. 4. Leaders remain on broker 2
When broker 3 rises, we return to three replicas per section. But all the leaders are still on broker 2.

Fig. 5. Unbalanced placement of leaders after the restoration of brokers 1 and 3
Kafka has a tool for better rebalancing of leaders than RabbitMQ. There you had to use a third-party plug-in or script that changed policies for migrating the main node by reducing redundancy during the migration. In addition, for large queues had to put up with inaccessibility during synchronization.
Kafka has a concept of “preferred cues” for the leadership role. When the topic sections are created, Kafka tries to evenly distribute the leaders across the nodes and marks these first leaders as preferred. Over time, due to server reboots, failures, and connectivity failures, leaders may end up on other nodes, as in the extreme case described above.
To fix this, Kafka offers two options:
- The auto.leader.rebalance.enable = true option allows the controller node to automatically reassign leaders back to preferred replicas and thereby restore uniform distribution.
- An administrator can run the kafka-preferred-replica-election.sh script to manually reassign.
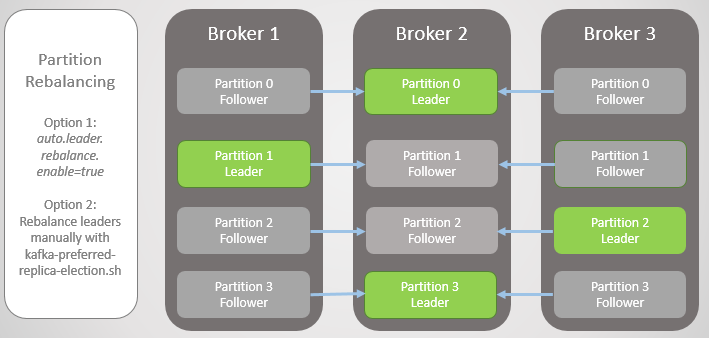
Fig. 6. Replicas after rebalancing
It was a simplified version of the failure, but the reality is more complex, although there is nothing too complicated here. It all comes down to synchronized replicas (In-Sync Replicas, ISR).
Synchronized Replicas (ISR)
ISR is a set of replicas of a partition that is considered to be “synchronized” (in-sync). There is a leader, but there may not be followers. A follower is considered synchronized if he made exact copies of all leader messages before the expiration of the replica.lag.time.max.ms interval.
The follower is removed from the ISR set if it:
- did not make a request for sampling for the interval replica.lag.time.max.ms (considered dead)
- did not have time to update for the interval replica.lag.time.max.ms (considered slow)
Followers make fetch requests in the interval replica.fetch.wait.max.ms , which by default is 500 ms.
To clearly explain the purpose of the ISR, you need to look at the confirmations from the producer (producer) and some failure scenarios. Producers can choose when a broker sends a confirmation:
- acks = 0, confirmation is not sent
- acks = 1, confirmation is sent after the leader has written a message to his local log
- acks = all, confirmation is sent after all replicas in the ISR have written a message to the local logs
In Kafka terminology, if the ISR has saved the message, it commits. Acks = all is the safest option, but also an additional delay. Let's look at two examples of failure and how the different 'acks' options interact with the ISR concept.
Acks = 1 and ISR
In this example, we will see that if the leader does not wait for each message from all followers to be saved, then if the leader fails, data may be lost. Going to an unsynchronized follower can be enabled or disabled by setting unclean.leader.election.enable .
In this example, the manufacturer is set to acks = 1. The section is distributed across all three brokers. Broker 3 is behind, it synchronized with the leader eight seconds ago and is now behind by 7456 messages. Broker 1 is only one second behind. Our producer sends a message and quickly receives ack back, without overhead for slow or dead followers that the leader does not expect.

Fig. 7. ISR with three replicas
Broker 2 fails and the manufacturer receives a connection error. After the leadership transition to broker 1, we lose 123 messages. The follower on broker 1 was part of the ISR, but did not fully synchronize with the leader when he fell.

Fig. 8. If a failure occurs, messages are lost
In the bootstrap.servers configuration, the manufacturer lists several brokers, and he can ask another broker who became the new leader of the section. He then establishes a connection with broker 1 and continues to send messages.

Fig. 9. Sending messages resumes after a short break
Broker 3 lags even further. It makes fetch requests, but cannot synchronize. This may be due to a slow network connection between brokers, a storage problem, etc. It is removed from the ISR. Now ISR consists of one remark - the leader! The manufacturer continues to send messages and receive confirmation.

Fig. 10. The follower on broker 3 is removed from the ISR
Broker 1 falls, and the role of the leader goes to broker 3 with the loss of 15286 messages! The manufacturer receives a connection error message. Going to the leader outside the ISR was only possible due to the setting unclean.leader.election.enable = true . If it is set to false , then the transition would not have occurred, and all read and write requests would be rejected. In this case, we are waiting for the return of broker 1 with its untouched data in the replica, which will again take the lead.
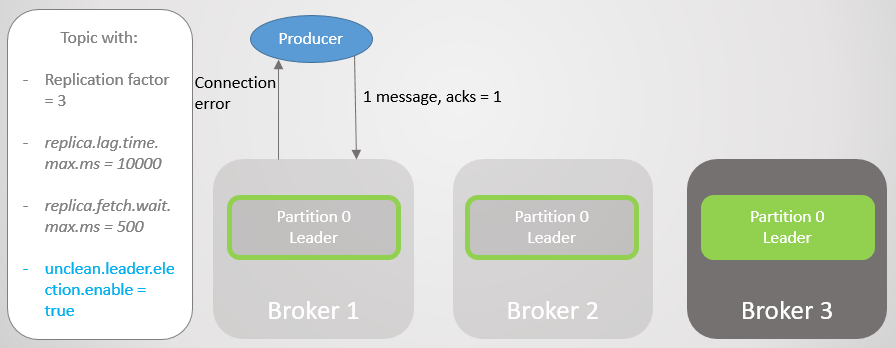
Fig. 11. Broker 1 drops. A large number of messages are lost on failure
The manufacturer establishes a connection with the last broker and sees that he is now the leader of the section. He begins to send messages to broker 3.

Fig. 12. After a brief break, messages are again sent to section 0
We saw that in addition to brief interruptions to establish new connections and search for a new leader, the manufacturer constantly sent messages. This configuration provides accessibility through consistency (data security). Kafka lost thousands of messages, but continued to accept new entries.
Acks = all and ISR
Let's repeat this scenario again, but with acks = all . Delay broker 3 an average of four seconds. The manufacturer sends a message with acks = all , and now does not receive a quick response. The leader waits until all messages in the ISR have saved the message.
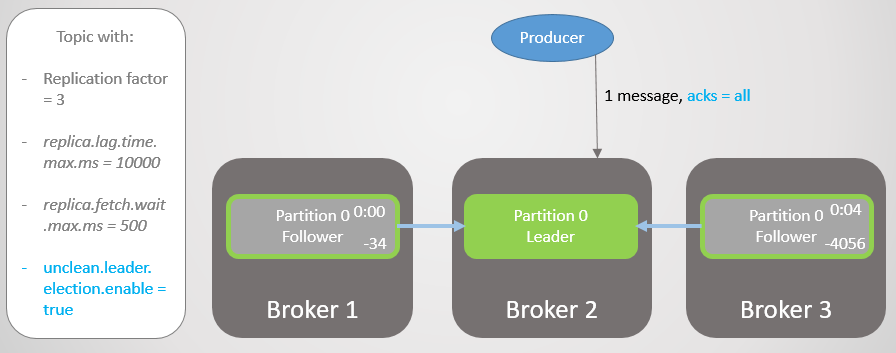
Fig. 13. ISR with three replicas. One is slow, causing a delay in recording
After four seconds of additional delay, broker 2 sends ack. All replicas are now fully updated.
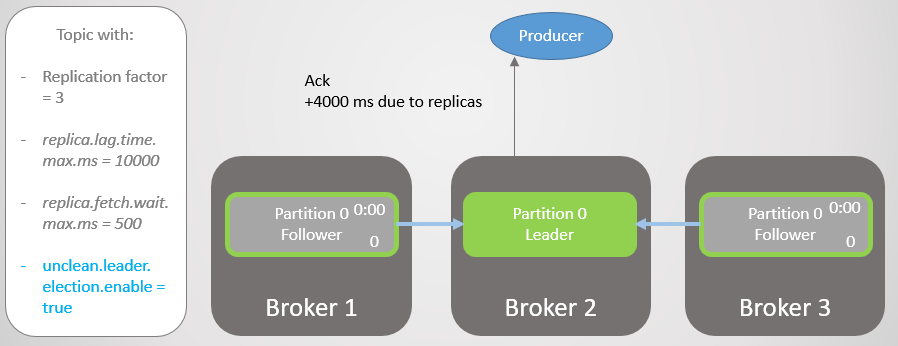
Fig. 14. All replicas save messages and ack is sent
Broker 3 is now even further behind and is being removed from the ISR. The delay is significantly reduced because there are no slow replicas left in the ISR. Broker 2 is now waiting only for broker 1, and he has an average lag of 500 ms.

Fig. 15. The replica on broker 3 is removed from the ISR
Then broker 2 falls, and leadership passes to broker 1 without losing messages.

Fig. 16. Broker 2 is falling
The manufacturer finds a new leader and begins to send him messages. The delay is still reduced, because now the ISR consists of one replica! Therefore, the acks = all option does not add redundancy.
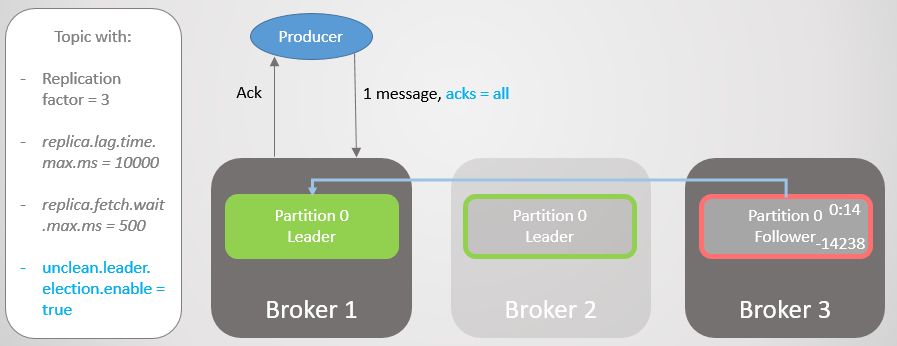
Fig. 17. The replica on broker 1 takes the lead without losing messages
Then broker 1 falls, and leadership passes to broker 3 with a loss of 14,238 messages!

Fig. 18. Broker 1 dies, and leadership transition with unclean setup leads to extensive data loss
We could not set the unclean.leader.election.enable option to true . By default, it is false . Setting acks = all with unclean.leader.election.enable = true provides accessibility with some additional data security. But, as you can see, we can still lose messages.
But what if we want to increase data security? You can set unclean.leader.election.enable = false , but this does not necessarily protect us from data loss. If the leader fell hard and took the data with him, then the messages are still lost, plus accessibility is lost until the administrator recovers the situation.
It is better to guarantee the redundancy of all messages, and otherwise refuse to record. Then, at least from the broker's point of view, data loss is possible only with two or more simultaneous failures.
Acks = all, min.insync.replicas and ISR
With the min.insync.replicas topic configuration, we increase data security. Let's go through the last part of the last scenario again, but this time with min.insync.replicas = 2 .
So, broker 2 has a replica leader, and the follower on broker 3 is removed from the ISR.
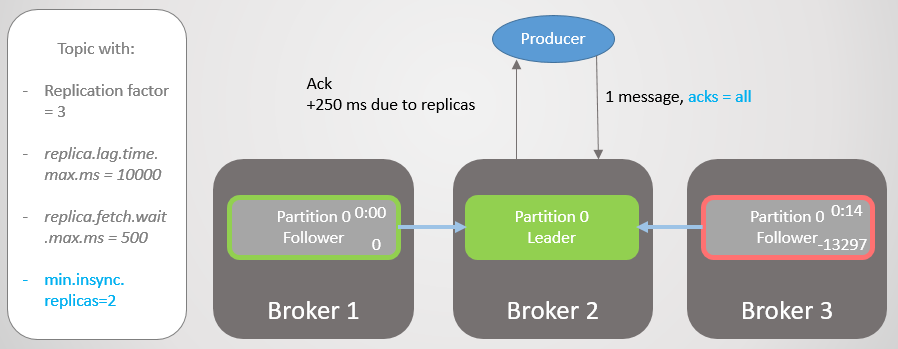
Fig. 19. ISR of two replicas
Broker 2 falls, and leadership passes to broker 1 without losing messages. But now ISR consists of only one replica. This does not correspond to the minimum number for receiving records, and therefore the broker responds to the attempt to record with the NotEnoughReplicas error.
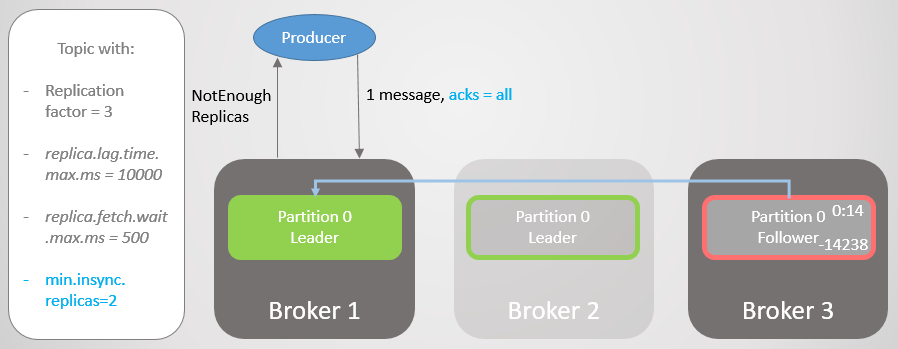
Fig. 20. The number of ISRs is one lower than that specified in min.insync.replicas
This configuration sacrifices availability for consistency. Before confirming a message, we guarantee that it is recorded on at least two replicas. This gives the manufacturer much more confidence. Here, message loss is possible only if two replicas fail at the same time in a short interval, until the message is replicated to an additional follower, which is unlikely. But if you are a superparanoid, you can set the replication rate to 5, and min.insync.replicas to 3. Then three brokers at once must fall at the same time to lose the record! Of course, for such reliability you will pay an additional delay.
When accessibility is needed for data security
As with RabbitMQ , sometimes accessibility is necessary for data security. You need to think about this:
- Can a publisher just return an error, and a higher service or user try again later?
- Can a publisher save a message locally or in a database to retry later?
If the answer is no, then accessibility optimization improves data security. You will lose less data if you choose availability instead of opt-out. Thus, it all comes down to finding a balance, and the decision depends on the specific situation.
The meaning of ISR
The ISR suite allows you to choose the optimal balance between data security and latency. For example, to ensure that most replicas are accessible in the event of failure, minimizing the impact of dead or slow replicas in terms of delay.
We ourselves choose the value of replica.lag.time.max.ms in accordance with our needs. In essence, this parameter means what delay we are ready to accept with acks = all . The default value is ten seconds. If this is too long for you, you can reduce it. Then the frequency of changes in the ISR will increase, as followers will more often be deleted and added.
RabbitMQ is just a collection of mirrors that need to be replicated. Slow mirrors introduce an additional delay, and the response of dead mirrors can be expected before the expiration of packets that check the availability of each node (net tick). ISRs are an interesting way to avoid these problems with increased latency. But we risk losing redundancy, since ISR can only be reduced to a leader. To avoid this risk, use the min.insync.replicas setting.
Customer Connection Guarantee
In the bootstrap.servers settings of the manufacturer and consumer, you can specify several brokers for connecting clients. The idea is that when you disconnect one node, there are several spare nodes with which the client can open a connection. These are not necessarily section leaders, but simply a springboard for bootstrapping. The client may ask them on which node the leader of the read / write section is located.
In RabbitMQ, clients can connect to any node, and internal routing sends a request where necessary. This means that you can install a load balancer in front of RabbitMQ. Kafka requires clients to connect to the host hosting the leader of the corresponding partition. In this situation, the load balancer does not deliver. The bootstrap.servers list is critical so that clients can access the correct nodes and find them after a crash.
Kafka Consensus Architecture
So far, we have not considered how the cluster finds out about the fall of the broker and how a new leader is chosen. To understand how Kafka works with network partitions, you first need to understand the consensus architecture.
Each Kafka cluster is deployed with the Zookeeper cluster - it is a distributed consensus service that allows the system to reach consensus at some given state with priority over consistency over availability. Approval of read and write operations requires the consent of most Zookeeper nodes.
Zookeeper stores cluster status:
- List of topics, sections, configuration, current leader replicas, preferred replicas.
- Cluster members. Each broker pings into a Zookeeper cluster. If he does not receive ping for a given period of time, then Zookeeper writes the broker inaccessible.
- The choice of primary and secondary nodes for the controller.
The controller node is one of the Kafka brokers who is responsible for electing replica leaders. Zookeeper sends to the controller notifications of cluster membership and topic changes, and the controller must act in accordance with these changes.
For example, take a new topic with ten sections and a replication coefficient of 3. The controller must select the leader of each section, trying to optimally distribute the leaders between brokers.
For each section, the controller:
- updates information in Zookeeper about ISR and the leader;
- sends a LeaderAndISRCommand command to each broker who posts a replica of this section, informing brokers about the ISR and leader.
When a broker with a leader falls, Zookeeper sends a notification to the controller, and he selects a new leader. Again, the controller first updates Zookeeper, and then sends a command to each broker, notifying them of a change in leadership.
Each leader is responsible for recruiting ISRs. The replica.lag.time.max.ms setting determines who will go there. When the ISR changes, the leader passes the new information to Zookeeper.
Zookeeper is always informed of any changes, so that in the event of a failure, the management smoothly moves to the new leader.

Fig. 21. Consensus Kafka
Replication protocol
Understanding replication details helps you better understand potential data loss scenarios.
Sample Requests, Log End Offset (LEO) and Highwater Mark (HW)
We have considered that followers periodically send fetch requests to the leader. The default interval is 500 ms. This differs from RabbitMQ in that in RabbitMQ, replication is initiated not by the queue mirror, but by the wizard. The master pushes changes to the mirrors.
The leader and all followers retain the Log End Offset (LEO) and the Highwater (HW) label. The LEO flag stores the offset of the last message in the local replica, and HW stores the offset of the last commit. Remember that for the commit status, the message must be saved in all ISR replicas. This means that LEO is usually slightly ahead of HW.
When a leader receives a message, he saves it locally. The follower makes a fetch request, passing his LEO. The leader then sends a message packet starting with this LEO, and also sends the current HW. When the leader receives information that all replicas have saved the message at a given offset, he moves the HW mark. Only the leader can move the HW, and so all followers will know the current value in the responses to their request. This means that followers can lag behind the leader in both reporting and knowledge of HW. Consumers receive messages only up to the current HW.
Note that “persisted” means written to memory, not to disk. For performance, Kafka synchronizes to disk at a specified interval. RabbitMQ also has such an interval, but it will send confirmation to the publisher only after the master and all the mirrors have written the message to disk. Kafka developers for performance reasons decided to send ack as soon as the message is written to memory. Kafka relies on the fact that redundancy compensates for the risk of short-term storage of confirmed messages only in memory.
Leader Failure
When a leader falls, Zookeeper notifies the controller, and he selects a new leader replica. The new leader sets a new HW mark in line with his LEO. Then followers receive information about the new leader. Depending on the version of Kafka, the follower will choose one of two scenarios:
- Truncates the local log to the known HW and sends a request to the new leader for messages after this mark.
- It will send a request to the leader to find out HW at the time of his election as a leader, and then truncate the log to this offset. Then it will start to make periodic sampling requests, starting at this offset.
The follower may need to trim the log for the following reasons:
- When a leader fails, the first ISR follower registered with Zookeeper wins the election and becomes the leader. All followers in the ISR, although considered “synchronized,” might not have received copies of all messages from the former leader. It is possible that the selected follower does not have the most current copy. Kafka guarantees that there is no discrepancy between the replicas. Thus, in order to avoid a discrepancy, each follower must truncate his log to the HW value of the new leader at the time of his election. This is another reason why setting acks = all is so important for consistency.
- Messages are periodically written to disk. If all cluster nodes fail at the same time, then replicas with different offsets will be saved on the disks. It is possible that when brokers return to the network again, the new leader who will be elected will be behind his followers, because he was saved to disk before the others.
Cluster Reunion
When connecting to a cluster, the replicas do the same as when the leader fails: they check the leader’s replica and truncate their log to its HW (at the time of election). By comparison, RabbitMQ equally regards reunited nodes as completely new. In both cases, the broker discards any existing state. If automatic synchronization is used, then the master must replicate absolutely all the current contents to a new mirror in the way "and let the whole world wait." During this operation, the master does not accept any read or write operations. This approach creates problems in large queues.
Kafka is a distributed log, and in general it stores more messages than the RabbitMQ queue, where data is deleted from the queue after reading it. Active queues should remain relatively small. But Kafka is a log with its own retention policy, which can set a period of days or weeks. The approach with blocking the queue and full synchronization is absolutely unacceptable for a distributed log. Instead, Kafka followers simply clip their log to the leader’s HW (at the time of election) if their copy is ahead of the leader. In the more likely case, when the follower is behind, he just starts making sample requests, starting with his current LEO.
New or reunited followers start outside the ISR and do not commit. They simply work next to the group, receiving messages as quickly as they can, until they catch up with the leader and enter the ISR. There is no blocking and no need to throw away all your data.
Disruption of connectivity
Kafka has more components than RabbitMQ, so here is a more complex set of behaviors when connectivity is broken in the cluster. But Kafka was originally designed for clusters, so the solutions are very well thought out.
The following are some connectivity scenarios:
- Scenario 1. Follower does not see the leader, but still sees Zookeeper.
- Scenario 2. The leader does not see any followers, but still sees Zookeeper.
- Scenario 3. Follower sees the leader, but does not see Zookeeper.
- Scenario 4. The leader sees the followers, but does not see the Zookeeper.
- Scenario 5. The follower is completely separate from both other Kafka nodes and Zookeeper.
- Scenario 6. The leader is completely separate from both other Kafka nodes and Zookeeper.
- Scenario 7. A Kafka controller node does not see another Kafka node.
- Scenario 8. The Kafka controller does not see Zookeeper.
Each scenario has its own behavior.
Scenario 1. Follower does not see the leader, but still sees Zookeeper

Fig. 22. Scenario 1. ISR of three replicas
Lack of connectivity separates broker 3 from brokers 1 and 2, but not from Zookeeper. Broker 3 can no longer send sample requests. After the replica.lag.time.max.ms time has elapsed, it is deleted from the ISR and does not participate in message commits. Once connectivity is restored, he will resume sampling requests and join the ISR when he catches up with the leader. Zookeeper will continue to receive pings and assume that the broker is alive and well.
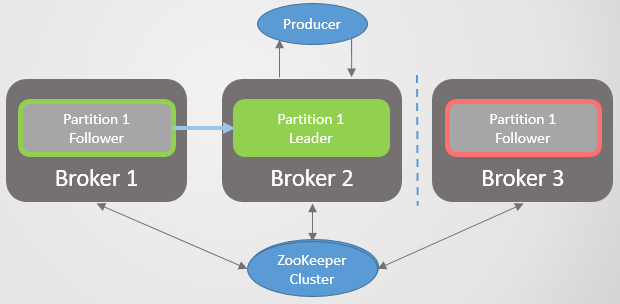
Fig. 23. Scenario 1. A broker is deleted from the ISR if it does not receive a request for sampling during the interval replica.lag.time.max.ms
There is no logical split-brain or node suspension, as in RabbitMQ. Instead, redundancy is reduced.
Scenario 2. The leader does not see any followers, but still sees Zookeeper

Fig. 24. Scenario 2. Leader and two followers
Disruption in network connectivity separates the leader from the followers, but the broker still sees Zookeeper. As in the first scenario, ISR is compressed, but this time only to the leader, since all followers stop sending requests for selection. Again, there is no logical separation. Instead, there is a loss of redundancy for new messages until connectivity is restored. Zookeeper continues to receive pings and believes that the broker is alive and well.

Fig. 25. Scenario 2. ISR shrunk only to a leader
Scenario 3. Follower sees the leader, but does not see Zookeeper
The follower is separated from Zookeeper, but not from the broker with the leader. As a result, the follower continues to make sample requests and be a member of the ISR. Zookeeper no longer receives pings and registers a broker crash, but since this is only a follower, there are no consequences after recovery.
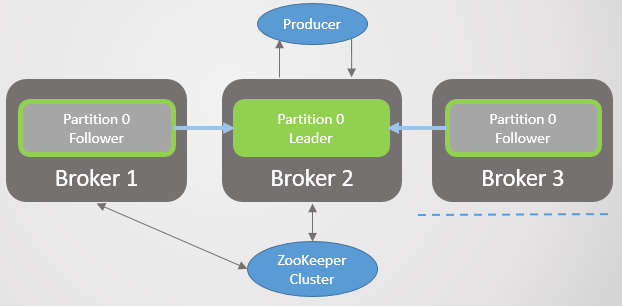
Fig. 26. Scenario 3. The follower continues to send sample requests to the leader
Scenario 4. The leader sees the followers, but does not see the Zookeeper
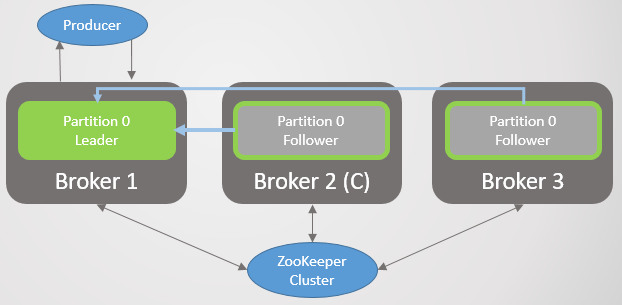
Fig. 27. Scenario 4. Leader and two followers
The leader is separate from Zookeeper, but not from brokers with followers.

Fig. 28. Scenario 4. The leader is isolated from Zookeeper
After a while, Zookeeper will register a broker crash and notify the controller. He will choose among the followers a new leader. However, the original leader will continue to think that he is the leader and will continue to accept entries with acks = 1 . Followers will no longer send him sample requests, so he will consider them dead and try to compress the ISR to himself. But since he does not have a connection to Zookeeper, he will not be able to do this, and at that moment he will refuse to accept further records.
Acks = all messages will not receive confirmation, because first the ISR includes all replicas, and the messages do not reach them. When the original leader tries to remove them from the ISR, he will not be able to do this and will cease to receive any messages at all.
Customers soon notice a change of leader and begin sending records to the new server. As soon as the network is restored, the original leader sees that he is no longer a leader, and truncates his log to the HW value that the new leader had at the time of the failure to avoid log divergence. Then he will start sending sampling requests to the new leader. All entries of the original leader that are not replicated to the new leader are lost. That is, messages that are not confirmed by the original leader in those few seconds when two leaders worked were lost.

Fig. 29. Scenario 4. The leader on broker 1 becomes a follower after the restoration of the network
Scenario 5. Follower is completely separate from both other Kafka nodes and Zookeeper
The follower is completely isolated from other Kafka nodes and from Zookeeper. ISR, , .
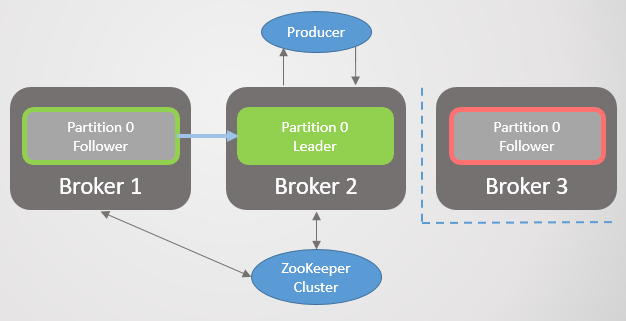
Fig. 30. 5. ISR
6. Kafka, Zookeeper

Fig. 31. 6.
, Zookeeper. acks=1 .

Fig. 32. 6. Kafka Zookeeper
replica.lag.time.max.ms , ISR , , Zookeeper, .
, Zookeeper , .
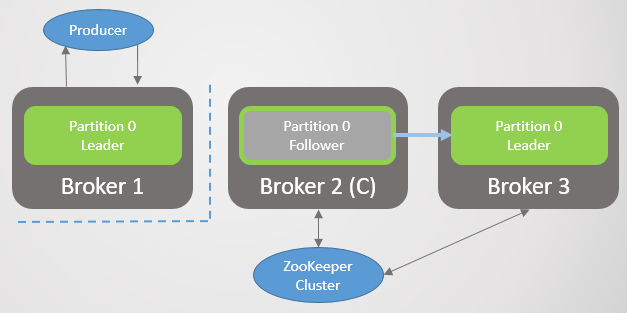
Fig. 33. 6.
, . 60 . .

Fig. 34. 6.
, . , Zookeeper , . HW .

Fig. 35. 6.
, acks=1 min.insync.replicas 1. , , , , — , . , acks=1 .
, , ISR . - . , , acks=all , ISR . . — min.insync.replicas = 2 .
7. Kafka Kafka
, Kafka . , 6. .
8. Kafka Zookeeper
Zookeeper Kafka. , Zookeeper, . , , , Kafka.
, , , . , , , .
- Zookeeper, acks=1 . Zookeeper . acks=all .
min.insync.replicas , , 6.
, Kafka:
- , acks=1
- (unclean) , ISR, acks=all
- Zookeeper, acks=1
- , ISR . , acks=all . , min.insync.replicas=1 .
- . , . .
, , . — acks=all min.insync.replicas 1.
RabbitMQ Kafka
. RabbitMQ . , . RabbitMQ. , . . , ( ) .
Kafka . . . , . , , . , - , . , .
RabbitMQ Kafka . , RabbitMQ . :
- fsync
- , (net tick). , .
Kafka , , , . - ( acks=all , min.insync.=2 ) .
Kafka . 11-, . 5 min.insync.replicas=3 . , .
RabbitMQ . . , . RabbitMQ , RabbitMQ .
RabbitMQ — . , (, ), , : Rebalanser ( ).
, RabbitMQ, Kafka. , 100% ! , - !
- , , .
: « , Kafka RabbitMQ?», « ?». , , . . , - . , .
, . , , , .
, , RabbitMQ Kafka — .