In spreadsheets like Excel, the running total is calculated very simply: the result in the first record matches its value:
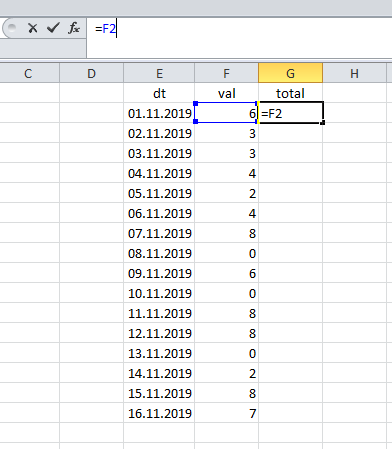
... and then we summarize the current value and the previous total.

In other words,
… or:
The appearance of two or more groups in the table complicates the task somewhat: now we count several results (for each group separately). However, here the solution lies on the surface: each time it is necessary to check which group the current record belongs to. Click and drag , and the work is done:
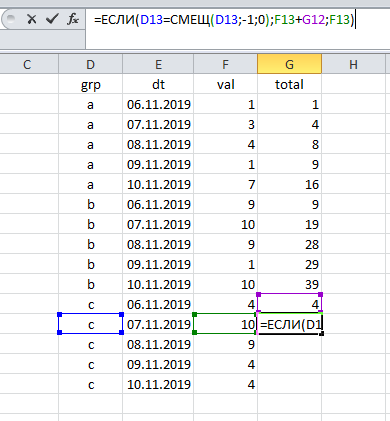
As you can see, the calculation of the cumulative total is associated with two unchanged components:
(a) sorting data by date and
(b) referring to the previous line.
But what is SQL? For a very long time there was no necessary functionality in it. A necessary tool - window functions - first appeared only in the SQL: 2003 standard. At that point, they were already in Oracle (version 8i). But the implementation in other DBMSs was delayed for 5-10 years: SQL Server 2012, MySQL 8.0.2 (2018), MariaDB 10.2.0 (2017), PostgreSQL 8.4 (2009), DB2 9 for z / OS (2007 year), and even SQLite 3.25 (2018).
Test data
-- -- -- create table test_simple (dt date null, val int null ); -- ( , . NLS_DATE_FORMAT Oracle) insert into test_simple (dt, val) values ('2019-11-01', 6); insert into test_simple (dt, val) values ('2019-11-02', 3); insert into test_simple (dt, val) values ('2019-11-03', 3); insert into test_simple (dt, val) values ('2019-11-04', 4); insert into test_simple (dt, val) values ('2019-11-05', 2); insert into test_simple (dt, val) values ('2019-11-06', 4); insert into test_simple (dt, val) values ('2019-11-07', 8); insert into test_simple (dt, val) values ('2019-11-08', 0); insert into test_simple (dt, val) values ('2019-11-09', 6); insert into test_simple (dt, val) values ('2019-11-10', 0); insert into test_simple (dt, val) values ('2019-11-11', 8); insert into test_simple (dt, val) values ('2019-11-12', 8); insert into test_simple (dt, val) values ('2019-11-13', 0); insert into test_simple (dt, val) values ('2019-11-14', 2); insert into test_simple (dt, val) values ('2019-11-15', 8); insert into test_simple (dt, val) values ('2019-11-16', 7); -- create table test_groups (grp varchar null, -- varchar2(1) in Oracle dt date null, val int null ); -- ( , . NLS_DATE_FORMAT Oracle) insert into test_groups (grp, dt, val) values ('a', '2019-11-06', 1); insert into test_groups (grp, dt, val) values ('a', '2019-11-07', 3); insert into test_groups (grp, dt, val) values ('a', '2019-11-08', 4); insert into test_groups (grp, dt, val) values ('a', '2019-11-09', 1); insert into test_groups (grp, dt, val) values ('a', '2019-11-10', 7); insert into test_groups (grp, dt, val) values ('b', '2019-11-06', 9); insert into test_groups (grp, dt, val) values ('b', '2019-11-07', 10); insert into test_groups (grp, dt, val) values ('b', '2019-11-08', 9); insert into test_groups (grp, dt, val) values ('b', '2019-11-09', 1); insert into test_groups (grp, dt, val) values ('b', '2019-11-10', 10); insert into test_groups (grp, dt, val) values ('c', '2019-11-06', 4); insert into test_groups (grp, dt, val) values ('c', '2019-11-07', 10); insert into test_groups (grp, dt, val) values ('c', '2019-11-08', 9); insert into test_groups (grp, dt, val) values ('c', '2019-11-09', 4); insert into test_groups (grp, dt, val) values ('c', '2019-11-10', 4); -- -- select * from test_simple order by dt; select * from test_groups order by grp, dt;
1. Window functions
Window functions are probably the easiest way. In the base case (table without groups) we consider data sorted by date:
order by dt
... but we are only interested in the lines before the current one:
rows between unbounded preceding and current row
Ultimately, we need a sum with these parameters:
sum(val) over (order by dt rows between unbounded preceding and current row)
A complete request would look like this:
select s.*, coalesce(sum(s.val) over (order by s.dt rows between unbounded preceding and current row), 0) as total from test_simple s order by s.dt;
In the case of a cumulative total for groups (
grp
field) we need only one small edit. Now we consider the data as divided into “windows” based on the group:

To account for this separation, you must use the
partition by
keyword:
partition by grp
And, accordingly, consider the amount for these windows:
sum(val) over (partition by grp order by dt rows between unbounded preceding and current row)
Then the whole request is converted in this way:
select tg.*, coalesce(sum(tg.val) over (partition by tg.grp order by tg.dt rows between unbounded preceding and current row), 0) as total from test_groups tg order by tg.grp, tg.dt;
The performance of window functions will depend on the specifics of your DBMS (and its version!), The size of the table, and the availability of indexes. But in most cases, this method will be the most effective. However, window functions are not available in older versions of the DBMS (which are still in use). In addition, they are not in such DBMSs as Microsoft Access and SAP / Sybase ASE. If a vendor-independent solution is needed, consideration should be given to alternatives.
2. Subquery
As mentioned above, window functions were introduced very late in the main DBMS. This delay should not be surprising: in relational theory, data is not ordered. Much more to the spirit of relational theory corresponds to a solution through a subquery.
Such a subquery should consider the sum of values with a date before the current (and including the current): .
What in the code looks like this:
select s.*, (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt <= s.dt) as total from test_simple s order by s.dt;
A slightly more effective solution will be in which the subquery considers the total up to the current date (but not including it), and then sums it up with the value in the row:
select s.*, s.val + (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt < s.dt) as total from test_simple s order by s.dt;
In the case of a cumulative result for several groups, we need to use a correlated subquery:
select g.*, (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt) as total from test_groups g order by g.grp, g.dt;
The condition
g.grp = t2.grp
checks the lines for inclusion in the group (which, in principle, is similar to the work of
partition by grp
in window functions).
3. Internal connection
Since subqueries and joins are interchangeable, we can easily replace one with another. To do this, you need to use Self Join, connecting two instances of the same table:
select s.*, coalesce(sum(t2.val), 0) as total from test_simple s inner join test_simple t2 on t2.dt <= s.dt group by s.dt, s.val order by s.dt;
As you can see, the filtering condition in the subquery
t2.dt <= s.dt
has become a join condition. In addition, in order to use the aggregating function
sum()
we need to group by date and value
group by s.dt, s.val
.
Similarly, you can do for the case with different
grp
groups:
select g.*, coalesce(sum(t2.val), 0) as total from test_groups g inner join test_groups t2 on g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt;
4. Cartesian product
Since we replaced the subquery with join, why not try the Cartesian product? This solution will require only minimal edits:
select s.*, coalesce(sum(t2.val), 0) as total from test_simple s, test_simple t2 where t2.dt <= s.dt group by s.dt, s.val order by s.dt;
Or for the case of groups:
select g.*, coalesce(sum(t2.val), 0) as total from test_groups g, test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt;
The listed solutions (subquery, inner join, cartesian join) correspond to SQL-92 and SQL: 1999 , and therefore will be available in almost any DBMS. The main problem with all of these solutions is poor performance. This is not a big trouble if we materialize the table with the result (but you still want more speed!). Further methods are much more effective (adjusted for the specifics of specific DBMSs and their versions already specified, table size, indexes).
5. Recursive request
One of the more specific approaches is a recursive query in a common table expression. To do this, we need an “anchor” - a query that returns the very first line:
select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple)
Then the results of the recursive query are added to the “anchor” using
union all
. To do this, you can rely on the
dt
date field, adding one day to it:
select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt) -- + 1 SQL Server
The piece of code that adds one day is not universal. For example, this is
r.dt = dateadd(day, 1, cte.dt)
for SQL Server,
r.dt = cte.dt + 1
for Oracle, etc.
Combining the "anchor" and the main request, we get the final result:
with cte (dt, val, total) as (select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple) union all select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt) -- r.dt = cte.dt + 1 Oracle, .. ) select dt, val, total from cte order by dt;
The solution for the case with the groups will not be much more complicated:
with cte (dt, grp, val, total) as (select g.dt, g.grp, g.val, g.val as total from test_groups g where g.dt = (select min(dt) from test_groups where grp = g.grp) union all select r.dt, r.grp, r.val, cte.total + r.val from cte inner join test_groups r on r.dt = dateadd(day, 1, cte.dt) -- r.dt = cte.dt + 1 Oracle, .. and cte.grp = r.grp ) select dt, grp, val, total from cte order by grp, dt;
6. Recursive query with row_number()
function
The previous decision was based on the continuity of the
dt
date field with a sequential increase of 1 day. We avoid this by using the
row_number()
window function, which numbers the rows. Of course, this is unfair - because we are going to consider alternatives to window functions. However, this solution may be a kind of proof of concept : in practice, there may be a field that replaces line numbers (record id). In addition, in SQL Server, the
row_number()
function appeared before full support for window functions was introduced (including
sum()
).
So, for a recursive query with
row_number()
we need two STEs. In the first, we only number the lines:
with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple)
... and if the row number is already in the table, then you can do without it. In the following query, we turn to
cte1
:
cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 )
And the whole request looks like this:
with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple), cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 ) select dt, val, total from cte2 order by dt;
... or for the case of groups:
with cte1 (dt, grp, val, rn) as (select dt, grp, val, row_number() over (partition by grp order by dt) as rn from test_groups), cte2 (dt, grp, val, rn, total) as (select dt, grp, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.grp, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.grp = cte2.grp and cte1.rn = cte2.rn + 1 ) select dt, grp, val, total from cte2 order by grp, dt;
7. CROSS APPLY
/ LATERAL
One of the most exotic ways of calculating a running total is to use the
CROSS APPLY
statement (SQL Server, Oracle) or its equivalent
LATERAL
(MySQL, PostgreSQL). These operators appeared rather late (for example, in Oracle only from version 12c). And in some DBMSs (for example, MariaDB ) they are not at all. Therefore, this decision is of purely aesthetic interest.
Functionally, using
CROSS APPLY
or
LATERAL
identical to the subquery: we attach the result of the calculation to the main request:
cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2
... which looks like this:
select s.*, t2.total from test_simple s cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2 order by s.dt;
The solution for the case with groups will be similar:
select g.*, t2.total from test_groups g cross apply (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt ) t2 order by g.grp, g.dt;
Total: we reviewed the main platform-independent solutions. But there are solutions specific to specific DBMS! Since there are so many options here, we’ll dwell on a few of the most interesting ones.
8. MODEL
statement (Oracle)
The
MODEL
statement in Oracle provides one of the most elegant solutions. At the beginning of the article, we examined the general formula of the cumulative total:
MODEL
allows you to implement this formula literally one to one! To do this, we first fill the
total
field with the values of the current row
select dt, val, val as total from test_simple
... then we calculate the line number as
row_number() over (order by dt) as rn
(or use the finished field with the number, if any). And finally, we introduce a rule for all lines except the first:
total[rn >= 2] = total[cv() - 1] + val[cv()]
.
The
cv()
function here is responsible for the value of the current line. And the whole request will look like this:
select dt, val, total from (select dt, val, val as total from test_simple) t model dimension by (row_number() over (order by dt) as rn) measures (dt, val, total) rules (total[rn >= 2] = total[cv() - 1] + val[cv()]) order by dt;
9. Cursor (SQL Server)
A running total is one of the few cases where the cursor in SQL Server is not only useful, but also preferable to other solutions (at least until version 2012, where window functions appeared).
The implementation through the cursor is pretty trivial. First you need to create a temporary table and fill it with dates and values from the main:
create table #temp (dt date primary key, val int null, total int null ); insert #temp (dt, val) select dt, val from test_simple order by dt;
Then we set the local variables through which the update will take place:
declare @VarTotal int, @VarDT date, @VarVal int; set @VarTotal = 0;
After that we update the temporary table through the cursor:
declare cur cursor local static read_only forward_only for select dt, val from #temp order by dt; open cur; fetch cur into @VarDT, @VarVal; while @@fetch_status = 0 begin set @VarTotal = @VarTotal + @VarVal; update #temp set total = @VarTotal where dt = @VarDT; fetch cur into @VarDT, @VarVal; end; close cur; deallocate cur;
And finally, we get the desired result:
select dt, val, total from #temp order by dt; drop table #temp;
10. Update through a local variable (SQL Server)
Updating through a local variable in SQL Server is based on undocumented behavior, so it cannot be considered reliable. Nevertheless, this is perhaps the fastest solution, and this is interesting.
Let's create two variables: one for cumulative totals and a table variable:
declare @VarTotal int = 0; declare @tv table (dt date null, val int null, total int null );
First, fill
@tv
data from the main table
insert @tv (dt, val, total) select dt, val, 0 as total from test_simple order by dt;
Then
@tv
update the table variable
@tv
using
@VarTotal
:
update @tv set @VarTotal = total = @VarTotal + val from @tv;
... after which we get the final result:
select * from @tv order by dt;
Summary: We reviewed the top 10 ways to calculate cumulative totals in SQL. As you can see, even without window functions, this problem is completely solvable, and the solution mechanics cannot be called complex.