On October 26, Linz am Rhein (Germany) hosted the HaxeUp Sessions 2019 mini-conference dedicated to Haxe and related technologies. And its most significant event was, of course, the final release of Haxe 4.0.0 (at the time of publication, that is, after about a week, update 4.0.1 was released ). In this article, I would like to present you a translation of the first report of the conference - a report on the work done by the Haxe team for 2019.

A little about the author of the report:
Simon has been working with Haxe since 2010, when he was still a student and wrote a work on fluid simulations in Flash. The implementation of such a simulation required constant access to data describing the state of the particles (at each step more than 100 queries were made to the data arrays about the state of each cell in the simulation), while working with arrays in ActionScript 3 is not so fast. Therefore, the initial implementation was simply inoperative and needed to find a solution to this problem. In his search, Simon came across an article by Nicolas Kannass (creator of Haxe) on the then undocumented Alchemy opcodes that were not available using ActionScript, but Haxe allowed them to be used. By rewriting the simulation on Haxe using the opcodes, Simon got a working simulation! And so, thanks to slow arrays in ActionScript, Simon learned about Haxe.
Since 2011, Simon joined the development of Haxe, he began to study OCaml (which is written on the compiler) and make various corrections to the compiler.
And since 2012, he became the main compiler developer. In the same year, the Haxe Foundation was created (an organization whose main goals are to develop and maintain the Haxe ecosystem, help the community organize conferences, and provide consulting services), and Simon became one of its co-founders.

In 2014-2015, Simon invited Josephine Pertosa to the Haxe Foundation, which over time became responsible for organizing conferences and community relations.
In 2016, Simon made his first presentation on Haxe , and in 2018 organized the first HaxeUp Sessions .

So what happened in the Haxe world over the past 2019?
In February and March, 2 release candidates came out (4.0.0-rc1 and 4.0.0-rc2)
In April, Aurel Bili (as an intern) and Alexander Kuzmenko (as a compiler developer) joined the Haxe Foundation team.
In May, the Haxe US Summit 2019 was held .
In June, Haxe 4.0.0-rc3 was released. And in September - Haxe 4.0.0-rc4 and Haxe 4.0.0-rc5.

Haxe is not only a compiler, but also a whole set of various tools, and throughout the year work on them was also constantly conducted:
Thanks to the efforts of Andy Lee, Haxe now uses Azure Pipelines instead of Travis CI and AppVeyor. This means that assembly and automated tests are now much faster.
Hugh Sanderson continues to work on hxcpp (a library for supporting C ++ in Haxe).
Suddenly, users of Github terurou and takashiski joined the work on externs for Node.js.
Rudy Ges worked on fixes and improvements to support the C # target.
George Corney continues to support the HTML extern generator.
Jens Fisher is working on vshaxe (an extension for VS Code for working with Haxe) and on many other Haxe related projects.

And the main event of the year, of course, was the long-awaited release of Haxe 4.0.0 (as well as neko 2.3.0), which accidentally coincided with the HaxeUp 2019 Linz :)

Simon devoted the bulk of the report to new features in Haxe 4.0.0 (you can also learn about them from the report of Alexander Kuzmenko from the last Haxe US Summit 2019).

The new eval macro interpreter is several times faster than the old. Simon talked about him in detail in his speech at the Haxe Summit EU 2017 . But since then it has improved the debugging capabilities of the code, fixed many bugs, redesigned the implementation of strings.
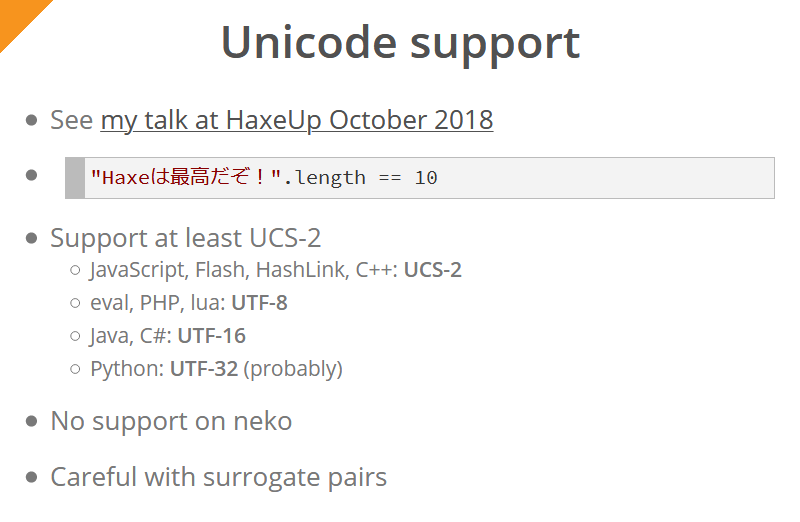
Haxe 4 introduces Unicode support for all platforms (except Neko). Simon described this in detail in his last year’s speech . For the end user of the compiler, this means that the expression "Haxeは最高だぞ!".length
for all platforms will always return 10
(again, except for Neko).
The UCS-2 encoding is minimally supported (a natively supported encoding is used for each platform / language; trying to support the same encoding everywhere would be impractical):
- JavaScript, Flash, HashLink and C ++ use UCS-2 encoding
- for eval, PHP, lua - UTF-8
- for Java and C # - UTF-16
- for Python - UTF-32
All characters that are outside the main multilingual plane (including emoji) are represented as “surrogate pairs” - such characters are represented by two bytes. For example, if in Java / C # / JavaScript (that is, for strings in UTF-16 and UCS-2 encodings) to request the length of a string consisting of one emoji, the result will be “2”. This fact must be taken into account when working with such strings on these platforms.
Haxe 4 introduces a new kind of iterator - key-value:

It works with Map
containers (dictionaries) and strings (using the StringTools class), support for arrays has not yet been implemented. It is also possible to implement such an iterator for custom classes, for this it is enough to implement the keyValueIterator():KeyValueIterator<K, V>
method for them keyValueIterator():KeyValueIterator<K, V>
.
The new meta tag @:using
allows you to associate static extensions with types at the place of their declaration.
In the example on the slide below, the MyOption
enumeration MyOption
associated with MyOptionTools
, so we statically expand this enumeration (which is impossible in the usual situation) and get the opportunity to call the get()
method, referring to it as an object method.

In this example, the get()
method is inline, which also allows the compiler to further optimize the code: instead of calling the MyOptionTools.get(myOption)
method, the compiler will substitute the stored value, i.e. 12
.
If the method is not declared as embeddable, then another optimization tool available to the programmer is to embed functions at the place of their call (call-site inlining). To do this, when calling the function, you must additionally use the inline
:

Thanks to the work of Daniil Korostelev , Haxe now has the opportunity to generate ES6 classes for JavaScript. All you need to do is just add the compilation flag -D js-es=6
.
Currently, the compiler generates one js file for the entire project (it may be possible in the future to generate separate js files for each of the classes, but so far this can only be done using additional tools ).

For abstract enumerations, values are now automatically generated.
In Haxe 3, it was necessary to manually set values for each constructor. In Haxe 4, abstract enumerations created on top of Int
behave according to the same rules as in C. The abstract enumerations created on top of strings behave similarly - for them, the generated values will coincide with the names of the constructors.

Some syntax improvements should also be mentioned:
- abstract enumerations and extern functions have become full-fledged members of Haxe and now you do not need to use
@:enum
and@:extern
meta tags to declare them - 4th Haxe uses a new type intersection syntax that better reflects the essence of expanding structures. Such constructions are most useful when declaring data structures: the expression
typedef T = A & B
means that the structureT
has all the fields that are in typesA
andB
- similarly, the four declare type parameter constraints: the entry
<T:A & B>
indicates that the type of parameterT
must be bothA
andB
- the old syntax will work (except for the syntax for type restrictions, because it will conflict with the new syntax for describing function types)

The new syntax for describing function types (function type syntax) is more logical: the use of parentheses around the types of function arguments is visually easier to read. In addition, the new syntax allows you to define argument names, which can be used as part of the documentation for the code (although it does not affect the typing itself).

The old syntax continues to be supported and is not declared obsolete, because otherwise, it would require too many changes in the existing code (Simon himself constantly finds himself out of habit using the old syntax).
Haxe 4 finally has arrow functions (or lambda expressions)!

Features of arrow functions in Haxe are:
- implicit
return
. If the body of a function consists of a single expression, then this function implicitly returns the value of this expression - it is possible to set the types of arguments to the function, because the compiler cannot always determine the required type (e.g.
Float
orInt
) - if the body of the function consists of several expressions, then you need to surround it with curly braces
- but there is no way to explicitly set the return type of the function
In general, the syntax of arrow functions is very similar to that used in Java 8 (although it works somewhat differently).
And since we mentioned Java, it should be said that in Haxe 4 it was possible to generate JVM bytecode directly. To do this, when compiling the project under Java, just add the -D jvm
flag.
Generating a JVM bytecode means that there is no need to use a Java compiler, and the compilation process is much faster.

So far, the JVM target has experimental status for the following reasons:
- in some cases, the bytecode is slightly slower than the result of translating Haxe into Java and then compiling with javac. But the compiler team is aware of the problem and knows how to fix it, it just requires additional work.
- there are problems with MethodHandle on Android, which also requires additional work (Simon will be glad if he is helped in solving these problems).

A general comparison of generating bytecode directly (genjvm) and compiling Haxe into Java code, which is then compiled into bytecode (genjava):
- as already mentioned, in terms of compilation speed, genjvm is faster than genjava
in terms of execution speed bytecode genjvm is still inferior to genjava - there are some problems when using type parameters and genjava
- genJvm uses MethodHandle to refer to functions, and genjava uses the so-called “Waneck functions” (in honor of Kaui Vanek , thanks to which Java and C # support appeared in Haxe). Although the code obtained using Waneck-functions does not look beautiful, it works and works quite quickly.
General tips for working with Java in Haxe:
- Due to the fact that the garbage collector in Java is fast, problems associated with it are rare. Of course, constantly creating new objects is not a good idea, but Java does a good job of managing memory and the need to constantly take care of allocations is not as acute as on some other platforms supported by Haxe (for example, in HashLink)
- accessing class fields in a jvm target can work very slowly in the case when this is done through a structure (
typedef
) - while the compiler cannot optimize such code - excessive use of the
inline
keyword should be avoided - the JIT compiler does a good job - Avoid using
Null<T>
, especially when dealing with complex mathematical calculations. Otherwise, a lot of conditional statements will appear in the generated code, which will negatively affect the speed of your code.
The new Haxe 4 feature, Null safety, can help avoid using Null<T>
. Alexander Kuzmenko spoke in detail about her at last year's HaxeUp .

In the example on the slide above, the static safe()
method has the Strict mode for checking for Null security enabled, and this method has an optional arg
parameter, which can have a null value. In order for this function to compile successfully, the programmer will need to add a check of the arg
argument value (otherwise, the compiler will display a message about the impossibility of calling the charAt()
method on a potentially null object).
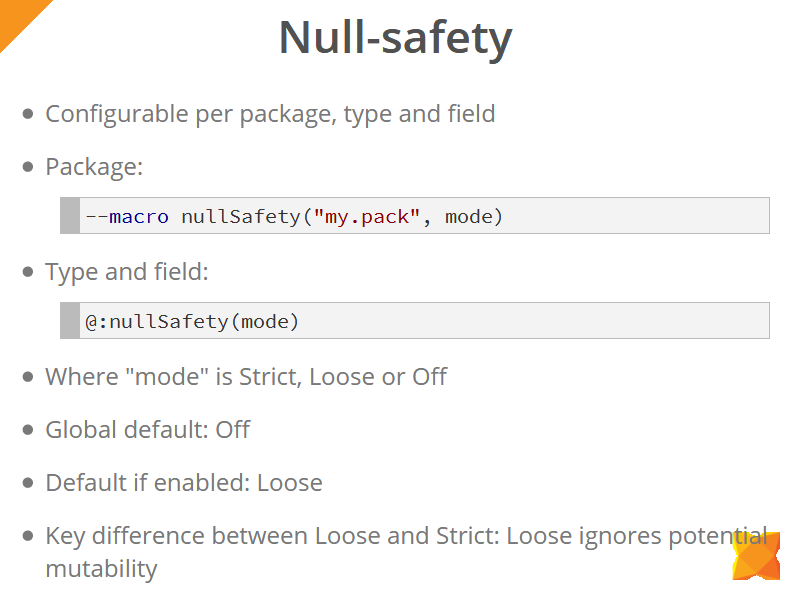
Null security can be configured both at the package level (using a macro) and types and individual fields of objects (using the @:nullSafety
meta tag).
The modes in which Null Security checks work are: Strict, Loose, and Off. Globally, these checks are disabled (Off-mode). When they are turned on, the Loose mode is used by default (unless you explicitly specify the mode). The key difference between Loose and Strict modes is that the Loose mode ignores the possibility of changing values between operations of accessing these values. In the example on the slide below, we see that a null
check has been added for the variable x
. However, in Strict mode, this code does not compile, because before working directly with the variable x
, the sideEffect()
method is sideEffect()
, which can potentially nullify the value of this variable, so you will need to add another check or copy the value of the variable to a local variable, which we will continue to work with.

Haxe 4 introduces a new final
keyword, which has a different meaning depending on the context:
- if you use it instead of the
var
keyword, then the field declared in this way cannot be assigned a new value. You can only set it directly when declaring (for static fields) or in the constructor (for non-static fields) - if you use it when declaring a class, it will prohibit inheritance from it
- if you use it as a modifier for accessing the property of an object, then this prohibits the redefinition of getter / setter in the heir classes.

Theoretically, the compiler, having met the final
keyword, can try to optimize the code, assuming that the value of this field does not change. But for now, this possibility is only being considered and is not implemented in the compiler.

And a little about the future of Haxe:
- currently working on asynchronous I / O API
Coroutine support is planned, but so far, work on them is stuck at the planning stage. Perhaps they will appear in Haxe 4.1, and perhaps later. - tail-call optimization will appear in the compiler
- and possibly the functions available at the module level . Although the priority of this feature is constantly changing