Agree on terminology
A robot does not have to be either large, humanoid, or in principle material (to the peak of Wikipedia , which, however, after a couple of paragraphs softens the initial wording and allows the robot to be immaterial). A robot is an automaton in the algorithmic sense, an automaton for autonomous (algorithmic) solution of some problems. The light detector that turns on the evening lights is a robot. Parsing emails to "external" and "internal" mail client - too.
Artificial intelligence (in the narrowly applied sense, Wikipedia does not share it again) are algorithms for extracting dependencies from data. It will not solve any problems by itself, for this it must first be implemented in the form of specific analytical processes (input data, models, output data, process control). The analytical process acting as a “carrier of artificial intelligence" can be started by a person, can be started by a robot. And stopped too, either one or the other. And manage too.
Interaction with the environment
Artificial intelligence needs data, moreover, in a form suitable for analysis. When the analyst begins to develop the analytical process, the data is prepared for the model by the analyst himself. As a rule, a data set sufficient in volume and scope (“dataset”) is created, on which the model is trained and tested. Having received a result that is satisfactory in accuracy (and, in more rare cases, “locally stable” in time), a typical analyst considers his work done. And in fact? In fact, this is only half the battle. Now it is necessary to ensure the “uninterrupted and efficient operation” of the analytical process - and the analyst may have difficulties with this.
The tools used to develop mechanisms of artificial intelligence and machine learning, except in the simplest cases, are not suitable for productive interaction with the external environment. Those. It’s probably possible to force, for example, Python to read and transform data from sensors in the production process (at least for a short time). But switching between several production and management processes, depending on the situation, scaling the corresponding computing power, handling all kinds of “exceptions” (inaccessibility of one of the data sources, infrastructure failure, user interaction problems, etc.) - this is not intended for Python . This requires a data management and integration platform. And the more loaded, the more varied our analytical process will be, the higher will be the bar of requirements for integration and “sub-echelon” solution components. The analyst, gravitating towards AI mechanisms, trying to implement the analytical process through the scripting language of his familiar modeling environment (and utilities developed “for him”, such as “laptops”), is faced with the inability to provide his analytical process with full productive use.
Adaptability and adaptability
Variability of the environment manifests itself in different ways. In some cases, the essence and nature of the phenomena controlled by artificial intelligence will change (entering an enterprise into new areas of business, requirements of national and international regulators, evolution of consumer preferences of enterprise products, etc.). In others, the nature of the data coming from the environment (new equipment with new sensors, more efficient data transmission channels, the availability of new technologies for “marking” data, etc.).
Can the analytical process "rebuild itself" when changing the structure of the environment? To simplify the question: how easy is it to rebuild the analytical process when changing the structure of the environment? From our observations, the answer is simple and sad: in most implementations (not ours!) Known to us, we will have to rewrite at least the analytical process - and often the AI contained in it. It may not be literally from “entry to exit” to rewrite, but you will have to add something to the programming to process new realities, change the internal logic of the “model-applying process” itself, etc. And this can result in a prohibitively expensive business - especially if the environment changes dynamically.
Agency: the limit of autonomy?
As the reader has probably already noticed, we are moving towards an increase in the complexity of reality offered to the attention of artificial intelligence. And we mark possible consequences for the “instrumental part”. In the hope that in the end we can find the answer to all the challenges that arise.
We came close to the need to provide the analytical process with such a degree of autonomy at which it would be able to cope not only with the variability of the environment, but also with the uncertainty of its state. This is not about the quantum nature of the environment (although we will talk about this in one of the following publications), we are only talking about the probability of getting the state expected by the analytical process at the time it expects and in the expected “volume”. For example: the process “thought” that it would manage with the next training of the model until new data for the application of the model arrived, but did not “manage” (for objective reasons, more records entered the training set than usual, and the model training was delayed). Or else: the markup group added a new press to the process, the vectorization model has already been trained on new textual material, and the neural network is still working on the old vectorization and sends extremely interesting new information to the "scrap". To cope with such situations, as our practice shows, you can only divide the previously unified analytical process into several autonomously working components and create your own “buffer projection” of the environment for each received agent process. This action (goodbye, Wikipedia) will be called agentization of the analytical process. And the quality communicated by agency to the analytical process (as a rule, to the whole system consisting of several processes at once) is called agency.
We set the task for the robot
Let's try to come up with such a problem, for the solution of which a robotic AI with all of the above properties would be required. We don’t have to go far for the idea, since many interesting cases and solutions to them have been published on the Internet - we will use one of these “case-solutions” (both for the statement of the problem and for the solution in terms of artificial intelligence). Our chosen task will be reduced to the classification of statements on the social network Twitter (“tweets”) into “negative” and “positive” in terms of their emotional coloring. To train the models, we will have large enough samples of “marked out” tweets (that is, with an already defined emotional coloring), and we will need to classify the tweets “unmarked” (i.e. with an undefined emotional coloring):

Figure 1 Statement of the problem for the classification of texts by emotional coloring (English sentiment analysis)
The approach to creating mathematical models capable of learning from marked-up texts and subsequently classifying texts with an indefinite emotional coloring is formulated in a fairly well-known example published on the Internet by S. Smetanin.
Data for the tasks of this class are kindly collected, processed and published by Yu. Rubtsova.
And on this we could begin to “assemble the robot” - but we will complicate the classic statement a little with one condition: both marked-up data and unallocated data are provided to the analytical process in the form of standard-size files as the process “consumes” the files already provided. Thus, our robot will need to start working on the minimum volumes of training data, constantly increasing the classification accuracy by repeating model training on increasing volumes of training data.
We go to the workshop InterSystems
Let us show by the example of the task just formulated by us how to robotize artificial intelligence using the InterSystems IRIS platform and a set of extensions to it called ML Toolkit. At the same time, ensuring that the analytical processes we create are able to interact productively with the environment, are adaptable, adaptive, and agent (“three A”).
Let's start with the agency. Let's place four business processes in the platform:

Figure 2 Configuration of a business process agent system with a component for interacting with Python
- GENERATOR ("generator") - as the files are consumed by other processes, it creates new files with input data (marked - "positive" and "negative" - tweets, and tweets with an indefinite emotional coloring)
- BUFFER (“buffer”) - as other processes consume records, reads new records from files created by the generator, and deletes these files after reading records
- ANALYZER (“analyzer”) - consuming entries from the buffer of indefinite tweets, applies a trained convolutional neural network to these records and places the resulting records with the calculated “probability of positive” in the monitor buffer; consuming entries from buffers of positive and negative tweets, performs neural network training
- MONITOR (“monitor”) - while consuming the records processed by the analyzer from its own buffer, it monitors the values of the tweet classification error metrics by the neural network during the last training and sends a signal to the analyzer about the need for new training of the neural network
You can schematically represent our agent system of business processes as follows:

Figure 3 Data flow within the agent system
All processes within our system operate independently of each other, but taking into account the signals of each other. For example, a signal to the beginning of the formation of the next file with records by the process-generator is the deletion of the previous file with records by the buffer.
Now about adaptability. The adaptability of the analytical process in our example is implemented through the "encapsulation" of the AI in the form of an element independent of the logic of the carrier process, with the isolation of its main functions - training and application of models:

Figure 4 Isolation in the analytical process-analyzer of the main functions of AI - training and scoring of mathematical models
Because the fragment of the analyzer process presented above is part of the “endless cycle” (which starts when the analyzer process starts and runs until the entire agent system stops), and the AI functions are executed in parallel, the process has the ability to adapt the AI operation to the situation: train models when necessary , and non-stop to use the version of models at his disposal. The need for training models is determined by an adaptive monitor process that works independently of the analyzer process and uses its own criteria to assess the accuracy of models trained by the analyzer:
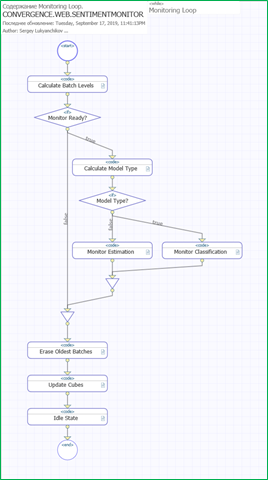
Figure 5 Recognition by the process monitor of the type of model and application of appropriate criteria for evaluating the accuracy of models
We turn to adaptability. The analytic process in InterSystems IRIS is a business process that has a graphical or XML representation as a sequence of steps. Steps can, in turn, be sequences of steps, cycles, condition tests, and other process controls. Steps can run program code for execution or transfer information (which can also be program code) for execution to other processes or external environments.
In particular, if it is necessary to change the analytical process, we have the opportunity to do this both in the graphical editor and in the IDE. Changing the analytical process in a graphical editor allows you to adapt the logic of the process without programming:

Figure 6 Process analyzer in a graphical editor with an open menu for adding controls
And finally, interaction with the environment. The most important component of the environment, in our case, will be the Python mathematical modeling environment. To ensure interaction with the Python and R environments, the corresponding functional extensions were created: Python Gateway and R Gateway . A key functional of both mechanisms is the ability to interact with the appropriate environment using convenient integration components. We have already seen the component for interacting with Python in the configuration of our agent system. In this way, business processes that contain AI implemented in Python interact with Python.
For example, the analyzer process contains functions for training and applying models, the implementation of one of which in Python in the InterSystems IRIS platform looks like this:

Figure 7 Implementation in Python of the InterSystems IRIS platform the learning function of models in the analyzer process
Each of the steps in this process is responsible for processing a specific interaction with Python: transferring input from the context of the InterSystems IRIS process to the Python context, passing code to execute in Python, returning the output from the Python context to the context of the InterSystems IRIS process.
The most commonly used type of interaction in our example is passing code to execute in Python:

Figure 8 Python code hosted in an InterSystems IRIS parser process is sent to Python for execution
In some interactions, data is returned from the Python context to the InterSystems IRIS process context:

Figure 9 Visual trace of the analyzer process session with viewing the information returned by Python in one of the process steps
We start the robot
Run the robot right in this article? Why not, here is the record of our webinar, during which (in addition to a number of other interesting and related to the robotization of AI stories!) Work of the above scenario is shown. Since the time of the webinar, unfortunately, is limited - and we want to show the “useful work” of our robotic script as compactly and visually as possible — we have placed below a more complete overview of the results of model training (7 consecutive training cycles instead of 3 in the webinar):

The results are quite consistent with intuitive expectations: as the training sample fills with “marked up” positive and negative tweets, the quality of our classification model improves (this is evidenced by the increasing “area under the curve”, the same AUC - Area Under Curve).
What conclusions I would like to make at the end of the article:
- InterSystems IRIS is a powerful AI platform for robotic processes
- Artificial intelligence can be implemented both in external environments (for example, Python and R with their modules containing ready-to-use algorithms), and in the InterSystems IRIS platform itself (using built-in library of algorithms or by writing algorithms in Python or R) - InterSystems IRIS provides interaction with external AI environments, allowing you to combine their capabilities with their own functionality
- InterSystems IRIS robots AI using "three A": adaptable, adaptive and agent business processes (they are also analytical processes)
- InterSystems IRIS works with external AI (Python, R) through sets of specialized interactions: data transfer / return, code transfer for execution, etc. Within the framework of one analytical process, interactions with several mathematical modeling environments can be carried out.
- InterSystems IRIS consolidates model input and output data in a single platform, historicizes and versions calculations
- Thanks to InterSystems IRIS, artificial intelligence can be used both in specialized analytical mechanisms and embedded in OLTP or integration solutions.
For those who read the article and are interested in the capabilities of InterSystems IRIS as a platform for developing or deploying artificial intelligence and machine learning mechanisms, we suggest discussing possible scenarios of interest to your enterprise. We will readily analyze the needs of your enterprise and jointly determine an action plan; The contact email for our AI / ML team is MLToolkit@intersystems.com .