
Recent advances in deep learning bring significant improvements to the development of speech synthesis systems (hereinafter - TTS). This is due to the use of more effective and faster methods of studying the voice and style of speakers, as well as due to the synthesis of more natural and high-quality speech.
However, to achieve this, most TTS systems must use large and complex neural network models that are difficult to train and that do not allow real-time speech synthesis, even with GPUs.
To solve these problems, our IBM Research AI team has developed a new method of neural network synthesis based on a modular architecture. This method combines three deep neural networks (hereinafter referred to as DNN) with intermediate processing of their output signals. We presented this work in our article “High-Quality, Lightweight, and Adaptable TTS Technology Using LPCNet” at Interspeech 2019. The TTS architecture is lightweight and can synthesize high-quality speech in real time. Each network specializes in different aspects of the speaker’s voice, which allows you to effectively train any of the components independently of the others.
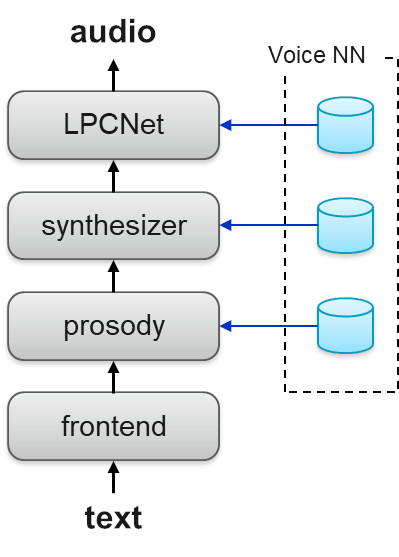
Diagram 1. TTS System Architecture
Another advantage of our approach is that after training the core networks, they can be easily adapted to a new style of speech or voice even on small volumes of training data, for example, for branding and customization purposes.
The synthesis process uses an interface module for a specific language, which converts the input text into a sequence of linguistic features. Then the following DNNs are applied one after another:
1. Prediction of prosody
Prosodic features of speech are presented as a four-dimensional vector per TTS unit (approximately one third of the sound conditions according to SMM (hidden Markov model)), which includes log-duration, initial and final log-pitch, as well as log-energy. These features are determined during the training process, so they can be predicted by the features of the text received by the interface during the synthesis. Prosody is extremely important not only for speech to sound natural and lively, but also for the data intended for training or adaptation to have the most complete reflection of the speaker’s speech style. Adaptation of prosody to the announcer's voice is based on the Variational Auto Encoder (VAE).
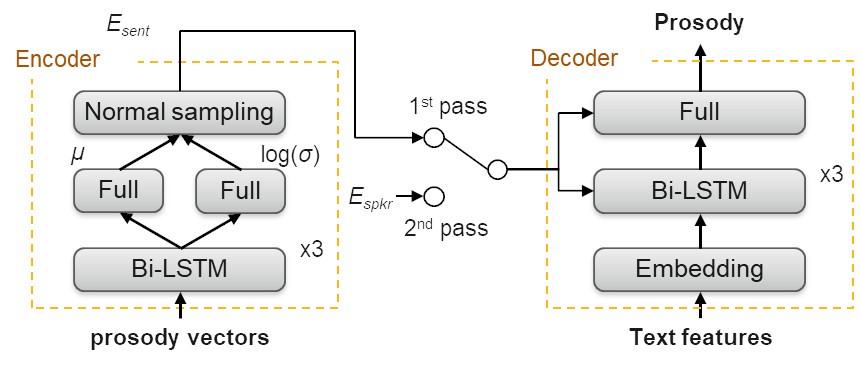
Scheme 2. Training and retraining of the prosody generator
2. Prediction of acoustic features
Acoustic feature vectors provide a spectral representation of speech in short 10-millisecond frames from which actual sound can be generated. Acoustic features are determined in the learning process, and they can be predicted by phonetic labels and prosody during the synthesis.
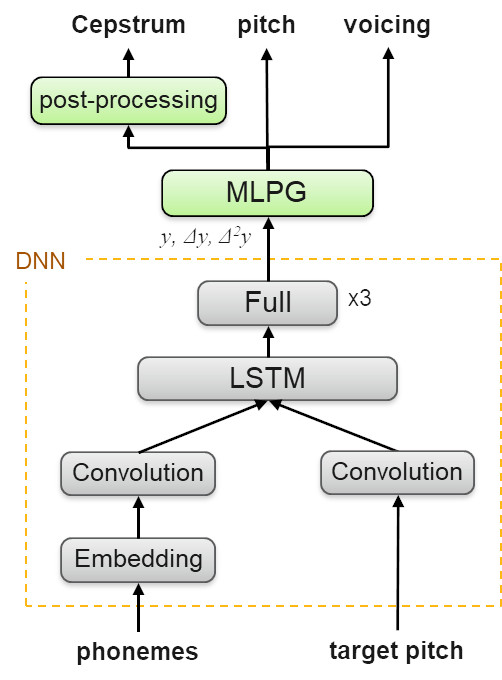
Scheme 3. Network synthesizer
The created DNN model is the audio data (voice announcer) necessary for training or adaptation. The architecture of the model consists of convolutional and recurrent layers designed to extract the local context and time dependencies in the sequence of sounds and tone structure. DNN predicts acoustic features from their first and second derivative. This is followed by the maximum likelihood method and formant filters are applied that help to generate better-sounding speech.
3. Neural vocoder
A neural vocoder is responsible for generating speech from acoustic features. He learns from the speaker’s natural speech patterns, given their respective characteristics. Technically, we were the first to use a new, lightweight, high-quality neural vocoder called LPCNet in a fully commercialized TTS system.
The novelty of this vocoder is that it does not try to predict a complex speech signal directly using DNN. Instead, the DNN only predicts a less complex residual voice path signal, and then uses Linear Predictive Coding (LPC) filters to convert it to the final speech signal.
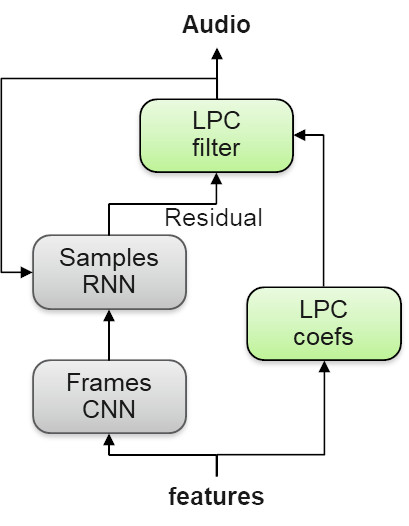
Scheme 4. Neural vocoder LPCNet
Voice adaptation
Adaptation to voice is easily achieved by retraining three networks based on a small amount of audio data from the target speaker. In our article, we present the results of adaptation experiments in terms of speech quality and its similarity to the true speaker’s speech. This page also provides examples of adaptation to eight different VCTK (Voice Cloning Toolkit) speakers, of which 4 are men and 4 are women.
Listening Results
The figure below shows the results of listening tests of synthesized and natural speech patterns of VCTK speakers. Mean Opinion Score (MOS) values are based on listeners' analysis of speech quality on a scale of 1 to 5. The similarity between pairs of samples was assessed by students on a scale of 1 to 4.
We measured the quality of synthesized speech, as well as its similarity to the speech of “live” speakers, comparing the female and male adapted voices lasting 5, 10 and 20 minutes with the natural speech of the speakers.
Test results show that we can maintain both high quality and high similarity to the original even for voices that have been trained on five-minute examples.
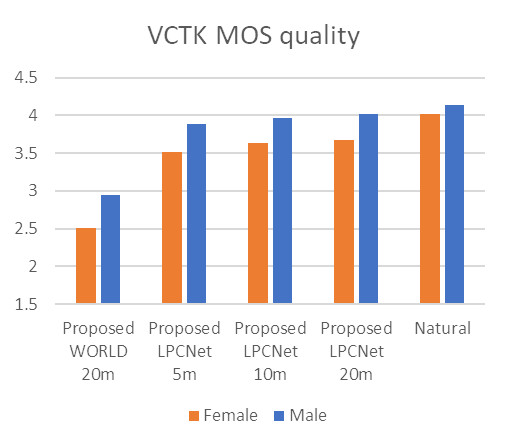
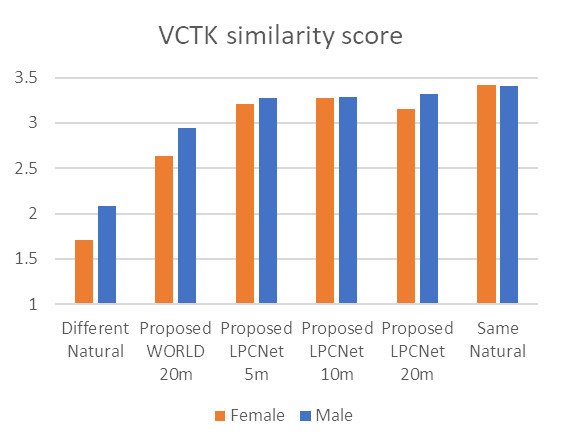
Diagram 5. Results of tests for quality and similarity
This work was carried out by IBM Watson and served as the basis for a new release of the IBM Watson TTS service with improved voice quality (see "* V3" voices in the IBM Watson TTS demo).