How servers negotiate with each other: Raft distributed consensus algorithm
When clusters reach hundreds, and sometimes thousands, of machines, the question arises of the consistency of server states relative to each other. The Raft Distributed Consensus Algorithm provides the most stringent consistency guarantee possible. In this article, we will consider Raft from the point of view of an engineer and try to answer the questions “How?” And “Why?” It works.

Raft is a distributed consensus algorithm that is needed so that several participants can jointly decide whether an event occurred or not, and what followed.
The data served by the Raft cluster is a log consisting of records. When the user wants to change the data stored in the cluster, he tries to add a new record to the log with the command:
These commands are executed by distributed state machines. For simplicity and clarity, in the framework of this article, we will assume that these records are simply given when reading to a client who, based on the events that have taken place, restores the current state of the system (see Event sourcing) .
To ensure consensus in Raft, a leader is first selected on whom responsibility for managing the distributed log will be laid. The leader accepts requests from clients and replicates them to other servers in the cluster. If the leader fails, a new leader will be selected in the cluster. This is if in a short sentence in three sentences. Details will follow.
Raft relies on heartbeat to determine when it is time to start a new election. The follower remains the follower as long as he receives messages from the current leader or candidate. The leader periodically sends all other heartbeat servers.
If the follower does not receive any messages for a while, he will quite naturally assume that the leader is dead, which means it's time to take the initiative in his hands. At this point, the former follower initiates the election.
To initiate the election, the follower increments its term number, switches to the “candidate” state, votes for itself, and then sends the “RequestVote” request to all other servers. After that, the candidate waits for one of three events:
When a leader is selected, he is responsible for managing the distributed log. The leader accepts requests from clients containing some teams. The leader puts in his log a new record containing the command, and then sends "AppendEntries" to all followers in order to replicate the record with the new record.
When the record is successfully replicated on most servers, the leader begins to consider the record closed and responds to the client. The leader keeps track of which record is the last. He sends the number of this record to AppendEntries (including heartbeat) so that followers can commit the record to themselves.
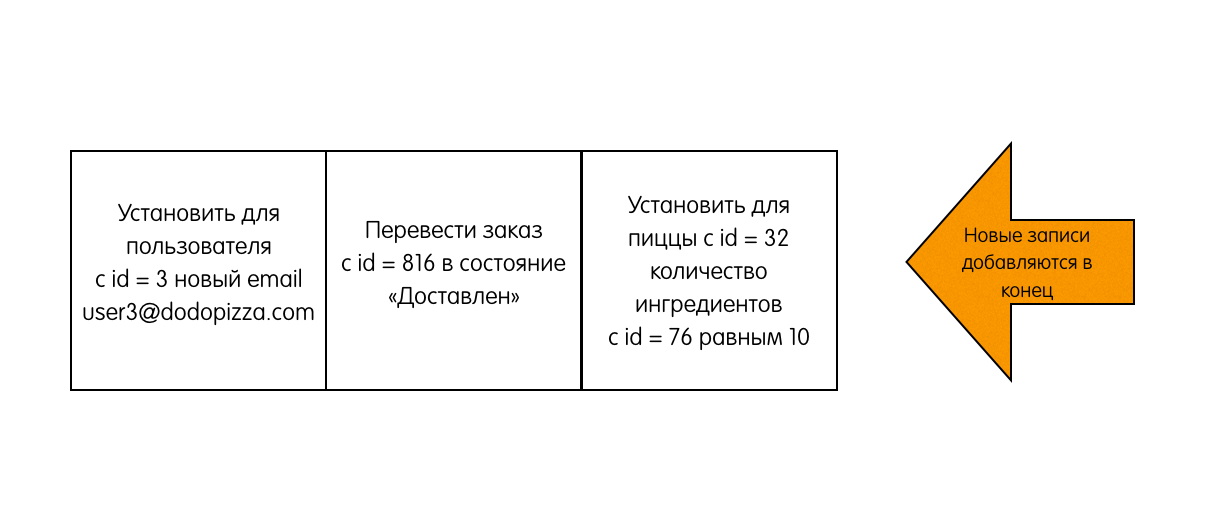
In case the leader cannot reach out to some followers, he will retrace the AppendEntries to infinity. The following picture shows how the logs are organized in the Raft cluster:

Each box is one entry in the log. Each record stores one command, for example, x ← 3 assign the value 3 to the key x. The record also stores the number of the term in which it was generated. In the picture, this is indicated by a number at the top of the square. The color indication of the squares also means the term number. Each record has a serial number (log index).
So far, from what we have examined, it is not clear how Raft can give at least some guarantees. However, the algorithm provides a set of properties that together guarantee the reliability of its execution:
Article author: Dmitry Pavlushin (developer Dodo Pizza Engineering).
Raft is a distributed consensus algorithm that is needed so that several participants can jointly decide whether an event occurred or not, and what followed.
The data served by the Raft cluster is a log consisting of records. When the user wants to change the data stored in the cluster, he tries to add a new record to the log with the command:
These commands are executed by distributed state machines. For simplicity and clarity, in the framework of this article, we will assume that these records are simply given when reading to a client who, based on the events that have taken place, restores the current state of the system (see Event sourcing) .
To ensure consensus in Raft, a leader is first selected on whom responsibility for managing the distributed log will be laid. The leader accepts requests from clients and replicates them to other servers in the cluster. If the leader fails, a new leader will be selected in the cluster. This is if in a short sentence in three sentences. Details will follow.
Basic concepts
- Server states In the Raft cluster, each server at any given time is in one of three states:
- Leader (leader) - processes all client requests, is the source of truth of all data in the log, supports the follower log.
- Follower (follower) is a passive server that only “listens” to new log entries from the leader and redirects all incoming requests from clients to the leader. In fact, it is a hot-standby replica of the leader.
- Candidate (candidate) is a special state of the server, possible only during the selection of a new leader.
During normal operation in a cluster, only one server is the leader, all the rest are its followers.
About asynchronismIt is worth noting here that condition is a relative concept. Due to the fact that the servers communicate asynchronously, different servers can observe the transitions of other servers from one state to another at different times.
- Raft divides time into segments of arbitrary length, called deadlines . Each term has a monotonically increasing number. The term begins with the election of a leader when one or more servers become candidates. If the candidate receives the majority of votes, he becomes a leader until the end of this period. If the votes are divided, and none of the candidates can get the majority of the votes, a timeout is triggered, and this period ends. After this, a new term begins with new candidates and elections. This situation is called split vote. An example is illustrated by term number three in the following diagram:

The term number serves as the logical timestamp in the Raft cluster. It helps servers determine which information is more relevant at the moment.
Server interaction rules and terms- Each server tracks the number of its current term.
- The server includes its expiration number in each sent message.
- If the server receives a message with a lesser term number than its own, then it ignores this message.
- If the server receives a message with a longer deadline number than its own, then it updates its deadline number to match the received one.
- If a candidate or leader receives a message with a longer deadline number than his own, then he understands that other servers have already initiated a new deadline, and his deadline is no longer relevant. Therefore, it goes from the current state to the “follower” state in addition to updating its number.
- Server Communication The servers in Raft interact by exchanging requests and responses. The basic algorithm uses only two types of calls:
- RequestVote is used by candidates during the election. The request contains the candidate’s term number and metadata about the candidate’s log, discussed in more detail below. The response contains the term number of the responding server and the value “true” if the server votes for the candidate; False if the server votes against the candidate.
- AppendEntries is used by the leader for log replication, as well as for the heartbeat mechanism. The request contains the leader’s term number, a collection of records that need to be added to the log (or an empty collection in the case of heartbeat), some metadata about the leader’s log, also discussed in more detail below. The response contains the follower term number and the value “true” if the follower successfully added entries to his log; “False” if adding entries to the log failed.
Work algorithm
1. Choose a leader
Raft relies on heartbeat to determine when it is time to start a new election. The follower remains the follower as long as he receives messages from the current leader or candidate. The leader periodically sends all other heartbeat servers.
If the follower does not receive any messages for a while, he will quite naturally assume that the leader is dead, which means it's time to take the initiative in his hands. At this point, the former follower initiates the election.
To initiate the election, the follower increments its term number, switches to the “candidate” state, votes for itself, and then sends the “RequestVote” request to all other servers. After that, the candidate waits for one of three events:
- The candidate receives the majority of votes (including his own) and wins the election. Each server votes only once in each term, for the first candidate to be reached (with some exceptions, discussed below), therefore, only one candidate can get the majority of votes in a specific term. The winning server becomes the leader, starts sending heartbeat and serving client requests to the cluster.
- The candidate receives a message from the current leader of the current term or from any server with an older term . In this case, the candidate understands that the elections in which he runs are no longer relevant. He has no choice but to recognize a new leader / new term and go into a state of follower.
- A candidate does not receive a majority of the votes for a certain timeout. This can happen when several followers become candidates, and the votes are divided among them so that not one gets the majority. In this case, the term ends without a leader, and the candidate immediately begins new elections for the next term.
2. We replicate logs
When a leader is selected, he is responsible for managing the distributed log. The leader accepts requests from clients containing some teams. The leader puts in his log a new record containing the command, and then sends "AppendEntries" to all followers in order to replicate the record with the new record.
When the record is successfully replicated on most servers, the leader begins to consider the record closed and responds to the client. The leader keeps track of which record is the last. He sends the number of this record to AppendEntries (including heartbeat) so that followers can commit the record to themselves.
In case the leader cannot reach out to some followers, he will retrace the AppendEntries to infinity. The following picture shows how the logs are organized in the Raft cluster:
Each box is one entry in the log. Each record stores one command, for example, x ← 3 assign the value 3 to the key x. The record also stores the number of the term in which it was generated. In the picture, this is indicated by a number at the top of the square. The color indication of the squares also means the term number. Each record has a serial number (log index).
3. We guarantee the reliability of the algorithm
So far, from what we have examined, it is not clear how Raft can give at least some guarantees. However, the algorithm provides a set of properties that together guarantee the reliability of its execution:
- Election Safety : no more than one leader can be selected within a single term. This property follows from the fact that each server votes within each term only once, and for the formation of a leader, a majority of votes is required
- Leader Append-Only : the leader never overwrites or erases, does not move entries in his log, only adds new entries. This property follows directly from the description of the algorithm - the only operation that a leader can perform with his log is to append entries to the end. And that’s it.
- Log Matching: if the logs of two servers contain an entry with the same index and expiration number, then both logs are identical up to and including this record.
Proof using mathematical induction and picturesMathematical induction is a method of proof, when the first step is to prove a statement for a simple case. In the second step, we accept the statement true for some case X. Based on this, we try to prove the statement for some neighboring case X + 1. Together, these two steps help to prove the statement for all cases.
In our situation, a simple case is empty logs. There are no records, therefore there is nothing to violate the property.
Now let's try to assume that there are some entries in the logs that correspond to our property. Raft has a mechanism that prevents the property from breaking when any log changes. This mechanism is called Consistency check . Let's look at the examples right away.
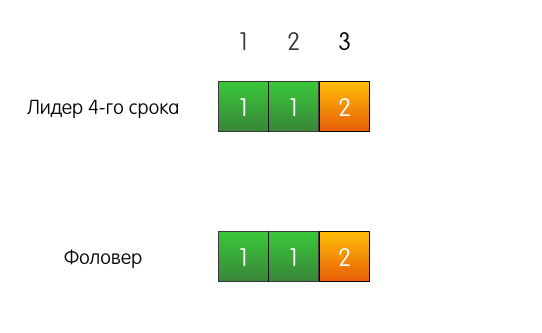
Good example . There is a leader, for example, of the 4th term, there is a follower. They both have matching logs from three entries.
A request from the client comes to the leader, he adds an entry to his log.

The leader sends AppendEntries to the follower. But, in addition to the most added record, the leader also indicates in the request that the record must be added at index 4, and at index 3, before it, there must be a record from term 2.
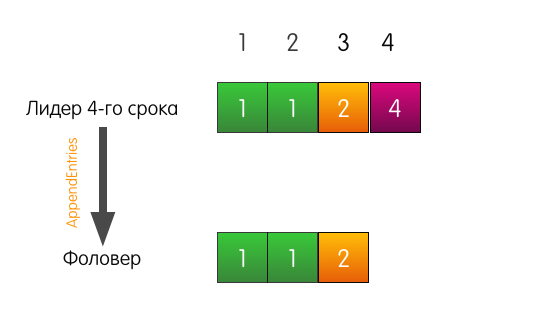
The log entry at index 3 in the follower log matches the one specified in the request, so the follower adds the record to his log and responds to the leader with success. The end.

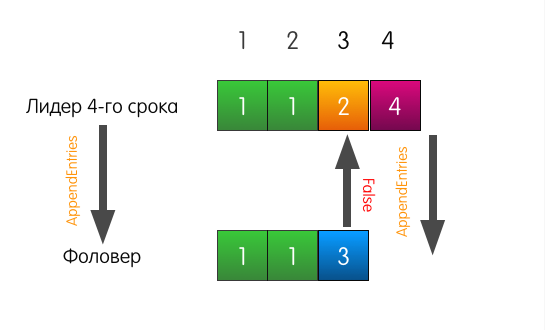
Also a good example, but with a tragic beginning. Now the follower's log is different from the log of the current leader.

When the leader receives a request to add an entry to the log, he will send the same AppendEntries as in the previous example.

However, this time, since the follower does not match the previous record, the follower fails.
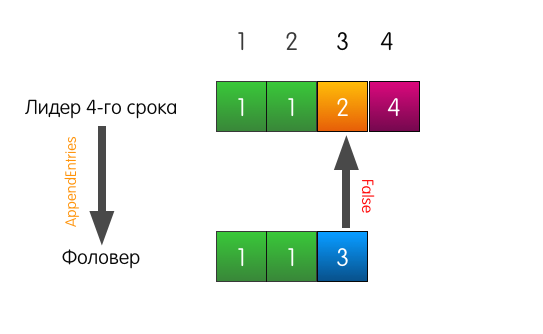
What does the leader do in this case? The leader simply rolls back a little and tries to feed the follower the record that he himself considers standing at index 3. He also includes the previous record in the request.
Now the follower responds with success and overwrites the entries in his log, starting from index 3.
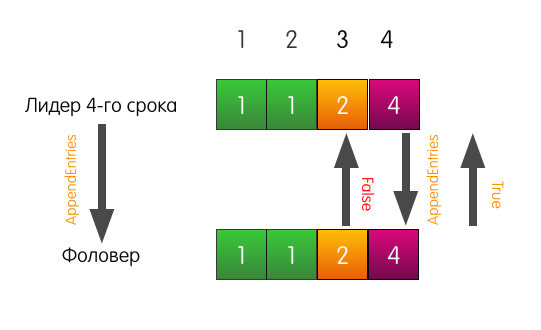
The follower’s log may differ from the leader’s log as you wish. There may not be enough entries in it, there may be extra entries in it. In any case, the consistency check ensures that the logs of followers will sooner or later coincide with the log of the leader.
- Leader Completeness : if the log entry is commited at a given time, then the logs of leaders of all subsequent periods will include this record. This property provides us with durability guarantees.
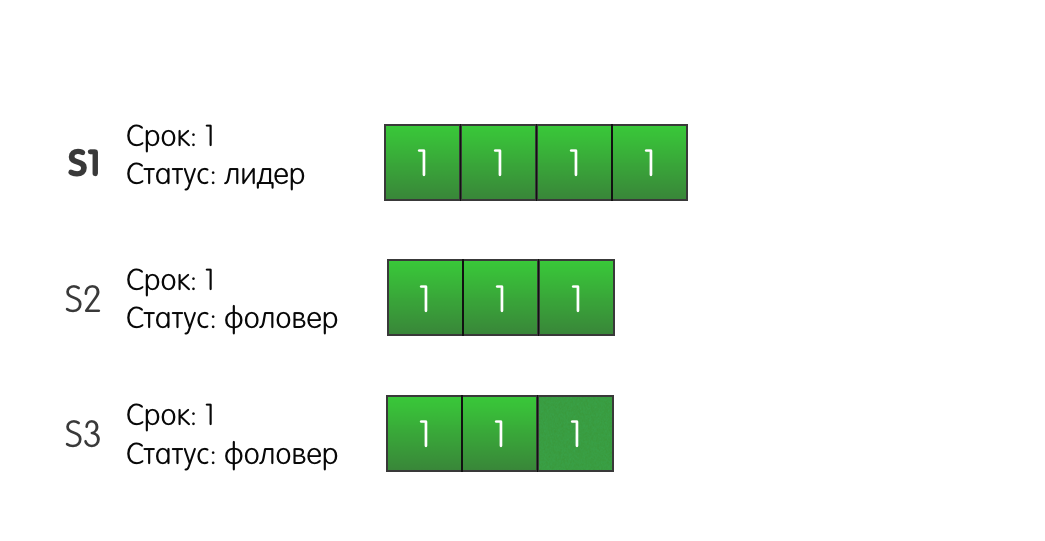
Proof and PicturesConsider the following situation: three servers in a cluster. Server S1 is the leader of the current first term. All servers have three log entries.

Leader S1 receives a request from the client and adds a new record to his log, sends AppendEntries to other S2 and S3 servers.
Record successfully reaches S2, but the network between S1 and S3 blinks and the request is lost. Since S1 knows that the record is present on two of the three servers, it can determine that the record is committed and respond successfully to the client.
S1 will also retry adding an entry to S3 until it succeeds. But what happens if S1 fails and it shuts down? Moreover, what will happen if S3 is the first to get tired of waiting and it becomes a candidate? S2 will vote for him, S3 will become the leader of the second term, and on the next request to add a record, S3 will overwrite our recorded record?
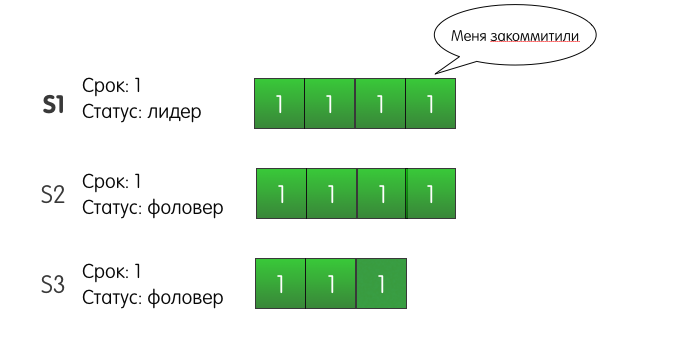
In fact, this situation cannot happen in the Raft cluster. The catch here is that S2 would not vote for S3. Why? Because the S3 server log at the time of voting is less relevant than the S2 server log. This mechanism is called Election restriction - the server will vote for another server only if the candidate’s log is no less relevant than the voter's log.
Raft compares the relevance of logs in two ways:
- Last record date number
- Log length
Candidates include these two parameters in the RequestVote request so that followers can compare the relevance of their log with the candidate’s log.
“Most important” is the log in which the last record is older.

If the deadline numbers of the last entries coincide, then the “main” is the log that is longer.

If both are the same, then the logs are equally relevant, and also, as follows from the previous property, are absolutely identical.
It turns out that the server log in which there is a secured record will always be more relevant than the log in which it is not. And a server that has a secured record will not vote for a server that does not have it. And since there is a recorded record on most servers, a candidate without this record will not be able to get a majority of the votes and become a leader in order to delete this record from other servers.
- State Machine Safety : this property is described in the original in terms of distributed state machines, in terms of our article this property can be described as follows: when a server commits a record with a certain index, no other server commits another record for this index.
This property follows from the past. If the follower commits some record at index N, then his log is identical to the leader’s log up to and including N. The Leader completeness property guarantees that all subsequent leaders will also contain this secured record at index N, which means that followers committing a record at index N in subsequent periods will commit the same value.
Links to materials for further study
All Articles