What is inside the chat bot?
My name is Ivan Bondarenko. I have been working on machine learning algorithms for text analysis and spoken language since about 2005. Now I work in Moscow PhysTech as a leading scientific developer of a business solutions laboratory based on the NTI Competence Center for Artificial Intelligence MIPT and in the company Data Monsters, which deals with the practical development of interactive systems for solving various problems in the industry. I also teach a little at our university. My story will be devoted to what a chat bot is, how machine learning algorithms and other approaches are used to automate human-computer communication and where it can be implemented.
The full version of my speech at the “Night of Scientific Stories” can be seen in the video , and I will give brief abstracts in the text below.

First of all, human interaction algorithms are successfully used in call centers. The work of a call center operator is very difficult and expensive. Moreover, in many situations it is almost impossible to completely solve the problem of human-computer communication. It's one thing when we work with a bank, which, as a rule, has several thousand customers. You can recruit the staff of the call center who would serve these clients and talk with them. But when we solve more ambitious tasks (for example, we produce smartphones or some other consumer electronics), we have not several thousand customers, but several tens of millions of customers all over the world. And we want to understand what problems people have with our products. Users, as a rule, share information with each other in the forums or write to the support service of the manufacturer of smartphones. Live operators will not be able to cope with work on a huge client base, and here algorithms come to the rescue, which can work in multi-channel mode, serving a huge number of people.
To solve such problems, to build algorithms for dialogue systems that could interact with a person and extract meaning, important information from arbitrary messages, there is a whole area in the field of computer linguistics - the analysis of texts in natural language. A robot must be able to read, understand, listen, speak and so on. This area - Natural Language Processing - breaks down into several parts.
When a bot communicates with a person and a person writes something to the bot, you need to understand what is written, what the user wanted, which he mentioned in his speech. Understanding the intentions of the user, the so-called intent - what a person wants: re-issue a bank card or order pizza. And the allocation of named entities, that is, things that the user specifically talks about: if it is pizza, then “Margarita” or “Hawaiian”, if the card, then which system - MasterCard, World and so on.

And finally, an understanding of the tonality of the message - in what emotional state a person is. The algorithm must be able to detect in which key the message is written, either this is news text, or this message is from a person who communicates with our bot in order to adequately respond to the key.

Generation of the text (Natural Language Generation) - an adequate response to a human request in the same human language (natural), and not a complex plate and not formal phrases.
Speech recognition and speech synthesis (Speech-to-Text and Text-to-Speech). If a chatbot does not just correspond with a person, but speaks and listens, you need to teach him to understand spoken language, convert sound vibrations into text, then to analyze this text with a text understanding module and generate sound vibrations from the response text, in turn which then the person, the subscriber will hear.
Chatbots include several key architectures.
The chatbot that answers the most frequently asked questions (FAQ-chatbot) is the easiest option. We can always formulate a set of model questions that people ask. For a site for the delivery of ready meals, as a rule, these are questions: “how much will the delivery cost”, “do you deliver to Pervomaisky district”, etc. You can group them according to several classes, intentions, user intentions. And for each intent, select typical answers.
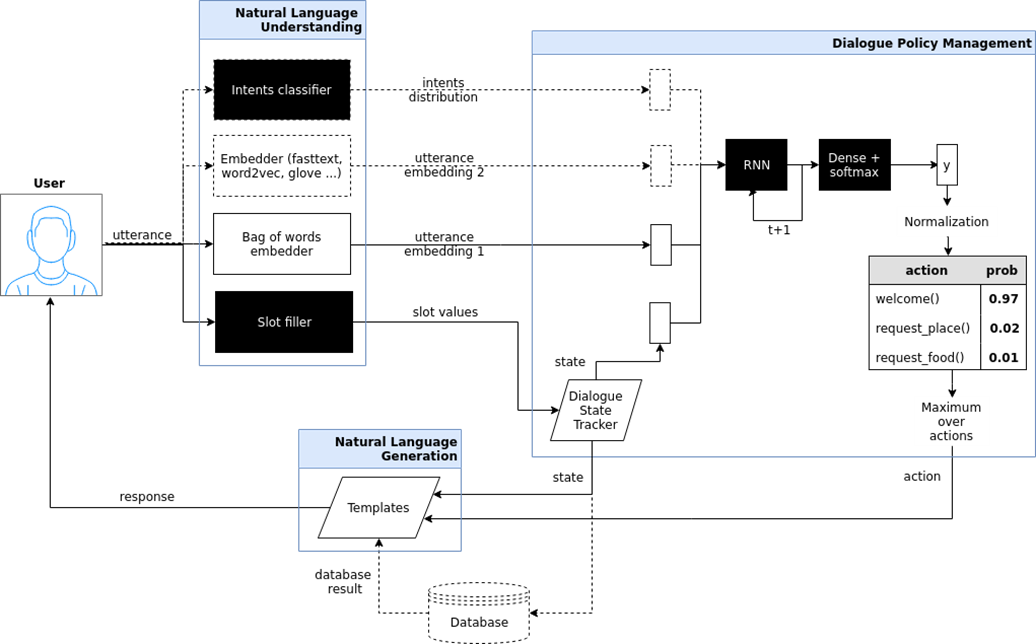
Targeted chat bot (goal oriented bot). Here I tried to show the architecture of such a chatbot, which is implemented in the iPavlov project. iPavlov is a project to create conversational artificial intelligence. In particular, a focused chatbot helps the user achieve a goal (for example, book a table in a restaurant or order pizza, or learn something about problems at the bank). It is not just about the answer to the question (question-answer - without any context). The targeted chatbot has a module for understanding text, dialogue management and a module for generating responses.
Chat bots of the question answering system question answering system and just “talkers” (chit chat bot). If the two previous types of chat bots either answer the most frequently asked questions or lead the user through the dialog box, in the end, helping to book a restaurant, figuring out what the user wants, Chinese or Italian cuisine, etc., then the question-answer a system is another type of chatbot. The task of such a chat bot is not to move along the column of the dialogue and not just to classify the user's intentions, but to provide an information search - to find the most relevant document that matches the person’s question and the place in the document where the answer is contained. For example, employees of a large retailer, instead of memorizing instructions governing work, or looking for an answer where to put buckwheat, ask a question to such a chatbot based on a question-answer system.
The recognition of intents, the allocation of named entities, the search in documents and the search for places in a document that correspond to the semantics of a question - all this without machine learning, without some kind of statistical analysis is impossible to implement. Therefore, machine learning is the basis of modern chat bots — task methods, approximations of some hidden patterns that exist in large data sets and the identification of these patterns. It makes sense to apply this approach when there are patterns, tasks, but it is impossible to come up with a simple formula, formalism to describe this pattern.
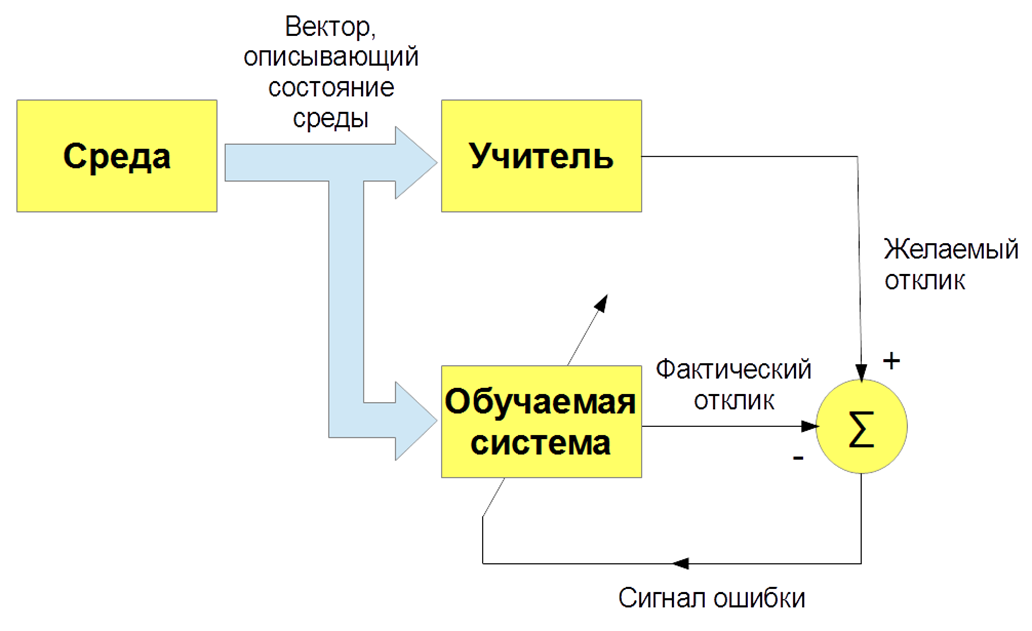
There are several types of machine learning: with a teacher (supervised learning), without a teacher (unsupervised learning), with reinforcement (reinforcement learning). We are primarily interested in the task of teaching with a teacher - when there are input images and instructions (labels) of the teacher and the classification of these images. Or input speech signals and their classification. And we teach our bot, our algorithm to reproduce the work of a teacher.
Okay, everything seems to be cool. And how to teach a computer to understand texts? Text is a complex object, and how do letters turn into numbers and come up with a vector description of the text? There is the simplest option - a "bag of words." We ask the dictionary of the whole system, for example, all the words that are in the Russian language, and formulate such very sparse vectors with word frequencies. This option is good for simple questions, but for more complex tasks it is not suitable.
In 2013, a kind of revolution took place in the modeling of words and texts. Thomas Mikolov proposed a special approach to effective vector representation of words based on the distribution hypothesis. If different words are found in the same context, then they have something in common. For example: “Scientists conducted an analysis of algorithms” and “Scientists conducted a study of algorithms.” So, “Analysis” and “research” are synonyms and mean approximately the same thing. Therefore, you can teach a special neural network to predict a word by context, or context by word.
Finally, how do we train? In order to train the bot to understand intentions, true intentions, you need to manually mark up a bunch of texts using special programs. To teach the bot to understand named entities - the name of a person, the name of the company, location - you also need to place texts. Accordingly, on the one hand, the learning algorithm with the teacher is the most effective, it allows you to create an effective recognition system, but on the other hand, a problem arises: you need large, labeled data sets, and this is expensive and time consuming. In the process of marking up data sets, there may be errors caused by the human factor.
To solve this problem, modern chatbots use the so-called transfer learning - transfer learning. Those who know many foreign languages, probably noticed such a nuance that it is easier to learn another foreign language than the first. Actually, when you study some new problem, you try to use your past experience for this. So, transfer learning is based on this principle: we teach the algorithm to solve one problem, for which we have a large data set. And then this trained algorithm (that is, we take the algorithm not from scratch, but trained to solve another problem), we train to solve our problem. Thus, we get an effective solution using a small variety of data.
One such model is ELMo (Embeddings from Language Models), like ELMo from Sesame Street. We use recurrent neural networks, they have memory and can process sequences. For example: “The programmer Vasya loves beer. Every evening after work, he goes to the Jonathan and misses a glass or two. " So, who is he? Is he this evening, is he a beer, or is he a programmer Vasya? A neural network that processes words as elements of a sequence, given the context, a recurrent neural network, can understand the relationships, solve this problem, and highlight some semantics.
We train such a deep neural network to model texts. Formally, this is the task of teaching with a teacher, but the teacher is the unallocated text itself. The next word in the text is a teacher in relation to all the previous ones. Thus, we can use gigabytes, dozens of gigabytes of texts, train effective models that the semantics in these texts emphasize. And then, when we use the Embeddings from Language Models (ELMo) model in output mode, we give the word based on context. Not just a stick, but let's stick. We look at what the neural network generates at this point in time, which signals. We catanate these signals and get a vector representation of the word in a specific text, taking into account its specific sematic significance.
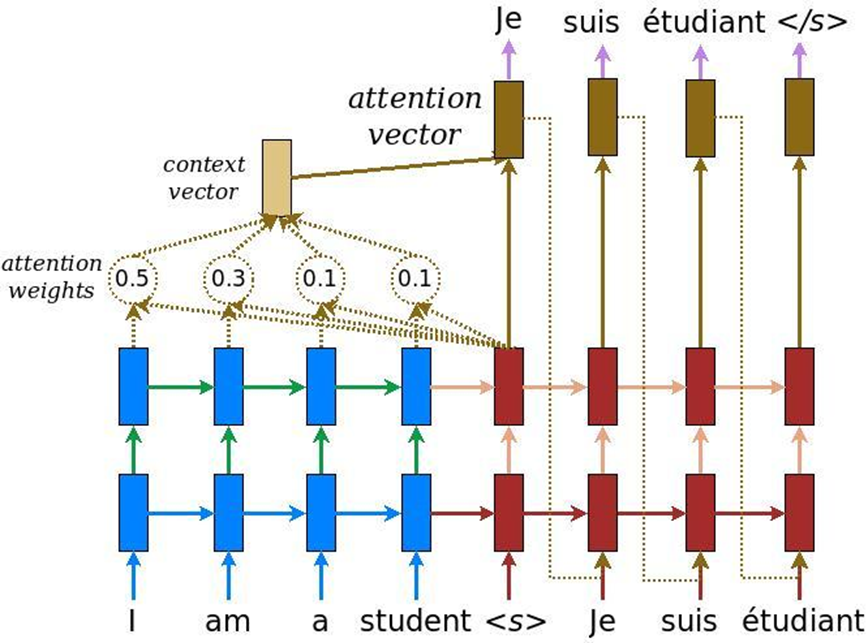
There is one more peculiarity in the analysis of texts: when the task of machine translation is solved, the same meaning can be conveyed by one number of words in English and another number of words in Russian. Accordingly, there is no linear comparison, and we need a mechanism that would focus on certain pieces of text in order to adequately translate them into another language. Initially, attention was invented for machine translation - the task of converting one text to another with ordinary recurrent neural systems. To this we add a special layer of attention, which at each moment of time evaluates which word is important to us now.
But then the guys from Google thought, why not use the attention mechanism at all without recurrent neural networks - just attention. And they came up with an architecture called a transformer (BERT (Bidirectional Encoder Representations from Transformers)).
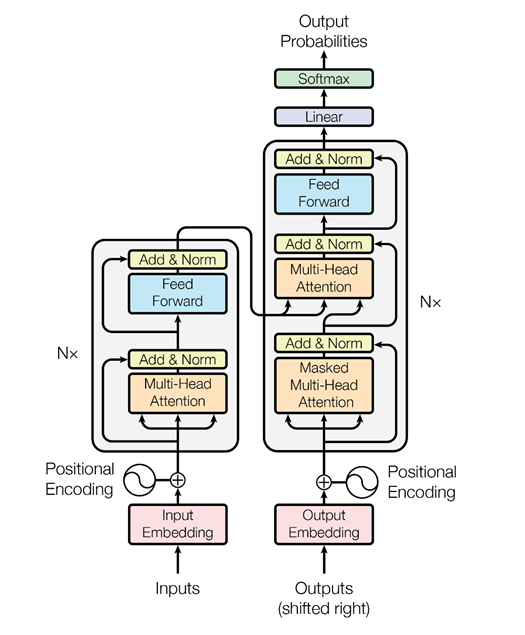
On the basis of such an architecture, when there is only multi-headed attention, special algorithms were invented that can also analyze the relationship of words in texts, the relationship of texts with each other - as ELMo does, it is only more cunning. Firstly, it’s a cooler and more complex network. Secondly, we solve two problems at the same time, and not one, as in the case of ELMo - language modeling, forecasting. We are trying to restore hidden words in the text and restore links between texts. That is, let's say: “The programmer Vasya loves beer. Every night he goes to the bar. ” Two texts are interconnected. “Programmer Vasya loves beer. Cranes fly south in the fall ”- these are two unrelated texts. Again, this information can be extracted from unallocated texts, trained BERT and get very cool results.
This was published last November in the article “Attention Is All You Need,” which I highly recommend reading. At the moment, this is the coolest result in the field of text analysis for solving various problems: for text classification (recognition of tonality, user's intentions); for question and answer systems; for recognizing named entities and so on. Modern dialogue systems use BERT, pre-trained contextual embeddings (ELMo or BERT) in order to understand what the user wants. But the dialogue management module is still often designed based on rules, because a particular dialogue can be very dependent on the subject or even on the task.
The full version of my speech at the “Night of Scientific Stories” can be seen in the video , and I will give brief abstracts in the text below.
Algorithm Capabilities
First of all, human interaction algorithms are successfully used in call centers. The work of a call center operator is very difficult and expensive. Moreover, in many situations it is almost impossible to completely solve the problem of human-computer communication. It's one thing when we work with a bank, which, as a rule, has several thousand customers. You can recruit the staff of the call center who would serve these clients and talk with them. But when we solve more ambitious tasks (for example, we produce smartphones or some other consumer electronics), we have not several thousand customers, but several tens of millions of customers all over the world. And we want to understand what problems people have with our products. Users, as a rule, share information with each other in the forums or write to the support service of the manufacturer of smartphones. Live operators will not be able to cope with work on a huge client base, and here algorithms come to the rescue, which can work in multi-channel mode, serving a huge number of people.
To solve such problems, to build algorithms for dialogue systems that could interact with a person and extract meaning, important information from arbitrary messages, there is a whole area in the field of computer linguistics - the analysis of texts in natural language. A robot must be able to read, understand, listen, speak and so on. This area - Natural Language Processing - breaks down into several parts.
Understanding the text (Natural Language Understanding, NLU).
When a bot communicates with a person and a person writes something to the bot, you need to understand what is written, what the user wanted, which he mentioned in his speech. Understanding the intentions of the user, the so-called intent - what a person wants: re-issue a bank card or order pizza. And the allocation of named entities, that is, things that the user specifically talks about: if it is pizza, then “Margarita” or “Hawaiian”, if the card, then which system - MasterCard, World and so on.
And finally, an understanding of the tonality of the message - in what emotional state a person is. The algorithm must be able to detect in which key the message is written, either this is news text, or this message is from a person who communicates with our bot in order to adequately respond to the key.
Generation of the text (Natural Language Generation) - an adequate response to a human request in the same human language (natural), and not a complex plate and not formal phrases.
Speech recognition and speech synthesis (Speech-to-Text and Text-to-Speech). If a chatbot does not just correspond with a person, but speaks and listens, you need to teach him to understand spoken language, convert sound vibrations into text, then to analyze this text with a text understanding module and generate sound vibrations from the response text, in turn which then the person, the subscriber will hear.
Types of Chat Bots
Chatbots include several key architectures.
The chatbot that answers the most frequently asked questions (FAQ-chatbot) is the easiest option. We can always formulate a set of model questions that people ask. For a site for the delivery of ready meals, as a rule, these are questions: “how much will the delivery cost”, “do you deliver to Pervomaisky district”, etc. You can group them according to several classes, intentions, user intentions. And for each intent, select typical answers.
Targeted chat bot (goal oriented bot). Here I tried to show the architecture of such a chatbot, which is implemented in the iPavlov project. iPavlov is a project to create conversational artificial intelligence. In particular, a focused chatbot helps the user achieve a goal (for example, book a table in a restaurant or order pizza, or learn something about problems at the bank). It is not just about the answer to the question (question-answer - without any context). The targeted chatbot has a module for understanding text, dialogue management and a module for generating responses.
Chat bots of the question answering system question answering system and just “talkers” (chit chat bot). If the two previous types of chat bots either answer the most frequently asked questions or lead the user through the dialog box, in the end, helping to book a restaurant, figuring out what the user wants, Chinese or Italian cuisine, etc., then the question-answer a system is another type of chatbot. The task of such a chat bot is not to move along the column of the dialogue and not just to classify the user's intentions, but to provide an information search - to find the most relevant document that matches the person’s question and the place in the document where the answer is contained. For example, employees of a large retailer, instead of memorizing instructions governing work, or looking for an answer where to put buckwheat, ask a question to such a chatbot based on a question-answer system.
Types of Machine Learning
The recognition of intents, the allocation of named entities, the search in documents and the search for places in a document that correspond to the semantics of a question - all this without machine learning, without some kind of statistical analysis is impossible to implement. Therefore, machine learning is the basis of modern chat bots — task methods, approximations of some hidden patterns that exist in large data sets and the identification of these patterns. It makes sense to apply this approach when there are patterns, tasks, but it is impossible to come up with a simple formula, formalism to describe this pattern.
There are several types of machine learning: with a teacher (supervised learning), without a teacher (unsupervised learning), with reinforcement (reinforcement learning). We are primarily interested in the task of teaching with a teacher - when there are input images and instructions (labels) of the teacher and the classification of these images. Or input speech signals and their classification. And we teach our bot, our algorithm to reproduce the work of a teacher.
Okay, everything seems to be cool. And how to teach a computer to understand texts? Text is a complex object, and how do letters turn into numbers and come up with a vector description of the text? There is the simplest option - a "bag of words." We ask the dictionary of the whole system, for example, all the words that are in the Russian language, and formulate such very sparse vectors with word frequencies. This option is good for simple questions, but for more complex tasks it is not suitable.
In 2013, a kind of revolution took place in the modeling of words and texts. Thomas Mikolov proposed a special approach to effective vector representation of words based on the distribution hypothesis. If different words are found in the same context, then they have something in common. For example: “Scientists conducted an analysis of algorithms” and “Scientists conducted a study of algorithms.” So, “Analysis” and “research” are synonyms and mean approximately the same thing. Therefore, you can teach a special neural network to predict a word by context, or context by word.
Finally, how do we train? In order to train the bot to understand intentions, true intentions, you need to manually mark up a bunch of texts using special programs. To teach the bot to understand named entities - the name of a person, the name of the company, location - you also need to place texts. Accordingly, on the one hand, the learning algorithm with the teacher is the most effective, it allows you to create an effective recognition system, but on the other hand, a problem arises: you need large, labeled data sets, and this is expensive and time consuming. In the process of marking up data sets, there may be errors caused by the human factor.
To solve this problem, modern chatbots use the so-called transfer learning - transfer learning. Those who know many foreign languages, probably noticed such a nuance that it is easier to learn another foreign language than the first. Actually, when you study some new problem, you try to use your past experience for this. So, transfer learning is based on this principle: we teach the algorithm to solve one problem, for which we have a large data set. And then this trained algorithm (that is, we take the algorithm not from scratch, but trained to solve another problem), we train to solve our problem. Thus, we get an effective solution using a small variety of data.
One such model is ELMo (Embeddings from Language Models), like ELMo from Sesame Street. We use recurrent neural networks, they have memory and can process sequences. For example: “The programmer Vasya loves beer. Every evening after work, he goes to the Jonathan and misses a glass or two. " So, who is he? Is he this evening, is he a beer, or is he a programmer Vasya? A neural network that processes words as elements of a sequence, given the context, a recurrent neural network, can understand the relationships, solve this problem, and highlight some semantics.
We train such a deep neural network to model texts. Formally, this is the task of teaching with a teacher, but the teacher is the unallocated text itself. The next word in the text is a teacher in relation to all the previous ones. Thus, we can use gigabytes, dozens of gigabytes of texts, train effective models that the semantics in these texts emphasize. And then, when we use the Embeddings from Language Models (ELMo) model in output mode, we give the word based on context. Not just a stick, but let's stick. We look at what the neural network generates at this point in time, which signals. We catanate these signals and get a vector representation of the word in a specific text, taking into account its specific sematic significance.
There is one more peculiarity in the analysis of texts: when the task of machine translation is solved, the same meaning can be conveyed by one number of words in English and another number of words in Russian. Accordingly, there is no linear comparison, and we need a mechanism that would focus on certain pieces of text in order to adequately translate them into another language. Initially, attention was invented for machine translation - the task of converting one text to another with ordinary recurrent neural systems. To this we add a special layer of attention, which at each moment of time evaluates which word is important to us now.
But then the guys from Google thought, why not use the attention mechanism at all without recurrent neural networks - just attention. And they came up with an architecture called a transformer (BERT (Bidirectional Encoder Representations from Transformers)).
On the basis of such an architecture, when there is only multi-headed attention, special algorithms were invented that can also analyze the relationship of words in texts, the relationship of texts with each other - as ELMo does, it is only more cunning. Firstly, it’s a cooler and more complex network. Secondly, we solve two problems at the same time, and not one, as in the case of ELMo - language modeling, forecasting. We are trying to restore hidden words in the text and restore links between texts. That is, let's say: “The programmer Vasya loves beer. Every night he goes to the bar. ” Two texts are interconnected. “Programmer Vasya loves beer. Cranes fly south in the fall ”- these are two unrelated texts. Again, this information can be extracted from unallocated texts, trained BERT and get very cool results.
This was published last November in the article “Attention Is All You Need,” which I highly recommend reading. At the moment, this is the coolest result in the field of text analysis for solving various problems: for text classification (recognition of tonality, user's intentions); for question and answer systems; for recognizing named entities and so on. Modern dialogue systems use BERT, pre-trained contextual embeddings (ELMo or BERT) in order to understand what the user wants. But the dialogue management module is still often designed based on rules, because a particular dialogue can be very dependent on the subject or even on the task.
All Articles