How we do automation of a large legacy network
Hey. We have 15,260+ objects and 38,000 network devices that need to be configured, updated and checked for their functionality. Maintaining such a fleet of equipment is quite difficult and requires a lot of time, effort and people. Therefore, we needed to automate work with network equipment and we decided to adapt the concept of Network as a Code to manage the network in our company. Under the cut, read our history of automation, mistakes made and a further plan for building systems.
Hello! My name is Alexander Prokhorov, and together with the team of network engineers in our department we are working on a network in #IT X5 . Our department develops network infrastructure, monitoring, network automation and the trendy direction of Network as a Code.
Initially, I did not really believe in any automation in our network in principle. There was a lot of legacy and configuration errors - not everywhere there was central authorization, not all hardware supported SSH, not all SNMP was configured. All this greatly undermined the belief in automation. Therefore, first of all, we tidied up what is needed to start the automation, namely: standardization of SSH connection, single authorization ( AAA ) and SNMP profiles. All this foundation allows you to write a tool for mass delivery of configurations to a device, but the question arises: can I get more? So we came to the need to draw up a plan for the development of automation and the concept of Network as a Code, in particular.
The concept of Network as a Code, according to Cisco, means the following principles:

The first two points allow you to apply the DevOps, or NetDevOps, approach to managing your network infrastructure. With the third paragraph there are difficulties, for example, what to do if there is no API? Of course, SSH and CLI, we are networkers!
In addition to trying to apply new approaches to network management, we wanted to solve some more acute problems in the network infrastructure, such as data integrity, updating and, of course, automation. By automation we mean not only mass delivery of configurations to equipment, but also automatic configuration, automatic collection of inventory data of network equipment, integration with monitoring systems. But first things first.
The functionality we set our sights on is:
A brief conclusion from the spoiler is to better systematize and control the process of mass delivery of configurations so as not to come to mass delivery of errors in configurations.
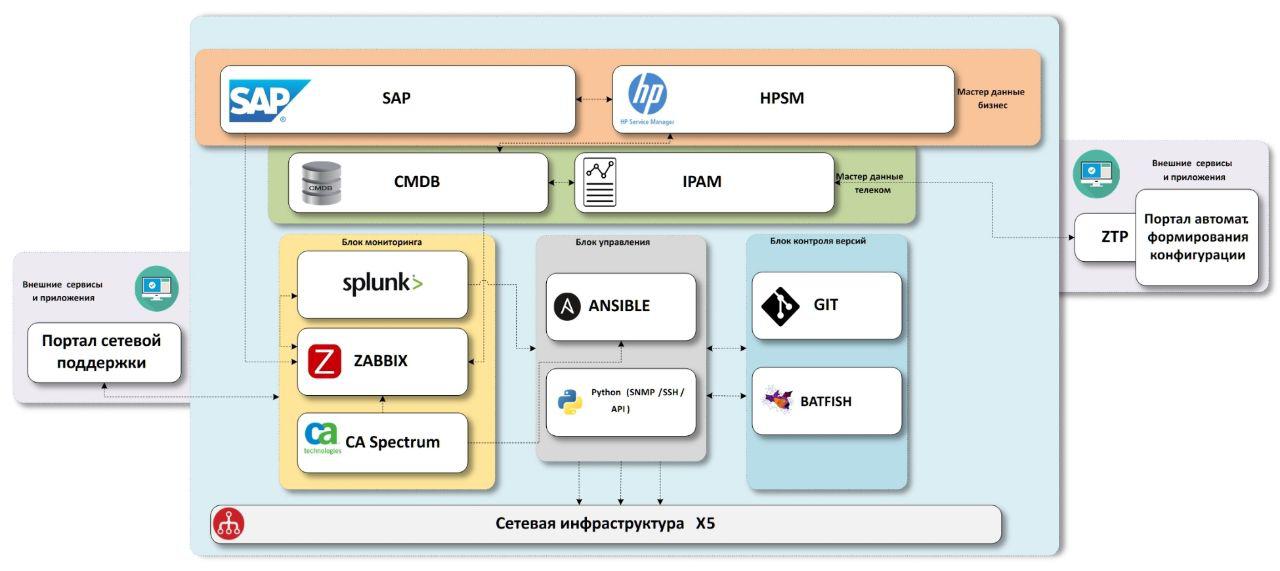
The scheme we arrived at consists of “business” master data blocks, “network” master data blocks, network infrastructure monitoring systems, configuration delivery systems, version control systems with a testing unit.
First we need to know what objects are in the company.
SAP - ERP company system. Data on almost all objects is there, or rather, on all stores and distribution centers. As well as there is data on equipment that passed through an IT warehouse with inventory numbers, which will also be useful to us in the future. Only offices are missing, they are not started in the system. We are trying to solve this problem in a separate process, starting from the moment of opening, we need a connection on each object, and we select the settings for communication, so somewhere at this moment we need to create master data. But data insufficiency is a separate topic, it is better to put this description in a separate article if there is interest in this.
HPSM - a system containing a common CMDB for IT, incident management, change management. Since the system is common to all IT, it should have all IT equipment, including network equipment. This is the place where we will add all the final data over the network. With incident and change management, we plan to interact from monitoring systems in the future.
We know what objects we have, enrich them with data over the network. For this purpose, we have two systems - IPAM from SolarWinds and our own CMDB.noc system.
IPAM - storage of IP subnets, the most correct and correct data on the IP address ownership in the company should be here.
CMDB.noc is a database with a WEB interface where static data on network equipment is stored - routers, switches, access points, as well as providers and their characteristics. Under static means that their change is carried out only with the participation of man. In other words, autodiscovering does not make changes to this database; we need it to understand what “should” be installed on the object. Its base is needed as a buffer between the productive systems that the entire company works with and internal network tools. Accelerates the development, adding the necessary fields, new relationships, adjusting parameters, etc. Plus, this solution is not only in the speed of development, but also in the presence of those relationships between the data that we need, without compromise. As a mini-example, we use several exid in the database for data communication between IPAM, SAP and HPSM.
As a result, we received complete data on all objects, with attached network equipment and IP addresses. Now we need configuration templates, or network services that we provide at these sites.

Here, we just reached the application of the first NaaC principle - storing target configurations in the repository. In our case, this is Gitlab. The choice for us was simple:
In Gitlab, the main interesting part of automation will take place - the process of changing the configuration standard or, more simply, the template.
Now let's say a new project comes to us. The tasks for the new IT project are to make a pilot in a certain volume of stores. According to the results of the pilot - if successful, make a replication for all objects of this type; otherwise collapse the pilot without performing a replication.
This process fits very well into the Git logic:

In a first approximation - even without automation, it is a very convenient tool for working together on a network configuration. Especially if you imagine that three or more projects came along at the same time. When the time comes for the release of projects in prod, you will need to resolve all configuration conflicts in the merge-requests and check that the settings are not mutually exclusive. And this is very convenient to do in git.
Plus, this approach adds us the flexibility to use the Gitlab CI / CD tools to test configurations virtually, to automate the delivery of configurations to a test bench or a pilot group of objects. // And even on prod if you want.
Initially, the main goal was precisely the mass delivery of configurations, as a tool that very clearly allows you to save engineers' time and speed up configuration tasks. For this, even before the start of the great activity “Network as a Code”, we wrote a python solution for connecting to equipment either to collect equipment configurations or to configure it. This is netmiko , this is pysnmp , this is jinja2 , etc.
But it’s time for us to divide the bulk configuration into several subspecies:
One of the tasks of automation is, of course, to find out what fell out of this automation. Not all 38k are configured perfectly the first time, it even happens that someone sets up the equipment with their hands. And you need to track these changes and restorejustice to the target configuration.
There are three approaches to verifying configuration compliance with the standard:
In the third case, an option appears to transfer this work to the incident management (OS), so that the inconsistencies are eliminated in small portions throughout the entire time than once by emergency.
Zabbix , which I wrote about earlier in the article “How we monitored 14,000 objects”, is our distributed objects monitoring system where we can make any triggers and alerts that we can think of. Since writing the last article, we have upgraded to Zabbix 4.0 LTS .
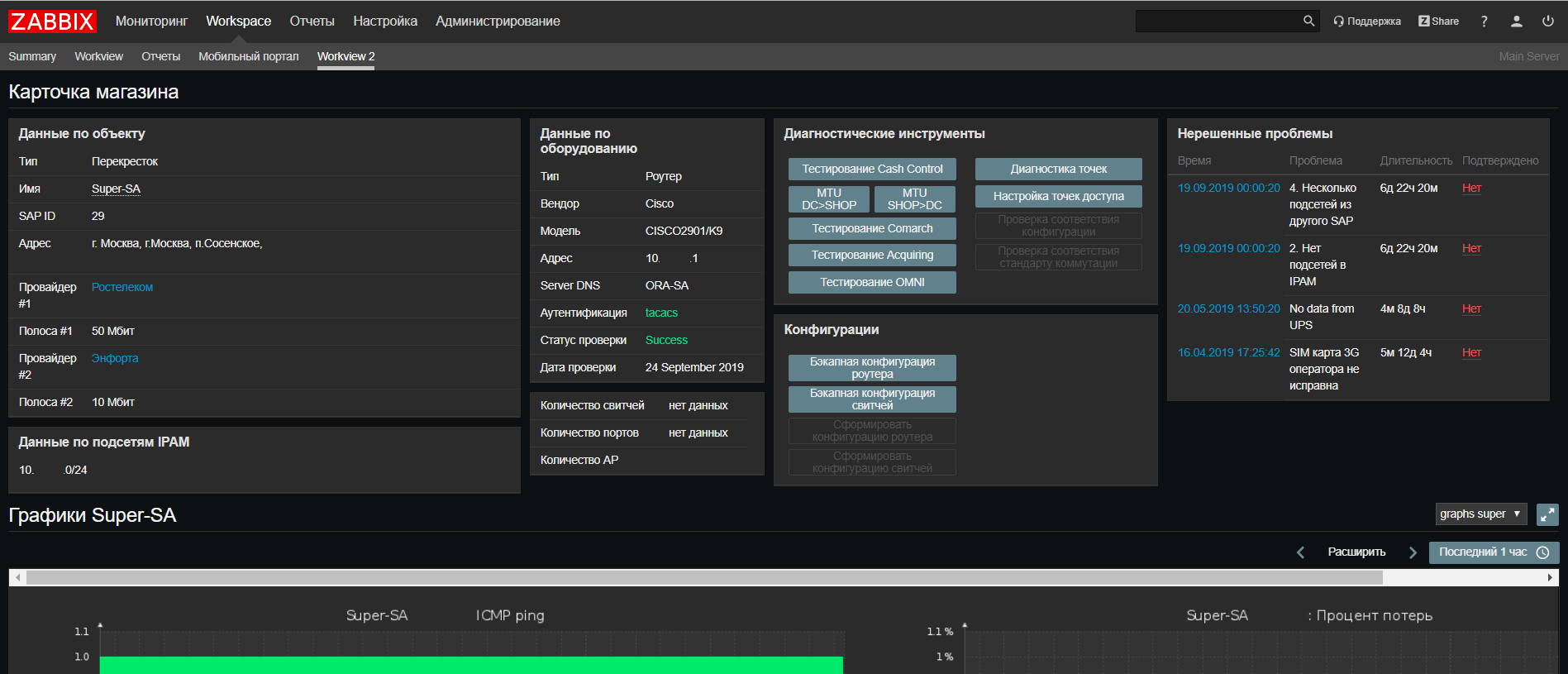
Based on Web Zabbix, we made an update to our network support portal, where now you can find all the information on an object from all our systems on one screen, as well as run scripts to check for frequently occurring problems.
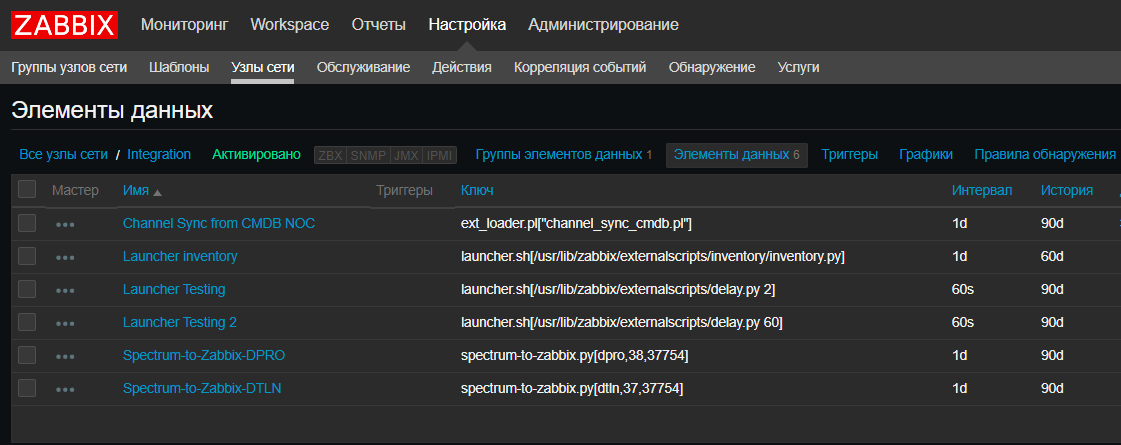
We also introduced a new feature - for us, Zabbix has become, in some way, a CRON for launching scheduled scripts, such as system integration scripts, autodiscover scripts. This is really convenient when you need to look at the current scripts and when and where they run, without checking all the servers. True, for scripts that run for more than 30 seconds, you need a launcher that launches them without waiting for the end. Fortunately, it is simple:
Splunk is a solution that allows you to collect event logs from network equipment, and this can also be used to monitor automation. For example, collecting a configuration backup, a python script generates a LOG message CFG-5-BACKUP , a router or switch sends a message to Splunk, in which we count the number of messages of this type from network equipment. This allows us to track the amount of equipment that the script has detected. And we see how many pieces of iron were able to report this to Splunk and verify that messages from all the pieces of iron have arrived.
Spectrum is a comprehensive system that we use to monitor critical objects, a rather powerful tool that helps us a lot in solving critical network incidents. In automation, we use it only pulling data from it, it is not open-source , so the possibilities are somewhat limited.
 Using systems with master data on equipment, we can think about creating ZTP, or Zero Touch Provisioning. Like a button "auto-tuning", but only without a button.
Using systems with master data on equipment, we can think about creating ZTP, or Zero Touch Provisioning. Like a button "auto-tuning", but only without a button.
We have all the necessary data from the previous blocks - we know the object, its type, what equipment is there (vendor and model), what are the addresses (IPAM), what is the current configuration standard (Git). By putting them all together, we can at least prepare a configuration template for uploading to the device, it will be more like One Touch Provisioning, but sometimes more is not required.
True Zero Touch needs a way to automatically deliver configurations to unconfigured hardware. Moreover, it is desirable regardless of the vendor. There are several working options - a console server, if all the equipment goes through the central warehouse, mobile console solutions, if the equipment arrives immediately. We are only working on these solutions, but as soon as there is a working option, we can share it.
In total, in our concept of Network as a Code , there were 5 main milestones:
It did not work to fit everything into one article, each item is worthy of a separate discussion, we can talk about something now, about something when we check the solutions in practice. If you are interested in any of the topics - at the end there will be a survey where you can vote for the next article. If the topic is not included in the list, but it is interesting to read about it, leave a comment as soon as we can, be sure to share our experience.
Special thanks to Virilin Alexander ( xscrew ) and Sibgatulin Marat ( eucariot ) for the reference visit in the fall of 2018 to the yandex cloud and the story about the automation in the cloud network infrastructure. After him, we got inspiration and a lot of ideas about the use of automation and NetDevOps in the infrastructure of X5 Retail Group.
Long story short, we want to automate the network
Hello! My name is Alexander Prokhorov, and together with the team of network engineers in our department we are working on a network in #IT X5 . Our department develops network infrastructure, monitoring, network automation and the trendy direction of Network as a Code.
Initially, I did not really believe in any automation in our network in principle. There was a lot of legacy and configuration errors - not everywhere there was central authorization, not all hardware supported SSH, not all SNMP was configured. All this greatly undermined the belief in automation. Therefore, first of all, we tidied up what is needed to start the automation, namely: standardization of SSH connection, single authorization ( AAA ) and SNMP profiles. All this foundation allows you to write a tool for mass delivery of configurations to a device, but the question arises: can I get more? So we came to the need to draw up a plan for the development of automation and the concept of Network as a Code, in particular.
The concept of Network as a Code, according to Cisco, means the following principles:
- Store target configurations in repository, Source Control
- Configuration changes go through the repository, Single Source of Truth
- Embedding configurations through the API
The first two points allow you to apply the DevOps, or NetDevOps, approach to managing your network infrastructure. With the third paragraph there are difficulties, for example, what to do if there is no API? Of course, SSH and CLI, we are networkers!
Is that all we need?
The application of these principles alone does not solve all the problems of the network infrastructure, just as their application requires a certain foundation with network data.
Questions that arose when we thought about this:
Based on all the questions above, it became clear that we need a set of systems that solve various problems, work in conjunction with each other and give us complete information about the network infrastructure.

Questions that arose when we thought about this:
- OK, I store the configuration as code, how should I apply it on a specific object?
- Ok, I have a configuration template in the repository, but how can I automatically configure a configuration for an object based on it?
- How to find out which model and which vendor should be on this object? Can I do it automatically?
- How can I check if the current settings of the object match the parameters in the repository?
- How to work with changes in the repository and replicate them on a productive network?
- What dataset and systems do I need to think about Zero Touch Provisioning?
- What about the differences in vendors, and even models of the same vendor?
- How to store subnets for automatic configuration?
Based on all the questions above, it became clear that we need a set of systems that solve various problems, work in conjunction with each other and give us complete information about the network infrastructure.
In addition to trying to apply new approaches to network management, we wanted to solve some more acute problems in the network infrastructure, such as data integrity, updating and, of course, automation. By automation we mean not only mass delivery of configurations to equipment, but also automatic configuration, automatic collection of inventory data of network equipment, integration with monitoring systems. But first things first.
The functionality we set our sights on is:
- Network equipment database (+ discovery, + auto-update)
- Base network addresses (IPAM + validation checks)
- Integration of monitoring systems with inventory data
- Storage of configuration standards in version control system
- Automatic formation of target configurations for an object
- Mass delivery of configurations to network equipment
- Implement a CI / CD process to manage network configuration changes
- Testing network configurations with CI / CD
- ZTP (Zero Touch Provisioning) - automatic setup of equipment for an object
Long story, we tried automatization
We started trying to automate the network setup work 2 years ago. Why now has this question come up again and needs attention?
Setting up more than a few dozen devices is tedious and boring with your hands. Sometimes the engineer’s hand twitches, and he makes mistakes. For several dozens, a script written by one engineer is usually enough, which rolls the updated settings to the network equipment.
Why not stop there? In fact, many network engineers already know how to do all kinds of pythons, and those who don’t know how will already be able to do it very soon (Natalya Samoilenko, however, has published an excellent work on Python , especially for networkers). Anyone who is tasked with configuring n + 1 routers is able to write a script and roll out the settings very quickly. Much faster than then able to bring everything back. According to the experience of automation “every man for himself”, mistakes occur when you can restore communication only with your hands, and only with great suffering of the whole team.

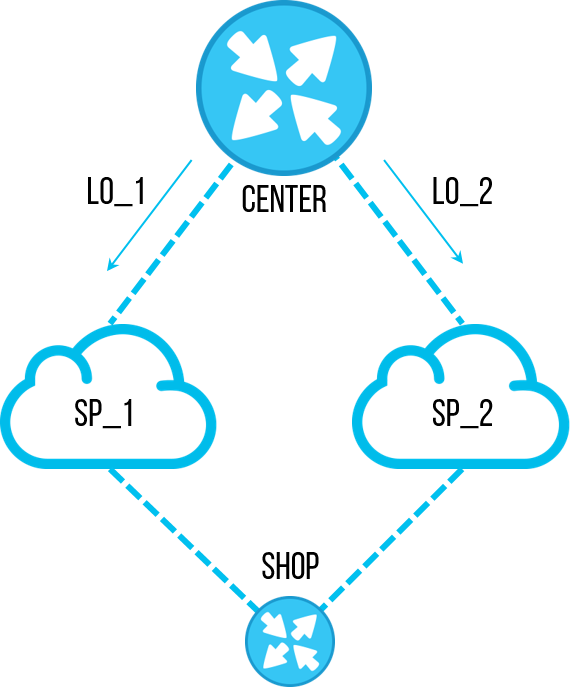 Once, one of the engineers decided to perform an important task - to restore order in the configurations of routers. As a result of the audit, an obsolete prefix-list with specific subnets was found on several objects, which we no longer needed. Previously, it was used to filter the loopback addresses of central sites so that they came through only one channel, and we could test the connection on this channel. But the mechanism was optimized, and they stopped using such a channel testing scheme. The employee decided to remove this prefix-list so that it does not loom in the configuration and cause confusion in the future. Everyone agreed to delete the unused prefix-list , the task is simple, they immediately forgot. But removing the same prefix-list with your hands on dozens of objects is pretty boring and time consuming. And the engineer wrote a script that will quickly go through the equipment, make “no prefix-list pl-cisco-primer” and solemnly save the configuration.
Once, one of the engineers decided to perform an important task - to restore order in the configurations of routers. As a result of the audit, an obsolete prefix-list with specific subnets was found on several objects, which we no longer needed. Previously, it was used to filter the loopback addresses of central sites so that they came through only one channel, and we could test the connection on this channel. But the mechanism was optimized, and they stopped using such a channel testing scheme. The employee decided to remove this prefix-list so that it does not loom in the configuration and cause confusion in the future. Everyone agreed to delete the unused prefix-list , the task is simple, they immediately forgot. But removing the same prefix-list with your hands on dozens of objects is pretty boring and time consuming. And the engineer wrote a script that will quickly go through the equipment, make “no prefix-list pl-cisco-primer” and solemnly save the configuration.
Some time after the discussion, several hours, or a day, I don’t remember, one object fell. After a couple of minutes, another, similar. The number of inaccessible objects continued to grow, in half an hour to 10, and every 2-3 minutes a new one was added. All engineers were connected for diagnosis. 40-50 minutes after the start of the accident, everyone was questioned about the changes, and the employee stopped the script. At that time, there were already about 20 objects with broken channels. A full restoration took 7 engineers for several hours.
Prefix-list was used to filter loopbacks - one was filtered on one channel, the second on the backup. This was used to test communication without switching productive traffic between channels. Therefore, the first rule of an incoming route-map on a BGP neighbor was DENY with “match ip address prefix list” . The rest of the rules in route-map were all PERMIT .
There are several nuances that may be worth noting:
All of the above is true for Cisco IOS . An empty prefix-list may appear when you declare a route-map , make it “match ip address prefix-list pl-test-cisco” . This prefix-list will not be explicitly declared in the configuration (in addition to the line with match ), but it can be found in show ip prefix-list .
Returning to what happened, when the prefix-list was deleted by the script, it became empty, since it was still in the first DENY rule in the route-map . An empty prefix-list allows all subnets, so everything that a BGP peer passed to us fell into the first DENY rule.
Why didn’t the engineer immediately notice that he had broken the connection? Here played the role of BGP timers in Cisco.
BGP itself does not exchange routes on a schedule, and if you updated the BGP routing policy, you need to reset the BGP session to apply the changes, "clear ip bgp <peer-ip>" to Cisco.
In order not to reset the session, there are two mechanisms:
Soft-reconfiguration holds the information received in UPDATE from the neighbor about the routes until policies are applied in the local adj-RIB-in table. When updating policies, it becomes possible to emulate UPDATE from a neighbor.
Route Refresh is the "ability" of peers to send UPDATE on request. The availability of this opportunity is agreed upon when establishing a neighborhood. Pros - no need to store a copy of UPDATE locally. Cons - in practice, after an UPDATE request from a neighbor, you need to wait until he sends it. By the way, you can disable the feature on Cisco with a hidden command:
There is an undocumented feature of Cisco - a 30-second timer, which is triggered by a change in BGP policies. After changing the policies, in 30 seconds the process of updating routes using one of the above technologies will start. I could not find a documented description of this timer, but there is a mention of it in BUG CSCvi91270 . You can learn about its availability in practice, after making changes in the lab and looking in debug for UPDATE requests to the neighbor or the soft-reconfiguration process . (If there is additional information on the topic - you can leave in the comments)
after making changes in the lab and looking in debug for UPDATE requests to the neighbor or the soft-reconfiguration process . (If there is additional information on the topic - you can leave in the comments)
For Soft-Reconfiguration , the timer works like this:
For Route-Refresh from the neighbor’s side like this:
If Route-Refresh is not supported by one of the peers and soft-reconfiguration inbound is not enabled, then route updates by the new policy will not automatically happen.
So, prefix-list was deleted, the connection remained, after 30 seconds it disappeared. The script managed to change the config, check the connection, and save the config. The fall from the script was not immediately connected, against the background of a large number of objects.
All of this could easily be avoided by testing, partial replication of settings. There was an understanding that automation should be centralized and controlled.

Setting up more than a few dozen devices is tedious and boring with your hands. Sometimes the engineer’s hand twitches, and he makes mistakes. For several dozens, a script written by one engineer is usually enough, which rolls the updated settings to the network equipment.
Why not stop there? In fact, many network engineers already know how to do all kinds of pythons, and those who don’t know how will already be able to do it very soon (Natalya Samoilenko, however, has published an excellent work on Python , especially for networkers). Anyone who is tasked with configuring n + 1 routers is able to write a script and roll out the settings very quickly. Much faster than then able to bring everything back. According to the experience of automation “every man for himself”, mistakes occur when you can restore communication only with your hands, and only with great suffering of the whole team.
Example
Once, one of the engineers decided to perform an important task - to restore order in the configurations of routers. As a result of the audit, an obsolete prefix-list with specific subnets was found on several objects, which we no longer needed. Previously, it was used to filter the loopback addresses of central sites so that they came through only one channel, and we could test the connection on this channel. But the mechanism was optimized, and they stopped using such a channel testing scheme. The employee decided to remove this prefix-list so that it does not loom in the configuration and cause confusion in the future. Everyone agreed to delete the unused prefix-list , the task is simple, they immediately forgot. But removing the same prefix-list with your hands on dozens of objects is pretty boring and time consuming. And the engineer wrote a script that will quickly go through the equipment, make “no prefix-list pl-cisco-primer” and solemnly save the configuration.
Some time after the discussion, several hours, or a day, I don’t remember, one object fell. After a couple of minutes, another, similar. The number of inaccessible objects continued to grow, in half an hour to 10, and every 2-3 minutes a new one was added. All engineers were connected for diagnosis. 40-50 minutes after the start of the accident, everyone was questioned about the changes, and the employee stopped the script. At that time, there were already about 20 objects with broken channels. A full restoration took 7 engineers for several hours.
Technical side
Prefix-list was used to filter loopbacks - one was filtered on one channel, the second on the backup. This was used to test communication without switching productive traffic between channels. Therefore, the first rule of an incoming route-map on a BGP neighbor was DENY with “match ip address prefix list” . The rest of the rules in route-map were all PERMIT .
There are several nuances that may be worth noting:
- The route-map rule in which there is no match - skips everything
- At the end of the prefix-list is implicit deny , but only if it is not empty
- An empty prefix-list is an implicit permit
All of the above is true for Cisco IOS . An empty prefix-list may appear when you declare a route-map , make it “match ip address prefix-list pl-test-cisco” . This prefix-list will not be explicitly declared in the configuration (in addition to the line with match ), but it can be found in show ip prefix-list .
2901-NOC-4.2(config)#route-map rm-test-in 2901-NOC-4.2(config-route-map)#match ip address prefix-list pl-test-in 2901-NOC-4.2(config-route-map)#do sh run | i prefix match ip address prefix-list pl-test-in 2901-NOC-4.2(config-route-map)#do sh ip prefix ip prefix-list pl-test-in: 0 entries 2901-NOC-4.2(config-route-map)#
Returning to what happened, when the prefix-list was deleted by the script, it became empty, since it was still in the first DENY rule in the route-map . An empty prefix-list allows all subnets, so everything that a BGP peer passed to us fell into the first DENY rule.
Why didn’t the engineer immediately notice that he had broken the connection? Here played the role of BGP timers in Cisco.
BGP itself does not exchange routes on a schedule, and if you updated the BGP routing policy, you need to reset the BGP session to apply the changes, "clear ip bgp <peer-ip>" to Cisco.
In order not to reset the session, there are two mechanisms:
- Cisco Soft-Reconfiguration
- Route Refresh as RFC2918
Soft-reconfiguration holds the information received in UPDATE from the neighbor about the routes until policies are applied in the local adj-RIB-in table. When updating policies, it becomes possible to emulate UPDATE from a neighbor.
Route Refresh is the "ability" of peers to send UPDATE on request. The availability of this opportunity is agreed upon when establishing a neighborhood. Pros - no need to store a copy of UPDATE locally. Cons - in practice, after an UPDATE request from a neighbor, you need to wait until he sends it. By the way, you can disable the feature on Cisco with a hidden command:
neighbor <peer-ip> dont-capability-negotiate
There is an undocumented feature of Cisco - a 30-second timer, which is triggered by a change in BGP policies. After changing the policies, in 30 seconds the process of updating routes using one of the above technologies will start. I could not find a documented description of this timer, but there is a mention of it in BUG CSCvi91270 . You can learn about its availability in practice,
after making changes in the lab and looking in debug for UPDATE requests to the neighbor or the soft-reconfiguration process . (If there is additional information on the topic - you can leave in the comments)
For Soft-Reconfiguration , the timer works like this:
2901-NOC-4.2(config)#no ip prefix-list pl-test seq 10 permit 10.5.5.0/26 2901-NOC-4.2(config)#do sh clock 16:53:31.117 Tue Sep 24 2019 Sep 24 16:53:59.396: BGP(0): start inbound soft reconfiguration for Sep 24 16:53:59.396: BGP(0): process 10.5.5.0/26, next hop 10.0.0.1, metric 0 from 10.0.0.1 Sep 24 16:53:59.396: BGP(0): Prefix 10.5.5.0/26 rejected by inbound route-map. Sep 24 16:53:59.396: BGP(0): update denied, previous used path deleted Sep 24 16:53:59.396: BGP(0): no valid path for 10.5.5.0/26 Sep 24 16:53:59.396: BGP(0): complete inbound soft reconfiguration, ran for 0ms Sep 24 16:53:59.396: BGP: topo global:IPv4 Unicast:base Remove_fwdroute for 10.5.5.0/26 2901-NOC-4.2(config)#
For Route-Refresh from the neighbor’s side like this:
2801-RTR (config-router)# *Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 rcv REFRESH_REQ for afi/sfai: 1/1 *Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 start outbound soft reconfig for afi/safi: 1/1
If Route-Refresh is not supported by one of the peers and soft-reconfiguration inbound is not enabled, then route updates by the new policy will not automatically happen.
So, prefix-list was deleted, the connection remained, after 30 seconds it disappeared. The script managed to change the config, check the connection, and save the config. The fall from the script was not immediately connected, against the background of a large number of objects.
All of this could easily be avoided by testing, partial replication of settings. There was an understanding that automation should be centralized and controlled.
The systems we need and their connections
A brief conclusion from the spoiler is to better systematize and control the process of mass delivery of configurations so as not to come to mass delivery of errors in configurations.
- DevOps: 50ms 4 - : ", !@#$%"
The scheme we arrived at consists of “business” master data blocks, “network” master data blocks, network infrastructure monitoring systems, configuration delivery systems, version control systems with a testing unit.
All we need is Data
First we need to know what objects are in the company.
SAP - ERP company system. Data on almost all objects is there, or rather, on all stores and distribution centers. As well as there is data on equipment that passed through an IT warehouse with inventory numbers, which will also be useful to us in the future. Only offices are missing, they are not started in the system. We are trying to solve this problem in a separate process, starting from the moment of opening, we need a connection on each object, and we select the settings for communication, so somewhere at this moment we need to create master data. But data insufficiency is a separate topic, it is better to put this description in a separate article if there is interest in this.
HPSM - a system containing a common CMDB for IT, incident management, change management. Since the system is common to all IT, it should have all IT equipment, including network equipment. This is the place where we will add all the final data over the network. With incident and change management, we plan to interact from monitoring systems in the future.
We know what objects we have, enrich them with data over the network. For this purpose, we have two systems - IPAM from SolarWinds and our own CMDB.noc system.
IPAM - storage of IP subnets, the most correct and correct data on the IP address ownership in the company should be here.
CMDB.noc is a database with a WEB interface where static data on network equipment is stored - routers, switches, access points, as well as providers and their characteristics. Under static means that their change is carried out only with the participation of man. In other words, autodiscovering does not make changes to this database; we need it to understand what “should” be installed on the object. Its base is needed as a buffer between the productive systems that the entire company works with and internal network tools. Accelerates the development, adding the necessary fields, new relationships, adjusting parameters, etc. Plus, this solution is not only in the speed of development, but also in the presence of those relationships between the data that we need, without compromise. As a mini-example, we use several exid in the database for data communication between IPAM, SAP and HPSM.
As a result, we received complete data on all objects, with attached network equipment and IP addresses. Now we need configuration templates, or network services that we provide at these sites.
Single source of truth
Here, we just reached the application of the first NaaC principle - storing target configurations in the repository. In our case, this is Gitlab. The choice for us was simple:
- Firstly, we already have this tool in our company, we did not need to deploy it from scratch
- Secondly, it is quite suitable for all our current and future tasks on network infrastructure
In Gitlab, the main interesting part of automation will take place - the process of changing the configuration standard or, more simply, the template.
Standard Change Process Example
One of the types of objects that we have is the Pyaterochka store. There, a typical topology consists of one router and one / two switches. The template configuration file is stored in Gitlab, in this part everything is simple. But that's not quite NaaC.Now let's say a new project comes to us. The tasks for the new IT project are to make a pilot in a certain volume of stores. According to the results of the pilot - if successful, make a replication for all objects of this type; otherwise collapse the pilot without performing a replication.
This process fits very well into the Git logic:
- For a new project, we are creating a Branch, where we make changes to the configurations.
- In Branch we also keep a list of objects on which this project is being piloted.
- If successful, we make a merge-request in the master branch, which will need to be replicated to the prod network
- In case of failure, either leave Branch for history, or simply delete
In a first approximation - even without automation, it is a very convenient tool for working together on a network configuration. Especially if you imagine that three or more projects came along at the same time. When the time comes for the release of projects in prod, you will need to resolve all configuration conflicts in the merge-requests and check that the settings are not mutually exclusive. And this is very convenient to do in git.
Plus, this approach adds us the flexibility to use the Gitlab CI / CD tools to test configurations virtually, to automate the delivery of configurations to a test bench or a pilot group of objects. // And even on prod if you want.
Deploying configuration to any environment
Initially, the main goal was precisely the mass delivery of configurations, as a tool that very clearly allows you to save engineers' time and speed up configuration tasks. For this, even before the start of the great activity “Network as a Code”, we wrote a python solution for connecting to equipment either to collect equipment configurations or to configure it. This is netmiko , this is pysnmp , this is jinja2 , etc.
But it’s time for us to divide the bulk configuration into several subspecies:
- Delivery of configurations to test and pilot zonesThis item is based on Gitlab CI, which allows you to enable configuration delivery to the pilot and test zones in the pipeline.
- Duplication of configurations in prod
- A separate item, most often the replication to 38k devices takes place in several waves - increasing volume - to monitor the situation in prod. Plus, work of this magnitude requires coordination of the work, therefore it is better to start this process by hand. For this, it is convenient to use Ansible + -AWX and fasten the dynamic compilation of inventory from our master data systems to it.
- As an addition, this is a convenient solution when you need to give the second line the launch of pre-configured playbooks that perform complex and important operations, such as switching traffic between sites.
- Data collection
- Autodiscover network devices
- Backup configurations
- Check connectivity
We allocated this task in a separate block, as there are times when someone suddenly dismantled a switch or installed a new device, but we did not know about this in advance. Accordingly, this device will not be in our master data and will fall out of the process of configuration delivery, monitoring, and, in general, operational work. It happens that the equipment was installed legitimately, but the configuration was "poured" incorrectly and, for some reason, ssh , snmp , aaa or non-standard passwords for access do not work there. To do this, we have python to try all possible legacy connection methods that we could have in the company, make brute-force for all old passwords, and all in order to get to the piece of iron and prepare it for work with ansible and monitoring .
There is a simple way - to make several inventory files for ansible, where to describe all the possible data for connections (all types of vendors with all possible username / password pairs) and run a playbook for each inventory variant. We hoped for a better solution, but at the RedHat conference, Ansible architect advised the same way. It is generally assumed that you know in advance what you are connecting to.
We wanted a universal solution - when removing a backup, look for new equipment and, if found, add it to all the necessary systems. Therefore, we choose a solution in python - know what could be more beautiful than a program that itself can detect a network piece of hardware to connect to it, regardless of what is configured on it (within reasonable limits, of course), configure as needed, remove the configuration and, at the same time, Add API data to the required systems.
Verification like Monitoring
One of the tasks of automation is, of course, to find out what fell out of this automation. Not all 38k are configured perfectly the first time, it even happens that someone sets up the equipment with their hands. And you need to track these changes and restore
There are three approaches to verifying configuration compliance with the standard:
- Doing the check once a period - unload the current state, check against the target and correct the identified deficiencies.
- Without checking anything, once a period - roll out the target configurations. True, there is a risk of breaking something - maybe there wasn’t everything in the target configuration.
- A convenient approach is when differences from the target configuration in Single Source of Truth are considered alerts and are monitored by the monitoring system. This includes: a mismatch with the current configuration standard, a difference between the hardware and the one specified in the master data, a mismatch with the data in IPAM .
In the third case, an option appears to transfer this work to the incident management (OS), so that the inconsistencies are eliminated in small portions throughout the entire time than once by emergency.
Zabbix , which I wrote about earlier in the article “How we monitored 14,000 objects”, is our distributed objects monitoring system where we can make any triggers and alerts that we can think of. Since writing the last article, we have upgraded to Zabbix 4.0 LTS .
Based on Web Zabbix, we made an update to our network support portal, where now you can find all the information on an object from all our systems on one screen, as well as run scripts to check for frequently occurring problems.
We also introduced a new feature - for us, Zabbix has become, in some way, a CRON for launching scheduled scripts, such as system integration scripts, autodiscover scripts. This is really convenient when you need to look at the current scripts and when and where they run, without checking all the servers. True, for scripts that run for more than 30 seconds, you need a launcher that launches them without waiting for the end. Fortunately, it is simple:
launcher.sh
#!/bin/bash nohup $* > /dev/null 2>/dev/null & echo $(date) Started job for $*
Splunk is a solution that allows you to collect event logs from network equipment, and this can also be used to monitor automation. For example, collecting a configuration backup, a python script generates a LOG message CFG-5-BACKUP , a router or switch sends a message to Splunk, in which we count the number of messages of this type from network equipment. This allows us to track the amount of equipment that the script has detected. And we see how many pieces of iron were able to report this to Splunk and verify that messages from all the pieces of iron have arrived.
Spectrum is a comprehensive system that we use to monitor critical objects, a rather powerful tool that helps us a lot in solving critical network incidents. In automation, we use it only pulling data from it, it is not open-source , so the possibilities are somewhat limited.
The cherry on the cake
Using systems with master data on equipment, we can think about creating ZTP, or Zero Touch Provisioning. Like a button "auto-tuning", but only without a button.
We have all the necessary data from the previous blocks - we know the object, its type, what equipment is there (vendor and model), what are the addresses (IPAM), what is the current configuration standard (Git). By putting them all together, we can at least prepare a configuration template for uploading to the device, it will be more like One Touch Provisioning, but sometimes more is not required.
True Zero Touch needs a way to automatically deliver configurations to unconfigured hardware. Moreover, it is desirable regardless of the vendor. There are several working options - a console server, if all the equipment goes through the central warehouse, mobile console solutions, if the equipment arrives immediately. We are only working on these solutions, but as soon as there is a working option, we can share it.
Conclusion
In total, in our concept of Network as a Code , there were 5 main milestones:
- Master data (communication of systems and data with each other, API of systems, data sufficiency for support and launch)
- Monitoring of data and configurations (autodiscovering of network devices, checking for the relevance of the configuration at the facility)
- Version control, testing and piloting of configurations (Gitlab CI / CD as applied to the network, network configuration testing tools)
- Configuration delivery (Ansible, AWX, python scripts for connection)
- Zero Touch Provisioning (What data is needed, how to build a process so that it is, how to connect to a non-configured piece of hardware)
It did not work to fit everything into one article, each item is worthy of a separate discussion, we can talk about something now, about something when we check the solutions in practice. If you are interested in any of the topics - at the end there will be a survey where you can vote for the next article. If the topic is not included in the list, but it is interesting to read about it, leave a comment as soon as we can, be sure to share our experience.
Special thanks to Virilin Alexander ( xscrew ) and Sibgatulin Marat ( eucariot ) for the reference visit in the fall of 2018 to the yandex cloud and the story about the automation in the cloud network infrastructure. After him, we got inspiration and a lot of ideas about the use of automation and NetDevOps in the infrastructure of X5 Retail Group.
All Articles