GIT from the inside: introduction (translation)
Hello, Habr! I present to you the translation of the article "Git for Computer Scientists" by Tommi Virtanen.
GIT Inside Out: An Introduction
From myself: Periodically I read articles about how various popular technologies are arranged under the hood, I came across this material . The article seemed interesting by the presence of simple and understandable schemes, which are perceived much better than sheets of a dull text. I decided to translate into Russian. Images taken from the original.
Who will be interested and possibly useful: people who work with Git every day (i.e., every second, if not the first software developer), and who want to better understand the mechanism of its work.
Note: for a better understanding of the article, one should have an idea of such a beast as a directed acyclic graph (DAG) .
Object storage
The Git object repository is, roughly speaking, a DAG containing various types of objects. Objects are stored in compressed form and identified by SHA-1 hashes (this is NOT a hash of the contents of the file that represents the object, but of its presentation in Git).
Blob

Blob is a simple object, just a collection of bytes. It could be a file, a symbolic link, or whatever. The semantics are determined by the object that points to this blob.
Tree
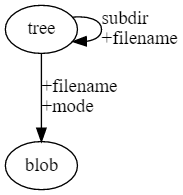
Objects of the "tree" type describe directories (directories). They can point to blobs that store the contents of files, as well as to other trees, thus creating a subdirectory structure.
If a node points to another node in the DAG, they say that it depends on that node, i.e. cannot exist without it. No one points to can be deleted using the garbage collection ( git gc command) or restored using the git fsck --lost-found command .
Commit
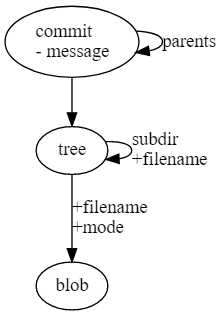
Commit refers to a tree representing the state of files in Git at the time the commit was created. Also, commit can refer to other commits that are its parents:
- If the commit has more than 1 parent, this means that it describes the merge operation (merge)
- If the commit has no parents, this is the so-called initial (initial) commit (i.e. the first in the repository)
- It is also possible that there are more than 1 initial commit in the repository - this usually means merging two separate repositories
The body of the commit object is a commit message .
Refs (links)
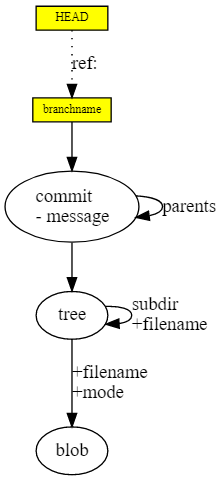
Links (or headings, or branches) are similar to stickers with notes pasted on DAG nodes, some kind of notes, or bookmarks - “I work here”. Unlike DAG nodes, which cannot be changed, and can only be added, links can be moved as you like. They are not stored in the history and are not transferred directly between repositories.
The git commit command adds a new node to the DAG and moves a bookmark to it for the current branch.
Links are in the heads / branchname namespace , but part of the heads can be omitted.
The HEAD link stands apart - it does not point to a node, but to another link - this is a pointer to the current active branch.
Remote refs

These are, roughly speaking, stickers of a different color. The difference is that remote links are in a different namespace and are also managed by a remote server. To update them, use the git fetch command.
Tag

A tag is a combination of a DAG node and a sticker (another color). The tag points to commit, and includes an optional message and GPG signature. A sticker (link) is a simple way to access a tag, and in case of loss, it can be restored with the git fsck --lost-found command.
Thus, a Git repository is a combination of DAG and links.
Story
Now, knowing how Git stores version history, let’s try to depict various operations, as well as understand how Git differs from systems representing history as linear changes for each branch.
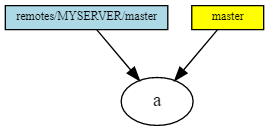
The simplest repository. We just copied ( git clone ) the remote repository with a single commit.
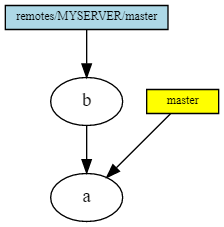
Here we read ( git fetch ) the remote repository and got 1 new commit, but have not merged it with our branch yet.
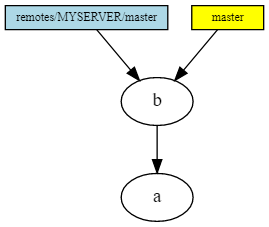
Here's what happens after running the git merge remotes / MYSERVER / master command. Since the merge was performed as fast forward (there were no local commits in our local branch), the following happened: the files of our working copy changed, and the pointer to the branch also moved.
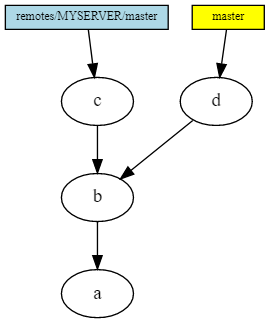
Run git commit locally and then git fetch . Now we have both local and remote commit. Obviously, you need a merge .
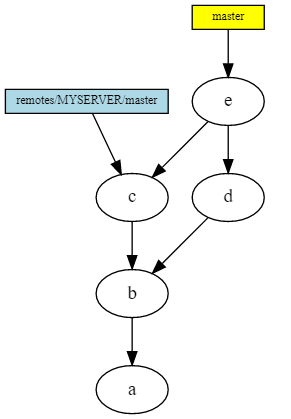
This is the result of the git merge remotes / MYSERVER / master command. Since we had a local commit, this is not fast forward, and a separate commit is created in the DAG for this merge. Notice - he has 2 parent commit.

This is how our tree will look after several commit-s, in both branches (local and remote) + merge. You can clearly see how Git DAG captures the entire history of our actions.
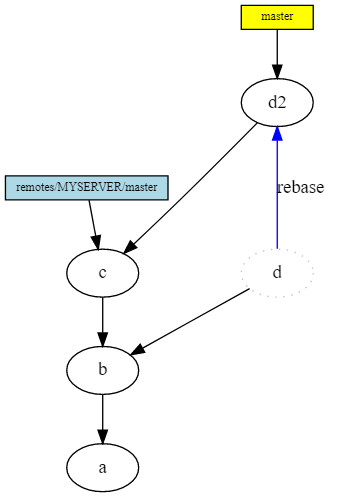
However, such a story is difficult to read. If you have not published your branch yet, or have agreed with other team members that they should not build on it in their work, you have an alternative: you can rebase your branch. In this case, your commit is replaced with another commit, with a different parent, to which the link to the branch also moves.
In this case, your old commit-s remain in the DAG until garbage collection. In principle, this is a kind of insurance, in case something goes wrong. If you still have links to old commit, then they will be saved as long as the links exist.
You should NOT rebase for branches on top of which other people have created commit. You can restore them (and not even very difficult), but this adds confusion and a lot of useless work.
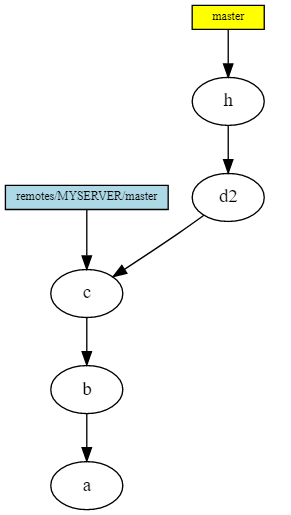
Here's how it looks after garbage collection (or ignoring inaccessible commits), and creating a new commit on top of the branch to which rebase was applied.

Also, with rebase, you can move multiple commit s at the same time.
That's all. I hope the material will be useful.
All Articles