Edition-Based Redefinition: is it possible in production?
Hello! My name is Antonina, I am an Oracle developer of the Sportmaster Lab IT division. I have been working here for only two years, but thanks to a friendly team, a close-knit team, a mentoring system, corporate training, the critical mass has accumulated when I want to not only consume knowledge, but also share my experience.

So, Edition-Based Redefinition. Why did we even have such a need to study this technology, and here the term "high availability" and how Edition-Based Redefinition will help us as Oracle developers save time?
What is proposed as a solution by Oracle? What is going on in the backyard when applying this technology, what problems we encountered ... In general, there are many questions. I will try to answer them in two posts on the topic, and the first of them is already under the cut.
Each development team, creating its own application, seeks to make the most accessible, most fault-tolerant, most reliable algorithm. Why do we all strive for this? Probably not because we are so good and we want to release a cool product. More precisely, not only because we are so good. It is also important for business. Despite the fact that we can write a cool algorithm, cover it with unit tests, see that it is fault-tolerant, we still (the Oracle developers) have a problem - we are faced with the need to upgrade our applications. For example, our colleagues in the loyalty system are forced to do this at night.
If this happened on the fly, users would see a picture: “Please excuse me!”, “Do not be sad!”, “Wait, we have updates and technical work here.” Why is this so important for business? But it’s very simple - for a long time, business has been laying in its losses not only losses of some real goods, material values, but also losses from downtime of infrastructure. For example, according to Forbes magazine, back in 13, one minute of Amazon service downtime was then worth 66 thousand dollars. That is, in half an hour the guys lost almost $ 2 million.
It is clear that for medium and small businesses, and not for such a giant as Amazon, these quantitative characteristics will be much less, but nevertheless, in relative terms, this remains a significant evaluation characteristic.
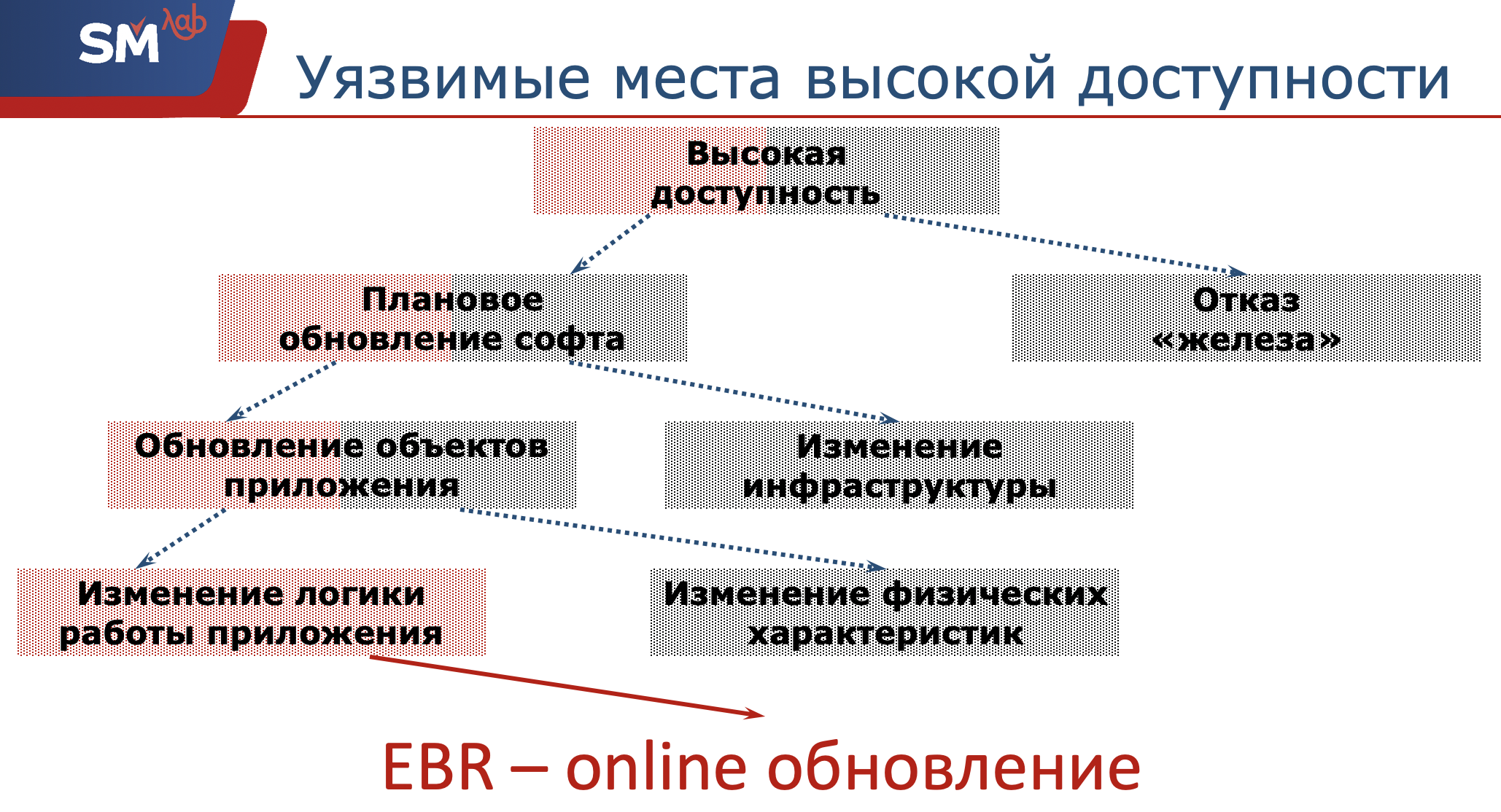
So, we need to ensure the high availability of our application. What are some potentially dangerous places Oracle developers have for this accessibility?
First things first, our hardware may fail. We, as developers, are not responsible for this. Network administrators must ensure that the server and structural objects are operational. What we are leading to is a software upgrade. Again, scheduled software updates can be divided into two classes. Or we are changing some kind of infrastructure, for example, updating the operating system on which the server is spinning. Either we decided to move to the new release of Oracle (it would be nice if we successfully moved to it :)) ... Or, the second class, this is what we have the maximum relation to - this is updating the objects of the application that we are developing with you.
Again, this update can be divided into two more classes.
Or we are changing some physical characteristics of this object (I think that every Oracle developer sometimes encountered the fact that his index fell, he had to rebuild the index on the fly). Or, let's say we introduced new sections in our tables, that is, no stop will occur. And that very problematic place is a change in the logic of the application.
So what does Edition-Based Redefinition have to do with it? And this technology - it’s just about how to update the application online, on the fly, without affecting the work of users.

What are the requirements for this online update? We must do this unnoticed by the user, that is, everything must remain in working condition, all applications. Provided that such a situation may occur when a user sat down, started working and remembered sharply that he had an urgent meeting, or that he needed to take the car to the service. He got up, ran out because of his workplace. And at that time, we somehow updated our application, the logic of work changed, new users have already connected to us, the data has started to be processed in a new way. So, we need to ultimately ensure the exchange of data between the original version of the application and the new version of the application. Here they are, two requirements that are put forward for online updates.

What is proposed as a solution? Starting with version 11.2 Release Oracle, Edition-Based Redefenition technology is introduced and concepts such as edition, editionable objects, editioning view, cross-edition trigger are introduced. We allowed ourselves such a translation as “versioning”. In general, EBR technology with some stretch could be called versioning DBMS objects inside the DBMS itself.
So what is Edition as an entity?
This is a kind of container inside which you can change and set the code. Inside your own scope, inside your own version. In this case, the data will be changed and written only to those structures that are visible in the current Edition. Versioning representations will be responsible for this, and we will consider their work further.

This is what the technology looks like outside. How does this work? For starters, at the code level. We will have our original application, version 1, in which there are some algorithms that process our data. When we understand that we need to upgrade, the following happens when creating a new edition: all the objects that process the code are inherited in the new edition ... At the same time, in this newly created sandbox, we can have fun as we like, invisibly to the user: we can change which work functions, procedures; change the package; we can even refuse to use any object.
What will happen? The original version remains unchanged, it remains available to the user and all the functionality is available. In the version that we created, in the new edition, those objects that have not been changed remain unchanged, that is, inherited from the original version of the application. With the block that we have touched upon, objects are updated in the new version. And of course, when you delete an object, it is not available to us in the new version of our application, but it remains functional in the original version. That's how simple it works at the code level.

What happens to data structures and what does the versioning view have to do with it?

Since by data structures we mean a table, and a versioning view, this is, in fact, a shell (I called for myself the ethological “look-up” of our table), which is a projection onto the original columns. When we understand that we need to change the operation of our application, and, say, somehow add columns to the table, or even prohibit their use, we create a new versioning view in our new version.

Accordingly, in it we will use only the set of columns that we need, which we will process. So, in the initial version of the application, data is written to the set that is defined in this scope. The new application will write to the set of columns that is defined in its scope.

The structures are clear, but what happens to the data? And how all this is interconnected, We had data stored in the original structures. When we understand that we have a certain algorithm that allows us to convert data from the original structure and decompose this data into a new structure, this algorithm can be put into the so-called cross-version triggers. They are just aimed at seeing structures from different versions of the application. That is, subject to the availability of such an algorithm, we can hang it on a table. In this case, data will be transformed from the original structures to new ones, and progressive forward triggers will be responsible for this. Provided that we need to ensure the transfer of data to the old version, again, based on some kind of algorithm, reverse triggers will be responsible for this.
What happens when we decide that our data structure has changed and we are ready to work in parallel mode both for the old version of the application and for the new version of the application? We can simply initialize the filling of new structures with some idle update. After that, both of our versions of the application become available for use by the user. The functionality remains for old users from the old version of the application; for new users, the functionality will be from the new version of the application.
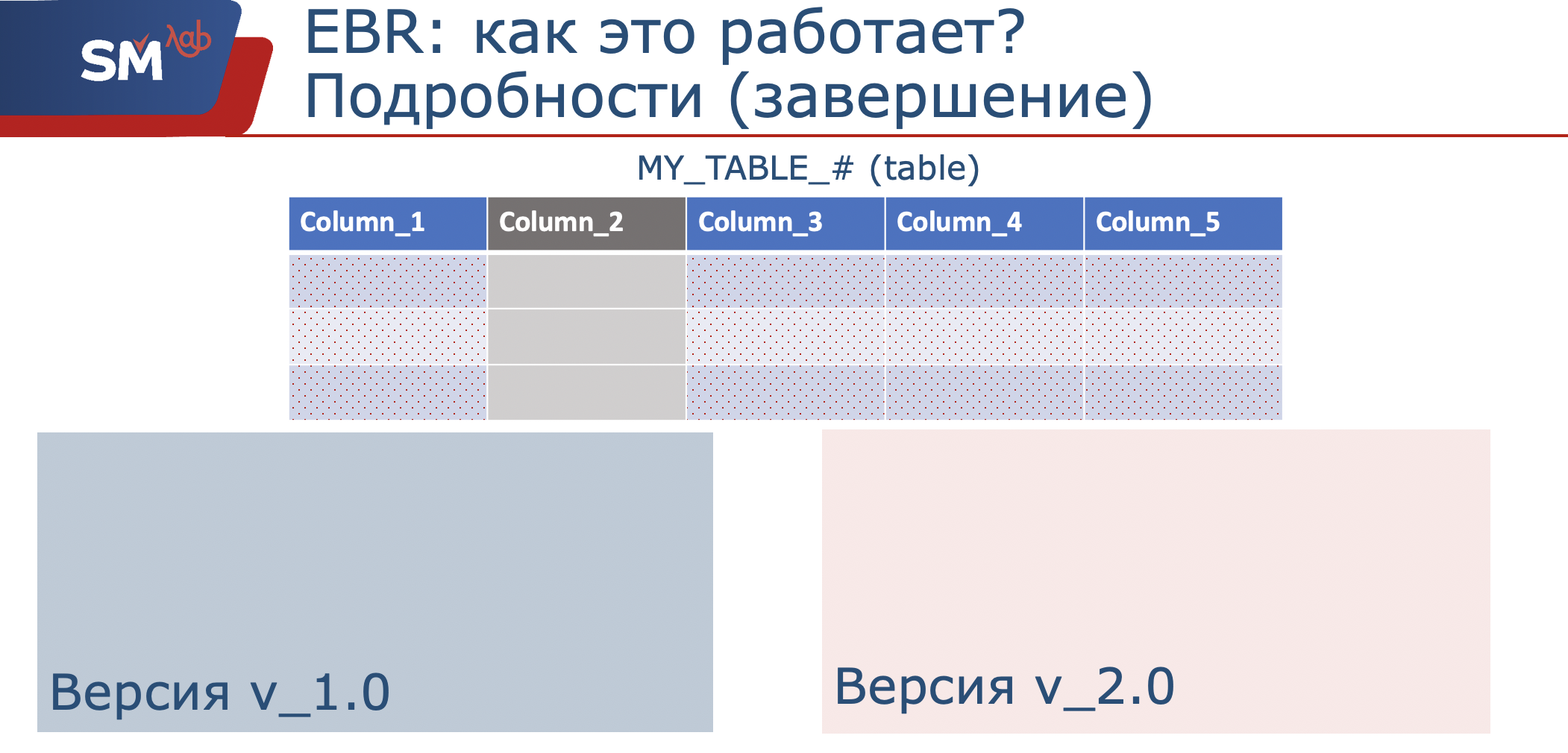
When we realized that users from the old application all disconnected, this version could be hidden from use. Perhaps even the data structure has been changed. We remember that with us the versioning view in the newly created version will already look only at the set of columns 1, 3,4,5. Well and accordingly, if we do not need this structure, it can be deleted. Here is a brief summary of how it works.

What are the restrictions imposed? That is, well done Oracle, excellent Oracle, excellent Oracle: they came up with a cool thing. The first limitation at the moment is objects of the versioned type, these are PL / SQL objects, that is, procedures, packages, functions, triggers, and so on. Synonyms are versioned and views are versioned.
What is not versioned and will never be versioned are tables and indexes, materialized views. That is, in the first version, we only change metadata and we can store copies of them as much as you want ... in fact, a limited number of copies of this metadata, but more on that later. The second concerns user data, and their replication would require a lot of disk space, which is not logical and is very expensive.

The next limitation is that the schema objects will be fully versioned if and only if they belong to the version-authorized user. In fact, these privileges for the user are just some kind of mark in the database. You can grant these permissions with the usual command. But I draw your attention that this action is irreversible. Therefore, let's not immediately roll up our sleeves, type all this on the battle server, and first we will test.
The next limitation is that nonversioned objects cannot depend on versioned ones. Well, that’s quite logical. At a minimum, we will not understand which edition, which version of the object to look at. On this point, I would like to draw attention, because we had to fight this moment.
Further. Versioned views belong to the schema owner, table owner, and only in each version. In essence, a versioned view is a table wrapper, so it’s clear that it should be unique in every version of the application.
What is also important, the number of versions in the hierarchy can be 2000. Most likely, this is due to the fact that you do not load the dictionary somehow heavily. I said initially that objects, when creating a new edition, are inherited. Now this hierarchy is built exclusively linear - one parent, one descendant. Perhaps there will be some kind of tree structure, I see some prerequisites for this in the fact that you can set the version creation command as an inheritor from a particular edition. This is currently a strictly linear hierarchy, and the number of links in this chain is 2000.
It is clear that with some frequent upgrades of our application, this number could be exhausted or overstepped, but starting with the 12th release of Oracle, the extreme editions created in this chain can be cut under the condition that they are no longer used.

I hope you now understand roughly how this works. If you decide - “Yes, we want to touch it” - what needs to be done to switch to using this technology?
First things first, you need to determine the use strategy. What is it about? Understand how often our table structures change, whether we need to use versioned views, especially if we need cross-versioned triggers to ensure data changes. Or we will only version our PL / SQL code. In our case, when we were testing, we watched that we still have tables changing, so we will probably use versioned views as well.
Further, naturally, the selected scheme is granted versioned privileges.
After that, we rename the table. Why is this done? Just to protect our PL / SQL code objects from modification of tables.
We decided to throw a sharp symbol at the end of our tables, given the 30-character limit. After that, versioning views are created with the original table name. And already they will be used inside the code. It is important that in the first version we are moving to, the versioned view is a complete set of columns in the source table, because PL / SQL code objects can access all of these columns exactly the same.
After that, we outweigh the DML triggers from tables to versioned views (yes, versioned views allow us to hang triggers on them). Perhaps we revoke the grants from the tables and give them to the newly created views ... In theory, all these points are enough, we just have to recompile the PL / SQL code and the dependent views.
And-and-and-and-and ... Naturally, tests, tests, and as many tests as possible. Why tests? It could not be so simple. What did we stumble about?
This is what my second post will be about.
So, Edition-Based Redefinition. Why did we even have such a need to study this technology, and here the term "high availability" and how Edition-Based Redefinition will help us as Oracle developers save time?
What is proposed as a solution by Oracle? What is going on in the backyard when applying this technology, what problems we encountered ... In general, there are many questions. I will try to answer them in two posts on the topic, and the first of them is already under the cut.
Each development team, creating its own application, seeks to make the most accessible, most fault-tolerant, most reliable algorithm. Why do we all strive for this? Probably not because we are so good and we want to release a cool product. More precisely, not only because we are so good. It is also important for business. Despite the fact that we can write a cool algorithm, cover it with unit tests, see that it is fault-tolerant, we still (the Oracle developers) have a problem - we are faced with the need to upgrade our applications. For example, our colleagues in the loyalty system are forced to do this at night.
If this happened on the fly, users would see a picture: “Please excuse me!”, “Do not be sad!”, “Wait, we have updates and technical work here.” Why is this so important for business? But it’s very simple - for a long time, business has been laying in its losses not only losses of some real goods, material values, but also losses from downtime of infrastructure. For example, according to Forbes magazine, back in 13, one minute of Amazon service downtime was then worth 66 thousand dollars. That is, in half an hour the guys lost almost $ 2 million.
It is clear that for medium and small businesses, and not for such a giant as Amazon, these quantitative characteristics will be much less, but nevertheless, in relative terms, this remains a significant evaluation characteristic.
So, we need to ensure the high availability of our application. What are some potentially dangerous places Oracle developers have for this accessibility?
First things first, our hardware may fail. We, as developers, are not responsible for this. Network administrators must ensure that the server and structural objects are operational. What we are leading to is a software upgrade. Again, scheduled software updates can be divided into two classes. Or we are changing some kind of infrastructure, for example, updating the operating system on which the server is spinning. Either we decided to move to the new release of Oracle (it would be nice if we successfully moved to it :)) ... Or, the second class, this is what we have the maximum relation to - this is updating the objects of the application that we are developing with you.
Again, this update can be divided into two more classes.
Or we are changing some physical characteristics of this object (I think that every Oracle developer sometimes encountered the fact that his index fell, he had to rebuild the index on the fly). Or, let's say we introduced new sections in our tables, that is, no stop will occur. And that very problematic place is a change in the logic of the application.
So what does Edition-Based Redefinition have to do with it? And this technology - it’s just about how to update the application online, on the fly, without affecting the work of users.
What are the requirements for this online update? We must do this unnoticed by the user, that is, everything must remain in working condition, all applications. Provided that such a situation may occur when a user sat down, started working and remembered sharply that he had an urgent meeting, or that he needed to take the car to the service. He got up, ran out because of his workplace. And at that time, we somehow updated our application, the logic of work changed, new users have already connected to us, the data has started to be processed in a new way. So, we need to ultimately ensure the exchange of data between the original version of the application and the new version of the application. Here they are, two requirements that are put forward for online updates.
What is proposed as a solution? Starting with version 11.2 Release Oracle, Edition-Based Redefenition technology is introduced and concepts such as edition, editionable objects, editioning view, cross-edition trigger are introduced. We allowed ourselves such a translation as “versioning”. In general, EBR technology with some stretch could be called versioning DBMS objects inside the DBMS itself.
So what is Edition as an entity?
This is a kind of container inside which you can change and set the code. Inside your own scope, inside your own version. In this case, the data will be changed and written only to those structures that are visible in the current Edition. Versioning representations will be responsible for this, and we will consider their work further.
This is what the technology looks like outside. How does this work? For starters, at the code level. We will have our original application, version 1, in which there are some algorithms that process our data. When we understand that we need to upgrade, the following happens when creating a new edition: all the objects that process the code are inherited in the new edition ... At the same time, in this newly created sandbox, we can have fun as we like, invisibly to the user: we can change which work functions, procedures; change the package; we can even refuse to use any object.
What will happen? The original version remains unchanged, it remains available to the user and all the functionality is available. In the version that we created, in the new edition, those objects that have not been changed remain unchanged, that is, inherited from the original version of the application. With the block that we have touched upon, objects are updated in the new version. And of course, when you delete an object, it is not available to us in the new version of our application, but it remains functional in the original version. That's how simple it works at the code level.
What happens to data structures and what does the versioning view have to do with it?
Since by data structures we mean a table, and a versioning view, this is, in fact, a shell (I called for myself the ethological “look-up” of our table), which is a projection onto the original columns. When we understand that we need to change the operation of our application, and, say, somehow add columns to the table, or even prohibit their use, we create a new versioning view in our new version.
Accordingly, in it we will use only the set of columns that we need, which we will process. So, in the initial version of the application, data is written to the set that is defined in this scope. The new application will write to the set of columns that is defined in its scope.
The structures are clear, but what happens to the data? And how all this is interconnected, We had data stored in the original structures. When we understand that we have a certain algorithm that allows us to convert data from the original structure and decompose this data into a new structure, this algorithm can be put into the so-called cross-version triggers. They are just aimed at seeing structures from different versions of the application. That is, subject to the availability of such an algorithm, we can hang it on a table. In this case, data will be transformed from the original structures to new ones, and progressive forward triggers will be responsible for this. Provided that we need to ensure the transfer of data to the old version, again, based on some kind of algorithm, reverse triggers will be responsible for this.
What happens when we decide that our data structure has changed and we are ready to work in parallel mode both for the old version of the application and for the new version of the application? We can simply initialize the filling of new structures with some idle update. After that, both of our versions of the application become available for use by the user. The functionality remains for old users from the old version of the application; for new users, the functionality will be from the new version of the application.
When we realized that users from the old application all disconnected, this version could be hidden from use. Perhaps even the data structure has been changed. We remember that with us the versioning view in the newly created version will already look only at the set of columns 1, 3,4,5. Well and accordingly, if we do not need this structure, it can be deleted. Here is a brief summary of how it works.
What are the restrictions imposed? That is, well done Oracle, excellent Oracle, excellent Oracle: they came up with a cool thing. The first limitation at the moment is objects of the versioned type, these are PL / SQL objects, that is, procedures, packages, functions, triggers, and so on. Synonyms are versioned and views are versioned.
What is not versioned and will never be versioned are tables and indexes, materialized views. That is, in the first version, we only change metadata and we can store copies of them as much as you want ... in fact, a limited number of copies of this metadata, but more on that later. The second concerns user data, and their replication would require a lot of disk space, which is not logical and is very expensive.
The next limitation is that the schema objects will be fully versioned if and only if they belong to the version-authorized user. In fact, these privileges for the user are just some kind of mark in the database. You can grant these permissions with the usual command. But I draw your attention that this action is irreversible. Therefore, let's not immediately roll up our sleeves, type all this on the battle server, and first we will test.
The next limitation is that nonversioned objects cannot depend on versioned ones. Well, that’s quite logical. At a minimum, we will not understand which edition, which version of the object to look at. On this point, I would like to draw attention, because we had to fight this moment.
Further. Versioned views belong to the schema owner, table owner, and only in each version. In essence, a versioned view is a table wrapper, so it’s clear that it should be unique in every version of the application.
What is also important, the number of versions in the hierarchy can be 2000. Most likely, this is due to the fact that you do not load the dictionary somehow heavily. I said initially that objects, when creating a new edition, are inherited. Now this hierarchy is built exclusively linear - one parent, one descendant. Perhaps there will be some kind of tree structure, I see some prerequisites for this in the fact that you can set the version creation command as an inheritor from a particular edition. This is currently a strictly linear hierarchy, and the number of links in this chain is 2000.
It is clear that with some frequent upgrades of our application, this number could be exhausted or overstepped, but starting with the 12th release of Oracle, the extreme editions created in this chain can be cut under the condition that they are no longer used.
I hope you now understand roughly how this works. If you decide - “Yes, we want to touch it” - what needs to be done to switch to using this technology?
First things first, you need to determine the use strategy. What is it about? Understand how often our table structures change, whether we need to use versioned views, especially if we need cross-versioned triggers to ensure data changes. Or we will only version our PL / SQL code. In our case, when we were testing, we watched that we still have tables changing, so we will probably use versioned views as well.
Further, naturally, the selected scheme is granted versioned privileges.
After that, we rename the table. Why is this done? Just to protect our PL / SQL code objects from modification of tables.
We decided to throw a sharp symbol at the end of our tables, given the 30-character limit. After that, versioning views are created with the original table name. And already they will be used inside the code. It is important that in the first version we are moving to, the versioned view is a complete set of columns in the source table, because PL / SQL code objects can access all of these columns exactly the same.
After that, we outweigh the DML triggers from tables to versioned views (yes, versioned views allow us to hang triggers on them). Perhaps we revoke the grants from the tables and give them to the newly created views ... In theory, all these points are enough, we just have to recompile the PL / SQL code and the dependent views.
And-and-and-and-and ... Naturally, tests, tests, and as many tests as possible. Why tests? It could not be so simple. What did we stumble about?
This is what my second post will be about.
All Articles