Bisectional division method in testing
Content
Sometimes bugs themselves find us. So we shoved a large row of data - and the system hung. Is it because of 1 million characters that fell? Or didn’t she like a particular one?
Or the file was uploaded to the system and it crashed. From what? Due to name, extension, data inside or sizes? You can push the localization onto the developer, let him think what is bad in the file. But often you can find the reason yourself, and then more accurately describe the problem.
If you find the minimum data to play, then:
- You will save time for the developer - he will not have to connect to the test stand, load the file himself and debut
- The manager will be able to easily assess the priority of the task - is it urgently needed to be fixed, or can the bug wait? While the name "some files fall, xs why" is hard to do ...
- A description of the bug from understanding the cause of the fall will also benefit.
How to find the minimum data for playing a bug? If there are any hints in the logs, apply them. If there are no clues, then the best method is the bisectional division method (also known as the “bisection” or “dichotomy” method).
Method Description
The method is used to find the exact place of the fall:
- Take a falling packet of data.
- Break in half.
- Check half 1
- If it fell, then the problem is there. We work further with her.
- If it does not fall → check half 2.
- Repeat steps 1-3 until one falling value remains.

The method allows you to quickly localize the problem, especially if it is done programmatically. Developers integrate such mechanisms into data processing. And if they don’t build it in, then they themselves suffer later, when the tester comes to them and says, "It falls on this file, but I could not find the exact reason."
Application by testers
Data row
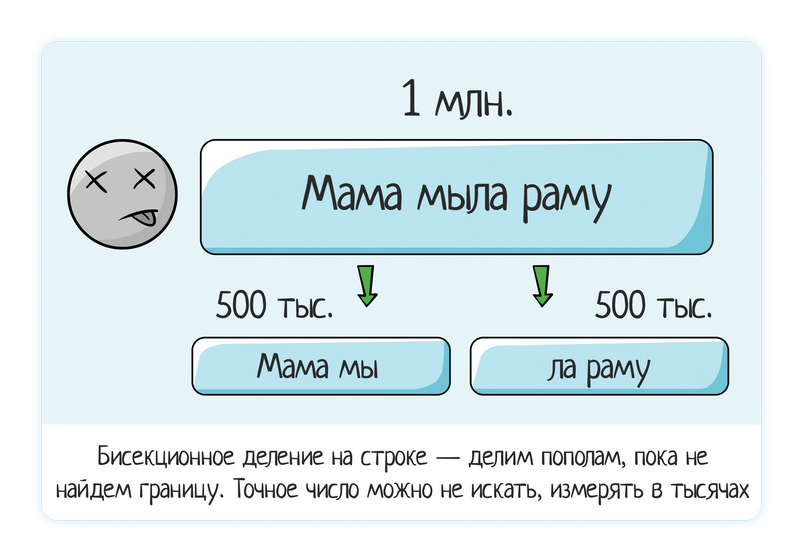
Loaded a line of 1 million data - the system freezes.
We try 500 thousand (divided in half) - it still hangs.
We try 250 thousand - it does not hang, everything is ok.
↓
Hence the conclusion that the problem is somewhere between 250 and 500 thousand. Again, we apply bisectional division.
We try 350 thousand (dividing it “by eye” - it’s quite permissible, you don’t have to run into exact numbers when playing manually) - everything is ok
We try 450 thousand - it’s bad.
We try 400 thousand - it’s bad.
↓
In general, you can already get a bug. It is very rarely required from the tester to report that the border or bug is clearly in the number 286 586. It is quite enough to localize it approximately - 290 thousand.
It’s just one thing to check “10” and immediately “300 thousand”, and it’s completely different to provide more complete information: “up to 10 thousand everything is OK, from 10 to 280 thousand brakes start, already 290 thousand are falling”.
It is clear that when the quantity is measured in thousands, it will take too long to manually search for a specific face. Yes, the developer does not need this. Well, no one wants to waste time in vain.
Of course, if the original problem was on a line with a length of 10-30 characters, you can find the exact border. It’s all in a reasonable relationship to time - if using guesswork or bisectional division you can quickly find the exact value and it is small (up to 100 usually) - we are looking for sure. If the problems are on a large string, more than 1000 → look for approximately.
File
Uploaded a file - crashed! How why? First, we try to analyze for ourselves what could affect what our test tested? This is the main rule chip "first positive, then negative." If you do not try to stuff everything into one test at once:
- Checked a small sample file
- We checked a huge 2GB file, with a bunch of columns, a bunch of columns, plus different variations of the internal data
It will be hard to localize here. And if you separate the checks:
- A lot of lines (but the data is positive and verified earlier)
- Many columns
- Heavy weight
- ...
That is already approximately understandable, what is the reason. For example, it falls on a large number of lines - from 100 thousand. Ok, we are looking for a more accurate border using bisectional division:
- We divided the file into two by 50 thousand, checked the first.
- If you fall, divide it.
- And so, until we find a specific place to fall

If the drop depends on the number of lines, we look for an approximate border: "After 5000 it falls, there are no 4000 thousand." Searching for a specific place (4589) is not necessary. Too long and not worth the time.
This bug was found by students in Dadat . Data files can be loaded there, the system will process and standardize this data: correct typos, determine missing information from directories (KLADR code, FIAS, geo-coordinates, city district, zip code ...).
The girl tried to download a large file and got the result: the system shows a progress bar at 100% load and hangs for more than 30 minutes.
Localization went further - when does the freeze begin? This is important because it affects the priority of the task. What is the typical amount of downloaded files? How often do users ship straight LOTS?
Maybe the system is designed to process thousands of lines, then such a bug is crammed into “Fix it someday”. Or typical downloads - 10-50 thousand lines that process normally, well, that means the bug is not burning, we will fix it a bit later.
Task localization:
- for a file with 50 thousand lines, 15 seconds hang,
- for a file with 100 thousand lines, 30 seconds hang,
- for a file with 150 thousand lines, 1 min hangs,
- for a file with 165 thousand lines, 4 minutes hang
- for a file 172 thousand lines with a 100% full progress bar freezes for more than half an hour
This is where the work of the tester is already done qualitatively. Full information is provided about the operation of the system, on the basis of which the manager can already conclude how urgently it is necessary to fix the bug.
The verification also takes not too much time. You can go or from the end - here we have downloaded 200 thousand lines, and when does the problem begin? We use the bisectional division method!
Or we start with a relatively small number - 50 thousand, gradually increasing (twice, the method of bisectional division, just the opposite). Knowing that everything will be bad at 200 thousand, we understand that there will not be many tests. We checked 50, 100, 150 - for three tests we found an approximate border. And then digging is no longer necessary.
But remember that you also need to test your theory. Is it true that the problem is in the number of lines, and not the data inside the file? Checking this is very easy - create a file with 5,000 lines with a single “positive” value. That value which exactly works which you already checked earlier. If there is no fall, then the matter is unclean =)) It seems that the theory of the number of rows was erroneous and the matter is in the data itself.

Although you can try 10 thousand lines with exactly a positive value. It is possible that the fall will happen again. Just your source file was on several columns. Or there were characters inside that took up more bytes than a positive value ... In general, do not immediately reject the theory of file size or number of lines. Try bisectional division on the contrary - double the file.
But in any case, remember that the more checks are mixed in one, the more difficult it is to localize the bug. Therefore, it is better to immediately test the number of rows or columns on any one positive value. So that you are sure that you are testing the amount of data, not the data itself. Test analysis and all that =)

But what if the problem is not in the number of rows, but in the data itself? And you do not know where exactly. Perhaps you crammed data from the “War and Peace” into a test file, or downloaded a large spreadsheet from somewhere on the Internet ... Or the user found a problem at all - he uploaded his file and everything fell down. He came to support, support came to you: the file is on you, play it.
Further action depends on the situation. If a user’s deadlines are running or money is debited from him, and then the file processing has fallen, then this is a blocker bug. And there is no time to train a localization tester. It’s easier to give the exact-falling file to the developer, let him be free and find the reason himself.
But if you yourself found a mistake, that is, time to dig yourself. Again, not forgetting common sense, as always with localization. At first we tried to draw conclusions ourselves, then went for help. To make a conclusion yourself, you need:
- check the logs, there may be the right answer;
- view the contents of the file: something may catch your eye, that’s the first theory;
- use the bisectional division method.
As a result, instead of the “Falls file, xs why, here’s in the 2GB file attachment” bug, you put a well-thought-out and localized bug: “The file falls if the DD / MM / YYYYY format date is inside”. And then you do not need a 2GB file already, you only need one file for one line and one column!

Application by developers
On a large amount of data, the tester does not look for a clear boundary, because it is unreasonable to do this manually. But developers use the method of bisectional division in the code and can always find a specific place to fall. After all, the system will divide up to victory, and not a person!

For example, we have a mechanism for loading data into the system. It can load as 10 thousand and a million. But this does not matter, since the download is in batches of 200 entries. If something went wrong, the system itself conducts bisectional division. Itself. Until it finds a problem place. Then read in the logs:
- Got 1000 records
- Processed 200 records
- Processed 400 records
- Oops, fell on a pack of 200 records!
- I try to process a pack of size 100
- I try to process a pack of size 50
- I try to process a pack of size 25
...
- Error on such identifiers: the required Email field is not filled
- Processed 600 records
...
Here, of course, further logic also depends on the developer. Either processing stops after encountering an error, or goes further. Stumbled on a pack of 200 entries? We got to the point of finding a bottleneck, marked the record as erroneous, processed the remaining 199, and drove on.
But what if the whole pack falls apart? We marked the record as erroneous, but the remaining 199 were also unable to process. Why? We apply the same method, looking for a new problem. The trick is that you always need to be able to stop on time.

If the number of errors is more than 10-50-100, then it is better to stop the download. It is possible that an upload error occurred in the original system and we received a million “curves” of data. If the system will divide each pack of 200 records in half, and then divide the remaining 199, and so on, then everyone will be bad:
- The log grows from the usual 15 mb to 3 gb and becomes unreadable;
- The system may crash on trying to generate a final error message (I talked about this situation in the BMW Mnemonics section);
- A lot of time is spent searching for all the errors. Yes, the system does it faster than a person, but if you divide a million packs of 200 records, it will take time.
So the brain must be included everywhere - both in manual testing and when writing program code. You must always understand when to stop. Only in the case of manual testing will it be “about to find the border”, and in the development “stop if there are a lot of falls”.
Summary
The method of bisectional division is used to find the exact place of incidence and localization of the bug.
Look for the number and start dividing it in half:
- line length;
- file size;
- file weight;
- number of rows / columns;
- amount of free memory in a mobile phone;
- ...

But remember - someday you have to stop! No need to stop and look for the exact number if it requires thousands of additional tests. But 5-10 minutes can be given to localization.
PS - look for more useful articles on my blog by the tag “useful”
All Articles