CQM - Another Look in Deep Learning for Search Engine Optimization in Natural Language
CQM - Another Look in Deep Learning for Search Engine Optimization in Natural Language
Short Description: Calibrated Quantum Mesh (CQM) is the next step from RNN / LSTM (Recurrent Neural Networks) / Long short-term memory (LSTM)). There is a new algorithm called Calibrated Quantum Mesh (CQM), which promises to increase the accuracy of natural language searches without the use of labeled training data.
A completely new natural language search (NLS) and natural language understanding (NLU) algorithm has been created, which not only surpasses the traditional RNN / LSTM or even CNN algorithms, but is also self-learning and does not require marked data for training.
It sounds too good to be true, but the initial results are impressive. CQM - developed by Praful Krishna and his team at Coseer (San Francisco).
Although the company is still small, they work with several Fortune 500 companies and have begun holding technical conferences.
This is where they hope to prove themselves:
Accuracy: According to Krishna, the average NLS function in a less serious chatbot, as a rule, has an accuracy of only about 70%.
Coseer's initial applications achieved an accuracy of over 95% in returning the correct relevant information. Keywords are not required.
Labeled training data is not required: We all know that labeled training data is a financial and time expense that limits the accuracy of our chat bots.
A few years ago M.D. Anderson abandoned his expensive and years-long experiment with IBM Watson for oncology due to accuracy.
What held back accuracy was the need for very experienced cancer researchers to annotate documents in the enclosure. They should have done this instead of doing their research.
Speed of implementation: Coseer says that without training data, most deployments can be launched within 4-12 weeks. This is much less than when the user begins to use a pre-trained system, the work of which begins with the preliminary loading of marked-up documents.
In addition, unlike current large vendors using traditional deep learning algorithms, Coseer prefers to deploy them in both a secure and private cloud to ensure data security.
All the “evidence” used to reach any conclusion is stored in a journal that can be used to demonstrate transparency and compliance with data security rules such as GDPR.
How it works
Coseer talks about the three principles that define CQM:
1. Words (variables) have different meanings.
Consider the word “oven”, which may be a noun or a verb. For example, “verse”, which can mean “poem” or the verb “verse wind” - these are the words homonyms.
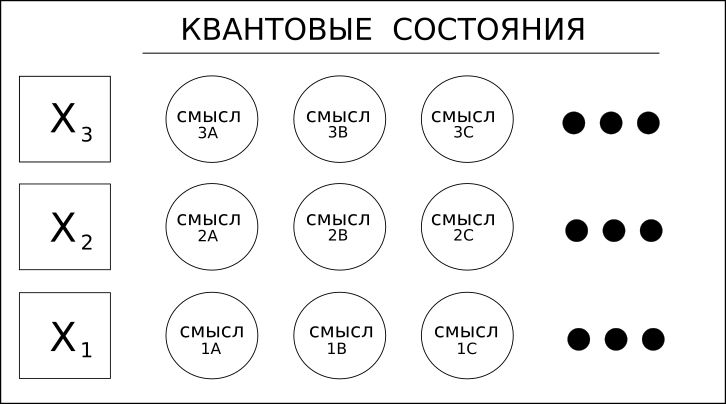
Deep learning solutions, including RNN / LSTM or even CNN for text, can only look forward or backward to determine the “context” of a word and thereby determine its meaning.
Coseer takes into account all possible meanings of the word and applies statistical probability to each of them based on the entire document or corpus.
The use of the term "quantum" in this case refers only to the possibility of multiple values, and not to a more exotic superposition of quantum computing.
2. Everything is interconnected in a grid of values:
Extracting from all available words (variables) all their possible relationships is the second principle.
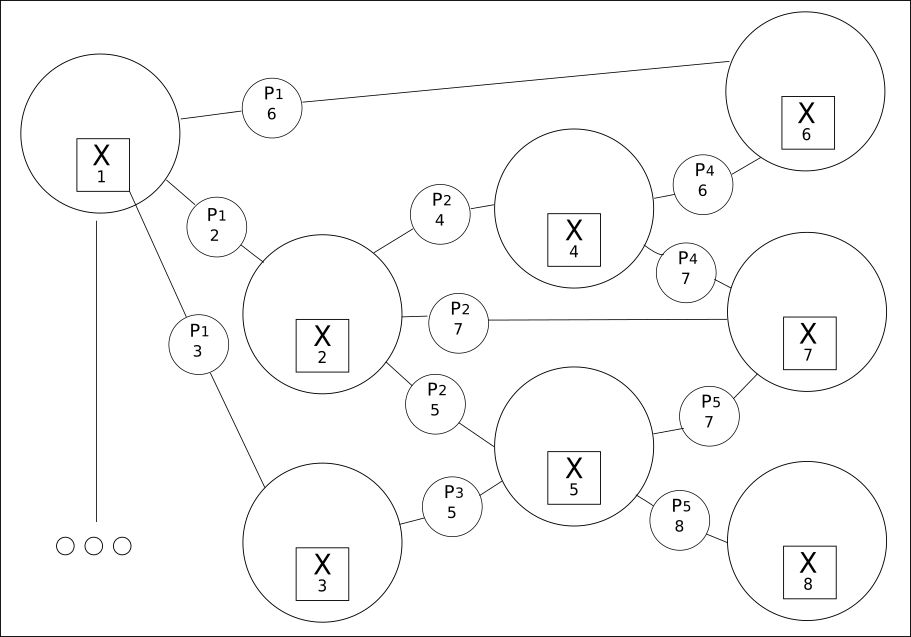
CQM creates a grid of possible values, among which a real value will be found. Using this approach reveals a much wider relationship between previous or subsequent phrases than traditional Deep Learning can provide.
Although the number of words can be limited, their relationships can be in the hundreds of thousands.
3. All available information is used sequentially to combine the grid into a single value. This calibration process quickly identifies missing words or concepts and provides very fast and accurate training.
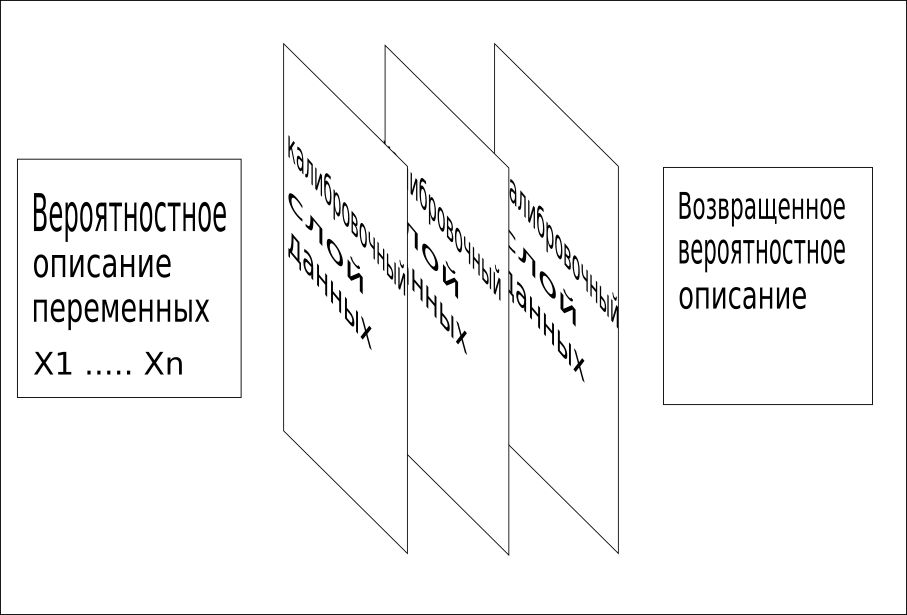
CQM models use training data, contextual data, reference data, and other facts known about the problem to identify these calibration data layers.
Unfortunately, Coseer has published very little in the public domain to explain the technical aspects of the algorithm.
Any breakthrough in eliminating marked data during training should be welcomed, and, of course, improving accuracy will lead to the fact that much more satisfied customers will use your chat bot.
All Articles