Clean decomposition
In this article I want to consider an approach to splitting tasks into subtasks when using Clean Architecture.
The decomposition problem was encountered by the NullGravity mobile development team and below how we solved it and what happened in the end.

It was the fall of 2018, we were developing the next application for a telecom operator. But this time was different. The timing was quite tight and tied to the client’s marketing campaign. Android team has grown from 3 to 6-7 developers. Several tasks were taken in the sprint and the question was how to decompose them effectively.
What do we mean when we speak effectively:
We divide all subtasks into the following types:
Data and Domain correspond to layers in Clean Architecture.
Empty, UI, Item and Custom refer to the presentation layer.
Integration applies to both the domain and presentation layers.
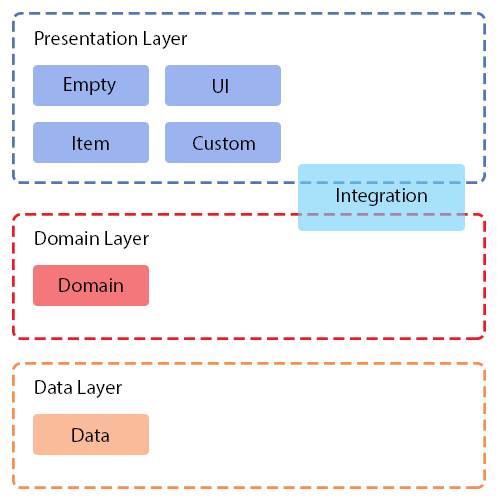
Figure 1. Location of tasks relative to Clean Architecture layers
Let's look at each type individually.
Description of DTO, API, work with database, datasource, etc.
Repository interface, description of business models, interactors.
The repository interface in the data layer is also implemented.
Such a somewhat illogical, at first glance, separation made it possible to isolate tasks such as data and domain as much as possible.
Creating a basic screen layout and additional states, if any.
If the screen is a list of elements, then for each type you need to create a model - Item. For mapping Item to the layout, AdapterDelegate is needed. We use the delegate adapter concept but with some modifications .
Next, create an example of working with a list item in PresentationModel.
Base classes required for tasks like ui or item: PresentationModel, Framgent, layout, DI module, AdapterDelagate factory. Binding interfaces and implementations. Create an entry point to the screen.
The result of the task is the application screen. It contains Toolbar, RecyclerView, ProgressView, etc. that is, common interface elements, the addition of which could be duplicated by different developers and would lead to inevitable merge conflicts.
Implementation of a non-standard UI component.
An additional type is needed to separate the development of a new component from a task of type UI.
Integration of domain and presentation layers.
As a rule, this is one of the most time-consuming tasks. It is necessary to reduce the two layers and refine the points that could have been missed in the previous stages.
Tasks like data, empty and custom can be started immediately after the sprint starts. They are independent of other tasks.
The domain task is executed after the data task.
The ui and item tasks after the empty task.
The integration task is the last to be completed as it requires the completion of all previous tasks.
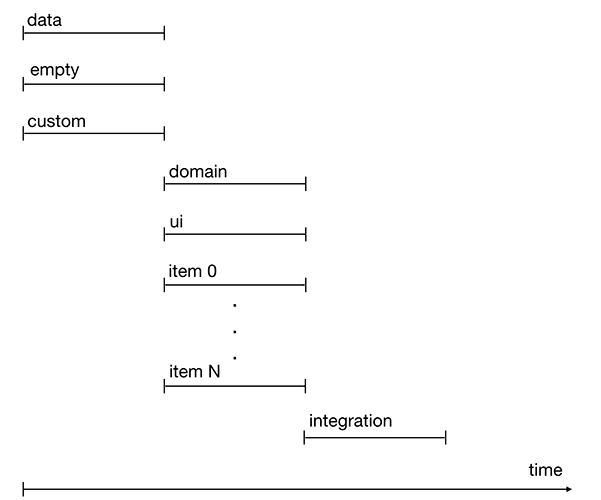
Figure 2. Timeline task execution
Despite the fact that some tasks are blocked by other tasks, they can be started at the same time or with a slight delay. Such tasks include domain, ui, and item. Thus, the development process is accelerated.
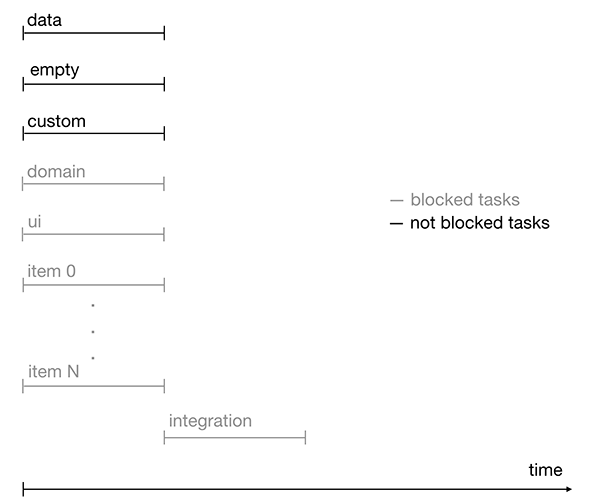
Figure 3. Timeline of performing tasks with locks
For each specific functionality, the set of tasks can vary.
There may be a different number of tasks empty, ui, item and integration, and some types may simply be absent.
To collect statistics when creating a task, label is assigned to it. This mechanism in the future will allow you to analyze the time spent on each type and form the average cost. The collected information can be applied when evaluating a new project.
For automation, we also managed to find a solution. Since tasks are typical, why their description in Jira should be different. We developed templates for summary and description. At first it was just a json file, the Python parser of this file, and the Jira REST API was connected to generate tasks.
In this form, the script lasted almost a year. Today it has turned into a full-fledged desktop application written in Python using PyQt and MVP architecture.
Maybe MVP was overhead, but when the first version on Tkinter crashed MacOS version 10.14.6 and not all teams could use the application, we easily rewrote view for PyQt in half a day and it worked. Once again, we were convinced that the use of architectural approaches, even for such simple tasks, has its advantages. A screenshot of the JiraSubTaskCreator is shown in Figure 4.
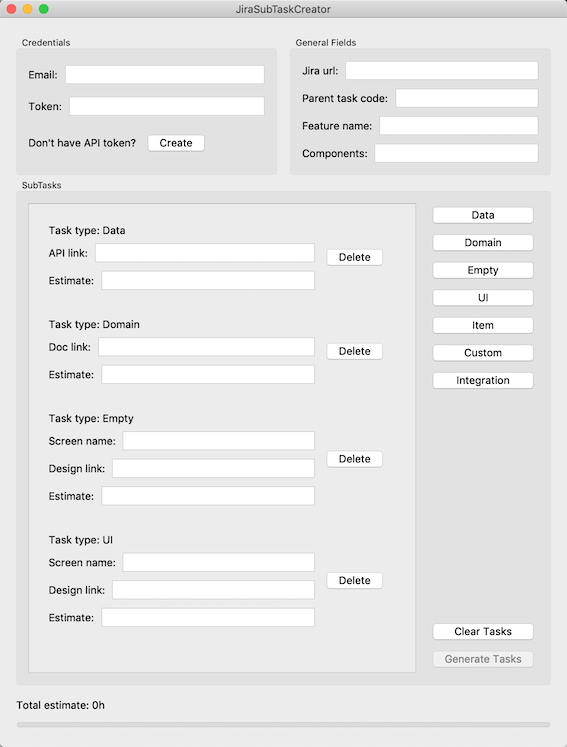
Figure 4. The main JiraSubTaskCreator screen
The decomposition problem was encountered by the NullGravity mobile development team and below how we solved it and what happened in the end.
Background
It was the fall of 2018, we were developing the next application for a telecom operator. But this time was different. The timing was quite tight and tied to the client’s marketing campaign. Android team has grown from 3 to 6-7 developers. Several tasks were taken in the sprint and the question was how to decompose them effectively.
What do we mean when we speak effectively:
- The maximum number of parallel tasks.
This makes it possible to occupy all available resources. - Reducing the size of merge requests.
They will not be watched for show, and you can still catch potential problems at the stage of code review. - Reduce the amount of merge conflicts.
Tasks will flow faster and there is no need to switch the developer to conflict resolution. - An opportunity to collect statistics of expenses of time.
- Automate task creation in Jira.
How did we solve the problem?
We divide all subtasks into the following types:
- Data
- Domain
- Empty
- UI
- Item
- Custom
- Integration
Data and Domain correspond to layers in Clean Architecture.
Empty, UI, Item and Custom refer to the presentation layer.
Integration applies to both the domain and presentation layers.
Figure 1. Location of tasks relative to Clean Architecture layers
Let's look at each type individually.
Data
Description of DTO, API, work with database, datasource, etc.
Domain
Repository interface, description of business models, interactors.
The repository interface in the data layer is also implemented.
Such a somewhat illogical, at first glance, separation made it possible to isolate tasks such as data and domain as much as possible.
UI
Creating a basic screen layout and additional states, if any.
Item
If the screen is a list of elements, then for each type you need to create a model - Item. For mapping Item to the layout, AdapterDelegate is needed. We use the delegate adapter concept but with some modifications .
Next, create an example of working with a list item in PresentationModel.
Empty
Base classes required for tasks like ui or item: PresentationModel, Framgent, layout, DI module, AdapterDelagate factory. Binding interfaces and implementations. Create an entry point to the screen.
The result of the task is the application screen. It contains Toolbar, RecyclerView, ProgressView, etc. that is, common interface elements, the addition of which could be duplicated by different developers and would lead to inevitable merge conflicts.
Custom
Implementation of a non-standard UI component.
An additional type is needed to separate the development of a new component from a task of type UI.
Integration
Integration of domain and presentation layers.
As a rule, this is one of the most time-consuming tasks. It is necessary to reduce the two layers and refine the points that could have been missed in the previous stages.
The order of tasks
Tasks like data, empty and custom can be started immediately after the sprint starts. They are independent of other tasks.
The domain task is executed after the data task.
The ui and item tasks after the empty task.
The integration task is the last to be completed as it requires the completion of all previous tasks.
Figure 2. Timeline task execution
Despite the fact that some tasks are blocked by other tasks, they can be started at the same time or with a slight delay. Such tasks include domain, ui, and item. Thus, the development process is accelerated.
Figure 3. Timeline of performing tasks with locks
For each specific functionality, the set of tasks can vary.
There may be a different number of tasks empty, ui, item and integration, and some types may simply be absent.
Process automation and statistics collection
To collect statistics when creating a task, label is assigned to it. This mechanism in the future will allow you to analyze the time spent on each type and form the average cost. The collected information can be applied when evaluating a new project.
For automation, we also managed to find a solution. Since tasks are typical, why their description in Jira should be different. We developed templates for summary and description. At first it was just a json file, the Python parser of this file, and the Jira REST API was connected to generate tasks.
In this form, the script lasted almost a year. Today it has turned into a full-fledged desktop application written in Python using PyQt and MVP architecture.
Maybe MVP was overhead, but when the first version on Tkinter crashed MacOS version 10.14.6 and not all teams could use the application, we easily rewrote view for PyQt in half a day and it worked. Once again, we were convinced that the use of architectural approaches, even for such simple tasks, has its advantages. A screenshot of the JiraSubTaskCreator is shown in Figure 4.
Figure 4. The main JiraSubTaskCreator screen
findings
- We have developed an approach to decomposition of tasks into subtasks minimally dependent on each other;
- Generated templates for describing tasks;
- We received small merge requests, which makes it possible to carefully review and change the code in isolation
- Reduced the number of conflicts with merge request;
- We got the opportunity to more accurately assess and analyze the time spent on each type of task;
- Automated part of the routine work.
All Articles