“Consultant +”: change in the flow of material. Fonts, styles, text alignment with python
"Consultant +" - a reference system for lawyers, accountants and so on. It works stably like a watch. In this post, it’s suggested that you set this clock a bit to your needs in terms of text output, namely: look at how you can process text information that the system gives with python. Along the way, work with the text elements declared in the title.
As a lawyer who has worked with the help program “Consultant +” for a long time, I have always lacked an ordinary function in this system. This function was as follows. When any changes appear in the regulatory act, K + employees post an overview of the changes in the form of two columns of text:

The column on the left is what it was before, the column on the right is the norm that is now in effect. Now (some years ago), the functionality has been updated and the changes are highlighted in bold and immediately visible. This is all very convenient. But there are uncomfortable things.
Firstly, some norms are not given, because their volume is too large for K + employees and you have to go to the system links, and secondly, you can’t just take and copy these two columns by pasting them into a regular excel or word table.
Perhaps this was done intentionally so that users work more actively with the system, including not transferring anything from there.
Well have to fix it.
The task : to spread the text in two columns, where it is possible and where not - just remove the norm and put all this into an Excel spreadsheet. At the same time, let's see how you can change the font, alignment and other trifles in the text using python.
For an example that feeds our future program, we take from K + the changes to the Law "On JSC". This law is often changed, so there will be work to do.
Save the changes to a regular txt file (for example, the edition of .txt). You get something like the following:

So, it is clear that each change is separated from the other by a solid line, which after saving took the form of numerous “???”. There is also a change heading to be reckoned with. Everything looks simple except for some points.
So, come across changes that have the following form:

In addition, the matter is compounded by the fact that individual changes differ significantly in length.
Create a new consult.py file and add the first lines to it:
The openpyxl module is already familiar, it allows you to work with Excel, but the other two are new. Their function is to correctly process Russian characters, which are often incorrectly read by programs.
In advance, create a new empty excel file outside the program, naming it for example revision2.xlsx. We will open this file with our program and write data there. This will be our final file.
So, the program opens the excel file, enters it:
Also above we create 3 empty lists where we will collect data: test, test2, test3.
Next, in the variable 'a' we will put everything that may fall into the form of the name of the change. In y - there will be a dividing line. It is the same in length:
Now the fun part.
We opened the cp1251 encoded .txt file. Each line was cleared of spaces from the end and the beginning with the strip method.
If the line begins with the word "old" we skip it. Why do we need to keep the “old” and the “new”, this is already clear. Next, we divide the line: from the beginning to 35 characters and from 39 characters to the end. That is, we eliminate the gap in the middle:

We put the contents of the space in the middle of the line in col3, because it may not be a space if the change is written in one line in a row:

Further, if the line starts with the change header (we wrote these headers into variable a), then we immediately write this line to excel without any splitting and add the line - x + = 1 (or x = x + 1). Empty lines, which we come across, we miss.
Consider the following code snippet:
If the length of 2 parts of the string is 0, that is, it does not exist, then test2 gets the first part of the string. If there is a space in the line, but the second part of the line is absent, then the first and second part of the line, respectively, fall into test and test2.
If there is a space in the line, and the line is not empty and its length is more than 60 characters, then it is added to test3.
If the line is empty, that is, we went through the entire change, then we write everything that we collected in excel cells, simultaneously checking the void in test (so that it is not empty) and the length of test3.
Finally, save the excel file:
Add some beauty to our table.
In particular, we will make it so that when outputting data, the change headers are highlighted in bold, and the text itself is smaller and formatted for easy reading.
Python allows you to do this. To do this, we need to add and change the code in the places where we record the results in an excel file:
That is, in fact, we only added the applicable methods .font and .alignment.
The entire program took the form:
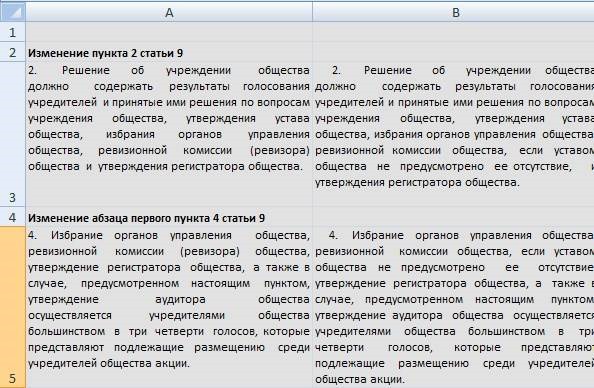
So, in the end, after processing the file by the program, we have a pretty decent table with changes in the law:
The program can be downloaded from the link - here .
An example file for processing by the program is here .
Shade on the wattle fence
As a lawyer who has worked with the help program “Consultant +” for a long time, I have always lacked an ordinary function in this system. This function was as follows. When any changes appear in the regulatory act, K + employees post an overview of the changes in the form of two columns of text:
The column on the left is what it was before, the column on the right is the norm that is now in effect. Now (some years ago), the functionality has been updated and the changes are highlighted in bold and immediately visible. This is all very convenient. But there are uncomfortable things.
Firstly, some norms are not given, because their volume is too large for K + employees and you have to go to the system links, and secondly, you can’t just take and copy these two columns by pasting them into a regular excel or word table.
Perhaps this was done intentionally so that users work more actively with the system, including not transferring anything from there.
Well have to fix it.
The task : to spread the text in two columns, where it is possible and where not - just remove the norm and put all this into an Excel spreadsheet. At the same time, let's see how you can change the font, alignment and other trifles in the text using python.
For an example that feeds our future program, we take from K + the changes to the Law "On JSC". This law is often changed, so there will be work to do.
Save the changes to a regular txt file (for example, the edition of .txt). You get something like the following:
So, it is clear that each change is separated from the other by a solid line, which after saving took the form of numerous “???”. There is also a change heading to be reckoned with. Everything looks simple except for some points.
So, come across changes that have the following form:
In addition, the matter is compounded by the fact that individual changes differ significantly in length.
We proceed to K +.
Create a new consult.py file and add the first lines to it:
from __future__ import unicode_literals import codecs import openpyxl
The openpyxl module is already familiar, it allows you to work with Excel, but the other two are new. Their function is to correctly process Russian characters, which are often incorrectly read by programs.
In advance, create a new empty excel file outside the program, naming it for example revision2.xlsx. We will open this file with our program and write data there. This will be our final file.
So, the program opens the excel file, enters it:
wb = openpyxl.load_workbook('2.xlsx') sheet=wb.get_active_sheet() x=1 y=0 test=[] test2=[] test3=[]
Also above we create 3 empty lists where we will collect data: test, test2, test3.
Next, in the variable 'a' we will put everything that may fall into the form of the name of the change. In y - there will be a dividing line. It is the same in length:
a=('','','','','','','') y='?????????????????????????????????????????????????????????????????????????'
Now the fun part.
with open ('.txt',encoding='cp1251') as f: lines = (line.strip() for line in f) for line in lines: if line.startswith(''): continue col1=line[:35] col2=line[39:] col3=line[35:39] if line.startswith(a): sheet.cell(row=x, column=1).value=line # , .. sheet.cell(row=x, column=1).font=ft2 #sheet.cell(row=x, column=1).style='20 % - Accent3' x+=1 # x+=2 elif line==None: continuewith open ('.txt',encoding='cp1251') as f: lines = (line.strip() for line in f) for line in lines: if line.startswith(''): continue col1=line[:35] col2=line[39:] col3=line[35:39] if line.startswith(a): sheet.cell(row=x, column=1).value=line # , .. x+=1 # x+=2 elif line==None: continue
We opened the cp1251 encoded .txt file. Each line was cleared of spaces from the end and the beginning with the strip method.
If the line begins with the word "old" we skip it. Why do we need to keep the “old” and the “new”, this is already clear. Next, we divide the line: from the beginning to 35 characters and from 39 characters to the end. That is, we eliminate the gap in the middle:
We put the contents of the space in the middle of the line in col3, because it may not be a space if the change is written in one line in a row:
Further, if the line starts with the change header (we wrote these headers into variable a), then we immediately write this line to excel without any splitting and add the line - x + = 1 (or x = x + 1). Empty lines, which we come across, we miss.
Consider the following code snippet:
if len(col2)==0: # 1- 2- if line.startswith(a): continue test2.append(col1) #test3.append(col1) if col3==' ' and col2!=None: test.append(line[:35]) test2.append(line[39:]) if col3!=' ' and line!=y and len(line)>60: #print(test3) test3.append(line) if line==y: # , if test!=None: sheet.cell(row=x, column=1).value=(' '.join(test).strip('\?')) sheet.cell(row=x, column=1).font=ft sheet.cell(row=x, column=1).alignment=al sheet.cell(row=x, column=2).value=(' '.join(test2).strip('\?')) sheet.cell(row=x, column=2).font=ft sheet.cell(row=x, column=2).alignment=al test=[] test2=[] x+=1 if len(test3)>0: #print(len(test3)) sheet.cell(row=x, column=2).value=(' '.join(test3).strip('\?')) sheet.cell(row=x, column=2).font=ft sheet.cell(row=x, column=2).alignment=al test3=[] x+=1 else: continue
If the length of 2 parts of the string is 0, that is, it does not exist, then test2 gets the first part of the string. If there is a space in the line, but the second part of the line is absent, then the first and second part of the line, respectively, fall into test and test2.
If there is a space in the line, and the line is not empty and its length is more than 60 characters, then it is added to test3.
If the line is empty, that is, we went through the entire change, then we write everything that we collected in excel cells, simultaneously checking the void in test (so that it is not empty) and the length of test3.
Finally, save the excel file:
wb.save('2.xlsx')
Styles, font and text alignment in python
Add some beauty to our table.
In particular, we will make it so that when outputting data, the change headers are highlighted in bold, and the text itself is smaller and formatted for easy reading.
Python allows you to do this. To do this, we need to add and change the code in the places where we record the results in an excel file:
from openpyxl.styles import Font, Color,NamedStyle, Alignment
al= Alignment(horizontal="justify", vertical="top") ft = Font(name='Calibri', size=9) ft2 = Font(name='Calibri', size=9,bold=True)
if line.startswith(a): sheet.cell(row=x, column=1).value=line # , .. sheet.cell(row=x, column=1).font=ft2
if line==y: # , if test!=None: sheet.cell(row=x, column=1).value=(' '.join(test).strip('\?')) sheet.cell(row=x, column=1).font=ft sheet.cell(row=x, column=1).alignment=al sheet.cell(row=x, column=2).value=(' '.join(test2).strip('\?')) sheet.cell(row=x, column=2).font=ft sheet.cell(row=x, column=2).alignment=al
if len(test3)>0: #print(len(test3)) sheet.cell(row=x, column=2).value=(' '.join(test3).strip('\?')) sheet.cell(row=x, column=2).font=ft sheet.cell(row=x, column=2).alignment=al
That is, in fact, we only added the applicable methods .font and .alignment.
The entire program took the form:
The code
from __future__ import unicode_literals import codecs import openpyxl from openpyxl.styles import Font, Color,NamedStyle, Alignment """ 1. Consultant+ , .txt ????????????????????????????????????????????????????????????????????????? 15 1 48 15) 15) excel . word - txt : .txt : 2.xlsx """ #file = open ( '2.txt', 'w',encoding='cp1251', newline = '\n') wb = openpyxl.load_workbook('2.xlsx') sheet=wb.get_active_sheet() x=1 y=0 test=[] test2=[] test3=[] a=('','','','','','','') y='?????????????????????????????????????????????????????????????????????????' # #al= Alignment(horizontal="distributed", vertical="top") al= Alignment(horizontal="justify", vertical="top") ft = Font(name='Calibri', size=9) ft2 = Font(name='Calibri', size=9,bold=True) with open ('.txt',encoding='cp1251') as f: lines = (line.strip() for line in f) for line in lines: if line.startswith(''): continue col1=line[:35] col2=line[39:] col3=line[35:39] if line.startswith(a): sheet.cell(row=x, column=1).value=line # , .. sheet.cell(row=x, column=1).font=ft2 #sheet.cell(row=x, column=1).style='20 % - Accent3' x+=1 # x+=2 elif line==None: continue #print (line) #print (len(col2)) if len(col2)==0: # 1- 2- if line.startswith(a): continue test2.append(col1) #test3.append(col1) if col3==' ' and col2!=None: test.append(line[:35]) test2.append(line[39:]) if col3!=' ' and line!=y and len(line)>60: #print(test3) test3.append(line) if line==y: # , if test!=None: sheet.cell(row=x, column=1).value=(' '.join(test).strip('\?')) sheet.cell(row=x, column=1).font=ft sheet.cell(row=x, column=1).alignment=al sheet.cell(row=x, column=2).value=(' '.join(test2).strip('\?')) sheet.cell(row=x, column=2).font=ft sheet.cell(row=x, column=2).alignment=al test=[] test2=[] x+=1 if len(test3)>0: #print(len(test3)) sheet.cell(row=x, column=2).value=(' '.join(test3).strip('\?')) sheet.cell(row=x, column=2).font=ft sheet.cell(row=x, column=2).alignment=al test3=[] x+=1 else: continue wb.save('2.xlsx')
So, in the end, after processing the file by the program, we have a pretty decent table with changes in the law:
The program can be downloaded from the link - here .
An example file for processing by the program is here .
All Articles