Qrator Filter Network Configuration Management System
TL; DR : Description of the client-server architecture of our internal network configuration management system, QControl. It is based on a two-level transport protocol that works with gzip-packed messages without decompression between endpoints. Distributed routers and endpoints receive configuration updates, and the protocol itself allows the installation of localized intermediate relays. The system is built on the principle of differential backup (“recent-stable”, explained below) and uses the JMESpath query language along with the Jinja template engine to render configuration files.
Qrator Labs manages a globally distributed attack mitigation network. Our network works on the principle of anycast, and subnets are announced via BGP. Being a BGP anycast network physically located in several regions of the Earth, we can process and filter out illegitimate traffic closer to the core of the Internet - Tier-1 operators.
On the other hand, being a geographically distributed network is not easy. Communication between network points of presence is critical for a security service provider in order to have a consistent configuration of all network nodes, updating them in a timely manner. Therefore, in order to provide the highest possible level of basic services for consumers, we needed to find a way to reliably synchronize configuration data between continents.
In the beginning was the Word. It quickly became a communication protocol in need of an update.
The cornerstone of the existence of QControl and at the same time the main reason for spending a significant amount of time and resources to build such a protocol is the need to obtain a single authoritative source of configuration and, ultimately, synchronize our points of presence with it. The repository itself was just one of several requirements during the development of QControl. In addition, we also needed integration with existing and planned services at the points of presence (TP), smart (and customizable) methods of data validation, as well as access control. In addition to this, we also wanted to manage such a system using commands, rather than making modifications to the files. Prior to QControl, data was sent to points of presence in almost manual mode. If one of the points of presence was unavailable, and we forgot to update it later, the configuration turned out to be out of sync - you had to spend time returning it to service.
As a result, we came up with the following scheme:
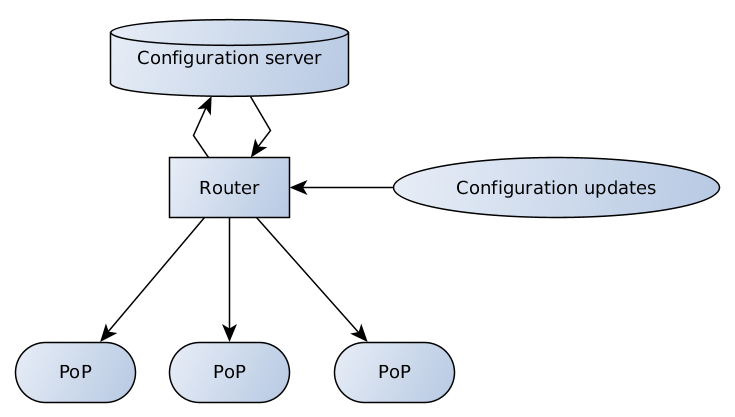
The configuration server is responsible for data validation and storage, the router has several endpoints that receive and broadcast configuration updates from clients and support teams to the server, and from the server to points of presence.
The quality of the Internet connection is still significantly different in different parts of the world - to illustrate this thesis, let's look at a simple MTR from Prague, the Czech Republic to Singapore and Hong Kong.

MTR from Prague to Singapore

Same thing to hong kong
High delays mean less speed. In addition, there is packet loss. The width of the channels does not compensate for this problem, which should always be taken into account when building decentralized systems.
A full point of presence configuration is a significant amount of data that needs to be sent to many recipients over untrusted connections. Fortunately, although the configuration is constantly changing, this happens in small portions.
Recent-stable design
We can say that building a distributed network on the principle of incremental updates is a fairly obvious solution. But there are a lot of problems with diffs. We need to keep all the diffs between the control points, as well as be able to send them in case someone missed some of the data. Each destination must apply them in a strictly defined sequence. Typically, in the case of multiple destinations, such an operation can take a long time. The recipient should also be able to request the missing parts and, of course, the central part should respond to such a request correctly, sending only the missing data.
As a result, we came to a rather interesting solution - we have only one support layer, fixed, let's call it stable, and only one diff for it is recent. Each recent is based on the last stable formed and is sufficient to rebuild configuration data. As soon as a fresh recent arrives at its destination, the old one is no longer needed.
It remains only from time to time to send a fresh stable configuration, for example, due to the fact that recent has become too large. It is also important here that we send all these updates in the broadcast / multicast mode, without worrying about individual recipients and their ability to collect pieces of data together. As soon as we are convinced that everyone has the correct stable - we send only new recent ones. Is it worth it to clarify that this works? Works. Stable is cached on the configuration server and recipients, recent is created as needed.
Two-Level Transport Architecture
Why did we build our transport on two levels? The answer is quite simple - we wanted to separate routing from high-level logic, drawing inspiration from the OSI model with its transport layer and application layer. We took Thrift for the role of the transport protocol, and for the high-level control message format, the msgpack serialization format. That is why the router (executing multicast / broadcast / relay) does not look inside msgpack, does not unpack and does not pack the contents back, and only performs data transfer.
Thrift (from the English - “thrift”, pronounced [θrift]) is an interface description language that is used to define and create services for different programming languages. It is a framework for remote procedure call (RPC). It combines a software pipeline with a code generation engine for developing services that, to one degree or another, work efficiently and easily between languages.
We took the Thrift framework because of RPC and support for many languages. As usual, the client and server are the easy parts. However, the router turned out to be a tough nut, partly due to the lack of a ready-made solution during our development.
 There are other options, such as protobuf / gRPC, however, when we started our project, gRPC was quite young and we did not dare to take it on board.
There are other options, such as protobuf / gRPC, however, when we started our project, gRPC was quite young and we did not dare to take it on board.
Of course, we could (and in fact, it was worth doing) to create our own bike. It would be easier to create a protocol for what we need, because the client-server architecture is relatively straightforward in implementation compared to building a router on Thrift. One way or another, there is a traditional prejudice towards self-written protocols and implementations of popular libraries (not in vain), in addition, the discussion always raises the question: “How will we port it to other languages?” Therefore, we immediately threw out ideas about the bicycle.
Msgpack is an analogue of JSON, but faster and less. This is a binary data serialization format for exchanging data between multiple languages.
At the first level, we have Thrift with the minimum information necessary for the router to forward the message. At the second level are packaged msgpack structures.
We chose msgpack because it is faster and more compact compared to JSON. But more importantly, it supports custom data types, allowing us to use cool features such as transferring raw binaries or special objects indicating the lack of data, which was important for our recent-stable scheme.
Jmespath
JMESPath is a JSON request language.
This is exactly what the description looks like, which we get from the official JMESPath documentation, but in fact, it gives a lot more. JMESPath allows you to search and filter subtrees in an arbitrary tree structure, as well as apply changes to data on the fly. It also allows you to add special filters and data conversion procedures. Although, of course, it requires brain tension to understand.
Jinja
For some consumers, we need to turn the configuration into a file - so we use the template engine and Jinja is the obvious choice. With its help, we generate a configuration file from the template and the data received at the destination.
To generate a configuration file, we need a JMESPath request, a template for the file location in the FS, a template for the config itself. Also at this stage it’s nice to clarify file permissions. All this turned out to be successfully combined in one file - before the start of the configuration template, we put the header in YAML format, which describes the rest.
For example:
---
selector: "[@][?@.fft._meta.version == `42`] | items([0].fft_config || `{}`)"
destination_filename: "fft/{{ match[0] }}.json"
file_mode: 0644
reload_daemons: [fft]
...
{{ dict(match[1]) | json(indent=2, sort_keys=True) }}
In order to make a configuration file for a new service, we add only a new template file. No changes to source code or software at points of presence are required.
What has changed since QControl was introduced into operations? The first and most important is the consistent and reliable delivery of configuration updates across all nodes in the network. The second is to get a powerful configuration verification tool and make changes to it by our support team, as well as by consumers of the service.
We managed to do all this using the recent-stable update scheme to simplify communication between the configuration server and configuration recipients. Using a two-layer protocol to support a content-independent data routing method. Having successfully integrated the Jinja-based configuration generation engine into a distributed filtering network. This system supports a wide range of configuration methods for our distributed and variegated peripherals.
Thanks for the help in writing the material thanks to VolanDamrod , serenheit , NoN .
English version of the post.
All Articles