We are selected from the jungle of tests: we are building a short way from fixtures to testing

In this article, I want to offer an alternative to the traditional test design style using Scala's functional programming concepts. The approach was inspired by the many months of pain from supporting dozens and hundreds of falling tests and a burning desire to make them easier and more understandable.
Despite the fact that the code is written in Scala, the proposed ideas will be relevant for developers and testers in all languages that support the functional programming paradigm. You can find a link to Github with a complete solution and example at the end of the article.
Problem
If you have ever dealt with tests (it doesn’t matter - unit tests, integration or functional), most likely they were written as a set of sequential instructions. For example:
// . // , , // . " = 'customer'" - { import TestHelper._ " < 250 - " in { val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40) val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1) result shouldBe 90 } " >= 250 - 10%" in { val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 100) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 120) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 130) insertBonus(db, id = 1, packageId = 1, bonusAmount = 40) val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1) result shouldBe 279 } } " = 'vip'" - {/*...*/}
This is the preferred for most, not requiring development, a way to describe tests. Our project has about 1000 tests of different levels (unit tests, integration tests, end-to-end), and all of them, until recently, were written in a similar style. As the project grew, we began to feel significant problems and a slowdown with the support of such tests: putting the tests in order took no less time than writing business-relevant code.
When writing new tests, you always had to think from scratch how to prepare the data. Often copy-paste steps from neighboring tests. As a result, when the data model in the application changed, the house of cards crumbled and had to be collected in a new way in each test: at best, just a change in the helpers functions, at worst - a deep immersion in the test and rewriting it.
When the test fell honestly - that is, because of a bug in the business logic, and not because of problems in the test itself - it was impossible to understand where something went wrong without debugging. Due to the fact that it took a long time to understand the tests, no one fully possessed knowledge of the requirements - how the system should behave under certain conditions.
All this pain is the symptom of two deeper problems of this design:
- The contents of the test are allowed in a too loose form. Each test is unique, like a snowflake. The need to read the details of the test takes a lot of time and demotivates. Not important details distract from the main thing - the requirements verified by the test. Copy paste is becoming the main way to write new test cases.
- Tests do not help the developer localize bugs, but only signal a problem. To understand the state at which the test is performed, you need to restore it in your head or connect with a debugger.
Modeling
Can we do better? (Spoiler: we can.) Let's look at what this test consists of.
val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
The tested code, as a rule, will wait for some explicit parameters to enter - identifiers, sizes, volumes, filters, etc. Also, it will often need data from the real world - we see that the application refers to the menu and menu templates database. To run the test reliably, we need fixture — the state that the system and / or data providers must be in before the test runs and the input parameters, often related to the state.
We will prepare dependencies with this fixture - fill the database (queue, external service, etc.). With the prepared dependency, we initialize the tested class (services, modules, repositories, etc.).
val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1)
By executing the test code on some input parameters, we get a business-significant result ( output ) - both explicit (returned by the method) and implicit - a change in the notorious state: database, external service, etc.
result shouldBe 90
Finally, we verify that the results are exactly what they expected, summing up the test with one or more assertions .
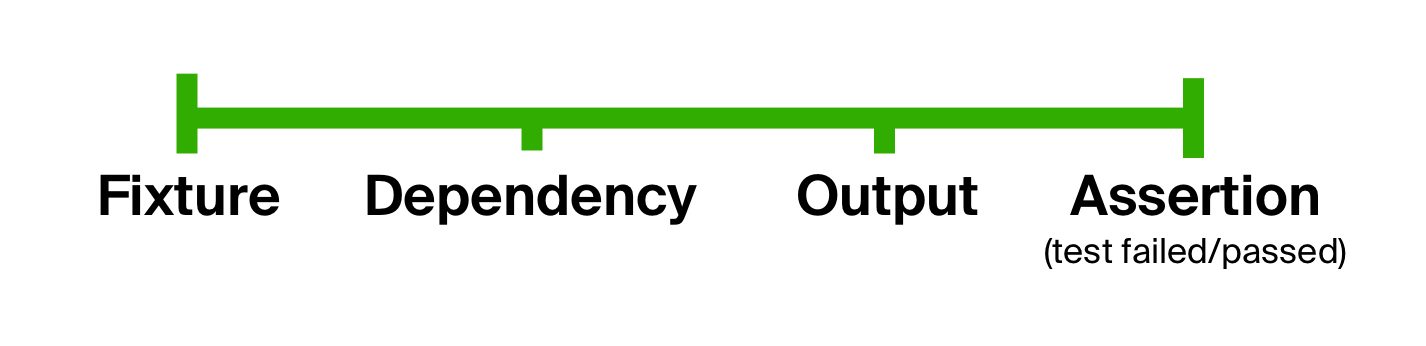
We can conclude that, in general, the test consists of the same stages: preparing the input parameters, executing the test code on them, and comparing the results with the expected ones. We can use this fact to get rid of the first problem in the test - too loose form, clearly dividing the test into stages. This idea is not new and has long been used in tests in the BDD-style ( behavior-driven development ).
What about extensibility? Any of the steps in the testing process can contain as many intermediate steps as you like. Looking ahead, we could form a fixture, creating at first some human-readable structure, and then convert it into objects that fill the database. The testing process is infinitely expandable, but, ultimately, it always comes down to the main stages.

Running tests
Let's try to realize the idea of dividing the test into stages, but first we determine how we would like to see the final result.
In general, we want to make writing and supporting tests a less labor-intensive and more enjoyable process. The less explicit non-unique (repeated elsewhere) instructions in the body of the test, the less changes will need to be made to the tests after changing contracts or refactoring and the less time it will take to read the test. The design of the test should encourage the reuse of frequently used pieces of code and prevent thoughtless copying. It would be nice if the tests had a uniform look. Predictability improves readability and saves time — imagine how much time it would take physics students to master each new formula if they were described in free-form words rather than in mathematical language.
Thus, our goal is to hide everything distracting and superfluous, leaving only the information critical for understanding the application: what is tested, what is expected at the input, and what is expected at the output.
Let's go back to the model of the test device. Technically, each point on this graph can be represented by a data type, and transitions from one to another - functions. You can come from the initial data type to the final one by applying the following function to the result of the previous one by one. In other words, using a composition of functions : preparing data (let's call it prepare
), executing the test code ( execute
), and checking the expected result ( check
). We will pass the first point of the chart, fixture, to the input of this composition. The resulting higher-order function is called the test life cycle function .
def runTestCycle[FX, DEP, OUT, F[_]]( fixture: FX, prepare: FX => DEP, execute: DEP => OUT, check: OUT => F[Assertion] ): F[Assertion] = // Scala , check(execute(prepare(fixture))) // andThen: (prepare andThen execute andThen check) (fixture)
The question is, where do the internal functions come from? We will prepare the data in a limited number of ways - to fill the database, get wet, etc. - therefore, the options for the prepare function will be common to all tests. As a result, it will be easier to make specialized life-cycle functions that hide specific implementation of data preparation. Since the methods of invoking the code being checked and checking are relatively unique for each test, execute
and check
will be supplied explicitly.
// — def prepareDatabase[DB](db: Database): DbFixture => DB def testInDb[DB, OUT]( fixture: DbFixture, execute: DB => OUT, check: OUT => Future[Assertion], db: Database = getDatabaseHandleFromSomewhere(), ): Future[Assertion] = runTestCycle(fixture, prepareDatabase(db), execute, check)
By delegating all the administrative nuances to the life cycle function, we get the opportunity to expand the testing process without getting into any already written test. Due to the composition, we can infiltrate anywhere in the process, extract or add data there.
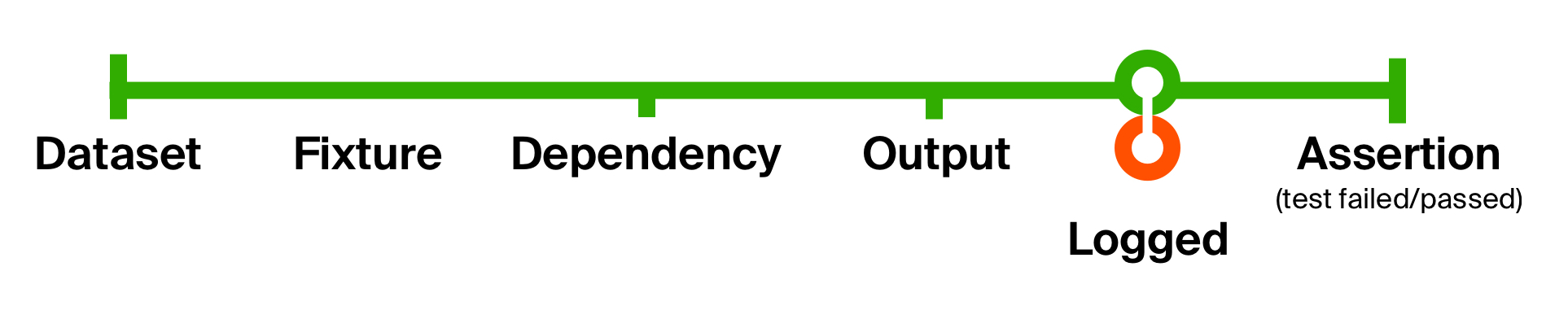
To better illustrate the possibilities of this approach, we will solve the second problem of our initial test - the lack of supporting information to localize the problems. Add logging when receiving a response from the tested method. Our logging will not change the data type, but will only produce a side effect - displaying a message on the console. Therefore, after the side effect, we will return it as is.
def logged[T](implicit loggedT: Logged[T]): T => T = (that: T) => { // Logged T, // “” that log(). // - . loggedT.log(that) // : that.log() that // } def runTestCycle[FX, DEP, OUT, F[_]]( fixture: FX, prepare: FX => DEP, execute: DEP => OUT, check: OUT => F[Assertion] )(implicit loggedOut: Logged[OUT]): F[Assertion] = // logged - execute (prepare andThen execute andThen logged andThen check) (fixture)
With such a simple movement, we added logging of the returned result and the state of the database in each test . The advantage of these small functions is that they are easy to understand, easy to compose for reuse, and easy to get rid of if they are no longer needed.

As a result, our test will look like this:
val fixture: SomeMagicalFixture = ??? // - def runProductionCode(id: Int): Database => Double = (db: Database) => new SomeProductionLogic(db).calculatePrice(id) def checkResult(expected: Double): Double => Future[Assertion] = (result: Double) => result shouldBe expected // Database testInDb " = 'customer'" in testInDb( state = fixture, execute = runProductionCode(id = 1), check = checkResult(90) )
The body of the test has become terse, fixtures and checks can be reused in other tests, and we do not manually prepare the database anywhere else. Only one problem remains ...
Fixture preparation
In the code above, we used the assumption that the fixture will come from somewhere ready-made and that it only needs to be transferred to the life cycle function. Since data is a key ingredient in simple and supported tests, we cannot but touch on how to form it.
Suppose our test store has a typical medium-sized database (for simplicity, an example with 4 tables, but in reality there may be hundreds). Part contains background information, part - directly business, and all together it can be connected into several full-fledged logical entities. Tables are interconnected by keys ( foreign keys ) - to create a Bonus
entity, you need the Package
entity, and it, in turn, User
. And so on.

Circumstances of circuit limitations and all kinds of hacks lead to inconsistency and, as a result, to test instability and hours of exciting debugging. For this reason, we will fill the database honestly.
We could use military methods for filling, but even with a superficial examination of this idea, many difficult questions arise. What will prepare the data in tests for these methods themselves? Will I need to rewrite the tests if the contract changes? What if the data is delivered by a non-tested application (for example, import by someone else)? How many different queries will have to be done in order to create an entity dependent on many others?
insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Disparate helper methods, as in the original example, are the same problem, but with a different sauce. They assign responsibility for managing dependent objects and their relationships to us, and we would like to avoid this.
Ideally, I would like to have this type of data, one look at which is enough to understand in general terms what state the system will be during the test. One of the good candidates for state visualization is a table (a la datasets in PHP and Python), where there is nothing superfluous except for fields critical for business logic. If the business logic changes in a feature, all test support will be reduced to updating the cells in the dataset. For example:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) )
From our table, we will generate keys - entity relationships by ID. At the same time, if the entity depends on another, a key will be generated for the dependence. It may happen that two different entities generate a dependency with the same identifier, which can lead to violation of the restriction on the primary key of the database ( primary key ). But at this stage, the data is extremely cheap to deduplicate - since the keys contain only identifiers, we can put them into a collection that provides deduplication, for example, in Set
. If this turns out to be insufficient, we can always make smarter deduplication in the form of an additional function compiled into a life cycle function.
sealed trait Key case class PackageKey(id: Int, userId: Int) extends Key case class PackageItemKey(id: Int, packageId: Int) extends Key case class UserKey(id: Int) extends Key case class BonusKey(id: Int, packageId: Int) extends Key
We delegate the generation of fake content to fields (for example, names) to a separate class. Then, resorting to the help of this class and the rules for converting keys, we get string objects intended directly for insertion into the database.
object SampleData { def name: String = "test name" def role: String = "customer" def price: Int = 1000 def bonusAmount: Int = 0 def status: String = "new" } sealed trait Row case class PackageRow(id: Int, name: String, userId: Int, status: String) extends Row case class PackageItemRow(id: Int, packageId: Int, name: String, price: Int) extends Row case class UserRow(id: Int, name: String, role: String) extends Row case class BonusRow(id: Int, packageId: Int, bonusAmount: Int) extends Row
The default fake data, as a rule, will not be enough for us, so we will need to be able to redefine specific fields. We can use lenses - run through all the lines created and change the fields of only those that are needed. Since the lenses in the end are ordinary functions, they can be composited, and this is their usefulness.
def changeUserRole(userId: Int, newRole: String): Set[Row] => Set[Row] = (rows: Set[Row]) => rows.modifyAll(_.each.when[UserRow]) .using(r => if (r.id == userId) r.modify(_.role).setTo(newRole) else r)
Thanks to the composition, within the whole process we can apply various optimizations and improvements - for example, group rows in tables so that they can be inserted with one insert
, reducing test time, or securing the final state of the database to simplify catching problems.
def makeFixture[STATE, FX, ROW, F[_]]( state: STATE, applyOverrides: F[ROW] => F[ROW] = x => x ): FX = (extractKeys andThen deduplicateKeys andThen enrichWithSampleData andThen applyOverrides andThen logged andThen buildFixture) (state)
All together will give us a fixture that fills the dependency for the test - the database. In the test itself, nothing superfluous will be seen, except for the original dataset - all details will be hidden inside the composition of functions.

Our test suite will now look like this:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) ) " -" - { "'customer'" - { " " - { "< 250 - " - { "(: )" in calculatePriceFor(dataTable, 1) "(: )" in calculatePriceFor(dataTable, 3) } ">= 250 " - { " - 10% " in calculatePriceFor(dataTable, 2) " - 10% " in calculatePriceFor(dataTable, 4) } } } "'vip' - 20% , " in calculatePriceFor(dataTable, 5) }
A helper code:
// def calculatePriceFor(table: Seq[DataRow], idx: Int) = testInDb( state = makeState(table.row(idx)), execute = runProductionCode(table.row(idx)._1), check = checkResult(table.row(idx)._5) ) def makeState(row: DataRow): Logger => DbFixture = { val items: Map[Int, Int] = ((1 to row._3.length) zip row._3).toMap val bonuses: Map[Int, Int] = ((1 to row._4.length) zip row._4).toMap MyFixtures.makeFixture( state = PackageRelationships .minimal(id = row._1, userId = 1) .withItems(items.keys) .withBonuses(bonuses.keys), overrides = changeRole(userId = 1, newRole = row._2) andThen items.map { case (id, newPrice) => changePrice(id, newPrice) }.foldPls andThen bonuses.map { case (id, newBonus) => changeBonus(id, newBonus) }.foldPls ) } def runProductionCode(id: Int): Database => Double = (db: Database) => new SomeProductionLogic(db).calculatePrice(id) def checkResult(expected: Double): Double => Future[Assertion] = (result: Double) => result shouldBe expected
Adding new test cases to the table becomes a trivial task, which allows you to concentrate on covering the maximum number of boundary conditions , rather than on a boilerplate.
Reusing fixture preparation code on other projects
Well, we wrote a lot of code for preparing fixtures in one specific project, spending a lot of time on this. What if we have several projects? Are we doomed to reinvent the wheel and copy-paste each time?
We can abstract the preparation of fixtures from a specific domain model. In the world of FP, there is the concept of a typeclass . In short, typeclasses are not classes from OOP, but something like interfaces, they define some type group behavior. The fundamental difference is that this group of types is determined not by class inheritance, but by instantiation, like ordinary variables. As with inheritance, resolving instances of type classes (via implicits ) occurs statically , at the compilation stage. For simplicity, for our purposes, typeclasses can be thought of as extensions from Kotlin and C # .
To pledge an object, we do not need to know what this object has inside, what fields and methods it has. It is only important for us that the log
behavior with a certain signature be defined for it. It would be Logged
to implement a certain Logged
interface in each class, and it is not always possible - for example, in library or standard classes. In the case of typeclasses, things are much easier. We can create an instance of the Logged Logged
, for example, for fixtures, and display it in a readable form. And for all other types, create an instance for the Any
type and use the standard toString
method to log any objects in their internal representation for free.
trait Logged[A] { def log(a: A)(implicit logger: Logger): A } // Future implicit def futureLogged[T]: Logged[Future[T]] = new Logged[Future[T]] { override def log(futureT: Future[T])(implicit logger: Logger): Future[T] = { futureT.map { t => // map Future , // logger.info(t.toString()) t } } } // , implicit def anyNoLogged[T]: Logged[T] = new Logged[T] { override def log(t: T)(implicit logger: Logger): T = { logger.info(t.toString()) t } }
In addition to logging, we can extend this approach to the entire process of preparing fixtures. The test solution will offer its own timeclasses and the abstract implementation of functions based on them. The responsibility of the project using it is to write its own instance of typeclasses for types.
// def makeFixture[STATE, FX, ROW, F[_]]( state: STATE, applyOverrides: F[ROW] => F[ROW] = x => x ): FX = (extractKeys andThen deduplicateKeys andThen enrichWithSampleData andThen applyOverrides andThen logged andThen buildFixture) (state) override def extractKeys(implicit toKeys: ToKeys[DbState]): DbState => Set[Key] = (db: DbState) => db.toKeys() override def enrichWithSampleData(implicit enrich: Enrich[Key]): Key => Set[Row] = (key: Key) => key.enrich() override def buildFixture(implicit insert: Insertable[Set[Row]]): Set[Row] => DbFixture = (rows: Set[Row]) => rows.insert() // , - (, ) trait ToKeys[A] { def toKeys(a: A): Set[Key] // Something => Set[Key] } // ... trait Enrich[A] { def enrich(a: A): Set[Row] // Set[Key] => Set[Row] } // ... trait Insertable[A] { def insert(a: A): DbFixture // Set[Row] => DbFixture } // (. ) implicit val toKeys: ToKeys[DbState] = ??? implicit val enrich: Enrich[Key] = ??? implicit val insert: Insertable[Set[Row]] = ???
When designing the fixture generator, I was guided by the implementation of the principles of programming and SOLID design as an indicator of its stability and adaptability to different systems:
- The principle of single responsibility ( of The Single Responsibility Principle ): each taypklass describes exactly one aspect of the behavior type.
- The principle of opening / closing ( of The the Open the Closed Principle ): we do not modify the existing type of battle for the tests, we are expanding its instanced taypklassov.
- ( The Liskov Substitution Principle ) , .
- ( The Interface Segregation Principle ): .
- ( The Dependency Inversion Principle ): , .
, , , .
, , , , , .
Summary
() . , , , . , , . , (, ), .
, , . , .
, , , . , , , -. , . !
: Github
All Articles