ACL 2019 Conference Notes

The Annual Meeting of the Association for Computational Linguistics (ACL) is the premier natural language processing conference. It has been organized since 1962. After Canada and Australia, she returned to Europe and marched in Florence. Thus, this year it was more popular with European researchers than the similar EMNLP.
This year, 660 articles out of 2900 submitted were published. Great amount. It is hardly possible to make some kind of objective review of what was at the conference. Therefore, I will tell my subjective feelings from this event.
I came to the conference to show in a poster session our decision from the Kaggle competition about Google's Gendered Pronoun Resolution . Our solution relied heavily on the use of pre -trained BERT models . And, as it turned out, we were not alone in this.
Bertology

There were so many works based on BERT, describing its properties and using it as a basement, that even the term Bertology appeared. Indeed, the BERT models have turned out so successful that even large research groups compare their models with the BERT.
So in early June, work appeared about XLNet . And right before the conference - ERNIE 2.0 and RoBERTa
Facebook RoBERTa
When the XLNet model was first introduced, some researchers suggested that it achieved better results not only because of its architecture and training principles. She also studied on a larger body (almost 10 times) than BERT and longer (4 times more iterations).
Researchers at Facebook have shown that BERT has not yet reached its maximum. They presented an optimized approach to teaching the BERT model - RoBERTa (Robustly optimized BERT approach).
Changing nothing in the architecture of the model, they changed the training procedure:
- We increased the body for training, the size of the batch, the length of the sequence and training time.
- The task of predicting the next sentence was removed from training.
- They began to dynamically generate MASK tokens (tokens that the model tries to predict during pre-training).
ERNIE 2.0 from Baidu
Like all popular recent models (BERT, GPT, XLM, RoBERTa, XLNet), ERNIE is based on the concept of a transformer with a self-attention mechanism. What sets it apart from other models is the concepts of multi-task learning and continuous learning.
ERNIE learns on different tasks, constantly updating the internal representation of its language model. These tasks have, like other models, self-learning (self-supervised and weak-supervised) goals. Examples of such tasks:
- Recover the correct word order in a sentence.
- Capitalization of words.
- Definition of masked words.
On these tasks, the model learns sequentially, returning to the tasks on which it was trained earlier.
RoBERTa vs ERNIE
In publications, RoBERTa and ERNIE are not compared with each other, since they appeared almost simultaneously. They are compared to BERT and XLNet. But here it is not so easy to make a comparison. For example, in the popular benchmark GLUE XLNet is represented by an ensemble of models. And researchers from Baidu are more interested in comparing single models. In addition, since Baidu is a Chinese company, they are also interested in comparing the results of working with the Chinese language. More recently, a new benchmark has appeared: SuperGLUE . There are not many solutions yet, but RoBERTa is in the first place here.
But overall, both RoBERTa and ERNIE perform better than XLNet and significantly better than BERT. RoBERTa, in turn, works a little better than ERNIE.
Graphs of knowledge
A lot of work has been devoted to combining two approaches: pre-trained networks and the use of rules in the form of knowledge graphs (Knowledge Graphs, KG).
For example: ERNIE: Enhanced Language Representation with Informative Entities . This paper highlights the use of knowledge graphs on top of the BERT language model. This allows you to get the best results on tasks such as determining the type of entity ( Entity Typing) and Relation Classification .
In general, the fashion for choosing names for models by the names of characters from "Sesame Street" leads to funny consequences. For example, this ERNIE has nothing to do with Baidu's ERNIE 2.0, about which I wrote above.

Another interesting work about generating new knowledge: COMET: Commonsense Transformers for Automatic Knowledge Graph Construction . The paper considers the possibility of using new architectures based on transformers for training knowledge-based networks. Knowledge bases in a simplified form are many triples: subject, attitude, object. They took two knowledge base datasets: ATOMIC and ConceptNet. And they trained a network based on the GPT (Generative Pre-trained Transformer) model. The subject and attitude were input and tried to predict the object. Thus, they got a model that generates objects by input subjects and relations.
Metrics
Another interesting topic at the conference was the choice of metrics. It is often difficult to evaluate the quality of a model in natural language processing tasks, which slows down progress in this area of machine learning.
In a Studying Summarization Evaluation Metrics in the Appropriate Scoring Range article, Maxim Peyar discusses the use of various metrics in a text summarization problem. These metrics do not always correlate well with each other, which hinders the objective comparison of various algorithms.
Or here's an interesting job: Automatic Evaluation for Multi-Sentence Texts . In it, the authors present a metric that can replace BLEU and ROUGE on tasks where you need to evaluate texts from several sentences.
The BLEU metric can be represented as Precision - how many words (or n-grams) from the model’s response are contained in the target. ROUGE is Recall - how many words (or n-grams) from the target are contained in the response of the model.
The metric proposed in the article is based on the WMD (Word Mover's Distance) metric - the distance between two documents. It is equal to the minimum distance between words in two sentences in the space of the vector representation of these words. More information about WMD can be found in the tutorial, which uses WMD from Word2Vec and from GloVe .
In their article, they offer a new metric: WMS (Word Mover's Similarity).
WMS(A, B) = exp(−WMD(A, B))
They then define SMS (Sentence Mover's Similarity). It uses an approach similar to the approach with WMS. As a vector representation of the sentence, they take the averaged vector of sentence words.
When calculating WMS, words are normalized by their frequency in the document. When calculating SMS sentences are normalized by the number of words in the sentence.
Finally, the S + WMS metric is a combination of WMS and SMS. In their article, they point out that their metrics correlate better with a person’s manual assessment.
Chatbots
The most useful part of the conference, in my opinion, were poster sessions. Not all reports were interesting, but if you started to listen to one, you will not leave for another in the middle of the report. With posters is another matter. There are several dozen of them at the poster session. You choose the ones that you liked and you can usually talk directly with the developer about technical details. By the way, there is an interesting site with posters from conferences . True, there are posters from two conferences there, and it is not known whether the site will be updated.
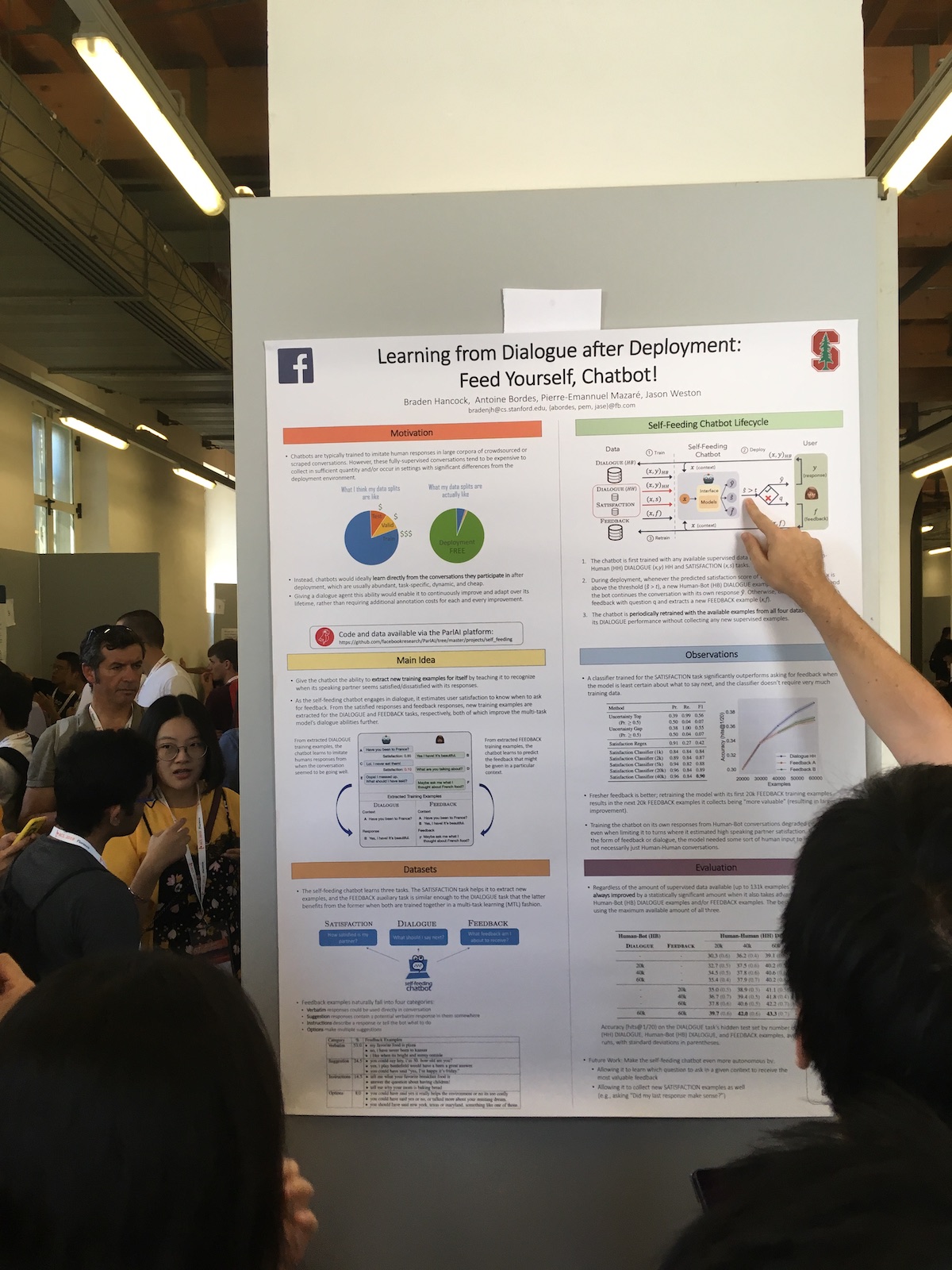
In poster sessions, large companies often presented interesting work. For example, here's a Facebook article Learning from Dialogue after Deployment: Feed Yourself, Chatbot! .
The peculiarity of their system is the expanded use of user responses. They have a classifier that evaluates how satisfied the user is with the dialogue. They use this information for different tasks:
- Use a measure of satisfaction as a metric of quality.
- They train the model, thus applying the approach of continuous learning (Continual Learning).
- Use directly in the dialogue. Express some human reaction if the user is satisfied. Or they ask what is wrong if the user is unsatisfied.
From the reports, there was an interesting story about the Chinese chatbot from Microsoft. The design and implementation of XiaoIce, an empathetic social chatbot
China is already one of the leaders in introducing artificial intelligence technologies. But often what is happening in China is not well known in Europe. And XiaoIce is an amazing project. It already exists for five years. Not many chatbots of this age are currently working. In 2018, it already had 660 million users.
The system has both a chit-chat bot and a skill system. The bot has already 230 skills. That is, they add approximately one skill per week.
To assess the quality of the chit-chat bot, they use the duration of the dialogue. And not in minutes, as is often done, but in the number of replicas in a conversation. They call this metric Conversation-turns Per Session (CPS) and write that at the moment its average value is 23, which is the best indicator among similar systems.
In general, the project is very popular in China. In addition to the bot itself, the system writes poetry, draws pictures, releases a collection of clothes , sings songs.
Machine translate
Of all the speeches that I attended, the liveliest was the simultaneous interpretation report by Liang Huang, representing Baidu Research.
He talked about such difficulties in modern simultaneous translation:
- There are only 3,000 certified simultaneous interpreters in the world.
- Translators can work only 15-20 minutes continuously.
- Only about 60% of the source text is translated.
Translation on whole sentences has already reached a good level, but for simultaneous translation there is still room for improvement. As an example, he cited their simultaneous interpretation system, which worked at the Baidu World Conference. The delay in translation in 2018 compared to 2017 was reduced from 10 to 3 seconds.
Not many teams do this, and few working systems exist. For example, when Google translates the phrase you write online, it constantly remakes the final phrase. And this is not simultaneous translation, because with simultaneous translation we cannot change the words already spoken.

In their system, they use prefix translation - part of a phrase. That is, they wait a few words and begin to translate, trying to guess what will appear in the source. The size of this shift is measured in words and is adaptive. The system after each step decides whether it is worth the wait, or whether it is already possible to translate. To evaluate this delay, they introduce the following metric: metric of Average Lagging (AL) .
The main difficulty with simultaneous translation is the different word order in languages. And the context helps to fight this. For example, you often need to translate the speeches of politicians, and they are quite stereotyped. But there are also problems. Then the speaker joked about Trump. So, he says, if Bush flew to Moscow, then it is highly likely that in order to meet with Putin. And if Trump has flown to, then he can meet and play golf. In general, when translating, people often come up with, add something from themselves. And let's say, if you need to translate some kind of joke, and they can’t do it right away, they can say: "A joke was said here, just laugh."
There was also an article about machine translation that received the award “The Best Long Paper”: Bridging the Gap between Training and Inference for Neural Machine Translation .
It describes such a machine translation problem. In the learning process, we generate word-for-word translation based on the context of known words. In the process of using the model, we rely on the context of the newly generated words. There is a discrepancy between training the model and using it.
To reduce this discrepancy, the authors suggest at the stage of training in the context to mix the words that are predicted by the model during the same training. The article discusses the optimal choice of such generated words.
Conclusion
Of course, a conference is not only articles and reports. It is also communication, dating and other networking. In addition, conference organizers are trying to somehow entertain the participants. At the ACL, at the main party there was a performance of tenors, Italy after all. And to summarize, there were announcements from the organizers of other conferences. And the most violent reaction among the participants was caused by messages from the organizers of EMNLP that this year the main party will be at Hong Kong Disneyland, and in 2020 the conference will be held in Dominican Republic.
All Articles