
HabrでOpenCLが何であり、それが何のためであるかを既に述べていますが、この標準は比較的新しいため、プログラムのパフォーマンスが他のソリューションにどのように関連するかは興味深いです。
このトピックでは、 OpenCLとGPUのCUDAおよびシェーダー 、CPUのOpenMPとを比較します。
N-tel問題のテストが実施されました。 それは並列アーキテクチャによく適合し、問題の複雑さはO(N 2 )として増大します。ここで、Nはボディの数です。
挑戦する
テストとして、粒子系の進化をシミュレートするタスクが選択されました。
スクリーンショット(クリック可能)は、静磁場内のN点の電荷のタスクを示しています。 計算の複雑さの点では、古典的なN体問題と違いはありません(写真がそれほど美しくない限り)。
測定中、画面出力は無効になり、FPSは1秒あたりの反復回数を意味します(各反復はシステムの進化における次のステップです)。


結果
GPU
このタスクのGLSLおよびCUDAコードは、すでにUNNの従業員によって作成されています。
NVidia Quadro FX5600
ドライバーバージョン197.45
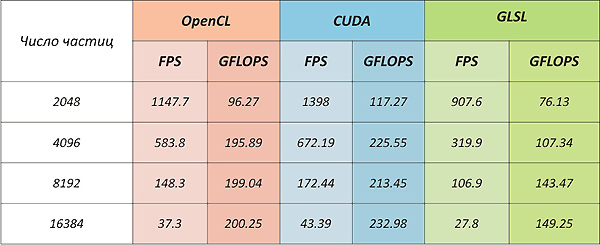
CUDAはOpenCLよりも約13%優れています。 さらに、このアーキテクチャのこのタスクで理論的に可能なパフォーマンスを評価すると、CUDAの実装がそれに到達します。
( CUDAとOpenCLのパフォーマンス比較では、OpenCLコアのパフォーマンスはCUDAを13%から63%失います)
テストはQuadroシリーズのカードで実行されたという事実にもかかわらず、通常のGeForce 8800 GTSまたはGeForce 250 GTSが同様の結果をもたらすことは明らかです(3つのカードはすべてG92チップに基づいています)。
Radeon HD4890
ATI Stream SDKバージョン2.01
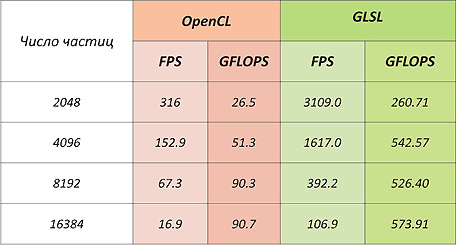
OpenCLは、AMDカードのシェーダーに負けてしまいます。これは、それらのコンピューティングユニットがVLIWアーキテクチャを備えているためです(最適化後)多くのシェーダープログラムがうまく機能しますが、OpenCLコード(ドライバーの一部)のコンパイラーは最適化が不十分です。
また、この非常に控えめな結果は、AMDカードが物理レベルでローカルメモリをサポートしないが、ローカルメモリ領域をグローバルにマップするという事実によって引き起こされる可能性があります。
CPU
OpenMPを使用するコードは、IntelおよびMicrosoftのコンパイラーを使用してコンパイルされました。
Intelは、中央プロセッサでOpenCLコードを実行するためのドライバーをリリースしなかったため、ATI Stream SDKが使用されました。
Intel Core2Duo E8200
ATI Stream SDKバージョン2.01
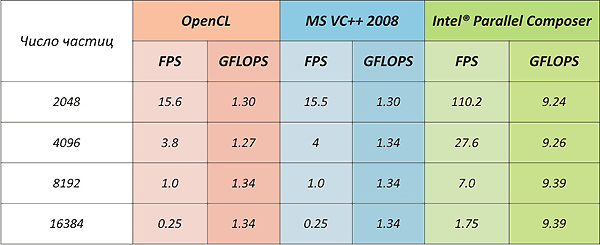
MS VC ++を使用してコンパイルされたOpenMPコードのパフォーマンスは、OpenCLとほぼ同じです。
これは、IntelがOpenCLを解釈するためのドライバーをリリースしておらず、AMDのドライバーが使用されているという事実にもかかわらずです。
Intelのコンパイラは「正直」にそれを行いませんでした。メインプログラムループを完全に展開し、約8k回繰り返します(粒子の数はコード内の定数によって設定されました)。また、SSE命令の使用によりパフォーマンスが7倍になりました。 しかし、勝者はもちろん判断されません。
特徴的に、コードは古いAMD Athlon 3800+でも開始されましたが、Intelのような傑出した結果を待つ必要はありません。
おわりに
- 現時点では、ドライバーは完全には開発されておらず、 標準に何かが入っている場合もありますが、実際のコードでは使用できません。 (たとえば、OpenCLのプログラムでのテクスチャのサポートは、HD5xxxシリーズのATIカードでのみ登場しました)。
- ドライバーはこの特定のプラットフォームに最適なコードを生成しません。この点に関して、メーカーには開発の余地があります。
- OpenCLでの書き込みは、CUDAドライバーAPIでの書き込みとほぼ同じです。
- それはより多くの機能のようですが、必ずしも便利ではありません。 300の行の末尾のようなものが表示されますが、これはプログラムのいずれに対しても必ず伸びます。 これは、並列コンピューティング用に設計されたほぼすべてのデバイスでコードを実行できるという事実に対する料金です。
- すでに、OpenCLプログラムは競合他社と比較してまともなパフォーマンスを示しており、汎用並列コンピューティングに正常に使用できます。 そして、本物のジェダイにとっては、300行のコードが邪魔にならないことを認めなければなりません。特に、別のライブラリに移動できるためです。
ありがとう
コードが作成され、測定が行われ、結果はNNSU VMK Denis Bogolepovの大学院生とNSTU IRITの学生であるMaxim Zakharovによっても解釈されました。
彼らに感謝します。