質問番号0-なぜですか?
pnp4nagiosに関する投稿で、 「Nagios / Pnp4Nagiosは、システムの状態に関する統計情報の収集に代わるものではありません」と書きました。 なぜそう思うのですか? 1)システムの状態の統計は広範であり、多くのインジケータを含むため2)それらを監視すること、またはアラートを生成することは常に意味をなさない。 たとえば、ディスクが実行するI / O操作の数やコンテキストの切り替えがいつ発生するかを知ることは悪くありませんが、ほとんど重要ではありません。 それに、Nagiosはこれを目的としていません。 この記事では、システムの詳細な説明は行いません。自分の観点からすると、特に興味深いのは瞬間だけです。
質問番号1-収集した理由
私がムニン、サボテンなどから収集したものを選んだ理由を強調します。
- 拡張性
- 明度
- コンセプト-すべてがプラグイン
- データ収集と記録は分離されています
- 収集されたインジケータの数
- 拡張性
collectdの一般的な作業スキーム:
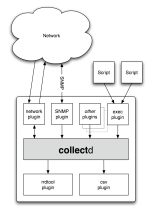
拡張性
プッシュは、中央ノードでデータを収集するために使用されます(Cacti / Muninでのポーリング/プルとは異なります)。 複数のノードをデータストレージに含めることができ、さらに、異なるノード上のストレージにデータを分離できます。 データ転送は別のプラグイン-ネットワークです。
軽量
メインデーモンとプラグインはCで記述されており、システムをロードせずにデータ収集の10秒間隔を簡単に生き延びます。
すべてがプラグインです
CPU使用率データコレクター-プラグイン。 プロセスに関する情報-プラグイン。 RRD / CSVを記録して作成する-プラグイン。
データ収集と記録は分離されています
データは読み取りと書き込みの両方が可能です。 collectdは、プラグインを「リーダー」と「ライター」に分割します。 情報を収集するのは読者です。 データが読み取られた後、それらは登録されたライターに送信されますが、一般的にはどのライターでもかまいません。 最も「人気のある」ライターは、データをセントラルノードとRRDToolに送信するネットワークプラグインであり、原則として、RRDでの統計を意味します。 したがって、ノードでは、RRDに統計情報を保持し、さらに処理するためにデータを送信できます。
収集されたインジケータの数
現在、システムとアプリケーションに関する情報を収集するための90以上の基本的なプラグインがあります。
拡張性
独自のデータソースを追加するには、次のものがあります。
- execプラグインは一般に標準的な拡張メソッドです-プログラムは開始し、stdoutへのデータ出力は処理されますが、collectdにはプラスがあります-値が出力された後にプログラムを終了する必要はありません。特にスクリプトに当てはまります。
- Python / Perl / Javaバインディング-リーダーとライターの両方、以下でより詳細な説明
バインディング(バインディング)による拡張性
バインディングは、本質的に、他の言語から収集された内部メカニズムにアクセスし、プラグインを記述するためのプラグインです。 現在サポートされているのはJava / Perl / Pythonです。 たとえば、Pythonの場合、インタプリタはcollectdの開始時に起動され、メモリに保存され、数秒ごとに実行するリソースを節約し、スクリプトがAPIにアクセスできるようにします。
スクリプトはデータプロバイダー(リーダー)および/またはライター(ライター)として登録できるため、登録されたプロシージャは構成で指定された時間間隔ごとに呼び出されます。 リーダーですべてが明確な場合、ライターは特別な注意を払う必要があります-通過するすべてのデータを処理するために、スクリプトを簡単に組み込むことができます。 たとえば、保存された値の独自のベースを作成できます。 Python でのそのようなプラグインの簡単な例は 、プロジェクトのドキュメントにあります。
興味深い便利なプラグイン機能
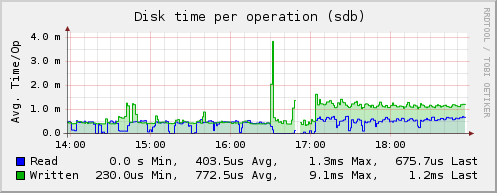
- まず第一に、私はディスクプラグインが好きでした-箱から出して、それは平均ディスク応答時間を測定することができました:
- Tailプラグイン-ファイルをtail(1)として読み取り、regexpを使用して値を取得できます。 事前に設定された値のうち、最小/最大/平均を取り、レコードの総数を計算し、たとえばnginxの場合、応答時間とロケーションのリクエストに関する統計を収集できます。
- リクエストサービス時間に関するレコードをnginxログに追加します。
log_format maintime '$remote_addr - - [$time_local] reqtime=$request_time "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" "$host" upstream: $upstream_addr gzip:"$gzip_ratio"';
- collectd構成にエントリを作成します。
ロードプラグインテール <プラグイン「テール」> <ファイル "/var/log/nginx/somesite.access.log"> インスタンス「nginxproxy」 <一致> 正規表現「reqtime =([0-9] + \\。[0-9] +)」 DSType "GaugeMax" タイプ「レイテンシー」 インスタンス「最大応答時間」 </一致> <一致> 正規表現「reqtime =([0-9] + \\。[0-9] +)」 DSType "GaugeAverage" タイプ「レイテンシー」 インスタンス「平均応答時間」 </一致> <一致> 正規表現 "。*" DSType "CounterInc" タイプ「派生」 インスタンス「リクエスト」 </一致> </ファイル> </ Plugin>
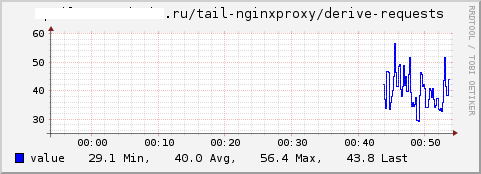
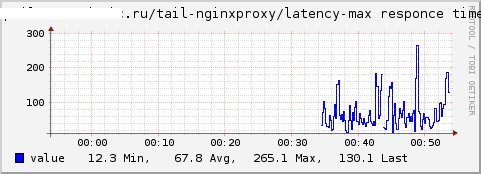
リクエストの総数、最大応答時間、平均応答時間のグラフをそれぞれ取得します。
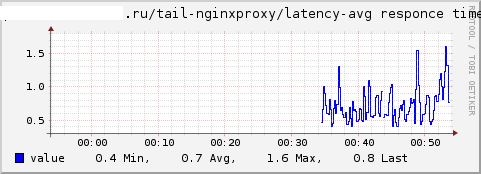
Curlプラグインには同様の機能があります。
- リクエストサービス時間に関するレコードをnginxログに追加します。
- プロセスプラグイン-フィルターに該当する実行中のプロセスの数、スレッドの数、占有メモリのサイズ、入出力などに関する情報を収集できます。
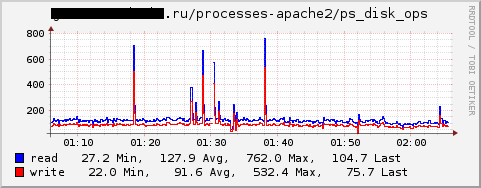
この場合、データは完全に正しいわけではありません-これらは読み取り/書き込みディスク操作ではありませんが、一般的にはすべて、つまり ソケットエントリもカウントされます。 私は著者に通知しました。多分彼らは次のバージョンでそれを修正するでしょう。
- UnixSockプラグインを使用すると、 単純なテキストプロトコルを使用してデータを交換できます。特に、カウンター値を送受信できます。 このプラグインを使用すると、Nagiosに統合できます。
その他の機能
フィルターとチェーン
バージョン4.6以降、iptablesのチェーンと同様のフィルターとチェーンのメカニズムが登場しました。 このメカニズムを使用すると、たとえば、タイムスタンプが現在の時間よりもNだけ大きいまたは小さい値を切り捨てるなど、データをフィルター処理できます。これは、サーバーでクロックが停止した場合に役立ちます。 RRDは将来から時間を取得し、測定値に歪みが生じます。
通知としきい値
バージョン4.3以降、 通知としきい値の基本システムが登場しました。 リーダーやライターと同様に、「プロデューサー」と「コンシューマー」があります。前者は通知を生成し、後者は通知を処理します。 特に、Execプラグインは、通知への応答(スクリプトの実行など)とスクリプトからの通知の送信の両方を行うことができます。
一連のしきい値を設定することにより、異常が発生したときに通知を作成できます。 ただし、これらの基本機能は同じNagiosに置き換わるものではないことを理解してください。 Nagiosを完全に使用するには、バンドルされたcollectd-nagiosプログラムを使用して、UnixSockプラグインによって作成されたソケットを照会し、Nagiosの標準形式で結果を返すことができます。
欠点
概して、グラフ表示システムのみを分類できます。 1つのホストから約200トンのカウンターを生成できることを考慮すると、視覚化は最後の場所ではありません。 標準のcollection3インターフェースは悪くありませんが、完璧にはほど遠いです。 現在、いくつかの独立したチャート表示システムが開発されていますが、まだお勧めできません。
その他
Sebastian Harl(tokee)の開発者の1人はDebianのパッケージのメインメンテナーです。そのため、バックポートにはほとんど常に最新バージョンがあります。