人文科学の分野でITがどのように適用されるのかについて話をすることにしました(メリットあり!)

ミリオンブックは、誰もがGoogleブックスで見るGoogleの書籍デジタル化プロジェクトの名前です。 2007年に100万冊の書籍が電子形式に変換されました。 現在、Googleの新たな課題は、3,000万冊の本をデジタル化することです。
そして、人文科学に新たな疑問が生じました。この文学の海をどうするか? 最近出版された何百万もの本をどうするか?
まず、百万冊の本を読むことができないことは明らかです。
第二に、人文科学がこれを読むべきであることは明らかです。
実際、人文科学と自然科学者の根本的な違いは、フィクションの全量に遅れないようにする義務です。 Kalevalaを読んだことがないかもしれませんが、それが何であり、どのようであるかを想像する必要があります。
どうする?
もちろん、新しい技術の支援を求めてください。 まず、データマイニング。 これを行うために、ノースウェスタン大学とイリノイ大学でMONKプロジェクトが開始されました。
MONKは、テキストとテキストの繰り返しパターンを検出するデータベースとプログラムで構成されます。 MorphAdornerは、個々の単語と文、品詞、およびトークンの間のリンクを追跡します。 また、さまざまな方言も考慮されます。 このプログラムは、学習と自己学習、テキストの分類、および確率の計算が可能です(たとえば、いくつかのテキストでの単語の出現頻度により、以下のテキストの出現確率を計算します)。 したがって、このツールを使用すると、任意のテキストのDNAを取得できます。
また、1つのグループにまとめられたテキストグループの主要な言語パターンを見つけることもできます。たとえば、1790年から1900年の間に女性によって書かれたテキストのDNAは次のようになります。
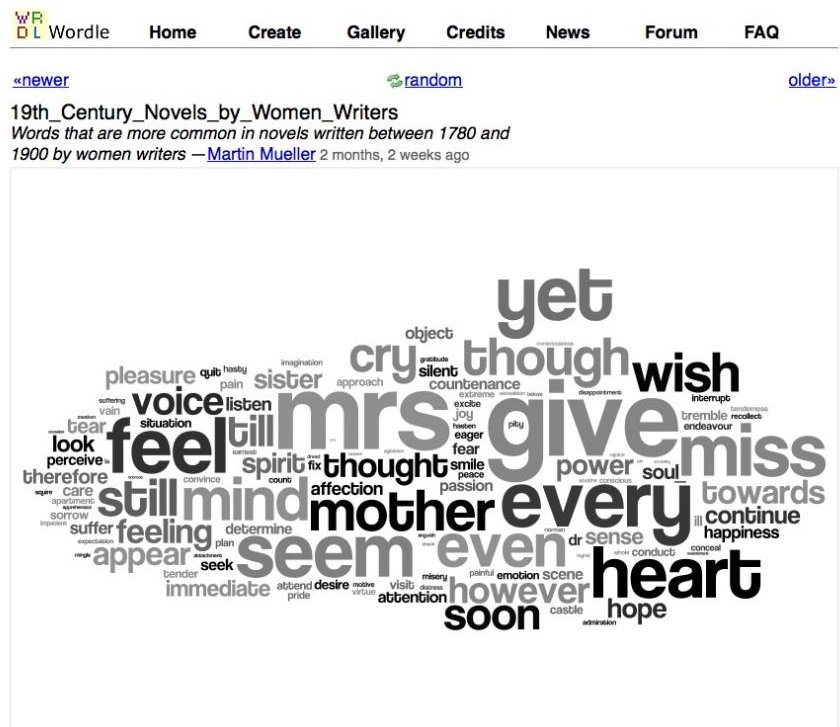
そして、同じ時代の男性によって書かれたテキストのDNA-このように:
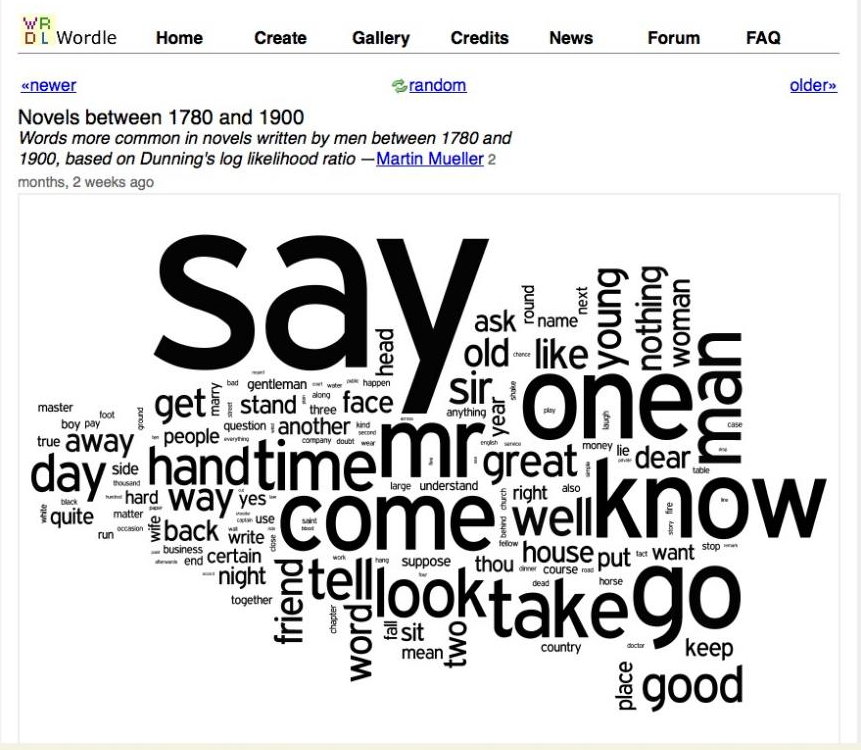
現在、MONKには大きな期待が寄せられています。 たとえば、彼らはその助けを借りて、疑わしいテキストの著者を特定し、そのテキストが書かれた年、さらには著者の性別を調べたいと考えています。 もちろん、何百万冊もの本を読む必要がなくなるだけで、書かれているものに遅れずについていくことができます。
執筆時には、次のソースが自由に使用されました。