
AI MTSセンターNikita Semenovの主要な開発者にフロアを提供します。
こんにちは 序文として、有名な科学者のジャン・ルクン、ジョシュア・ベンジオ、ジェフリー・ヒントンを引用したいと思います。これらは最近、情報技術分野で最も権威ある賞の1つであるチューリング賞を受賞した人工知能の先駆者です。 Nature誌の2015年の号の1つで、彼らは非常に興味深い記事「ディープラーニング」をリリースしました。興味深いフレーズがありました。「ディープラーニングには、手作りの機能を必要とせずに生信号を処理する能力が約束されていました」。 正しく翻訳することは困難ですが、意味は次のようなものです。「深層学習には、手作業で標識を作成することなく生の信号に対処する能力が約束されています。」 私の意見では、開発者にとってこれは既存のものすべての主な動機です。
古典的なアプローチ
それでは、古典的なアプローチから始めましょう。 機械と話すことの理解について話すとき、私たちは自分の声の助けを借りていくつかのサービスを制御したい、または何らかの論理で彼の音声コマンドに応答するシステムの必要性を感じている特定の人がいることを意味します。
この問題はどのように解決されますか? クラシックバージョンでは、前述のように、音声認識コンポーネント、自然言語理解コンポーネント、特定のビジネスロジックを担当するコンポーネントの3つの大きなコンポーネントで構成されるシステムが使用されます。 最初にユーザーが特定の音声信号を作成します。音声信号は音声認識コンポーネントに到達し、音声からテキストに変わります。 次に、テキストは自然言語理解コンポーネントに分類され、そこから特定のセマンティック構造が取り出されます。これは、ビジネスロジックを担当するコンポーネントに必要です。
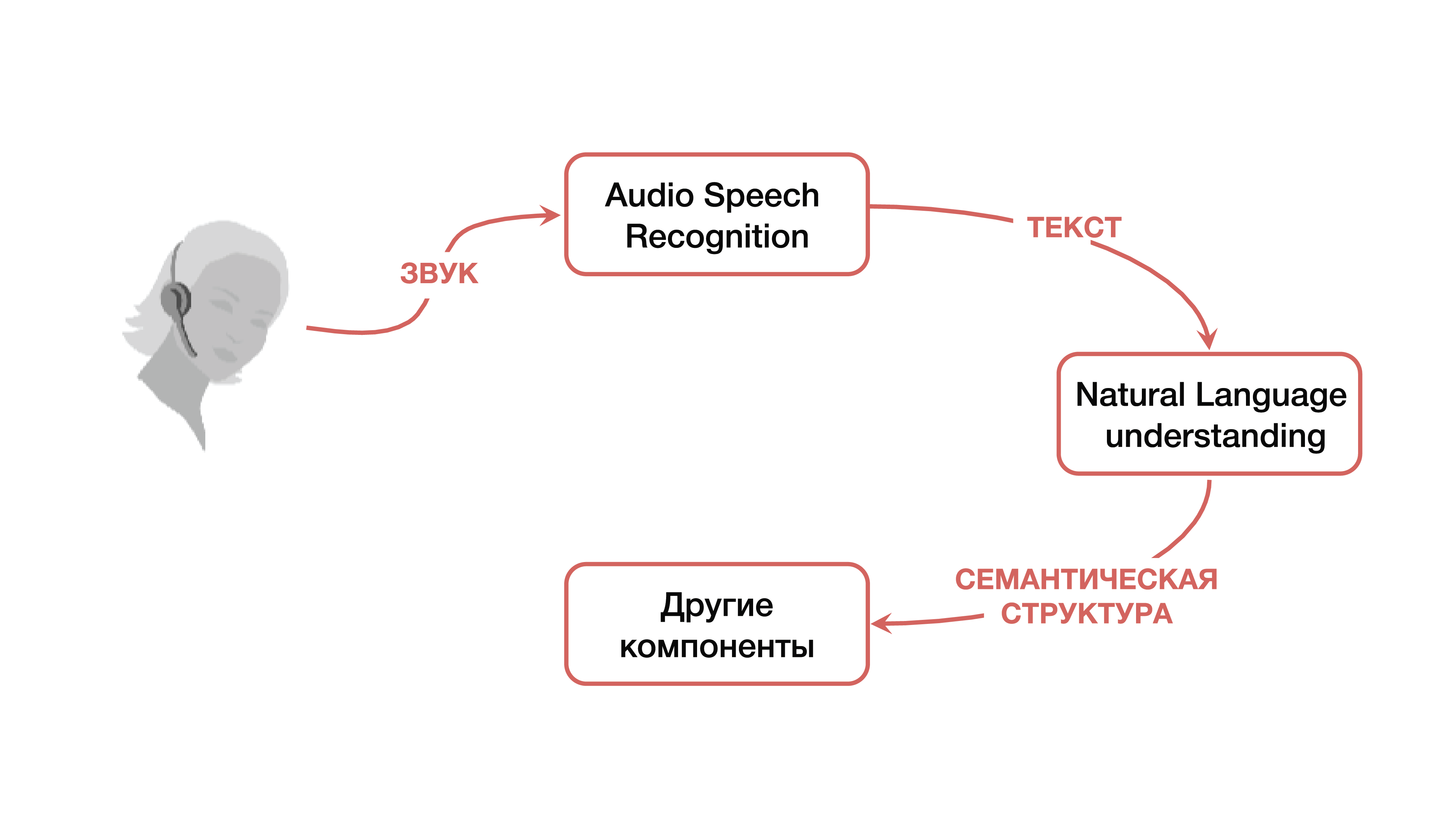
セマンティック構造とは何ですか? これは、いくつかのタスクを1つにまとめる一般化/集約の一種です-理解を容易にするために。 構造には3つの重要な部分が含まれます:ドメインの分類(トピックの特定の定義)、意図の分類(実行する必要があることの理解)、および次の段階の特定のビジネスタスクに必要なカードに記入するための名前付きエンティティの割り当て。 セマンティック構造が何であるかを理解するために、Googleが最もよく引用している簡単な例を検討できます。 「アーティストの曲を再生してください」という簡単なリクエストがあります。

このリクエストのドメインと主題は音楽です。 意図-曲を再生します。 「歌を再生する」カードの属性-どんな種類の歌、どんな種類のアーティスト。 このような構造は、自然言語を理解した結果です。
会話音声を理解する複雑で多段階の問題を解決することについて話す場合、私が言ったように、それは2つの段階から成ります。最初は音声認識で、2番目は自然言語の理解です。 古典的なアプローチでは、これらの段階を完全に分離します。 最初のステップとして、入力および出力で音響信号を受信する特定のモデルがあり、言語および音響モデルと辞書を使用して、この音響信号から最も可能性の高い言語仮説を決定します。 これは完全に確率的な話です-既知のベイズ式に従って分解し、サンプルの尤度関数を記述して最尤法を使用できる式を取得できます。 単語シーケンスWにこの単語シーケンスの確率を掛けると、信号Xの条件付き確率があります。

最初の段階-音声信号から言葉の仮説を得ました。 次に、2番目のコンポーネントがあります。このコンポーネントは、この非常に言語的な仮説を採用し、上記のセマンティック構造を抽出しようとします。
言語シーケンスWが入力にある場合、意味構造Sの確率があります。

別々に教えられるこれらの2つの要素/ステップで構成される古典的なアプローチの悪い点は何ですか(つまり、最初に最初の要素のモデルを訓練し、次に2番目のモデルを訓練します)?
- 自然言語理解コンポーネントは、ASRが生成する高レベルの言語仮説と連携します。 これは大きな問題です。最初のコンポーネント(ASR自体)が低レベルの生データで動作し、高レベルの言語仮説を生成し、2番目のコンポーネントが入力として仮説を取得します-一次ソースからの生データではなく、最初のモデルが与える仮説-仮説を構築します最初の段階の仮説について。 「条件付き」になりすぎるため、これはかなり問題の多い話です。
- 次の問題:セマンティックな構造を構築するために必要な単語の重要性と、言語仮説を構築する際に最初のコンポーネントが好むものとの間に関連性がありません。 つまり、言い換えれば、仮説はすでに構築されているということです。 私が言ったように、それは3つのコンポーネントに基づいて構築されています:音響部分(入力に入って何らかの形でモデル化されたもの)、言語部分(すべての言語エングラムを完全にモデル化する-発話の確率)および辞書(単語の発音)。 これらは結合する必要がある3つの大きな部分であり、いくつかの仮説がそこにあります。 ただし、同じ仮説の選択に影響を与える方法はないため、この仮説は次の段階で重要になります(原則として、完全に別々に学習し、互いに影響を与えないという点にあります)。
End2Endアプローチ
古典的なアプローチとは何か、問題は何かを理解しました。 End2Endアプローチを使用して、これらの問題を解決してみましょう。
End2Endとは、さまざまなコンポーネントを単一のコンポーネントに結合するモデルを意味します。 アテンション(アテンション)モジュールを含むエンコーダーデコーダーアーキテクチャーで構成されるモデルを使用してモデル化します。 このようなアーキテクチャは、音声認識の問題や、自然言語の処理、特に機械翻訳に関連するタスクでよく使用されます。
私たちが区別する前に提起された古典的なアプローチの問題を解決できるようなアプローチの実装のための4つのオプション:これらは直接、共同、マルチステージおよびマルチタスクモデルです。
ダイレクトモデル
直接モデルは、入力の低レベルの未加工の属性、つまり 低レベルのオーディオ信号、および出力ですぐにセマンティック構造を取得します。 つまり、1つのモジュール、つまり古典的なアプローチからの最初のモジュールの入力と、同じ古典的なアプローチからの2番目のモジュールの出力を取得します。 まさにそのような「ブラックボックス」。 ここからいくつかのプラスとマイナスがあります。 モデルは入力信号を完全に転写することを学習しません-これは明確なプラスです。大きな大きなマークアップを収集する必要がないため、多くのオーディオ信号を収集する必要がなく、それをマークアップ用のマーカーに与える必要がありません。 この音声信号と対応するセマンティック構造が必要です。 そしてそれだけです。 これにより、データのマークアップに伴う労力が軽減されます。 おそらく、このアプローチの最大のマイナス点は、条件付きで2つの問題を即座に解決しようとする「ブラックボックス」にとってタスクが複雑すぎることです。 最初に、彼は自分の内部で、ある種の文字起こしを構築し、次にこの文字起こしから意味構造を明らかにしようとします。 これはかなり難しいタスクを起こします-転写の一部を無視することを学ぶこと。 そして、それは非常に難しいです。 この要素は、このアプローチのかなり大きなマイナスです。
確率について話す場合、このモデルは、モデルパラメーターθをもつ音響信号Xから最も可能性の高い意味構造Sを見つける問題を解決します。
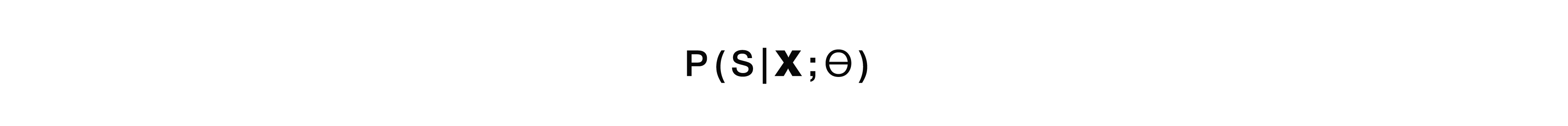
ジョイントモデル
代替手段は何ですか? これは共同モデルです。 つまり、一部のモデルは直線に非常に似ていますが、1つの例外があります。出力は既に言語シーケンスで構成されており、セマンティック構造は単純に連結されています。 つまり、入力には音声信号とニューラルネットワークモデルがあり、出力には既に音声による書き起こしと意味構造の両方があります。
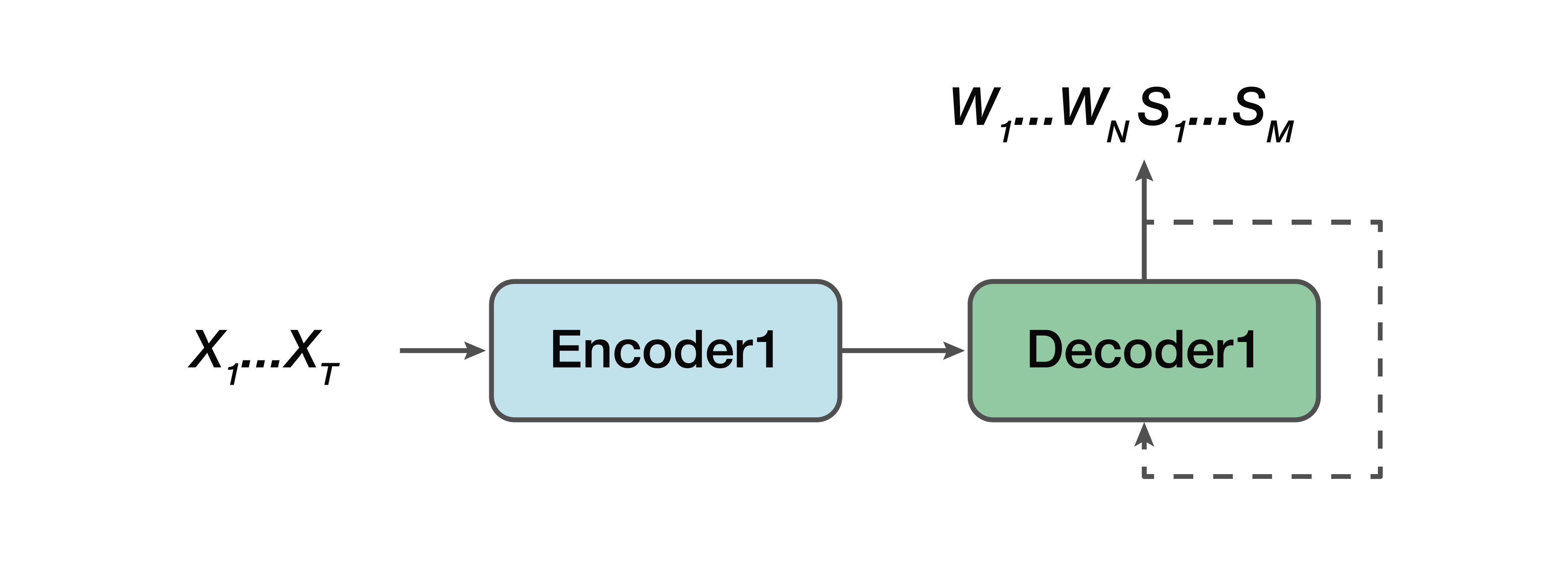
長所から:シンプルなエンコーダー、シンプルなデコーダーがまだあります。 直接モデルの場合のように、モデルは一度に2つの問題を解決しようとしないため、学習が容易になります。 もう1つの利点は、セマンティック構造が低レベルのサウンド属性に依存していることです。 繰り返しますが、1つのエンコーダー、1つのデコーダーです。 そして、それに応じて、プラスの1つは、この非常にセマンティックな構造とその転写自体への直接的な影響を予測することに依存していることに注意することができます。
繰り返しますが、パラメータWを持つ音響信号Xから最も可能性の高い単語Wのシーケンスと対応する意味構造Sを見つける必要があります。
マルチタスクモデル
次のアプローチは、マルチタスクモデルです。 繰り返しますが、エンコーダーデコーダー方式ですが、例外が1つあります。
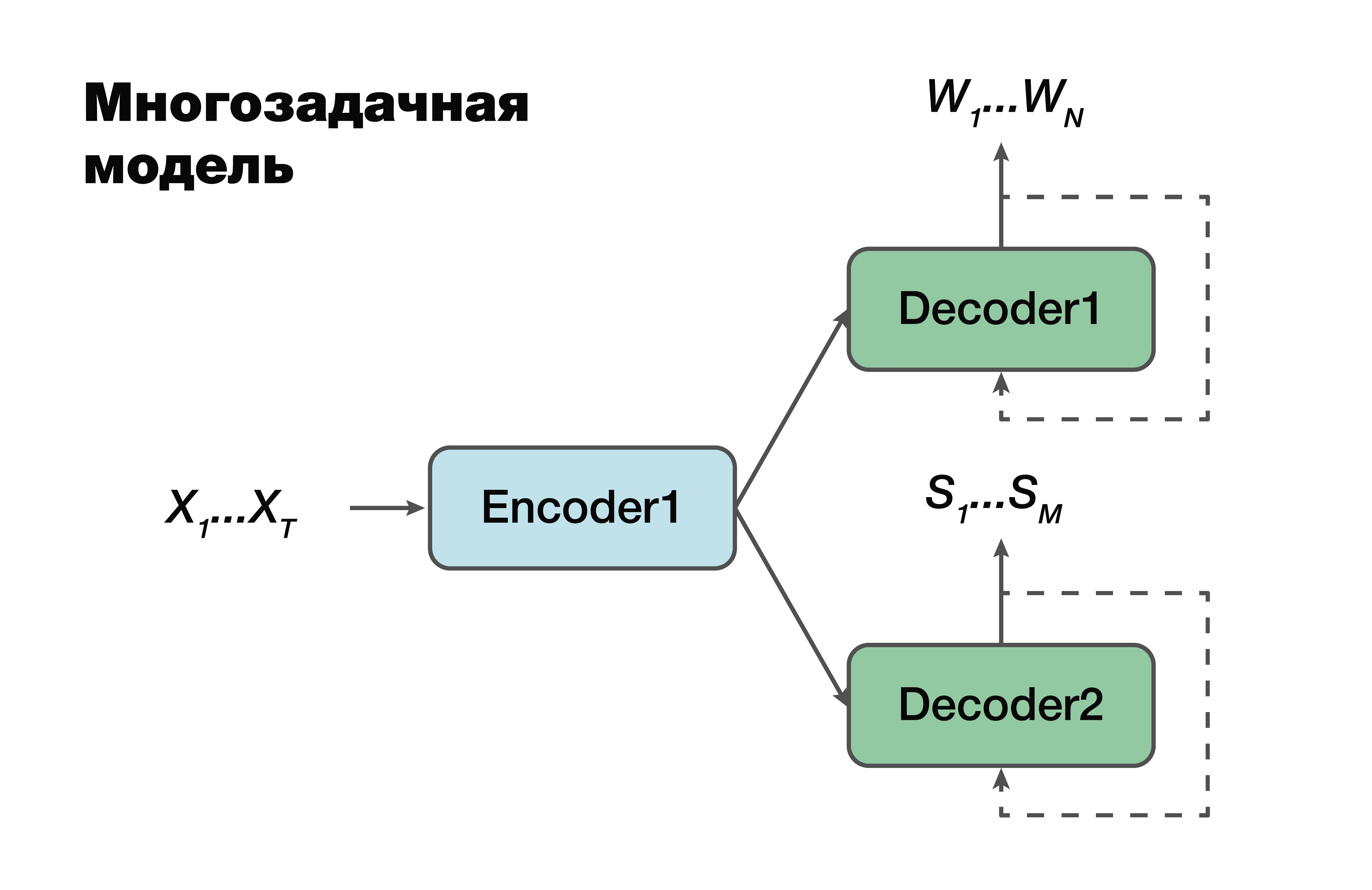
各タスク、つまり言語シーケンスを作成し、セマンティック構造を作成するために、単一のエンコーダーを生成する1つの共通の非表示表現を使用する独自のデコーダーがあります。 機械学習で非常に有名なトリックで、仕事で頻繁に使用されます。 2つの異なる問題を一度に解決すると、ソースデータの依存関係をより適切に検索できます。 そして、これの結果として-最適なパラメーターが複数のタスクに対して一度に選択されるため、最高の一般化能力。 このアプローチは、データの少ないタスクに最適です。 また、デコーダーは、エンコーダーが作成する1つの隠れたベクトル空間を使用します。

すでに確率では、エンコーダーおよびデコーダーモデルのパラメーターに依存していることに注意することが重要です。 そして、これらのパラメーターは重要です。
多段モデル
私の意見では、最も興味深いアプローチ、つまり多段階モデルに目を向けます。 非常に注意深く見ると、実際にはこれは1つの例外を除いて同じ2つのコンポーネントの古典的なアプローチであることがわかります。
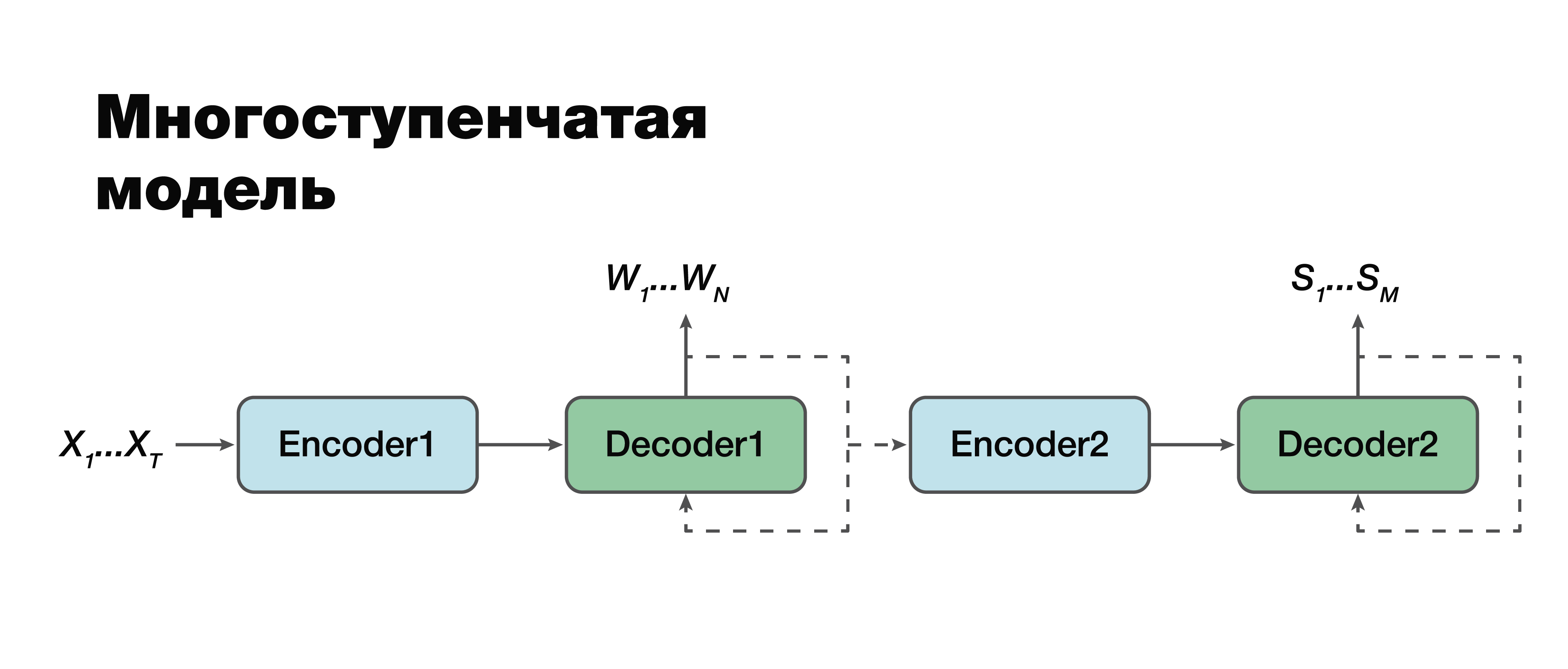
ここで、モジュール間の接続を確立し、それらを単一モジュールにすることができます。 したがって、意味構造は条件付きで転写に依存していると見なされます。 このモデルを使用するには、2つのオプションがあります。 これらの2つのミニブロック、つまり最初と2番目のエンコーダーデコーダーを個別にトレーニングできます。 または、それらを組み合わせて、両方のタスクを同時にトレーニングします。
前者の場合、2つのタスクのパラメーターは関連していません(異なるデータを使用してトレーニングできます)。 大量の音と、それに対応する言葉のシーケンスと文字起こしがあるとします。 私たちはそれらを「運転」し、最初の部分だけを訓練します。 優れた転写シミュレーションが得られます。 次に、2番目の部分を取り上げ、別の建物でトレーニングします。 最初の部分と2番目の部分を別々に取得してトレーニングしたため、このアプローチでは従来のアプローチと100%一貫したソリューションを接続して取得します。 そして、ケースの接続モデルをトレーニングします。これには、オーディオ信号、対応するトランスクリプション、対応する意味構造の3つのデータが既に含まれています。 そのような建物がある場合、特定の小さなタスクのために、大きな建物で個別に訓練されたモデルを再訓練し、そのようなトリッキーな方法で最大の精度を得ることができます。 このアプローチにより、第1段階の第2段階のエラーを考慮することにより、転写のさまざまな部分の重要性と意味構造の予測への影響を考慮することができます 。
入力音響信号X が第1ステージモデルのパラメーターにも依存する場合、最終タスクは古典的なアプローチと非常によく似ていますが、大きな違いは1つだけです。つまり、関数の2番目の項-意味構造の確率の対数です。

ここで、2番目のコンポーネントは1番目と2番目のモデルのパラメーターに依存することに注意することも重要です。
アプローチの精度を評価するための方法論
ここで、精度を評価するための方法論を決定する価値があります。 実際、古典的なアプローチでは適さない特徴を考慮するために、この精度をどのように測定するのでしょうか? これらの個別のタスクには、古典的なラベルがあります。 音声認識コンポーネントを評価するには、従来のWERメトリックを使用できます。 これはワードエラー率です。 それほど複雑ではない式に従って、単語の挿入、置換、置換の数を考慮し、それらをすべての単語の数で除算します。 そして、認識の質の特定の評価特性を取得します。 コンポーネント単位のセマンティック構造では、F1スコアを単純に考慮することができます。 これは、分類問題の古典的なメトリックでもあります。 ここでは、プラスまたはマイナスのすべてが明確です。 充実感があり、正確さがあります。 そして、これはそれらの間の調和平均にすぎません。
しかし、問題は、入力文字起こしと出力引数が一致しない場合、または出力がオーディオデータである場合の精度の測定方法です。 Googleは、音声認識の最初のコンポーネントを予測することの重要性を考慮したメトリックを提案しました。これは、この認識が2番目のコンポーネント自体に与える影響を評価することによって行われます。 彼らはそれをArg WERと呼びました。つまり、意味構造の本質に従ってWERの重さを量っています。
「5時間アラームを設定します」というリクエストを受け取ります。 このセマンティック構造には、「日付時間」タイプの引数「5時間」などの引数が含まれます。 音声認識コンポーネントがこの引数を生成する場合、この引数のエラーメトリック、つまりWERは0%であることを理解することが重要です。 この値が5時間に対応しない場合、メトリックのWERは100%です。 したがって、単純にすべての引数の加重平均値を考慮し、全体として、音声認識コンポーネントを作成する転写エラーの重要性を推定する特定の集約メトリックを取得します。
このトピックに関する調査の1つで実施したGoogleの実験の例を挙げましょう。 5つのドメイン、5つの被験者からのデータを使用しました:Media、Media_Control、Productivity、Delight、None-トレーニングテストデータセットのデータの対応する分布。 すべてのモデルがゼロからトレーニングされたことに注意することが重要です。 Cross_entropyが使用され、ビーム検索パラメーターは8、彼らが使用したオプティマイザー、もちろんAdamです。 もちろん、TPUの大きなクラウド上で考慮されます。 結果は何ですか? これらは興味深い数字です。
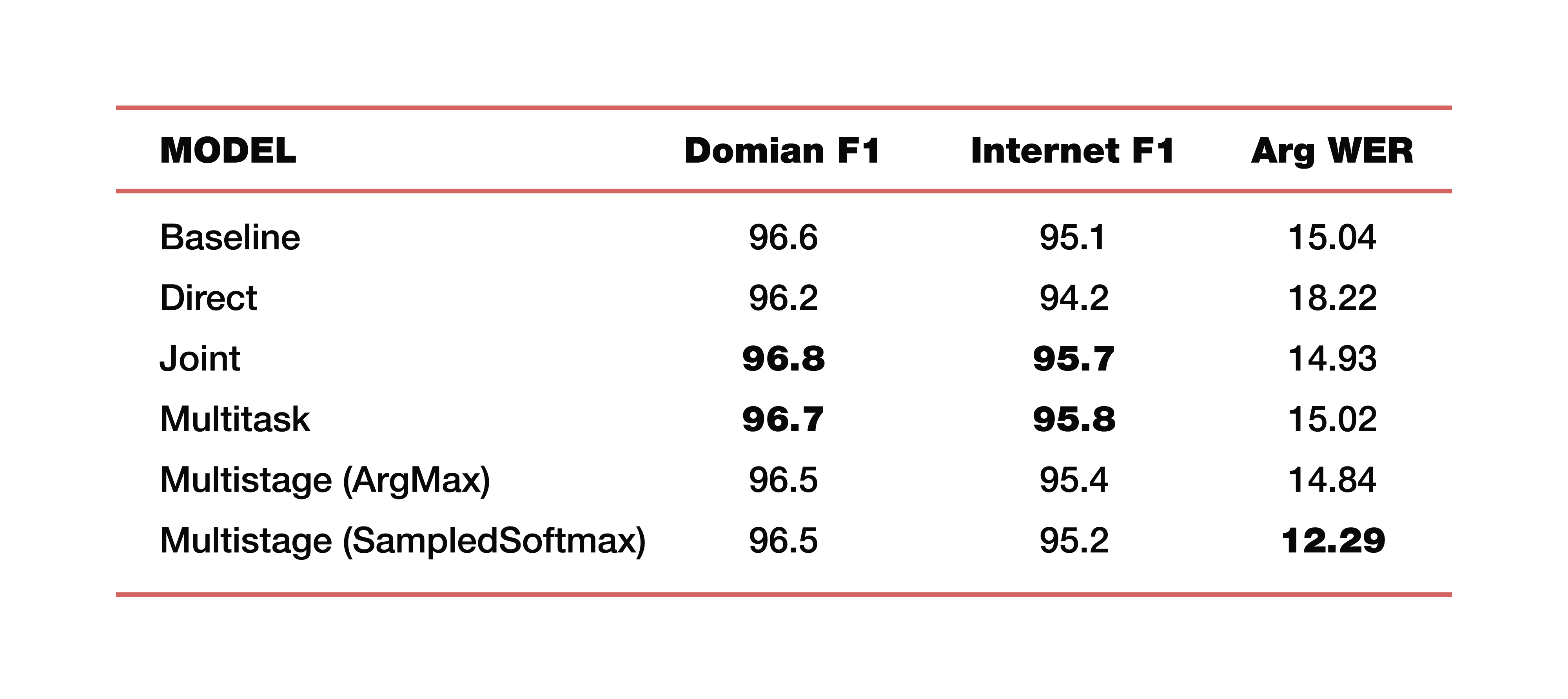
理解のために、ベースラインは、冒頭で述べたように、2つのコンポーネントで構成される古典的なアプローチです。 以下は、直接モデル、接続モデル、マルチタスクモデル、およびマルチステージモデルの例です。
2つのマルチステージモデルはいくらですか? 最初と2番目のパーツの接合部で、異なるレイヤーが使用されました。 最初のケースではこれはArgMax、2番目のケースではSampedSoftmaxです。
注目に値するものは何ですか? 従来のアプローチでは、3つのメトリックすべてが失われます。これは、これら2つのコンポーネントの直接的なコラボレーションの推定値です。 はい、私たちはそこで転写がどれだけうまく行われるかには興味がありません。意味構造を予測する要素がどれだけうまく機能するかにのみ興味があります。 F1-トピックごと、F1-意図ごと、およびエンティティの引数で考慮されるArgWerメトリックの3つのメトリックによって評価されます。 F1は、精度と完全性の間の加重平均と見なされます。 つまり、標準は100です。これに対して、ArgWerは成功ではなく、エラーです。つまり、標準は0です。
接続されたマルチタスクモデルが、トピックと意図のすべての分類モデルを完全に上回ることは注目に値します。 また、多段階のモデルでは、ArgWerの合計が非常に大きく増加します。 なぜこれが重要なのですか? 口語スピーチの理解に関連するタスクでは、ビジネスロジックを担当するコンポーネントで実行される最終アクションが重要だからです。 ASRによって作成された文字起こしに直接依存するのではなく、ASRとNLUコンポーネントが連携して動作する品質に依存します。 したがって、argWERメトリックのほぼ3つのポイントの差は、このアプローチの成功を示す非常に優れた指標です。 また、トピックと意図の定義により、すべてのアプローチに同等の値があることに注意してください。
話し言葉を理解するためにそのようなアルゴリズムを使用するいくつかの例を挙げます。 Googleは、会話の音声を理解するタスクについて話すとき、まず人間とコンピューターのインターフェースに注意します。つまり、これらはGoogle Assistant、Apple Siri、Amazon Alexaなどのあらゆる種類の仮想アシスタントです。 2番目の例として、対話型音声応答などのタスクプールに言及する価値があります。 つまり、これはコールセンターの自動化に従事している特定のストーリーです。
そのため、SLUにとってより重要なエラーにモデルが焦点を当てるのに役立つ共同最適化を使用する可能性があるアプローチを検討しました。 話し言葉を理解するというタスクに対するこのアプローチは、全体的な複雑さを大幅に簡素化します。
辞書、言語モデル、アナライザーなどの追加リソースを必要とせずに、論理的な結論を出す機会があります。 タスクは「直接」解決されます。
実際、あなたはそこで止めることはできません。 そして、今、2つのアプローチ、共通の構造の2つのコンポーネントを組み合わせた場合、さらに多くを目指すことができます。 3つのコンポーネントと4つのコンポーネントを組み合わせます。この論理チェーンを引き続き組み合わせて、エラーの重要性をより低いレベルに「プッシュスルー」します。 これにより、問題を解決する精度を高めることができます。