この記事では、重要な基本事項について説明しています。 それらは、作者が取り組んでいるV8だけでなく、すべてのJavaScriptエンジンに共通です( ベネディクトとマティアス )。 JavaScript開発者として、JavaScriptエンジンの動作をより深く理解することは、効率的なコードを記述する方法を見つけるのに役立つと言えます。

前の記事で、フォームとインラインキャッシュを使用してJavaScriptエンジンがオブジェクトと配列へのアクセスを最適化する方法について説明しました。 この記事では、パイプラインのトレードオフの最適化とプロトタイププロパティへのアクセスの高速化について説明します。
注:記事を読むよりもプレゼンテーションを見る場合は、 このビデオをご覧ください 。 そうでない場合は、スキップして読み進めてください。
最適化のレベルとトレードオフ
前回、最新のJavaScriptエンジンはすべて、実際には同じパイプラインを持っていることがわかりました。
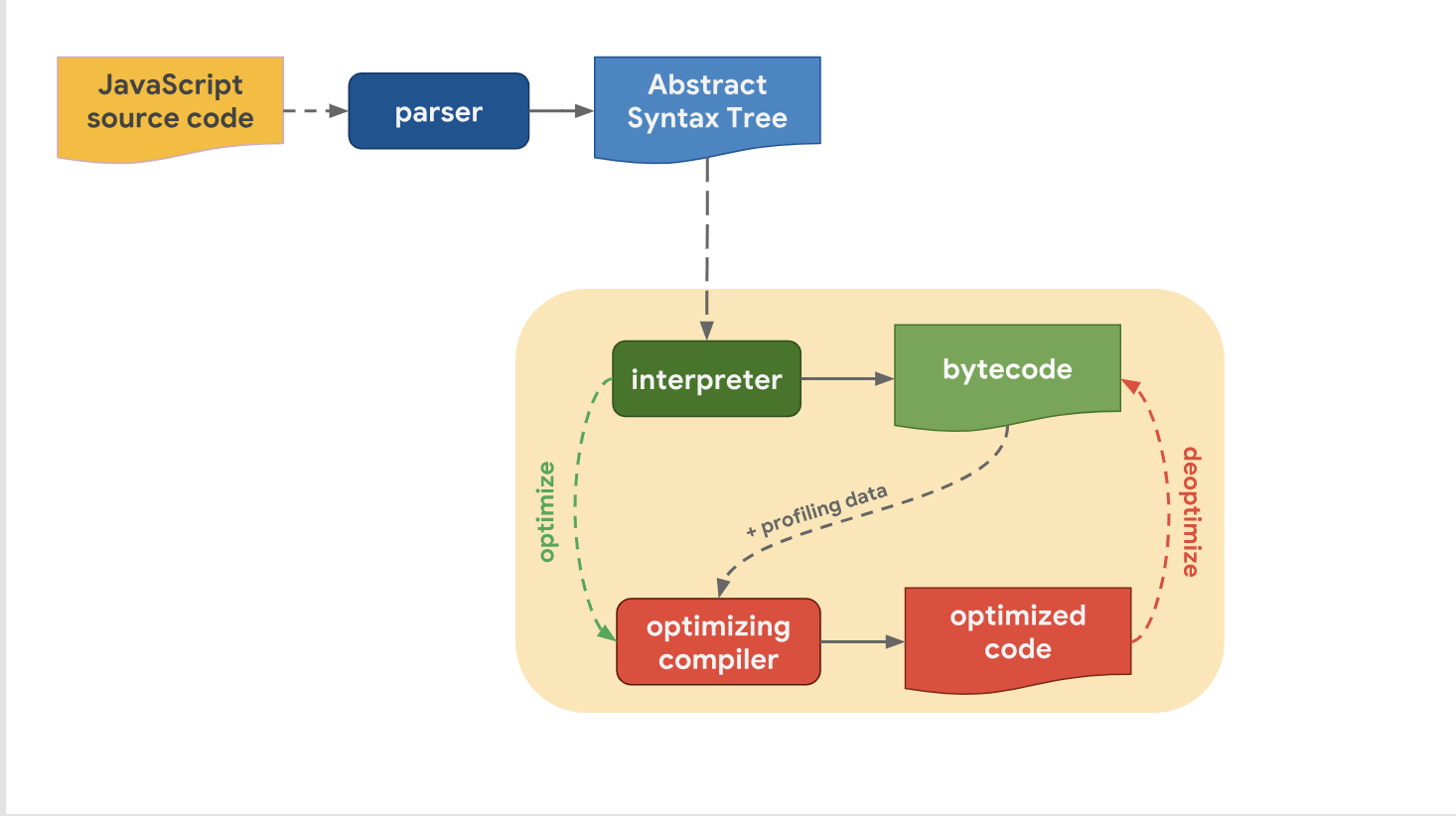
また、エンジンからエンジンへの高レベルのパイプラインの構造は類似しているという事実にもかかわらず、最適化パイプラインには違いがあることに気付きました。 これはなぜですか? 一部のエンジンには他のエンジンよりも多くの最適化レベルがあるのはなぜですか? 問題は、コード実行の段階への迅速な移行と、最適なパフォーマンスでコードを実行するために少しの時間を費やすことの間で妥協することです。

インタープリターはバイトコードをすばやく生成できますが、バイトコードだけでは速度の点で十分に効率的ではありません。 このプロセスに最適化コンパイラを含めると、ある程度の時間がかかりますが、より効率的なマシンコードが可能になります。
V8がこれを処理する方法を見てみましょう。 V8では、インタープリターはIgnitionと呼ばれ、既存のエンジンの中で最速のインタープリターと見なされていることを思い出してください(生のバイトコード実行速度の問題)。 V8の最適化コンパイラーはTurboFanと呼ばれ、高度に最適化されたマシンコードを生成します。

一部のJavaScriptエンジンがステップ間に最適化レベルを追加することを好む理由は、起動遅延と実行速度のトレードオフです。 たとえば、SpiderMonkeyは、インタープリターと完全に最適化されたIonMonkeyコンパイラーの間にベースライン層を追加します。
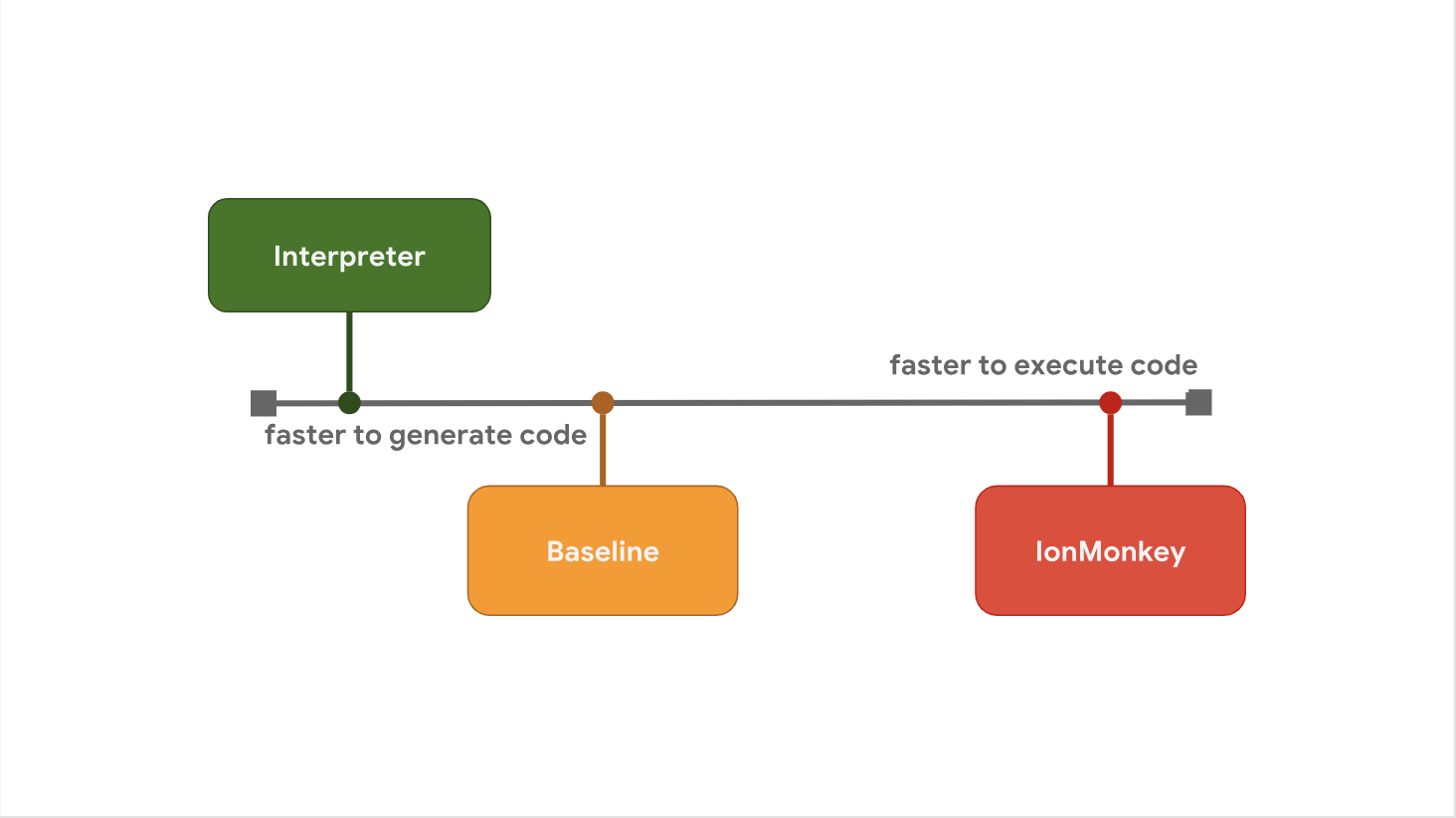
インタープリターはすぐにバイトコードを生成しますが、バイトコード自体は比較的低速です。 ベースラインはコードをもう少し長く生成しますが、実行時のパフォーマンスが向上します。 最後に、最適化コンパイラIonMonkeyはマシンコードの生成に最も時間を費やしますが、そのようなコードは非常に効率的です。
特定の例を見て、さまざまなエンジンのパイプラインがこの問題をどのように処理するかを見てみましょう。 ホットループでは、同じコードが頻繁に繰り返されます。
let result = 0; for (let i = 0; i < 4242424242; ++i) { result += i; } console.log(result);
V8は、Ignitionインタープリターでバイトコードを開始することから始まります。 ある時点で、エンジンはコードがホットであると判断し、プロファイリングデータを統合し、コードの基本的なマシン表現を構築するTurboFanインターフェイスを起動します。 その後、さらなる改善のために、別のスレッドでTurboFanオプティマイザーに送信されます。

最適化の進行中、V8は引き続きIgnitionでコードを実行します。 ある時点で、オプティマイザーが終了し、実行可能なマシンコードを受け取ると、すぐに実行ステージに進みます。
SpyderMonkeyは、インタープリターでバイトコードの実行も開始します。 ただし、ベースラインレベルが追加されているため、ホットコードが最初に送信されます。 ベースラインコンパイラは、メインスレッドでベースラインコードを生成し、生成の終了時に実行を継続します。

ベースラインコードがしばらく実行されている場合、SpiderMonkeyは最終的にIonMonkeyインターフェイス(IonMonkeyフロントエンド)を起動し、オプティマイザーを実行します。プロセスはV8と非常に似ています。 IonMonkeyが最適化に取り組んでいる間、これらはすべてベースラインで同時に機能し続けます。 最後に、オプティマイザーが作業を終了すると、ベースラインコードの代わりに最適化されたコードが実行されます。
ChakraのアーキテクチャはSpiderMonkeyに非常に似ていますが、Chakraはメインスレッドのブロックを回避するために、より多くのプロセスを同時に実行しようとしています。 メインスレッドでコンパイラの一部を実行する代わりに、Chakraはコンパイラが必要とするバイトコードとプロファイリングデータをコピーし、専用のコンパイラプロセスに送信します。

生成されたコードの準備ができると、エンジンはバイトコードの代わりにこのSimpleJITコードを実行します。 FullJITでも同じことが起こります。 このアプローチの利点は、コピー中に発生する一時停止が通常、本格的なコンパイラ(フロントエンド)を起動するよりもはるかに短いことです。 一方、このアプローチには欠点があります。 コピーヒューリスティックは最適化に必要な情報をスキップできるという事実にあるため、作業の速度を上げるためにコードの品質がある程度犠牲になると言えます。
JavaScriptCoreでは、すべての最適化コンパイラーがJavaScriptの基本的な実行と完全に並行して動作します。 コピーフェーズはありません。 代わりに、メインスレッドは単に別のスレッドでコンパイルを開始します。 次に、コンパイラは複雑なロックスキームを使用して、メインスレッドからプロファイリングデータにアクセスします。

このアプローチの利点は、メインスレッドでの最適化後に表示されるガベージの量を減らすことです。 このアプローチの欠点は、複雑なマルチスレッドの問題とさまざまな操作のロックコストを解決する必要があることです。
インタープリターの実行中の高速コード生成と最適化コンパイラーを使用した高速コード生成のトレードオフについて話しました。 しかし、もう1つの妥協点があり、それはメモリの使用に関するものです。 それを説明するために、2つの数字を追加する簡単なJavaScriptプログラムを作成しました。
function add(x, y) { return x + y; } add(1, 2);
V8のIgnitionインタープリターによってadd関数用に生成されたバイトコードを見てください。
StackCheck Ldar a1 Add a0, [0] Return
バイトコードを心配する必要はありません、あなたはそれを読むことができる必要はありません。 ここでは、 4つの命令しか含まれていないことに注意する必要があります 。
コードがホットになると、TurboFanは高度に最適化されたマシンコードを生成します。これを以下に示します。
leaq rcx,[rip+0x0] movq rcx,[rcx-0x37] testb [rcx+0xf],0x1 jnz CompileLazyDeoptimizedCode push rbp movq rbp,rsp push rsi push rdi cmpq rsp,[r13+0xe88] jna StackOverflow movq rax,[rbp+0x18] test al,0x1 jnz Deoptimize movq rbx,[rbp+0x10] testb rbx,0x1 jnz Deoptimize movq rdx,rbx shrq rdx, 32 movq rcx,rax shrq rcx, 32 addl rdx,rcx jo Deoptimize shlq rdx, 32 movq rax,rdx movq rsp,rbp pop rbp ret 0x18
特にバイトコードで見た4つのチームと比較して、ここには本当に多くのチームがあります。 一般に、バイトコードはマシンコードよりもはるかに容量が大きく、特に最適化されたマシンコードです。 一方、バイトコードはインタープリターによって実行されますが、最適化されたコードはプロセッサーによって直接実行できます。
これが、JavaScriptエンジンが「すべてを最適化」しない理由の1つです。 前に見たように、最適化されたマシンコードの生成には多くの時間がかかるため、より多くのメモリが必要です。

要約すると、 JavaScriptエンジンの最適化レベルが異なる理由は、インタープリターを使用した高速コード生成と最適化コンパイラーを使用した高速コード生成の妥協点を見つけるためです。 最適化レベルを追加すると、実行中の複雑さとオーバーヘッドのコストに基づいて、より多くの情報に基づいた意思決定を行うことができます。 さらに、最適化のレベルとメモリ使用量の間にはトレードオフがあります。 JavaScriptエンジンがホット関数のみを最適化しようとする理由です。
プロトタイププロパティへのアクセスを最適化する
前回、 JavaScriptエンジンがフォームとインラインキャッシュを使用してオブジェクトプロパティの読み込みを最適化する方法について説明しました。 エンジンは、オブジェクトの形状とオブジェクトの値を別々に保存することを思い出してください。
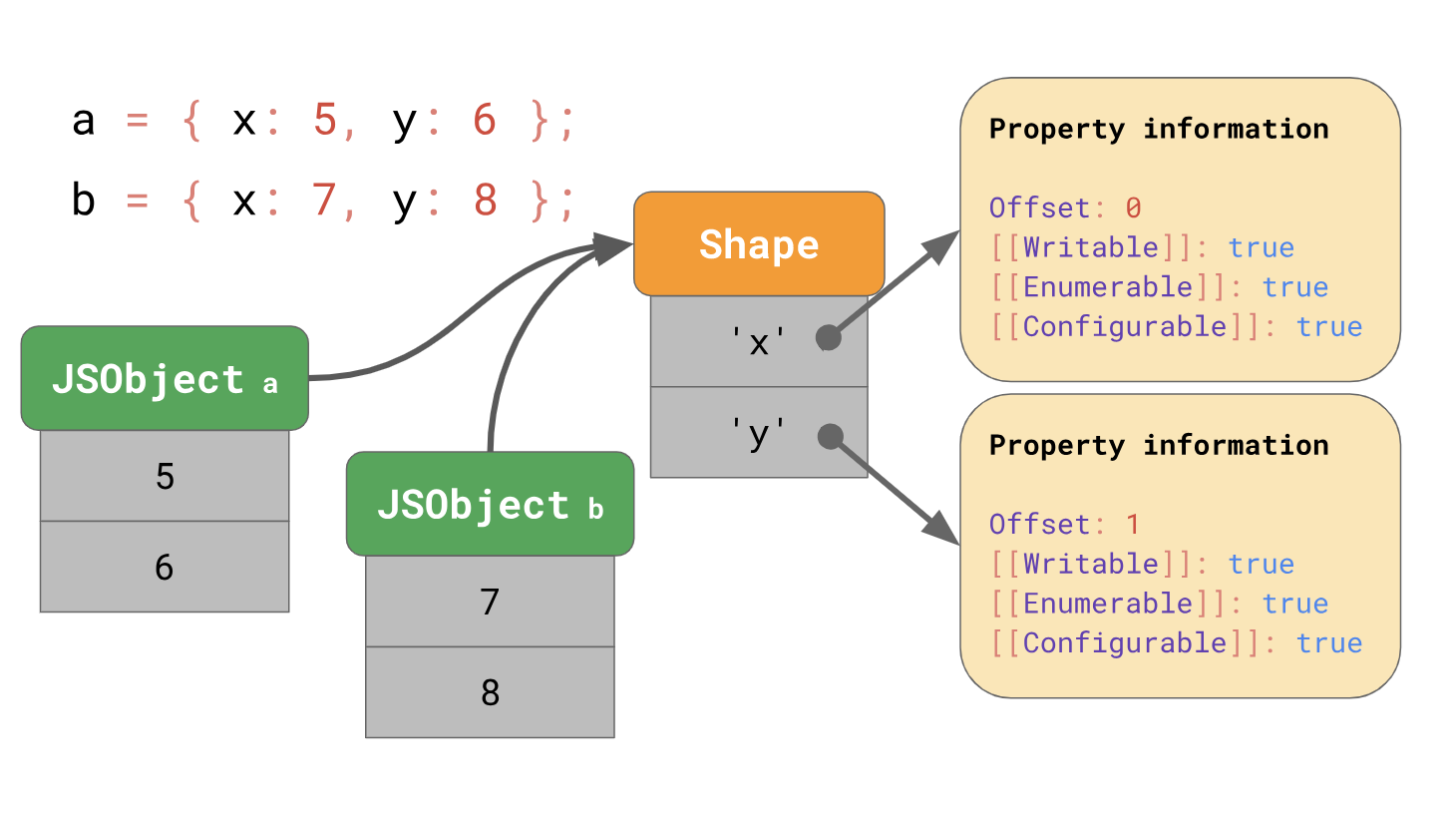
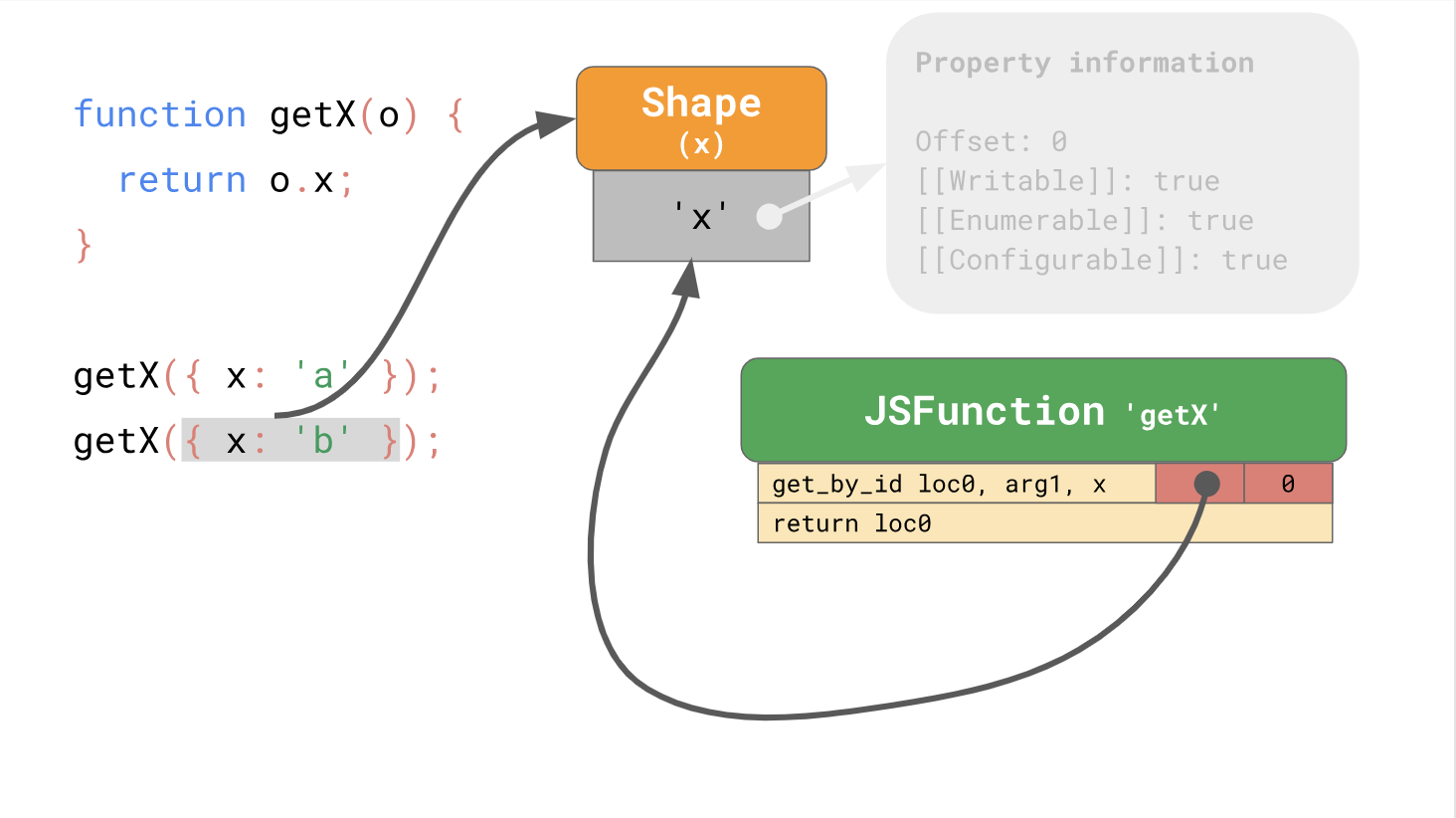
フォームを使用すると、インラインキャッシュまたは短縮ICを使用して最適化を使用できます。 フォームとICを連携させると、コード内の同じ場所から繰り返しプロパティにアクセスできるようになります。
そのため、出版物の最初の部分は終わり、クラスとプロトタイププログラミングについては2番目の部分で見つけることができます。 伝統的に、私たちはあなたのコメントと嵐の議論を待っているだけでなく、コース「情報システムのセキュリティ」の公開日にあなたを招待します。