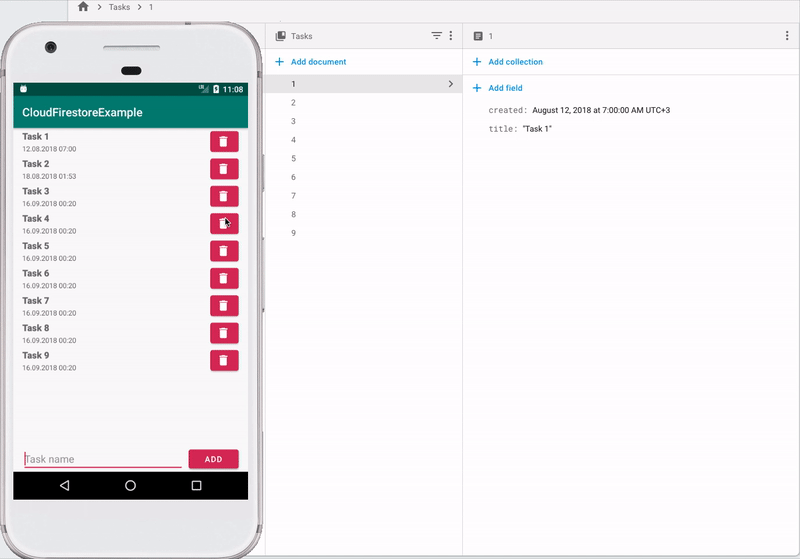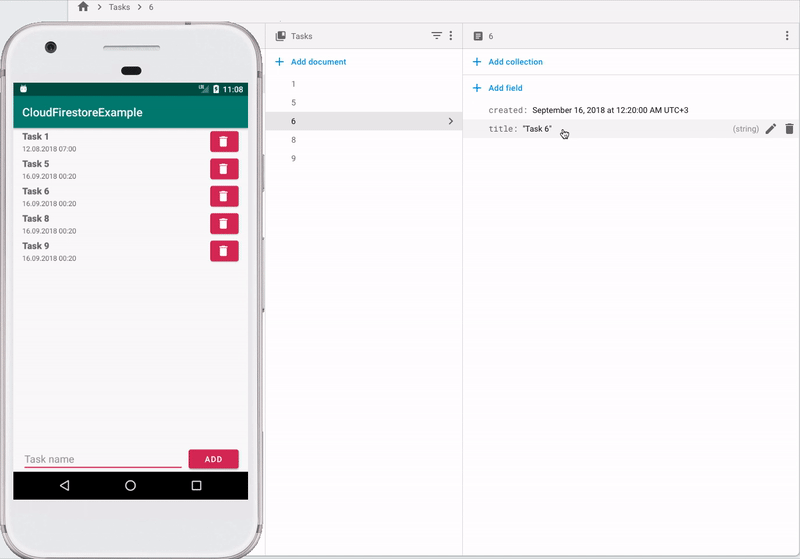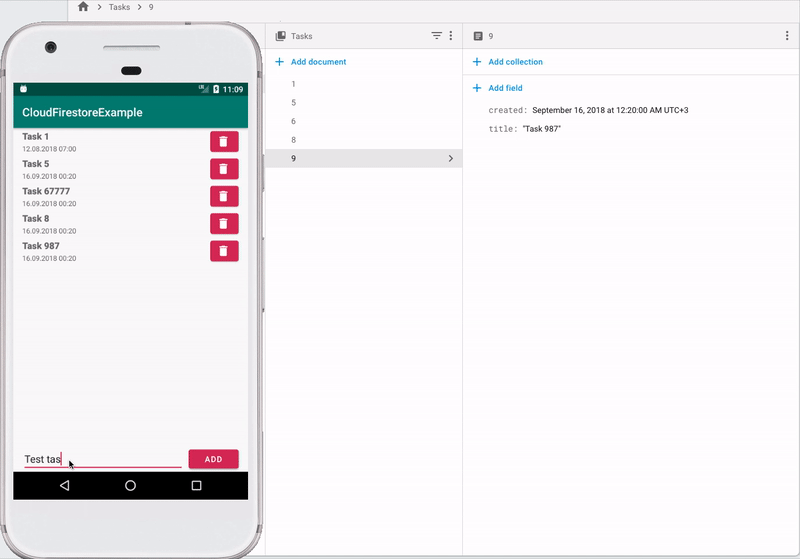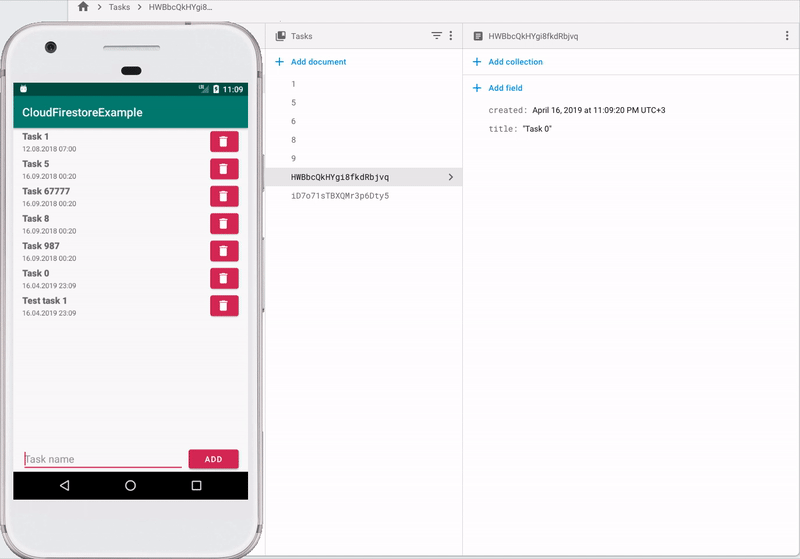
少し前、GoogleはCloud Firestoreを立ち上げました。 Cloud Firestoreは、GoogleがRealtime Databaseの代替として位置付けているクラウドベースのNoSQLデータベースです。 この記事では、使用方法を説明します。
少し前、GoogleはCloud Firestoreを立ち上げました。 Cloud Firestoreは、GoogleがRealtime Databaseの代替として位置付けているクラウドベースのNoSQLデータベースです。 この記事では、使用方法を説明します。
特徴
Cloud Firestoreを使用すると、データをリモートサーバーに保存し、簡単にアクセスして、リアルタイムで変更を監視できます。 ドキュメントには、Cloud FirestoreとRealtime Databaseの優れた比較が含まれています。
プロジェクトの作成と接続
Firebaseコンソールで、[データベース]を選択し、[データベースの作成]をクリックします。 次に、アクセス設定を選択します。 私たちに慣れるには、テストモードで十分です。しかし、実際にはこの問題にもっと真剣に取り組む方が良いでしょう。 アクセスモードの詳細については、 こちらをご覧ください 。
プロジェクトを構成するには、次の手順を実行します。
- ここからの指示に従って、Firebaseをプロジェクトに追加します。
- app / build.gradleに依存関係を追加します
implementation 'com.google.firebase:firebase-firestore:18.1.0'
これですべて準備完了です。
Cloud Firestoreを使用する基本的なテクニックを理解するために、簡単なアプリケーションを作成しました 。 動作させるには、Firebaseコンソールでプロジェクトを作成し、Android Studioのプロジェクトにgoogle-services.jsonファイルを追加する必要があります。
データ保存構造
Firestoreは、コレクションとドキュメントを使用してデータを保存します。 ドキュメントは、フィールドを含むレコードです。 ドキュメントはコレクションに結合されます。 ドキュメントにはネストされたコレクションも含まれる場合がありますが、これはAndroidではサポートされていません。 SQLデータベースから類推すると、コレクションはテーブルであり、ドキュメントはこのテーブルのエントリです。 1つのコレクションには、異なるフィールドセットを持つドキュメントが含まれる場合があります。
データの受信と記録
コレクションのすべてのドキュメントを取得するには、次のコードで十分です
remoteDB.collection(“Tasks”) .get() .addOnSuccessListener { querySnapshot -> // . querySnapshot.documents } .addOnFailureListener { exception -> // } }
ここでは、 Tasksコレクションからすべてのドキュメントをリクエストします 。
ライブラリを使用すると、パラメータを使用してクエリを生成できます。 次のコードは、条件からコレクションからドキュメントを取得する方法を示しています
remoteDB.collection(“Tasks”) .whereEqualTo("title", "Task1") .get() .addOnSuccessListener { querySnapshot -> // . querySnapshot.documents } .addOnFailureListener { exception -> // } }
ここでは、 タイトルフィールドがTask1の値に対応するTasksコレクションからすべてのドキュメントをリクエストします。
ドキュメントを受信すると、すぐにデータクラスに変換できます
remoteDB.collection(“Tasks”) .get() .addOnSuccessListener { querySnapshot -> // . querySnapshot.documents val taskList: List<RemoteTask> = querySnapshot.toObjects(RemoteTask::class.java) } .addOnFailureListener { exception -> // } }
書き込むには、データを含むハッシュマップを作成し(フィールドの名前がキーとして機能し、このフィールドの値が値として機能する)、ライブラリに転送する必要があります。 次のコードはこれを示しています
val taskData = HashMap<String, Any>() taskData["title"] = task.title taskData["created"] = Timestamp(task.created.time / 1000, 0) remoteDB.collection("Tasks") .add(taskData) .addOnSuccessListener { // } .addOnFailureListener { // }
この例では、新しいドキュメントが作成され、FirestoreがそのIDを生成します。 独自のIDを設定するには、次を実行する必要があります
val taskData = HashMap<String, Any>() taskData["title"] = task.title taskData["created"] = Timestamp(task.created.time / 1000, 0) remoteDB.collection("Tasks") .document("New task") .set(taskData) .addOnSuccessListener { // } .addOnFailureListener { // }
この場合、idがNew taskに等しいドキュメントが存在しない場合は作成され、存在する場合は指定されたフィールドが更新されます。
ドキュメントを作成/更新する別のオプション
remoteDB.collection("Tasks") .document("New task") .set(mapToRemoteTask(task)) .addOnSuccessListener { // } .addOnFailureListener { // }
変更を購読する
Firestoreでは、データの変更をサブスクライブできます。 コレクションへの変更と特定のドキュメントへの変更をサブスクライブできます
remoteDB.collection("Tasks") .addSnapshotListener { querySnapshot, error -> // querySnapshot - // error - }
querySnapshot.documents-すべてのドキュメントの更新されたリストが含まれています
querySnapshot.documentChanges-変更のリストが含まれています。 各オブジェクトには、変更されたドキュメントと変更の種類が含まれています。 3種類の変更が可能
ADDED-ドキュメントが追加されました、
変更済み-ドキュメントが変更されました。
削除済み-ドキュメントが削除されました
大量のデータをロードする
Realtime Databaseは、大量のデータをダウンロードするための多かれ少なかれ便利なメカニズムを提供します。これは、jsonファイルを手動で編集してダウンロードすることから成ります。 Firestoreには、すぐに使用できるものはありません。 大量の情報を簡単に読み込む方法が見つかるまで、新しいドキュメントを追加するのは非常に不便でした。 あなたが私のような問題を抱えないように、以下に大量のデータを素早く簡単にダウンロードする方法についての説明を添付します。 指示はインターネットで見つかりました。
- Node.jsとnpmをインストールする
- コマンドを実行してfirebase-adminパッケージをインストールします
npm install firebase-admin --save
- コレクションデータでjsonファイルを生成します。 例はTasks.jsonファイルにあります。
- ダウンロードするには、パスキーが必要です。 取得方法については、この記事で詳しく説明しています。
- export.jsファイルにデータを記録します
require( './ firestore_key.json')-アクセスキーを持つファイル。 スクリプトがあるフォルダーにいました
<YOU_DATABASE>-ファイヤーストアベースの名前
「./json/Tasks.json」-データが保存されているファイルへのパス
['created']-タイプがTimestampのフィールド名のリスト - スクリプトを実行する
node export.js
スクリプトはdalenguyen開発を使用します
おわりに
プロジェクトの1つでCloud Firestoreを使用しましたが、深刻な問題は発生しませんでした。 私のコレクションの1つには約15,000のドキュメントが含まれており、そのクエリは非常に高速で、インデックスを使用していません。 Cloud FirestoreとRoomおよびRemote Configを併用すると、データベースへの呼び出し回数を大幅に削減でき、無料の制限を超えることはできません。 1日あたりの無料関税では、50,000のドキュメントを読み取り、20,000を記録し、20,000を削除できます。