
「手にハンマーがある場合、すべてが釘のように見える」
データを実践する科学者として、私たちはデータの分析、収集、浄化、濃縮に従事し、データに基づいて私たちの周りの世界のモデルを構築し、訓練します。 もちろん、そのような没入感は私たちの世界のビジョンと理解に影響を与えることしかできませんでした。 プロの変形は他の場合と同じように私たちの職業に存在しますが、それは私たちに正確に何をもたらし、それは私たちの生活にどのように影響しますか?
免責事項
この記事は科学的であると主張するものではなく、ODSコミュニティの単一の観点を表すものではなく、著者の個人的な意見です。
前文

私たちの脳がどのように機能するか、私たちの周りの世界をどのように知覚するか、そして実際にここで何をしているのかに興味があるなら、この記事で説明することの多くは完全に新しいものではありません。 なんらかの形で、これはすべて完全に異なる角度から複数回説明されています。 私の仕事は、これらすべてをデータアナリストの観点から見ようとするだけでなく、私たちが仕事やモニターの外で実際に使用するツールとアプローチの類似点を描くことです。
はじめに

まず、このようなやや単純化されたセットアップを想像してください。
私たちの周りには、生き残り、正常に機能するための世界があります。人は、自分(世界)が何を表しているのか、どのように対話するのか、さまざまな相互作用からどのような結果が得られるのかを理解する必要があります。 つまり、言い換えれば、 現在のタスクを適切に解決する周囲の世界のモデルが必要です 。 キーは「 現在のタスク 」です。 生存の課題がそもそもあったとき、世界のモデルはまず第一に、危険の迅速な認識とそれに適切な反応の上に構築されました。 つまり、より悪いモデルを持っている人-それを渡すことができませんでした;より良いモデルを持っている人は、彼らの子孫に渡されました。 生活環境の改善に伴い、モデルの重点は純粋な生存からより高度に組織化されたものに変わり始め、環境がより安全になるほど、この「何か」はより多様になります。 「何か」の範囲は非常に広く、ビットコインやDSから急進的なフェミニズムや寛容にまで及びます。
自然は、限られた資源の状況での生存の問題を解決するために私たちの脳を作成しました-十分な食物がなく、ごみに十分なエネルギーがなかったので、生き残るためには、2つの相互に排他的なタスクを解決する必要がありました:
- 世界を発見し、モデルを改善し、生存の可能性を高める(非常にエネルギー集約的なタスク)
- エネルギー不足で死ぬな
自然はこのジレンマを非常にエレガントに解決し、データフローと反応をキャッシュする機能を脳に導入します。これは、外界との相互作用の基本的な問題(現在のモデルの枠組み内)を解決するためにエネルギーが実際に無駄にならない場合です。
このキャッシング方法と「注意のリソース理論」については、 D。カーネマンの優れた作品「 ゆっくり考え、素早く解決する 」[1]および「 注意と努力 」[3]で詳しく読むことができます。
D.カーネマンによると:
心理学者は、システム1とシステム2と呼ぶ2つの思考モードを区別します。
システム1は、労力をほとんど必要とせず、意図的な制御感を与えることなく、自動的かつ非常に迅速に動作します
システム2は、複雑な計算を含む意識的な精神的努力に必要な注意を与えます。 システム2のアクションは、多くの場合、主観的な活動感覚、選択、集中に関連しています。
行動、反応、および応答のパターンは、子供の頃から死まで、私たちの脳にプログラムされています(世界のモデルを形成および変更します)。 2つの要因は、モデルの形成段階に依存します-変更の受け入れ率と変更に必要なエネルギー量です。 小児期では、モデルが柔軟で柔軟な場合、速度は高く、エネルギーコストは最小限です。 モデルの密度が高いほど、モデルを変更するためにより多くのエネルギーが必要になります。 さらに、 エネルギーが必要なため、人は単にモデル内の何かを変更したいだけです。 そして、エネルギーの無駄は脳によって制御されており、彼はそれを費やすことを許すことにoooooしています。
モデルを変更するコマンドは、古いモデルのフレームワーク内で機能することが生存を脅かすまで、脳によって拒否されます(それでもエネルギーを消費しますが、なぜですか?)。 まあ、またはエネルギーが自発的な爆発によって受け取られるまで(何かからの衝撃、心理的な打撃など)
TL / DR:
- 生存のために、人は頭の中で彼の周りの世界のモデルを構築し、彼の現在のタスクを解決します
- 問題を解決するとき、脳はエネルギー消費を最小限に抑えようとします。
- System-1(Kahneman)のフレームワーク内で最もエネルギーを消費しない操作、変更に関する決定の失敗
- 最もエネルギーを消費するのは、System-2のフレームワーク内で機能し、モデルの変更とモデル自体の変更に関する決定を下すことです。
メタモデル(モデルモデル)

したがって、外の世界と対話するために、人は自分の脳で世界のモデルを構築し、可能な限り長くそれに応じて行動します(エネルギーコストの最小化についてもう一度思い出してください)。 しかし、残念なことにまたは幸いなことに、人は社会的な動物です。他の人と交流することはできません。
他の人々と効果的に対話するために、私たちはこれらの人々の行動モデル 、つまり特定のデータが存在する特定の状況での彼らの振る舞いのモデルを頭の中に構築します 。 つまり、この特定の人の周囲の世界のモデルのモデルを構築しています。
停止して考える- 人の頭の中の世界のモデルは不完全であり、彼自身の十分性と妥当性の基準しか満たしていないため、この(奇妙な)モデルのモデルを構築し、モデルに従ってこの人とやり取りします。 はい、 また、「彼のモデルのモデル」に示されているように、人々にできることを望んでいます 。 楽観的? はい、以上....
適切なモデルを構築してトレーニングするには、あなたに伝えるのではなく、多くの時間、エネルギー、データが必要です。 そして、どちらか一方も存在しないことが多く、モデルの自由度(パラメーター)が大きいほど、より多くのデータが必要になります-次元の呪い、覚えていますか?
そして、人生は飛ぶ、そして時間は短いので(System-1は機能する)、人に会い、ある条件で彼と通信さえするので、私たちはすでに持っているプリコンパイルされたモデルテンプレートの1つを選択する頭(「雌犬」、「普通の子供」、「モグラ塚」、「ちょうど」号、「ak」など)に、特定の場合にはわずかなフィントゥニアかもしれません。
はい、もちろん例外があります。時間やエネルギーのいずれについても気に入らない人がいます。 しかし、この場合、私たちはこの人のモデルにいる人についてのみ知っています。
ここから何が続きますか? いくつかの明らかなこと:
まあ、 まず 、科学者が他の人に対してtowardsりを感じない日付。
言葉から完全に。 彼の語彙では、「resみ」という用語はありません。 なんで? すべてが単純です-any辱の核心には誤解があります:
- どうして彼(彼女)はそうすることができますか(言う、行動する、行動する)?
- またはない (言う、する、する)?
つまり、この人物のモデルでは、特定の情報パケットの入力がある特定の状況では、このように行動するはずでしたが、行動しませんでした。 あのろくでなし? ええ、彼はろくでなしではありませんが、この人のモデルは間違っています。 その中に何かを見逃したか、特定の状況にまったく興味がありませんでしたが、テンプレートを使用したか、現在の状況の入力データがモデルをトレーニングしたデータと異なります。
この場合の対処方法 通常と同じ-データの何が問題であるかを調べ、新しい情報でモデルをオーバートレーニングします。
第二に、科学者の日付には「 インターネット上で誰かが間違っている 」という反射がありません。
インターネット上だけでなく、職場や社会などでも機能します。 人が何かを理解していないか(あなたのように)理解していないが、あなたのやり方では理解していない場合、おそらく彼は世界のこの部分に対してまったく異なるモデルを持っているでしょう。 そしてこれを納得させるために、すなわち 彼にモデルを変更させることは(特に彼が望んでいない場合)非常に難しく、非常にエネルギー集約的です。 必要ですか?
完全に異なるオプションは、人がモデルを変更する準備ができているときに、モデルを拡張または強化したいときに、そのための強さとエネルギーを持っていることです。 あなたは助けることができます-助けて、できません-できる人に直接。 助けることも直接することもできません-干渉しないでください 。
次回、あなたの意見では、彼が「間違っている」か「何かを理解していない」場合、動揺しないでください。 彼の世界のモデルでは、すべてが異なっています。 モデルをより粗く「単純」にすればするほど、少なくとも何かを変えることは言うまでもなく、 少なくとも平衡点から抜け出すために、より大きなエネルギー消費が必要になります。
そして第三に、科学者の日付は「 物事は常に彼らが見えるものではない 」という原則を覚えています。
このシステムがどのように機能するかを理解し、模倣し、現在の社会に馴染みのある基本的なテンプレートに適応する機会があります。そして、それから抜け出すまで、すべてがうまくいきます。 それは両方の方法で動作するので、忘れないでください-「 フクロウは見た目ではありません 。」
「ヘビとしてのロープの認識は、ロープとしてのロープの認識と同じくらい間違っています」(C)
モデルの構築とトレーニング

科学者の日付として、我々は多かれ少なかれ適切なモデルを構築し、訓練し、絶えず再訓練することがいかに難しいかをよく理解しています。 それで科学者が他の人の頭の中のモデルの不完全さを冷静に忍耐強く言及し、自分自身を絶えず改善します。 そして彼はまだプロであるため、成功するモデリングの基本原則を完全に覚えています。
周りに何がくるのか(ごみが入る-ごみが出る)
モデルの精度と妥当性は、他の何よりもデータの純度に依存します。 私たちは皆これを知っています。データのクリーンアップ、前処理、正規化などに膨大な時間を費やしています。 ガベージモデルをフィードします-結果は予測可能です。 彼女のクリアされた正規化されたデータとあなたのポケットの洞察力を養います。 私たちの頭の中のモデルはまったく同じように機能します。 これを理解し、 処理とトレーニングに最も正確でクリーンなデータを使用するよう努め、データの妥当性を分析するために絶えず重要なビューを使用し、モデル内の汚れたノイズの多い情報の防止に努めています 。 要するに-Habrを読んで、最初のチャンネルを見ないでください。
TrainとTestの違い(頭痛)
科学者は、モデルの適用性がモデルが研究して、それが適用される分布の類似性に直接依存すると理解します。 ある社会の行動のルールは別の社会では機能せず、ある分野での成功の原則は別の分野では適用されません。母の話に基づいて構築された異性の「典型的な行動モデル」
私たちは常に、世界のモデルを訓練した訓練データセットと、モデルを適用した実際のデータセットの可能な非類似性を考慮します。
要するに、 矛盾の理由を理解し、モデルを事前トレーニングに費やして実世界により厳密に一致させる準備ができています。
目的関数とマルチドメイン学習の選択
目的関数を変更することにより、ほぼすべてのタスクを別のドメインに転送できます。 問題は回帰として解決されませんか? クラスのターゲットをやり直し、分類タスクとして解決します。 さらに良いことには、グリッドで2つの方向に進み、1つで1つの問題を解決し、2つ目の問題を修正します。 同じデータセットで、2つの異なるモデルをトレーニングし、まったく異なるものをシャープにすることができます。 これを忘れないでください。最終目的関数が複数のドメインを一度にカバーする場合、人生における最善の選択肢はマルチドメイン学習です。 たとえば、職場では、お金を稼ぐだけで、プロのスキルをダウンロードでき、ソーシャルインタラクションスキルを向上させることができます。 従来のモデルの場合と同様に、このアプローチにより、最終的に、すべてのマルチドメインの目標を充実させ、改善することができます。 また、時間を忘れないでください- 個々の目的のための3つのモデルは3倍の時間を必要としますが、実際にはそれほど長くはありません。残念ながら、トレーニングを数十または2つのTPUシェックに並列化することはできません。
ブロックでのトレーニング(バッチ学習)
バッチを使用したモデルトレーニングが効果的であることが長い間証明されています。 オンライントレーニングが必要な特定の領域を考慮しない場合、時代全体を通過した後にのみ重みを更新しても意味がありません。 はい、バッチでのトレーニングは高周波ノイズを生成しますが、これはほぼ同じ精度でより高い収束率によって平準化されます。
これにより何が得られますか? 新しいデータに基づいて世界のモデルをわずかに変更する前に長く待つことは意味がないことを理解してください。 時代全体を待つ必要はありません。よくわかりませんが、新しい仕事で1年、新しい人との1年、 頻繁に変化します。最終目標への移動が早くなります 。 また、1回の事件の後に「すべてが失われた」と叫ぶのは無意味です。たぶんそれは単なる爆発であり、多分星はこのように発展し、バッチの終わりまで待って、エラーを蓄積し、モデルを変更します。
ハイパーパラメーター検索方法(グリッド検索とランダム検索)
トピックに関する多くの記事( 例 )があり、最適なハイパーパラメーターを検索する場合、グリッド検索よりもランダム検索の方が優れています。 したがって、この場合、 「ランダム」アクションの選択は、「事前にランダムに」実行する方が適切であり、事前に定義されたグリッドに厳密に従ってはなりません 。 ファンと厳格なアプローチの支持者は今私を踏みにじるでしょうが、真剣に、 ケースは世界を支配し、そのような方法の使用は、奇妙なことに、さらに合理的です。
いっそのこと、もちろん、 ベイジアン最適化を使用することです。 しかし、ここでは、それが実際の生活にどのように適用されるのか理解できません。 情報を理解するためのベイズのアプローチではなく、ハイパーパラメータを選択する際のベイズの最適化 。
アンサンブル
私たちは皆、アンサンブルの力について知っています。各モデルは独自の方法でデータを見て、そこから何らかの信号を引き出します。最良の結果は、第1レベルのモデルの上にメタモデルを使用することで達成されます。 人生では、すべてがまったく同じであり、自分の経験に基づいて世界の独自のモデルを構築できるだけでなく、他の人の世界のモデルから最高のものを吸収することもできます(逆もまた同様です)。 これらのモデルは本や映画で説明されており、他の人の行動を観察するだけで、彼らがどのようなモデルを持っているかを理解し、最善を尽くして自分自身を構築することができます。
「私たちの概念が弱いからではなく、概念の輪に含まれていないために、多くのことが理解できない」ことを思い出しましょう。コズマ・ペトロヴィッチは、科学者であるにもかかわらず、限られたモデルの問題を理解していました。 :)
人、環境、データが異なる-モデルは、一見明らかなことでも。 大企業で働いていたなら、行動、コミュニケーションのルール、ハラスメントなどに関するこれらの無限のトレーニングをすべて覚えているでしょう。 一体何だと思った。 しかし、いや、ゴミではありません。 大企業(文化、考え方、価値観の違いによる)では、通常のやり取りと仕事を確保するために、各従業員のモデルに基本原則の層を導入するだけです。
TL / DR
- この世界であなたに何が起こっているのか、あなたとあなたの世界のモデルだけが責任がある
- 他の人の世界モデルはあなた自身のものと相関する必要はありません
- 他の人の世界モデルのメタモデルは、現実に対応していない可能性が高い
- ベイジアンの原則に基づいて変化に対応できる世界のオープンモデルを頭の中で作成することは困難です。 一生を通してこの開いた状態でそれを維持することはさらに困難です。 この人と一緒にいるのはとても難しい
舞台裏に残っているもの
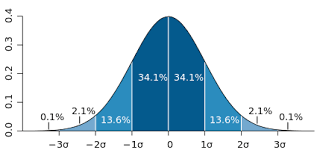
中央極限定理
CTCが言うように、弱依存分布の任意のタイプからサンプリングされたランダムイベントの合計は、それ自体がランダム変数であり、通常は制限内で分布します。
私たちの人生はランダムなイベントで構成されています :エレベーターや停留所でのバスの待ち時間、コーナーを逃したかどうかなどです。 最終的な分布のどこにあるかによって、センターまたはテールに対して、条件付きで1日を成功または失敗(別のランダム変数)として評価できます。 十分に大きいサンプル(たとえば、1年)では、このランダム変数が「 まあ、多かれ少なかれ大丈夫 」を中心に正規分布していることがわかります。
科学者が上記のすべてを理解し、それがいわゆる すべてが悪いときの「黒い線」 -バスが鼻の下に残って、コーヒーを注ぎ、コードを保存しなかった、など 彼は、今日私たちは分布の尾を持っている、私たちは今日この日を生き残る必要があることを理解しています 、そして明日、おそらく世界は私たちにわずかに異なる方法でイベントをサンプリングするでしょう。
ところで、 イベントの新しい参照ポイント(新しいサンプルセット)への移行は夢です。 カレンダーの日ではなく、真夜中ではなく、目覚めた後の主観的な新しい日です。 私たちの祖先はこれを直感的に理解しました(xgboostとkerasについては知りませんでしたが)、ここから「 夕方の朝は賢い 」、「 仕事をしたい、寝る、すべてが通り過ぎる 」ということわざがここから来ました。
論理的な結論は、「黒いバー」が長すぎる場合(この「あまりにも」のp値を計算しようとすることもできます)、これは私たちの生活方程式のいくつかの値がシフトすることを意味します (バスがルートから外れた、あなたが持っている朝の握手が現れた)、またはシステムへの外部の影響が実行されます。
意味する回帰
フランシス・ガルトンirの親切な言葉を思い出しましょう。彼は彼の作品「 継承における中間への回帰 」でこの現象に最初に注意を引きました。 また、このトピックは、D。カーネマンによる既述の優れた本[1]で十分にカバーされています。
科学者の日付として、今日何かが昨日より悪い場合、私たちは注意を払いません 。 特に今日の失敗は明日の成功の可能性を高めるため、 今日の失敗を意味し、今日の失敗に関連する回帰を覚えています、これも同じ法律に従って)
繰り返しますが、この法律は「 物事がうまくいけば、すぐにさらに悪化する 」という、より身近な形で長い間再定式化されてきました。
使用とインテリジェンス(搾取vs探索)
すでに述べたように、私たちの脳はエネルギー消費を最小限に抑えようとしていますが、これは生存と出産を優先するためです。 最初は、生き残るためのエネルギーがほとんどなく、保存する必要があり、そのような長い進化のための脳は、基本的なファームウェアのオッカムおじさんの原則によって刷り込まれました。 」 周りで起こるすべてが現在のモデルの枠組みで理解可能であり、原則としてすべてが多かれ少なかれあれば、何か新しいものを探す必要がない場合、世界の新しいモデルの構築にエネルギーを費やす必要はありません。
しかし、私たちはプログラムです...科学者はデートします。 ジャムがローカルミニマムにあるものをよく知っています。 私たちの生活の最適化関数の表面の複雑さは理解できず、説明することはできません (多くの人が意図的に単純化して存在を容易にします)。また、新しい最良の局所最小値は、1つまたは2つの単純なアクションで隣り合わせになります。 しかし、私たちは最適な状態にとどまり続け、「 まあ、何も変わらないことを知っています」と言っています 。 すでに述べたように、目的関数のランドスケープが複雑であるため、このようなことはわかりません。 あなたは思考を止めてジャンプを始めなければなりません。 定期的にローカルミニマムから出て、さまざまな方向にひきつこうとすると、あなたの人生がどのように変わるかを信じることはできません。
例として、RL( 強化学習 )の「ローカルミニマム」で立ち往生する問題を挙げることができます。 貪欲なアルゴリズムを使用して各状態のアクションを選択すると、もちろん、最終的に報酬を最適化しますが、周囲の空間の他の、おそらくより興味深い領域を残します。 したがって、 この特定の状況から最良ではなくランダムなアクションを選択する可能性をアルゴリズムに導入し、これが新しいもの、おそらくはより良いものにつながるかどうかを確認します 。 無限数の開始を伴うRL問題については、遅かれ早かれ、考えられるすべての状態と報酬を考慮し、最大のものを選択します。 残念ながら、実際には試行回数は限られています(そしてもちろん実験時間も)が、タスクはより興味深いものです。つまり、アクションをランダムに選択する代わりに、より洗練されたアルゴリズムを思いつくことができます。
ちなみに、 興味のバブル、パーソナライズされたフィード、検索結果などは、 探索の機会を遮断し、既に学習されたコンテンツの領域への情報の流れを閉じるため、有害です。
人口サンプル
私たちは、人、出来事、物事に関するすべての評価的判断が一般集団全体に基づいているのではなく 、観察のために利用可能な特定のサンプルにのみ基づいていることを理解しています 。 このことを認識して、「 すべての男性は偶蹄目動物 」または「 すべての女性は金髪 」などのラベルを非常に慎重に 掲げています。
また、通常のサンプルを使用しても、分布の「テール」に陥る確率はゼロにはほど遠いことを覚えています 。 そして、もしこれが起こったとしても、私たちは動揺せず、「なぜ私は再びいるのか」というトピックについては考えていませんが、レッスンを学び、冷静に進んでいます。
既に述べたように、突然何かのサンプル(人、イベントなど)が突然「尾」だけで構成され始めた場合、これは、世界の自分のモデルで世界がこのように反応し始めたことを突然反映する機会です。
認知的歪み
ある程度、私たちはまだすべて人間であり、私たちの脳はSystem-1の動作に起因するすべての可能な認知的歪みの影響を受けます。 基本的な帰属エラー 、 遡及的歪み 、 フレーミング 、 生存者の系統的エラーなど、など。 これらおよび他の多くのベールも私たちに影響を与えます。 しかし、科学者が日付を付けているように、私たちは常にこれらのtrapについて覚えており、常にシステム-2に負担をかけ、それらから自分自身を隔離しようとします。 歪みの性質とそれらから離調する方法を理解することは、私たちの仕事と実生活の両方で役立ちます。 はい、難しいです。System-2に十分なエネルギーがありませんが、筋肉は緊張したときにのみ成長します。
「その後はそれゆえ意味がありません」と他の論理エラー
繰り返しますが、 認知の歪みの場合と同様に、これらの論理エラーについて知っており、それらを覚えて、System-1を開発して、そのようなトラップのバイパスが自動的に行われるようにします。
地図が領土と一致していません
, “ , ” (). . , , - , , , . , , , , , , , .
TL/DR
- ,
- . ,
- (exploration)
- , . , - , 1
おわりに

, - , , , , , .
参照資料
- . … . — .: , 2013. — 625 .
- ., ., . : ., : , 2005. — 632 . — [ISBN 966-8324-14-5]
- カーネマンD.注意と努力/トランス英語からI. S.ウトチキナ。-M。:センス、2006 .-- 288 p。
- フリス・K、「脳と魂:神経活動が私たちの内なる世界をどのように形成するか」