
Radar Technologyの記事で述べたように、Lamodaはマイクロサービスアーキテクチャに積極的に移行しています。 ほとんどのサービスはHelmを使用してパッケージ化され、Kubernetesに展開されます。 このアプローチは、99%のケースで私たちのニーズを完全に満たしています。 特定のイベントのバックアップまたはサービスの更新を構成する必要がある場合など、標準のKubernetes機能が十分でない場合、1%が残ります。 この問題を解決するには、演算子パターンを使用します。 このシリーズの記事では、I-LamodaのR&Dチームの開発者であるGrigory Mikhalkinが、 Operator Frameworkを使用してK8sオペレーターを開発した経験から学んだ教訓について説明します 。
演算子とは何ですか?
Kubernetesの機能を拡張する1つの方法は、独自のコントローラーを作成することです。 Kubernetesの主な抽象化は、オブジェクトとコントローラーです。 オブジェクトは、クラスターの望ましい状態を記述します。 たとえば、 Podは起動する必要のあるコンテナーと起動パラメーターを記述し、 ReplicaSetオブジェクトはこのPodのレプリカをいくつ起動する必要があるかを示します。 コントローラーはオブジェクトの説明に基づいてクラスターの状態を制御します。上記の場合、 ReplicationControllerはReplicaSetで指定されたPodレプリカの数をサポートします。 新しいコントローラーの助けを借りて、イベント通知の送信、障害からの回復、 サードパーティのリソースの管理などの追加ロジックを実装できます。
オペレーターは、サードパーティリソースを提供する1つ以上のコントローラーを含むkubernetesアプリケーションです。 このコンセプトは2016年にCoreOSチームによって考案され、最近では、オペレーターの人気が急速に高まっています。 OperatorHubだけでなく、 kubedex (既に公開されている100を超える演算子が既にリストされています)のリストで、必要な演算子を見つけることができます。 オペレーター開発には、 Kubebuilder 、 Operator SDK 、 Metacontrollerの 3つの一般的なツールがあります 。 Lamodaでは、Operator SDKを使用するため、後で説明します。
オペレーターSDK
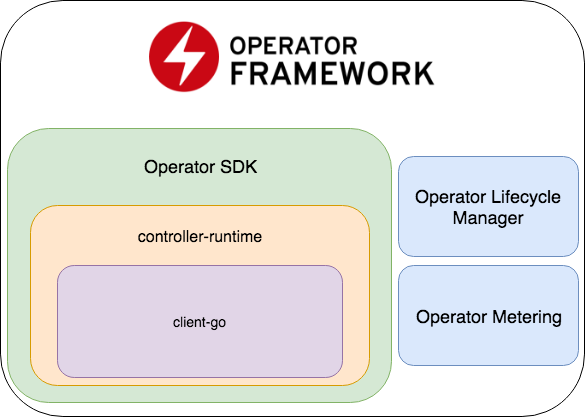
Operator SDKは、Operator Lifecycle ManagerとOperator Meteringの2つの重要な部分を含むOperator Frameworkの一部です。
- Operator SDKは、 コントローラー開発用の一般的なライブラリーであるcontroller-runtimeのラッパー(これはclient-goのラッパーです)、E2Eテストを記述するためのコードジェネレーター+フレームワークです。
- Operator Lifecycle Manager-既存のオペレーターを管理するためのフレームワーク。 オペレーターがゾンビモードに入るか、新しいバージョンがロールアウトされる状況を解決します。
- オペレーターメータリング -名前が示すように、オペレーターの作業に関するデータを収集し、それらに基づいてレポートを生成することもできます。
新しいプロジェクトを作成する
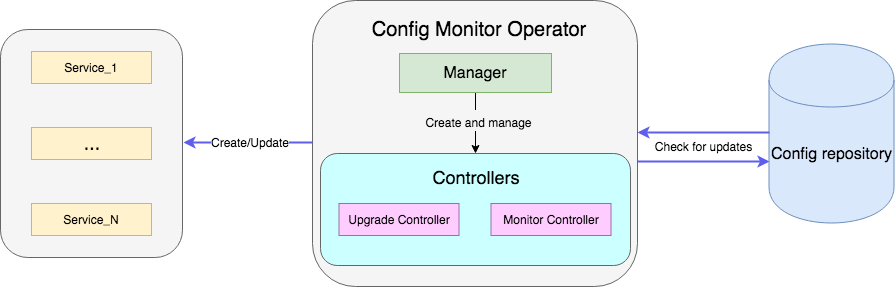
例としては、リポジトリ内の設定を使用してファイルを監視し、更新されると新しい設定を使用してサービスの展開を再開するオペレーターがあります。 完全なサンプルコードはこちらから入手できます 。
新しい演算子を使用してプロジェクトを作成します。
operator-sdk new config-monitor
コードジェネレーターは、割り当てられた名前空間で作業するオペレーターのコードを作成します 。 エラーの場合、同じ名前空間内で問題が分離されるため、このアプローチはクラスター全体へのアクセスを許可するよりも望ましい方法です。 --cluster-scoped
を追加すると、 cluster-wide
オペレーターを生成できます。 次のディレクトリは、作成されたプロジェクト内に配置されます。
- cmd-
Manager
初期化および起動されるmain package
が含まれています。 - deploy-RBACオペレーターのセットアップに必要なオペレーター、CRD、およびオブジェクトのステートメントが含まれています。
- pkg-新しいオブジェクトとコントローラーのメインコードを示します。
cmd/manager/main.go
ファイルが1つしかありません。
// Become the leader before proceeding err = leader.Become(ctx, "config-monitor-lock") if err != nil { log.Error(err, "") os.Exit(1) } // Create a new Cmd to provide shared dependencies and start components mgr, err := manager.New(cfg, manager.Options{ Namespace: namespace, MetricsBindAddress: fmt.Sprintf("%s:%d", metricsHost, metricsPort), }) ... // Setup Scheme for all resources if err := apis.AddToScheme(mgr.GetScheme()); err != nil { log.Error(err, "") os.Exit(1) } // Setup all Controllers if err := controller.AddToManager(mgr); err != nil { log.Error(err, "") os.Exit(1) } ... // Start the Cmd if err := mgr.Start(signals.SetupSignalHandler()); err != nil { log.Error(err, "Manager exited non-zero") os.Exit(1) }
1行目: err = leader.Become(ctx, "config-monitor-lock")
-リーダーが選択されています。 ほとんどのシナリオでは、名前空間/クラスターのステートメントのアクティブなインスタンスが1つだけ必要です。 デフォルトでは、Operator SDKはライフ戦略にリーダーを使用します。最初に起動されたオペレーターのインスタンスは、クラスターから削除されるまでリーダーのままです。
このオペレーターインスタンスがリーダーに指定された後、新しいManager
が初期化されますmgr, err := manager.New(...)
。 彼の責任は次のとおりです。
-
err := apis.AddToScheme(mgr.GetScheme())
-新しいリソーススキームの登録。 -
err := controller.AddToManager(mgr)
-コントローラーの登録。 -
err := mgr.Start(signals.SetupSignalHandler())
-コントローラーを起動して制御します。
現時点では、新しいリソースも登録用のコントローラーもありません。 次のコマンドを使用して、新しいリソースを追加できます。
operator-sdk add api --api-version=services.example.com/v1alpha1 --kind=MonitoredService
このコマンドはMonitoredService
リソーススキーマ定義をpkg/apis
ディレクトリーに追加し、yamlをdeploy/crds
CRD
定義とともにdeploy/crds
ます。 手動で生成されたすべてのファイルのうち、 monitoredservice_types.go
のスキーマ定義のみを変更する必要があります。 タイプMonitoredServiceSpec
は、リソースの望ましい状態を定義します。ユーザーがリソースの定義でyamlで指定するものです。 オペレーターのコンテキストでは、 Size
フィールドはレプリカの希望数を決定し、 ConfigRepo
は現在の構成のConfigRepo
示します。 MonitoredServiceStatus
は、リソースのMonitoredServiceStatus
状態を決定します。たとえば、このリソースに属するポッドの名前と現在のspec
ポッドを保存します。
スキームを編集した後、コマンドを実行する必要があります。
operator-sdk generate k8s
deploy/crds
CRD
定義を更新します。
次に、オペレーターの主要部分であるコントローラーを作成します。
operator-sdk add controller --api-version=services.example.com/v1alpha1 --kind=Monitor
monitor_controller.go
ファイルは、必要なロジックを追加するpkg/controller
monitor_controller.go
に表示されます。
コントローラー開発
コントローラーは、オペレーターの主要な作業ユニットです。 この場合、2つのコントローラーがあります。
- 監視コントローラーは、サービス構成の変更を監視します。
- アップグレードコントローラーはサービスを更新し、目的の状態に維持します。
本質的に、コントローラーは制御ループであり、サブスクライブされているイベントを使用してキューを監視し、処理します。
新しいコントローラーが作成され、 add
メソッドでマネージャーによって登録されます。
c, err := controller.New("monitor-controller", mgr, controller.Options{Reconciler: r})
Watch
メソッドを使用して、新しいリソースの作成または既存のMonitoredService
リソースのSpec
更新に関するイベントにサブスクライブします。
err = c.Watch(&source.Kind{Type: &servicesv1alpha1.MonitoredService{}}, &handler.EnqueueRequestForObject{}, common.CreateOrUpdateSpecPredicate)
イベントのタイプは、 src
パラメーターとpredicates
パラメーターを使用して構成できます。 src
はSource
型のオブジェクトを受け入れます。
-
Informer
-フィルターに一致するイベントについてapiserver
を定期的にポーリングし、そのようなイベントがある場合、コントローラーのキューに入れます。controller-runtime
これはclient-go
SharedIndexInformer
ラッパーです。 -
Kind
はSharedIndexInformer
ラッパーでもありますが、Informer
とは異なり、渡されたパラメーター(監視対象リソースのスキーム)に基づいてInformer
インスタンスを個別に作成します。 -
Channel
chan event.GenericEvent
をパラメーターとして受け入れ、それを通過するイベントはコントローラーのキューに配置されます。
redicates
は、 Predicate
インターフェースを満たすオブジェクトを期待します。 実際、これはイベント用の追加フィルターです。たとえば、 UpdateEvent
をフィルター処理する場合、リソースspec
行われた変更を正確に確認できます。
イベントが到着すると、 EventHandler
はそれを受け入れますWatch
メソッドへの2番目の引数Reconciler
期待する要求形式でイベントをラップします:
-
EnqueueRequestForObject
イベントを引き起こしたオブジェクトの名前と名前空間を使用してリクエストを作成します。 -
EnqueueRequestForOwner
オブジェクトの親のデータを使用してリクエストを作成します。 これは、たとえば、リソース制御Pod
削除されPod
おり、その交換を開始する必要がある場合に必要です。 -
EnqueueRequestsFromMapFunc
(MapObject
ラップされた)イベントを受信するmap
関数をパラメーターとして受け取り、リクエストのリストを返します。 このハンドラが必要な場合の例 -タイマーがあり、そのティックごとに、利用可能なすべてのサービスの新しい構成を引き出す必要があります。
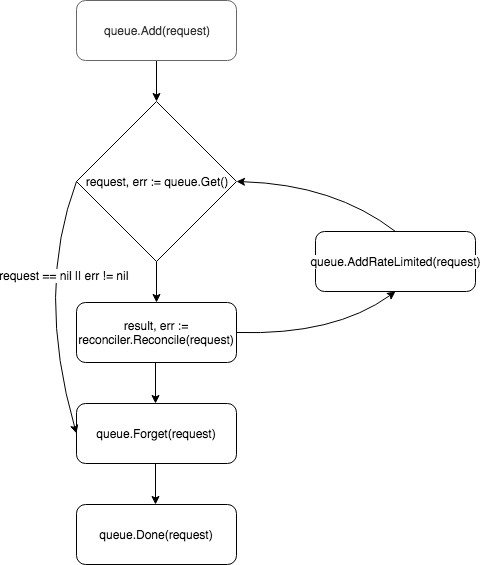
要求はコントローラーキューに配置され、ワーカーの1つ(デフォルトではコントローラーに1つあります)がキューからイベントをプルし、それをReconciler
渡します。
Reconcilerは、イベント処理の基本ロジックを含むReconcile
1つのメソッドのみを実装します。
func (r *ReconcileMonitor) Reconcile(request reconcile.Request) (reconcile.Result, error) { reqLogger := log.WithValues("Request.Namespace", request.Namespace, "Request.Name", request.Name) reqLogger.Info("Checking updates in repo for MonitoredService") // fetch the Monitor instance instance := &servicesv1alpha1.MonitoredService{} err := r.client.Get(context.Background(), request.NamespacedName, instance) if err != nil { if errors.IsNotFound(err) { // Request object not found, could have been deleted after reconcile request. // Owned objects are automatically garbage collected. For additional cleanup logic use finalizers. // Return and don't requeue return reconcile.Result{}, nil } // Error reading the object - requeue the request. return reconcile.Result{}, err } // check if service's config was updated // if it was, send event to upgrade controller if podSpec, ok := r.isServiceConfigUpdated(instance); ok { // Update instance Spec instance.Status.PodSpec = *podSpec instance.Status.ConfigChanged = true err = r.client.Status().Update(context.Background(), instance) if err != nil { reqLogger.Error(err, "Failed to update service status", "Service.Namespace", instance.Namespace, "Service.Name", instance.Name) return reconcile.Result{}, err } r.eventsChan <- event.GenericEvent{Meta: &servicesv1alpha1.MonitoredService{}, Object: instance} } return reconcile.Result{}, nil }
このメソッドは、 NamespacedName
フィールドを持つRequest
オブジェクトを受け入れます。これにより、リソースをキャッシュからプルできます: r.client.Get(context.TODO(), request.NamespacedName, instance)
。 この例では、リソース構成のConfigRepo
フィールドによって参照されるサービス構成を含むファイルに対して要求が行われます。 構成が更新されると、 GenericEvent
タイプの新しいイベントがGenericEvent
、 Upgrade
コントローラーがリッスンするチャネルに送信されます。
リクエストの処理後、 Reconcile
はタイプResult
およびerror
オブジェクトを返しerror
。 Result
フィールドがRequeue: true
またはerror != nil
場合、コントローラーはqueue.AddRateLimited
メソッドを使用してリクエストをキューに返します。 要求は、 RateLimiter
によって決定される遅延でキューに返されます。 デフォルトでは、 ItemExponentialFailureRateLimiter
使用されます。これにより、要求「戻り」の数の増加に伴って遅延時間が指数関数的に増加します。 Requeue
フィールドRequeue
設定されておらず、リクエストの処理中にエラーが発生しなかった場合、コントローラーはQueue.Forget
メソッドを呼び出します。これにより、 RateLimiter
のキャッシュからリクエストが削除されます(これにより、リターン数がリセットされます)。 要求処理の最後に、コントローラーはQueue.Done
メソッドを使用してキューからそれを削除します。
オペレーターの起動
オペレーターのコンポーネントは上記で説明されましたが、1つの疑問が残りました。それを開始する方法です。 まず、必要なすべてのリソースがインストールされていることを確認する必要があります(ローカルテストでは、 minikubeをセットアップすることをお勧めします )。
# Setup Service Account kubectl create -f deploy/service_account.yaml # Setup RBAC kubectl create -f deploy/role.yaml kubectl create -f deploy/role_binding.yaml # Setup the CRD kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_crd.yaml # Setup custom resource kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_cr.yaml
前提条件が満たされたら、テスト用のステートメントを実行する2つの簡単な方法があります。 最も簡単な方法は、次のコマンドを使用してクラスター外で起動することです。
operator-sdk up local --namespace=default
2番目の方法は、オペレーターをクラスターにデプロイすることです。 まず、演算子を使用してDockerイメージを構築する必要があります。
operator-sdk build config-monitor-operator:latest
deploy/operator.yaml
ファイルで、 REPLACE_IMAGE
をconfig-monitor-operator:latest
に置き換えます。
sed -i "" 's|REPLACE_IMAGE|config-monitor-operator:latest|g' deploy/operator.yaml
ステートメントを使用して配置を作成します。
kubectl create -f deploy/operator.yaml
これで、クラスター上のPod
のリストに、テストサービス付きPod
が表示され、2番目の場合-オペレーター付きPod
が表示されます。
結論やベストプラクティスの代わりに
現時点でのオペレーター開発の重要な問題は、ツールの文書化の弱さと確立されたベストプラクティスの欠如です。 新しい開発者がオペレータの開発を進めるとき、彼は特定の要件の実装例を実際に見る場所がないため、エラーは避けられません。 以下は、私たち自身の間違いから学んだいくつかの教訓です。
- 関連するアプリケーションが2つある場合は、それらを単一の演算子と組み合わせることを避けてください。 そうでなければ、疎結合サービスの原則に違反します。
- 懸念事項の分離について覚えておく必要があります。1つのコントローラーにすべてのロジックを実装しようとしないでください。 たとえば、構成を監視し、リソースを作成/更新する機能を広める価値があります。
-
Reconcile
メソッドでは、呼び出しのブロックは避けてください。 たとえば、外部ソースから設定をプルすることができますが、操作が長い場合は、このためのゴルーチンを作成し、リクエストをキューに返送して、応答Requeue: true
で示しRequeue: true
。
コメントでは、オペレーターの開発におけるあなたの経験について聞くことは興味深いでしょう。 次のパートでは、オペレーターのテストについて説明します。