Adwords(Googleの広告プラットフォーム)からのトラフィックの購入に取り組んでいます。 この領域の通常のタスクの1つは、新しいバナーの作成です。 ユーザーがバナーに慣れるにつれて、バナーは時間の経過とともに効果を失うことがテストで示されています。 季節とトレンドは変化しています。 さらに、オーディエンスのさまざまなニッチをキャプチャすることも目標であり、ターゲットを絞ったバナーはより適切に機能します。
新しい国への参入に関連して、バナーのローカライズの問題が発生しました。 バナーごとに、異なる言語および異なる通貨でバージョンを作成する必要があります。 デザイナーにこれを依頼することもできますが、この手作業により、すでに不足しているリソースにさらに負担がかかります。
自動化が容易なタスクのように見えます。 これを行うには、バナーに空白の「価格タグ」のローカライズ価格を課し、ボタンのアクション(「今すぐ購入」などのフレーズ)を呼び出すプログラムを作成します。 画像内のテキストの印刷が非常に簡単な場合、テキストを配置する必要がある場所を決定することは必ずしも簡単ではありません。 Peppercornsは、ボタンの色が異なっており、形状がわずかに異なっていると付け加えています。
この記事は、写真で指定されたオブジェクトを見つける方法に専念していますか? 一般的な方法は整理されます。 アプリケーション、機能、長所と短所の領域。 上記の方法は、セキュリティカメラ用プログラムの開発、UIのテストの自動化など、他の目的にも使用できます。 説明された困難は他のタスクで見つけることができ、使用される方法は他の目的に使用できます。 たとえば、Canny Edge Detectorは画像の前処理によく使用され、キーポイントの数を使用して画像の視覚的な「複雑さ」を評価できます。
説明したソリューションが、問題を解決するためのツールとトリックの武器を補充することを願っています。
コードはPython 3.6( リポジトリ )にあります。 OpenCVライブラリが必要です。 読者は、線形代数とコンピュータービジョンの基本を理解することが期待されます。
ボタン自体を見つけることに焦点を当てます。 長方形を見つけることも簡単な方法で解決できるため、価格タグを見つけることを覚えていますが、ソリューションは同じように見えるため、省略します。
テンプレートマッチング
頭に浮かぶ最初の考えは、なぜピクセルの色差の点でボタンに最も似ている領域を写真で見つけて見つけるだけではないのですか? これがテンプレートのマッチングを行うものです-テンプレートに最も類似した画像上のスペースを見つけることに基づいた方法です。 画像の「類似性」は、特定のメトリックによって定義されます。 つまり、パターンは画像に「重ね合わされ」、画像とテンプレートの不一致が考慮されます。 この不一致が最小になるテンプレートの位置。目的のオブジェクトの場所を示します。
たとえば、テンプレートと写真の差の二乗和(差の二乗和、SSD)などのさまざまなオプションをメトリックとして使用したり、相互相関(CCORR)を使用したりできます。 fとgをそれぞれ寸法(k、l)と(m、n)の画像とテンプレートとします(ここではカラーチャネルを無視します)。 i、j-テンプレートを「添付」した画像上の位置。
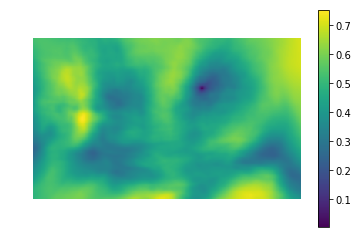
子猫を見つけるために二乗の差を適用してみましょう

写真で

(PETA Caring for Catsからの写真)。
左の写真は、写真内の場所とテンプレートの類似性のメトリック値です(つまり、異なるi、jのSSD値)。 暗い領域は、差が最小の場所です。 これは、テンプレートに最も似ている場所へのポインタです。右の写真では、この場所は丸で囲まれています。

相互相関は、実際には2つの画像の畳み込みです。 コンボリューションは、高速フーリエ変換を使用して迅速に実装できます。 畳み込み定理によれば、フーリエ変換後、畳み込みは単純な要素ごとの乗算になります。
どこで -畳み込み演算子。 このようにして、相互相関をすばやく計算できます。 これにより、 O(kllog(kl)+ mnlog(mn))とO(klmn)を正面から実装した場合の全体的な複雑さがわかります。 差の2乗は畳み込みを使用して実現することもできます。これは、ブラケットを開いた後、画像のピクセル値の2乗の合計と相互相関の差になるためです。
詳細は、このプレゼンテーションで確認できます。
実装に移りましょう。 幸いなことに、Nizhny Novgorod Intel部門の同僚がOpenCVライブラリを作成してくれました。既にmatchTemplateメソッドを使用してテンプレート検索を実装しています(ちなみに、FFT実装を使用していますが、これはドキュメントには記載されていませんが)、 異なる不一致のメトリックを使用しています :
- CV_TM_SQDIFF-ピクセル値の差の二乗の合計
- CV_TM_SQDIFF_NORMED-範囲0.1.1に正規化された、色差の二乗の合計。
- CV_TM_CCORR-テンプレートと画像セグメントの要素ごとの積の合計
- CV_TM_CCORR_NORMED-要素の合計が機能し、-1..1。の範囲に正規化されます。
- CV_TM_CCOEFF-平均のない画像の相互相関
- CV_TM_CCOEFF_NORMED-平均なしの画像間の相互相関、-1..1に正規化(ピアソン相関)
子猫を見つけるためにそれらを使用します。

TM_CCORRのみがそのタスクに対処しなかったことがわかります。 これは理解できることです。これはスカラー積であるため、このメトリックの最大値は、テンプレートを白い長方形と比較するときです。
これらのメトリックには、目的の画像でピクセルごとのパターンマッチングが必要であることに気付くかもしれません。 ガンマ、光、またはサイズに偏差があると、メソッドが機能しなくなります。 これはまさに私たちの場合であることを思い出させてください:ボタンは異なるサイズと異なる色にすることができます。
異なる色と光の問題は、エッジ検出フィルターを適用することで解決できます。 この方法では、画像のどこにシャープな色の変化があったかに関する情報のみが残ります。 さまざまな色と明るさのボタンにCanny Edge Detectorを適用します(もう少し分析します)。 左側は元のバナーで、右側はキャニーフィルターを適用した結果です。

私たちの場合、さまざまなサイズの問題もありますが、すでに解決されています。 対数極座標変換は、画像を、ズームと回転がオフセットとして表示されるスペースに変換します。 この変換を使用して、スケールと角度を復元できます。 その後、テンプレートをスケーリングおよび回転することにより、元の画像内のテンプレートの位置を見つけることができます。 この手順全体でFFTを使用することもできます( 「変換、回転、およびスケール不変画像のレジストレーションのためのFFTベースの手法」を参照) 。 文献では、水平および垂直パターンが比例的に変化し、スケール係数が小さな制限(2.0 ... 0.8)内で変化する場合を考慮しています。 残念ながら、ボタンのサイズ変更は大きく、不均衡になる可能性があり、結果が不正確になる可能性があります。
結果の構造(キャニーフィルター、対数極変換によるスケールのみの復元、最小2次不一致のある場所の検出による位置の取得)を適用して、3つの画像のボタンを見つけます。 大きな黄色のボタンをテンプレートとして使用します。

同時に、バナーのボタンはさまざまな種類、色、サイズになります。

ボタンのサイズを変更した場合、メソッドは正しく機能しませんでした。 これは、水平方向と垂直方向の両方で同じ回数だけボタンのサイズを変更する必要があるためです。 ただし、これは常にそうではありません。 右の写真では、ボタンのサイズは垂直方向ではなく水平方向に変更されており、大幅に減少しています。 サイズ変更が大きすぎる場合、対数極座標変換によって引き起こされる歪みにより、検索が不安定になります。 この点で、メソッドは3番目のケースでボタンを検出できませんでした。
キーポイント検出
別の方法を試すこともできます。ボタン全体を探す代わりに、ボタンの角や境界要素など、ボタンの典型的な部分を見つけましょう(ボタンの輪郭に沿って装飾的なストロークがあります)。 角と境界線は小さな(したがって単純な)オブジェクトであるため、見つけやすいようです。 四隅と境界線の間にあるのはボタンです。 キーポイントを見つけるためのメソッドのクラスは「キーポイント検出」と呼ばれ、キーポイントを使用して画像を比較および検索するアルゴリズムは「キーポイントマッチング」と呼ばれます。 画像内のパターンの検索は、パターンと画像にキーポイントを検出するアルゴリズムを適用し、パターンと画像のキーポイントを比較することになります。
通常、「キーポイント」は、周囲に特定のプロパティを持つピクセルを見つけることで自動的に検出されます。 それらを見つけるための多くの方法と基準が発明されました。 これらのアルゴリズムはすべて、原則として、角度またはシャープな色の変化など、いくつかの特徴的な画像要素を見つけるヒューリスティックです。 優れた検出器は迅速に動作し、画像の変換に耐性があります(画像を変更する場合、キーポイントが停止/移動しないようにする必要があります)。
ハリスコーナー検出器
最も基本的なアルゴリズムの1つはHarrisコーナー検出器です。 写真について(ここでは、「強度」-グレースケールに変換された画像で動作していると考えます)、彼は、強度の差が特定のしきい値よりも大きい付近のポイントを見つけようとします。 アルゴリズムは次のようになります。
強度から X軸とY軸の微分( そして それぞれ)。 たとえば、Sobelフィルターを適用することで見つけることができます。
ピクセルについては、正方形を考慮してください 四角 そして働く そして 。 一部のソースは、 、 そして -これらは強度の二次導関数であると考えるかもしれないので、明快さを追加しません(これはそうではありません)。
各ピクセルについて、特定の近傍(1ピクセル以上)の合計と次の特性を考慮します。
テンプレート検出の場合と同様に、大きなウィンドウに対するこの手順は、畳み込み定理を使用して効率的に実行できます。
各ピクセルについて、値を計算します ヒューリスティックR
価値 範囲[0.04、0.06]で経験的に選択された場合 一部のピクセルには特定のしきい値があり、その近傍 このピクセルには角度が含まれており、キーポイントとしてマークします。
前の式では、キーポイントのクラスターを互いに隣接して作成できます。その場合、それらを削除する価値があります。 これは、各ポイントに値があるかどうかを確認することで実行できます すぐ隣の人の間で最大。 そうでない場合、キーポイントは除外されます。 この手順は、 非最大抑制と呼ばれます。
フォーミュラ 理由で選ばれました。 -構造テンソルの成分-近傍の勾配の挙動を記述する行列:
この行列は、多くの点でその共分散行列に似ています。 たとえば、両方とも正の半正定行列ですが、類似性はこれに限定されません。 共分散行列には幾何学的な解釈があることを思い出してください。 共分散行列の固有ベクトルは、ソースデータ(共分散が計算された)の最大分散の方向を示し、固有値は軸に沿った散布を示します。

http://www.visiondummy.com/2014/04/geometric-interpretation-covariance-matrix/から撮影した画像
構造テンソルの固有値も同じように動作します:勾配の広がりを表します。 平坦な表面では、構造テンソルの固有値は小さくなります(勾配自体の広がりが小さいため)。 顔のある画像に構築された構造テンソルの固有値は大きく異なります。1つの数値は大きく(顔に垂直な方向のベクトルに対応)、2番目の数値は小さくなります。 角度テンソルでは、両方の固有値が大きくなります。 これに基づいて、ヒューリスティック( 構造テンソルの固有値です)。
両方の固有値が大きい場合、このヒューリスティックの値は大きくなります。
固有値の合計は行列のトレースであり、対角線上の要素の合計として計算できます(そして、式AとBを見ると、これが領域の勾配の長さの二乗の合計でもあることが明らかになります)。
固有値の積は行列の行列式であり、2x2の場合にも簡単に記述できます。
したがって、効果的に計算できます 、構造テンソルのコンポーネントの観点から表現します。
速い
Harrisの方法は優れていますが、多くの代替方法があります。 上記の方法と同じようにすべてを検討するのではなく、いくつかの人気のあるものだけを取り上げて、興味深いトリックを示し、それらを実際に比較します。

FASTアルゴリズムによってチェックされるピクセル
Harrisメソッドの代替はFASTです。 名前が示すように、FASTは上記の方法よりもはるかに高速です。 このアルゴリズムは、オブジェクトのエッジとコーナーにあるポイントを見つけようとします。 コントラストの違いの場所で。 FASTは、候補ピクセルの周りに半径Rの円を構築し、K単位だけ候補ピクセルより暗い(または明るい)長さtのピクセルの連続セグメントがあるかどうかを確認します。 この条件が満たされると、ピクセルは「キーポイント」と見なされます。 特定のtに対して、非コーナーであることが保証されているピクセルをカットするいくつかの予備チェックを追加することにより、このヒューリスティックを効率的に実装できます。 たとえば、 そして 、4つの極端なピクセルのうち、Kの中心より厳密に暗い/明るい3つの連続したピクセルがあるかどうかを確認するだけで十分です(写真-1、5、9、13)。 この条件により、間違いなく重要なポイントではない候補者を効果的にカットできます。
SIFT
以前のアルゴリズムは両方とも、画像サイズの変更に耐性がありません。 オブジェクトの縮尺が変更されている場合、画像内でテンプレートを見つけることはできません。 SIFT (スケール不変特徴変換)は、この問題の解決策を提供します。 キーポイントを抽出する画像を取得し、小さなステップでそのサイズを徐々に縮小し始めます。各スケールオプションに対してキーポイントが見つかります。 スケーリングは難しい手順ですが、ピクセルをスキップすることで2/4/8 / ...倍に効率的に削減できます(SIFTでは、これらの複数のスケールは「オクターブ」と呼ばれます)。 中間スケールは、異なるコアサイズのガウスブルーを画像に適用することで近似できます。 上で説明したように、これは計算効率的に実行できます。 結果は、最初に画像を縮小し、次に元のサイズに拡大した場合のように見えます-小さな細部は失われ、画像は「ぼやけ」ます。
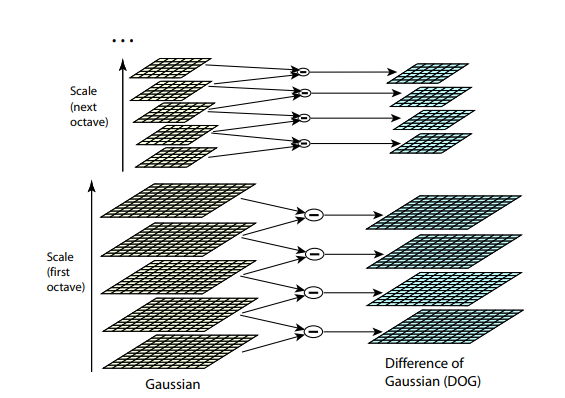
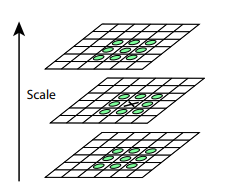
この手順の後、隣接するスケール間の差を計算します。 次のレベルのスケールで小さな詳細が見えなくなるか、逆に次のレベルのスケールで前のレベルでは見えなかった部分がキャプチャされ始めると、この差の大きな値(絶対値)が判明します。 この手法は、DoG、差分ガウスと呼ばれます。 この違いの大きな重要性は、画像上のこの場所に何か面白いものがあるというシグナルであると推測できます。 しかし、このキーポイントが最も表現力のあるスケールに興味があります。 これを行うために、キーポイントは周囲と異なるポイントであるだけでなく、さまざまな画像スケール間で最も強く異なるポイントであると見なします。 つまり、スペースXとYだけでなく、スペースでもキーポイントを選択します。 。 SIFTでは、これはDoG(ガウス分布の差)内のポイントを見つけることで行われます。これらのポイントは、 空間の立方体 彼女の周り:
キーポイントを見つけ、SIFTおよびSURF記述子を構築するためのアルゴリズムは特許を取得しています。 つまり、商用利用にはライセンスを取得する必要があります。 そのため、メインのopencvパッケージからは入手できず、個別のopencv_contribパッケージからのみ入手できます。 ただし、これまでのところ、私たちの研究は本質的に純粋に学術的であるため、比較してSIFTに参加することを妨げるものは何もありません。
記述子
何らかの種類の検出器(たとえば、Harris)をテンプレートと画像に適用してみましょう。


写真とテンプレートで重要な点を見つけたら、どうにかしてそれらを互いに比較する必要があります。 これまで、キーポイントの位置のみを抽出してきました。 このポイントの意味(たとえば、見つかった角度がどの方向に向けられているか)は、まだ決定されていません。 そして、そのような説明は、イメージポイントとパターンを互いに比較するときに役立ちます。 画像内のテンプレートのポイントの一部は、他のオブジェクトで覆われた歪みによってシフトされる可能性があるため、相互のポイントの位置のみに依存することは信頼できないようです。 したがって、特定の説明(記述子)を作成するために各キーポイントの近傍を取得します。これにより、2つのポイント(テンプレートから1つ、写真から1つ)を取得し、それらの類似性を比較できます。
簡単な
記述子をバイナリ配列(つまり、0と1の配列)の形式で作成する場合、2つの記述子のXORを作成することでそれらを非常に効率的に比較し、結果として1の数を計算できます。 そのようなベクターを作成する方法は? たとえば、キーポイントの近傍にあるN組のポイントを選択できます。 次に、i番目のペアについて、最初のポイントが2番目のポイントより明るいかどうかを確認し、明るい場合は、記述子のi番目の位置に1を書き込みます。したがって、長さNの配列を作成できます。近隣の単一のポイント(たとえば、近隣の中心がキーポイント自体)の場合、そのような記述子はノイズに対して不安定になります。1ピクセルの明るさを少し変更するだけで、記述子全体が「移動」します。 研究者は、ポイントをランダムに選択することが非常に効率的であることを発見しました(キーポイントを中心とする正規分布から)。 これは、 Briefアルゴリズムの基礎です。

著者が検討したペア生成方法の一部。 各セグメントは、生成されたポイントのペアを象徴しています。 著者は、GIIオプションが他のオプションよりもわずかに優れていることを発見しました。
ペアを選択したら、それらを修正する必要があります(つまり、記述子が計算されるたびにペアを生成するのではなく、一度生成してから覚えておく必要があります)。 OpenCVの実装では、これらのペアは事前に完全に生成され、 ハードコーディングされています。
SIFT記述子
SIFTは、画像内の異なるオクターブにガウスぼかしを適用した結果を使用して、記述子を効率的に読み取ることもできます。 記述子を計算するために、SIFTはキーポイントの周囲の16x16領域を選択し、4x4ピクセルブロックに分割します。 各ピクセルについて、グラデーションが考慮されます(キーポイントが見つかった同じスケールとオクターブで動作します)。 各ブロックのグラデーションは、方向(上、上、右、右など)に8つのグループに分けられます。 各グループでは、勾配の長さの合計-8つの数値が取得されます。これは、ブロック内の勾配の方向を記述するベクトルとして表すことができます。 このベクトルは、明るさの変化に対する耐性について正規化されています。 したがって、各ブロックに対して、単位長の8次元ベクトルが計算されます。 これらのベクトルは、長さが128の1つの大きな記述子に連結されます(4 * 4 = 16ブロックの近傍で、それぞれが8つの値を持つ)。 ユークリッド距離は、記述子の比較に使用されます。
比較
互いに最も適切なキーポイントのペアを見つける(たとえば、記述子によって最も類似したものから始めて、熱心にペアを作成する)と、最終的にテンプレートと画像を比較できます。

猫が見つかりました-しかし、ここでは、テンプレートと写真の断片との間にピクセルごとの対応があります。 そして、ボタンの場合はどうなりますか?
長方形のボタンがあるとします。 キーポイントが角にある場合、ポイントのロケールの4分の3がボタンの外側にあるものになります。 そして、ボタンの外側にあるものは、ボタンの上にあるものに応じて、写真ごとに大きく異なります。 背景が変化したときに、ハンドルのどの割合が一定のままになりますか? Brief記述子では、ペアの座標はロケールでランダムに独立して選択されるため、両方のポイントがボタン上にある場合にのみ記述子ビットは一定のままです。 つまり、Briefでは、記述子の1/16のみが変更されません。 SIFTでは、状況はわずかに改善されています。ブロック構造のため、記述子の1/4は変更されません。
この点で、SIFT記述子を引き続き使用します。
検出器の比較
ここで、取得したすべての知識を適用して問題を解決します。 私たちの場合、キーポイント検出器の要件は十分です。サイズを変更するための不変性と非常に高いパフォーマンスは必要ありません。 3つの検出器すべてを比較します。
| ハリスコーナー検出器 | 速い | SIFT |
|---|---|---|
 |  |  |
 |  |  |
 |  |  |
SIFTは、ボタン上のキーポイントが非常に少ないことを発見しました。 — , .
, . . , , , , . , , () . . , (, , ) , . , . - : , .
— , , , , ( , , ). , , "", , . , " " .
, . , , , , . ( , ) , , . , , — , , , . :
Contour detection
— - ( — ), . (/edges), , . contour detection.
Edge detection
keypoint detection, -, . , . , Harris corner detector. そして 。 , — : (, , ). , , ( non-maximum suppression), 8 , 8, I, :
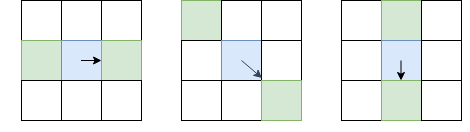
, — I. — , non-maximum suppression.
, . , non-maximum suppression , .
, non-maximum suppression , - , Il. “double thresholding”: Il, , Low, High “ ”. , Low High, “ ”, “ ”:
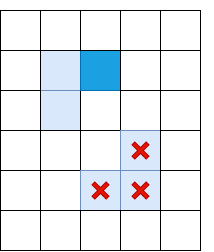
- “ ”, - — . , .
Canny Edge Detector. , .
Border tracking
— . ( , ), , . non-maximum suppression Canny, , , . , , -, “”. , ( ), ( , - ):

border tracking, (, , ), . , .
, — ? > , . “” , , , . , — . , contour matching , — , ( ). , . , :
- ( 100 )
- . 0.8, — , 20% — .
, , , . Canny , , - .
:

Canny filter (2 ) , - , - non-max suppression . (3 ) .
. , , . , . , .
|  |
|  |
|  |
|
. , (1 ~20) iOS Appstore Google Apps, ( ). , .
おわりに
まとめると。 “” CV deep learning - , . , , . , , .
- Template Matching — , , ( - ) . . , .
- キーポイントの検出/マッチング -キーポイントを見つけ、画像とテンプレートのポイントを一致させます。検出器は、回転、ズーム(選択した検出器と記述子に依存)、および部分的なオーバーラップに対するマッチングに耐性があります。ただし、この方法は、オブジェクトに十分な「キーポイント」があり、テンプレートのロケールと画像ポイントが非常によく一致する場合(つまり、テンプレートと写真の同じオブジェクト)にのみ有効です。
- 輪郭検出 -オブジェクトの輪郭を見つけ、目的のオブジェクトの輪郭に類似した輪郭を見つけます。 このソリューションでは、オブジェクトの形状のみが考慮され、その内容と色(プラスとマイナスの両方)が無視されます。
知識のある読者であれば、コンピュータビジョンの最新の訓練された方法を使用して問題を解決できることに気付くかもしれません。 たとえば、 YOLOネットワークは目的のオブジェクトのバウンディングボックスを返します。これが私たちの関心事です。 はい、ディープラーニングに基づいたソリューションのテストと立ち上げに成功しましたが、2回目の反復として(ローカライズツールが起動して動作を開始した後)。 これらのソリューションは、ボタンパラメーターの変更に対してより耐性があり、多くの肯定的なプロパティがあります。たとえば、しきい値とパラメーターを手で拾う代わりに、トレーニングセットにネットワークが誤っているバナー(アクティブラーニング)の例を追加できます。 タスクにディープラーニングを使用することには、問題と興味深い点があります。 たとえば、多くの最新のコンピュータービジョン手法では、多数のマークアップ画像が必要ですが、マークアップがなく(多くの実際の場合)、異なるバナーの総数は数千を超えません。 そのため、少数の画像を自分でレイアウトし、それらに基づいて他の同様のバナーを作成するジェネレーターを作成することにしました。 この方向には、多くの興味深いトリックがあります。 他にも多くの落とし穴があり、コンピュータービジョンオブジェクトの位置を決定するまさにそのタスクは膨大であり、多くの解決策があります。 したがって、記事の範囲を制限することが決定され、ディープラーニングに基づく決定は考慮されませんでした。
説明されているメソッドを実装し、記事の絵を描くメモ帳を含むコードは、 リポジトリにあります )。