
この記事では、 SNA Hackathon 2019タスクのテキスト部分に対するソリューションについて説明します。 提案されたアイデアのいくつかは、3月30日から4月1日までMail.ru Groupのモスクワ事務所で開催されるハッカソンのフルタイム部分の参加者にとって有用です。 さらに、この物語は、機械学習の実際的な問題を解決する読者にとっても興味深いものです。 私は賞品を請求できないので(私はOdnoklassnikiで働いています)、最もシンプルであると同時に効果的で興味深いソリューションを提供しようとしました。
機械学習の新しいモデルについて読んで、タスクに取り組んでいるときに著者がどのように推論したかを理解したいと思います。 したがって、この記事では、ソリューションのすべてのコンポーネントを詳細に実証しようとします。 最初の部分では、問題の説明と制限について説明します。 第二に-モデルの進化について。 3番目の部分は、モデルの結果と分析に専念します。 最後に、コメントで、発生した質問に答えようとします。 せっかちな読者は、すぐに最終的なアーキテクチャを見ることができます。
挑戦する
Hackathonの主催者は、スマートテープを作成する問題を解決することを提案しました。 ユーザーごとに、ユーザーが「クラス」を設定した投稿の最大数がリストの一番上になるように投稿のセットをソートする必要があります。 ランキングアルゴリズムを設定するには、フォームの履歴データ(ユーザー、投稿、フィードバック)を使用することになっています。 この表では、テキスト部分のデータの簡単な説明と、この記事で使用する表記法を示します。
| 出所
| 指定
| 種類
| 説明
|
|---|---|---|---|
| ユーザー
| user_id
| カテゴリー
| ユーザーID
|
| ポスト
| post_id
| カテゴリー
| 投稿ID
|
| ポスト
| テキスト
| カテゴリーリスト
| 正規化された単語のリスト
|
| ポスト
| 特徴
| カテゴリー
| 投稿の特性のグループ(著者、言語など)
|
| フィードバック
| フィードバック
| バイナリリスト
| ユーザーが投稿で実行できるさまざまなアクション(ビュー、クラス、コメントなど)
|
モデルの構築を開始する前に、将来のソリューションにいくつかの制限を導入しました。 これは、シンプルさと実用性、私の興味の要件を満たし、可能なオプションの数を減らすために必要でした。 これらの制限の中で最も重要なものを次に示します。
「クラス」の確率の予測 。 私はすぐにこの問題を分類問題として解決することにしました。 たとえば、ランキングで使用される方法を適用して、投稿のペアの順序を予測できます。 しかし、「クラス」を取得する予測確率に従って投稿をソートする、より単純な定式化に決めました。 以下に説明するアプローチを拡張してランキングを作成できることに注意してください。
モノリシックモデル 。 モデルのアンサンブルは競争に勝つ傾向があるという事実にもかかわらず、戦闘システムでのアンサンブルの維持は単一のモデルよりも困難です。 さらに、少なくともいくつかの非ブラックボックス解釈機能が必要でした。
微分可能な計算グラフ 。 まず、このクラスのモデル(ニューラルネットワーク) は、 テキスト データの 分析に関連するタスクを含む、多くのタスクの最先端を決定します 。 次に、最新のフレームワーク(私の場合はApache MXNet )を使用すると、非常に多様なアーキテクチャを実装できます。 したがって、数行のコードを変更するだけで、さまざまなモデルを試すことができます。
兆候と最小限の作業 。 モデルを新しいデータで簡単に拡張したかった。 これは、サインを準備する時間がほとんどないフルタイム部分で必要になる場合があります。 したがって、私は標識の選択への最も簡単なアプローチに落ち着きました:
- バイナリデータは、値が1または0のタグで表されます。
- 数値データはそのままか、カテゴリに離散化されます。
- カテゴリデータは埋め込みによって表示されます。
一般的な戦略を決定した後、さまざまなモデルを試し始めました。
モデルの進化
出発点は、行列分解法であり、推奨タスクでよく使用されます。
計算グラフの言語では、これは、ユーザーiがポストjに 「クラス」を置く確率の推定値が、ユーザー識別子とポスト識別子の埋め込みのスカラー積からのシグモイドであることを意味します。 同じことがダイアグラムで表現できます。

このようなモデルはあまり興味深いものではありません。すべての機能を使用するわけではなく、低頻度の識別子にはあまり有用ではなく、コールドスタートの問題があります。 しかし、計算グラフの形式でタスクを定式化したので、「手を広げて」、段階的に問題を解決できるようになりました。 まず、低頻度の値については、唯一の語彙外埋め込みを作成します。 次に、同じ次元の埋め込みを持つ必要性を取り除きます。 これを行うには、連結された特徴を入力として受け取る浅いパーセプトロンでスカラー積を置き換えます。 結果を図に示します:

固定ディメンションを削除すると、新しい属性の追加を開始できます。 あらゆる種類の特性(言語、著者、テキストなど)で投稿を表現することで、投稿のコールドスタートの問題を解決します。 モデルは、たとえば、 user_id = 42のユーザーが「carpet」という単語を含むロシア語の投稿に「classes」を配置することを学習します 。 将来、トレーニングデータに表示されなかった場合でも、このユーザーにカーペットに関するロシア語の投稿をすべてお勧めできるようになります。 テキストの埋め込みについては、今のところ、含まれている単語の埋め込みを単純に平均します。 その結果、モデルは次のようになります。
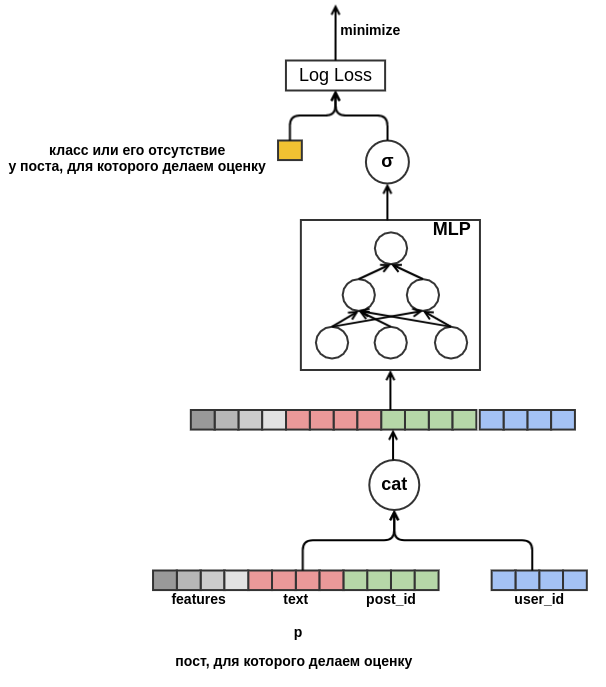
最後に、ユーザーのコールドスタートに対処したいと思います。 投稿のユーザービューの履歴データから機能を構築することが可能です。 このアプローチは、選択した戦略を満たしていません。手動で属性を作成することを最小限に抑えることにしました。 したがって、「クラス」の確率が評価されている投稿の前に表示された一連の投稿から、ユーザーのプレゼンテーションを独立して学習する機会をモデルに提供しました。 評価対象の投稿とは異なり、すべてのフィードバックはシーケンス内の各投稿について既知です。 これは、ユーザーが以前の投稿を「クラス」に設定したか、またはその逆でフィードから削除したかに関する情報にアクセスできることを意味します。

異なる長さのポストのシーケンスを固定幅の表現に結合する方法を決定することは残っています。 このような組み合わせとして、各投稿の表現の加重和を使用しました。 チャートでは、ポストウェイトjは α_j で示されています 。 重みは、 transformerまたはNMTで使用されるものと同様のクエリキー値アテンションメカニズムを使用して計算されました。 したがって、ユーザーが学習したプレゼンテーションは、評価が実行されている投稿に対しても構成されます。 以下は、 α_jを計算するグラフの一部です。
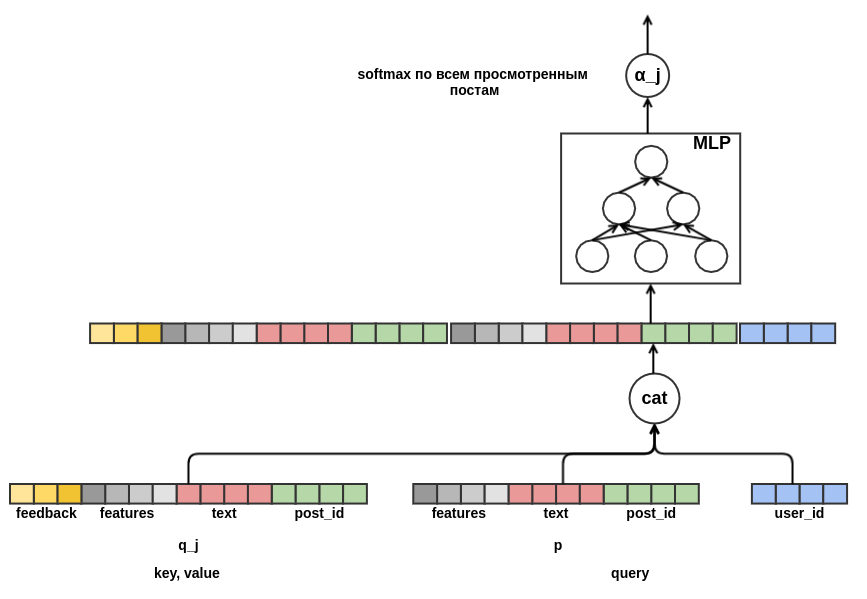
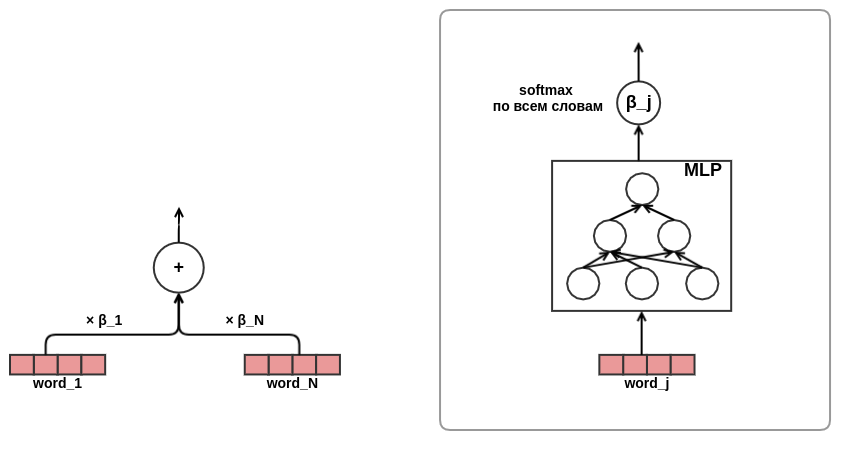
これで、モデルのアーキテクチャの開発が完了しました。 その結果、私は古典的な行列分解からかなり複雑なシーケンスモデルに移行しました。
結果と分析
16 GBのメモリとGeForce 930MXグラフィックスカードを搭載したラップトップ上のデータの7分の1でソリューションを開発およびデバッグしました。 256 GBのメモリとTesla T4カードを搭載した専用サーバーで完全なデータ実験を実行しました。 最適化のために、MXNetのデフォルトパラメータを使用したAdamアルゴリズムが使用されました。 この表は、簡略化されたモデルの結果を示しています。ポストのシーケンスの長さは10に制限されていました。 コンテストの提出では、長さ50のシーケンスを使用しました。
| モデル
| ログ損失
| 前の行からの改善
| トレーニング時間
|
|---|---|---|---|
| ランダム
| 0.4374±0.0009
| ||
| パーセプトロン
| 0.4330±0.0010
| 0.0043±0.0002
| 7分
|
| 標識付きパーセプトロン
| 0.4119±0.0008
| 0.0212±0.0003
| 44分
|
| ポストのシーケンスを持つパーセプトロン
| 0.3873±0.0008
| 0.0247±0.0003
| 4時間16分
|
| テキストに一連の投稿と注意を向けたパーセプトロン
| 0.3874±0.0008
| 0.0001±0.0001
| 4時間43分
|
最後の行は、私にとって最も予期せぬものであることが判明しました。テキストの表示に注意を払っても、結果に目に見える改善はありません。 私は、アテンションネットワークがidfのようなテキストの単語の重みを学習することを期待していました。 主催者が事前にストップワードを削除し、準備されたリストにはほぼ同じ重要度の単語が残っていたため、おそらくこれは起こらなかったでしょう。 したがって、「スマート」計量は、単純な平均化と比較して明確な利点を与えませんでした。 もう1つの考えられる理由は、単語のアテンションネットワークが非常に小さかったということです。これには、1つの狭い隠れ層しか含まれていませんでした。 おそらく彼女は何か有用なことを学ぶための表現能力を欠いていました。
クエリキー値アテンションメカニズムは、モデルの内部を調べ、意思決定を行う際にモデルが「アテンションを払う」ものを見つける機会を提供します。 これを説明するために、いくつかの例を選択しました 。
, http://ollston.ru/2018/02/10/uznajte-kakogo-cveta-vasha - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.16] 2016 2016 GZ8btjgY_Q0 https: - [0.16] . Nike http://ollston.ru/2018/02/04/istorii-yspeha-nike/ - : - [0.09] - 5 - 5 O3qAop0A5Qs https://ww - [0.09] ... , - [0.22] Microsoft Windows — http://ollston.ru/2018/02/06/microsoft-windows-istoriia-yspeha/ - [0.20] , 6 . , ? http://ollston.ru/2018/02/08/buddisty-g
最初の行は、評価する必要がある投稿のテキストを示し、次に以前に表示した投稿と対応するアテンションスコアを示します。 安心して、我々はモデルがパディングを無視することを学んだことに気付きます。 このモデルでは、魂の種類とWindowsについて、投稿が最も重要であると見なされました。 注意は肯定的(ユーザーが魂の種類に関する投稿とほぼ同じ方法でオーラに関する投稿に応答する)、または否定的(私たちはオーラに関する投稿を評価します-したがって、反応は投稿に対する反応と同じではないことに注意してください)テクノロジー)。 次の例は、「すべての栄光に」注目です。
- [0.20] 2018 (), , . - [0.08] ... !!! - [0.04] ))) - [0.18] ! , . 10 - [0.18] 2- , 5 , , 2 , . . - [0.07] ! - () - [0.03] "". . - [0.13] , - [0.05] , ... - [0.05] ...
ここでは、モデルは夏休みのテーマを明確に見ました。 子供や子猫でさえ道端を通りました。 次の例は、注意の解釈が常に可能であるとは限らないことを示しています。 時には何もはっきりしないこともあります:
! - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.15] , ! !!! - [0.16] ! http://gifok.ru/dobryj-vecher/ - [0.20] http://gifq.ru/aforizmy/ - [0.25] . . - [0.15] , . : 800 250-300
そのようなリストをいくつか見て、モデルは私が期待したことを学ぶことができたと結論付けました。 次に私がしたことは、言葉の埋め込みを見ることでした。 私たちの問題では、埋め込みが言語モデルを学習するときほど美しいとは期待できません:かなりノイズの多い変数を予測しようとしているだけでなく、小さなコンテキストウィンドウがありません-すべての単語の埋め込みは、テキスト内の順序を考慮せずに単純に平均化されます 埋め込みスペース内のトークンとそれらの最も近い隣人の例:
- : , , , , - : , , , , - : , , , , - : , , , , - : , , , ,
このリストの一部は説明しやすい(プログラム-bl)、何かが戸惑う(iPhone-youki)が、一般的には結果は再び私の期待に応えた。
おわりに
私は微分可能なグラフに基づいてモデルを構築するアプローチが好きです( 多くの人が 同意します )。 面倒な機能の手動選択から離れて、問題の正しい定式化と興味深いアーキテクチャの設計に集中できます。 そして、私のモデルはSNA Hackathon 2019テキストタスクで2位に過ぎませんでしたが、そのシンプルさとほぼ無制限の拡張オプションを考えると、この結果に非常に満足しています。 将来的には、同様のアイデアに基づいた戦闘システムに、より興味深く、適用可能なモデルが増えると確信しています。