どのようにすべてが始まりましたか?
ストリーミングは、FASTEN RUS BIプラットフォームの重要なコンポーネントです。 日付分析チームは、リアルタイムレポートを使用して、運用レポートを作成します。
ストリーミングアプリケーションは、 Spark Structured Streamingを使用して実装されます。 このフレームワークは、改善の速度という点でニーズを満たす便利なデータ変換APIを提供します。
ストリーム自体はAWS EMRクラスターで上昇しました。 そのため、クラスターに新しいストリームを上げると、Sparkジョブの送信時にsshスクリプトがレイアウトされ、その後アプリケーションが起動されました。 そして、最初はすべてが私たちに合っているように見えました。 しかし、ストリームの数が増えると、CIストリーミングの必要性がますます明らかになり、新しいエンティティでデータを配信するためのアプリケーションを起動する際の分析日付コマンドの自律性が高まります。
次に、ストリーミングをKubernetesに移植することで、この問題をどのように解決したかを見ていきます。
Kubernetesを選ぶ理由
リソースマネージャーとしてのKubernetesは、私たちのニーズに最適です。 これは、ダウンタイムのない展開であり、Helmを含むKubernetes上の幅広いCI実装ツールです。 さらに、私たちのチームは、K8でのCIパイプラインの実装に関する十分な専門知識を持っていました。 したがって、選択は明らかでした。
KubernetesベースのSparkアプリケーション管理モデルはどのように構成されていますか?

クライアントはK8でspark-submitを実行します。 アプリケーションドライバーポッドが作成されます。 Kubernetes Schedulerはポッドをクラスターノードにバインドします。 次に、ドライバーは、エグゼクティブを実行するポッドを作成する要求を送信し、ポッドが作成されてクラスターノードに接続されます。 その後、標準の操作セットが実行され、その後アプリケーションコードがDAGに変換され、ステージに分解され、タスクに分割され、実行可能ファイルで起動されます。
このモデルは、Sparkアプリケーションを手動で起動するときに非常にうまく機能します。 ただし、クラスターの外部でスパーク送信を起動するアプローチは、CIの実装という点では適していませんでした。 Sparkをクラスターノードで直接実行(spark-submitを実行)できるソリューションを見つける必要がありました。 ここで、Kubernetes Operatorモデルは要件を完全に満たしました。
Sparkアプリケーションライフサイクル管理モデルとしてのKubernetes Operator
Kubernetes Operatorは、 CoreOSが提案するKubernetesのステートフルアプリケーションを管理する概念であり、アプリケーションの展開、ファイルの場合のアプリケーションの再起動、アプリケーションの構成の更新などの運用タスクの自動化を伴います。 重要なKubernetes Operatorパターンの1つはCRD( CustomResourceDefinitions )です。これは、カスタムリソースをK8sクラスターに追加することを含み、ネイティブのKubernetesオブジェクトと同様にこれらのリソースを操作できます。
オペレーターは、クラスターのポッドに存在し、カスタムリソースの状態の作成/変更に応答するデーモンです。
Sparkアプリケーションのライフサイクル管理のためにこの概念を検討してください。
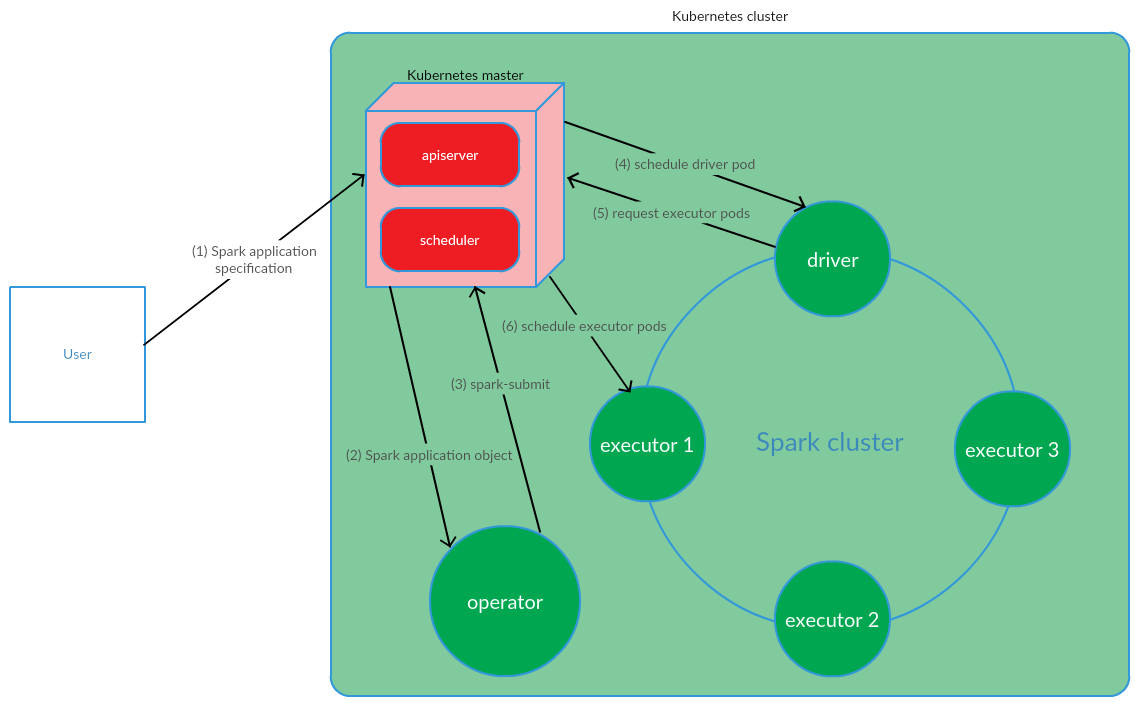
ユーザーはkubectl apply -f spark-application.yamlコマンドを実行します。ここで、spark-application.yamlはSparkアプリケーションの仕様です。 オペレーターは、Sparkアプリケーションオブジェクトを受け取り、spark-submitを実行します。
ご覧のとおり、Kubernetes Operatorモデルは、Kubernetesクラスターで直接Sparkアプリケーションのライフサイクルを管理することを含みます。これは、問題を解決するコンテキストでこのモデルを支持する重大な議論でした。
ストリーミングアプリケーションを管理するためのKubernetes Operatorとして、 spark-on-k8s-operatorを使用することが決定されました。 この演算子は、非常に便利なAPIを提供するだけでなく、Sparkアプリケーションの再起動ポリシーを構成する柔軟性も提供します(ストリーミングアプリケーションをサポートするコンテキストでは非常に重要です)。
CIの実装
CIストリーミングを実装するために、 GitLab CI / CDが使用されました 。 K8でのSparkアプリケーションの展開は、 Helmツールを使用して行われました。
パイプライン自体には2つの段階が含まれます。
- test-Helmテンプレートのレンダリングと同様に、構文チェックが実行されます。
- deploy-テスト(dev)および製品(prod)環境へのストリーミングアプリケーションのデプロイ。
これらの段階をより詳細に検討しましょう。
テスト段階では、SparkアプリケーションのHelmテンプレート(CRD- SparkApplication )が環境固有の値でレンダリングされます。
Helm-templateの主要なセクションは次のとおりです。
- 火花:
- version-Apache Sparkのバージョン
- image-使用されたDockerイメージ
- nodeSelector-囲炉裏のラベルに対応するリスト(キー→値)が含まれます。
- 許容値-Sparkアプリケーションの許容値のリストを示します。
- mainClass-Sparkアプリケーションクラス
- applicationFile-Sparkアプリケーションjarファイルがあるローカルパス
- restartPolicy-Sparkアプリケーションの再起動ポリシー
- Never-完成したSparkアプリケーションは再起動しません
- 常に-完了したSparkアプリケーションは、停止の理由に関係なく再起動します。
- OnFailure-Sparkアプリケーションはファイルの場合にのみ再起動します
- maxSubmissionRetries-Sparkアプリケーションの送信の最大数
- ドライバー/エグゼキューター:
- cores-ドライバー/エグゼキューターに割り当てられたカーネルの数
- インスタンス(エグゼクティブの構成にのみ使用)-エグゼクティブの数
- メモリ-ドライバ/エグゼキュータプロセスに割り当てられたメモリの量
- memoryOverhead-ドライバー/エグゼキューターに割り当てられたオフヒープメモリの量
- ストリーム:
- name-ストリーミングアプリケーションの名前
- arguments-ストリーミングアプリケーションへの引数
- sink-S3上のData Lakeデータセットへのパス
テンプレートをレンダリングした後、アプリケーションはHelmを使用してdevテスト環境にデプロイされます。
CIパイプラインを作成しました。
次に、deploy-prodジョブを起動します-本番環境でアプリケーションを起動します。
私たちは、ジョブの成功した実行を確信しています。
以下を見るとわかるように、アプリケーションは実行中であり、ポッドはRUNNINGステータスです。

おわりに
Spark構造化ストリーミングアプリケーションをK8に移植し、その後のCIの実装により、新しいエンティティにデータを配信するためのストリームの起動を自動化することができました。 次のストリームを上げるには、値のyamlファイルでSparkアプリケーションの設定の説明を含むマージリクエストを準備するだけで十分です。deploy-prodジョブが開始されると、Data Lake(S3)へのデータ配信が開始されます。 このソリューションにより、リポジトリへの新しいエンティティの追加に関連するタスクを実行するときに分析日付コマンドの自律性が確保されました。 さらに、ストリーミングをK8sに移植し、特にKubernetes Operator spark-on-k8s-operatorを使用してSparkアプリケーションを管理すると、ストリーミングの復元力が大幅に向上しました。 しかし、それについては次の記事で詳しく説明します。