まず第一に、それは節約です-開発とデバッグの時間を節約し、同様に重要なこと-プロジェクト予算からお金を節約します。 エミュレータがエミュレートしようとしている元の環境と100%同一ではないことは明らかです。 しかし、プロセスの開発と自動化を加速するためには、既存の類似性で十分です。 2018年にAWSで最も話題になったのは、ロシア連邦のAWSサブネットのIPアドレスのIPプロバイダーによるブロックです。 また、これらのロックは、Amazonクラウドにあるインフラストラクチャに影響を与えました。 AWSテクノロジーを使用してプロジェクトをこのクラウドに配置することを計画している場合、エミュレーションを開発およびテストすることは、見返り以上のものです。
この出版物では、既存のデータウェアハウスを長年AWSに移行する際に、S3、SQS、RDS PostgreSQL、およびRedshiftサービスでこのようなトリックをどのように達成したかを説明します。
これは、AWSおよびJavaハブのテーマと一致する、昨年の地図上の会議の一部にすぎません。 2番目の部分はPostgreSQL、Redshift、および列データベースに関連し、そのテキストバージョンは対応するハブで公開される場合があります。ビデオおよびスライドは会議Webサイトにあります。
AWSサブネットのブロック中にAWS向けのアプリケーションを開発する際、チームは事実上、新しい機能を開発する日々のプロセスでそれらに気付きませんでした。 テストも機能し、アプリケーションをデバッグできます。 そして、ログエントリでアプリケーションログを確認しようとしたときのみ、SignalFXのメトリックまたはRedshift / PostgreSQL RDSのデータ分析は失望しました。サービスはロシアのプロバイダーのネットワークを介して利用できませんでした。 AWSエミュレーションにより、VPNネットワークを介してAmazonクラウドを操作する際に、これに気付かずに大幅な遅延を回避できました。
「内部」の各クラウドプロバイダーには多くのドラゴンがいるため、広告に屈するべきではありません。 サービスプロバイダーがこのすべてを必要とする理由を理解する必要があります。 もちろん、Amazon、Microsoft、Googleの既存のインフラストラクチャには利点があります。 そして、すべてがあなたの開発を便利にするためだけに行われていると彼らが言うとき、彼らはあなたの針にあなたを置いて、無料で最初の服用を与えようとしている可能性が高いです。 後で、彼らはインフラストラクチャと特定の技術から降りません。 したがって、ベンダーのロックインを回避しようとします。 特定の決定から完全に抽象化することが常に可能であるとは限らないことは明らかであり、プロジェクトのほぼ90%を抽象化することは非常に頻繁に可能であると思います。 しかし、プロジェクトの残りの10%は、非常に重要なテクノロジーのプロバイダーに結びついており、アプリケーションのパフォーマンスを最適化するか、他に類を見ない独自の機能のいずれかです。 クラウドインフラプロバイダーの特定のAPIに「座る」のではなく、テクノロジーの長所と短所を常に覚えて、可能な限り自身を保護する必要があります。
AmazonはWebサイトでメッセージ処理について書いています 。 メッセージ交換テクノロジーの本質と抽象化はどこでも同じですが、キューやトピックを通過するメッセージというニュアンスがあります。 そのため、AWSは、既存のメッセージングブローカーからアプリケーションを移行するため、および新しいAmazon SQS / SNSアプリケーション用に提供および管理されるApache ActiveMQを使用することをお勧めします。 これは、標準化されたJMS APIおよびプロトコルAMQP、MMQT、STOMPの代わりに、独自のAPIにバインドする例です。 このプロバイダーとそのソリューションのパフォーマンスが向上し、スケーラビリティーがサポートされるなどのことは明らかです。 私の観点からすると、標準化されたAPIではなくライブラリを使用する場合、さらに多くの問題が発生します。
AWSにはRedshiftデータベースがあります。 これは、大規模な並列アーキテクチャを備えた分散データベースです。 Amazonの複数のRedshftサイトのテーブルに大量のデータをアップロードし、大規模なデータセットに対して分析クエリを実行できます。 これは、ACIDの保証が十分な頻度で少数のレコードに対して小さなリクエストを実行することが重要なOLTPシステムではありません。 Redshiftを使用する場合、単位時間あたりのクエリ数は多くないと想定されていますが、非常に大量のデータの集計を読み取ることができます。 このシステムは、AWS上のデータウェアハウス(ウェアハウス)をアップグレードし 、簡単なデータロードを約束するためにベンダーによって配置されています 。 それはまったく真実ではありません。
Amazon Redshiftがサポートするタイプに関するドキュメントからの抜粋。 これはかなり貧弱なセットであり、ここにリストされていないデータを保存および処理する必要がある場合、作業が困難になります。 たとえば、GUID。
ホールからの質問、「そしてJSON?」
-JSONはVARCHARとしてのみ記述でき、JSONを操作するための関数がいくつかあります。
聴衆からのコメント:「Postgresには通常のJSONサポートがあります。」
-はい、このタイプのデータと機能をサポートしています。 ただし、 Redshiftは PostgreSQL 8.0.2に基づいています。 誤解しない限り、ParAccelプロジェクトがありました。2005年のこのテクノロジーは、大規模並列アーキテクチャに基づく分散リクエストのスケジューラーを備えたpostgresのフォークです。 5〜6年が経過し、このプロジェクトはAmazon Web Servcesプラットフォームのライセンスを取得し、Redshiftと名付けられました。 オリジナルのPostgresから何かが削除され、多くが追加されました。 彼らは、AWSの認証/承認に関連する役割を追加し、Amazonのセキュリティが正常に機能することを追加しました。 ただし、たとえば、Foreign Data Sourceを使用してRedshiftから別のデータベースに接続する必要がある場合、これは見つかりません。 XMLを使用するための関数、JSONを2回使用するための関数、および誤って計算された関数はありません。
アプリケーションを開発するときは、特定の実装に依存しないようにしてください。アプリケーションコードは抽象化のみに依存します。 これらのファサードと抽象化は自分で作成できますが、この場合、既製のライブラリが多数あります-ファサード。 特定の実装、特定のフレームワークからコードを抽象化するものであり、テクノロジーの「共通点」として、すべての機能をサポートしているわけではないことは明らかです。 テストを簡素化するには、抽象化に基づいてソフトウェアを開発することをお勧めします。
AWSをエミュレートするために、2つのオプションに言及します。 1つ目はより正直で正確ですが、動作はより遅くなります。 2つ目はダーティで高速です。 ハックオプション(インフラストラクチャ全体を1つのプロセスで作成しようとしている)について説明します。テストとクロスプラットフォームオプションは、Windowsでの作業でより高速に動作します(Dockerは常にお金を稼ぐことができません)。
最初の方法は、linux / macosで開発していてdockerを使用している場合に最適です。アトラシアンlocalstackを使用することをお勧めします。 testcontainerを使用してlocalstackをJVMに統合すると便利です。
開発がWindowsで行われているプロジェクトのdockerでlockalstackを使用することをやめ、このプロジェクトが開始されたときに誰もdockerのアルファ版を保証しませんでした...深刻な企業ではLinuxおよびdockerを使用した仮想マシンのインストールが許可されないこともあります情報セキュリティへ。 私は、投資銀行の保護された環境で働くことや、ほとんどすべてのトラフィックファイアウォールを禁止することについて話しているのではありません。
Simple storage S3をエミュレートするオプションを検討しましょう。 これはAmazonの通常のファイルシステムではなく、オブジェクトの分散リポジトリです。 データの変更や追加の可能性なしに、データをBLOBとして配置します。 他のメーカーの同様の本格的な分散ストレージがあります。 たとえば、Ceph分散オブジェクトストレージを使用すると、 S3 RESTプロトコルと既存のクライアントを使用して、最小限の変更でその機能を操作できます。 しかし、これはJavaアプリケーションの開発とテストのためのかなり重いソリューションです。
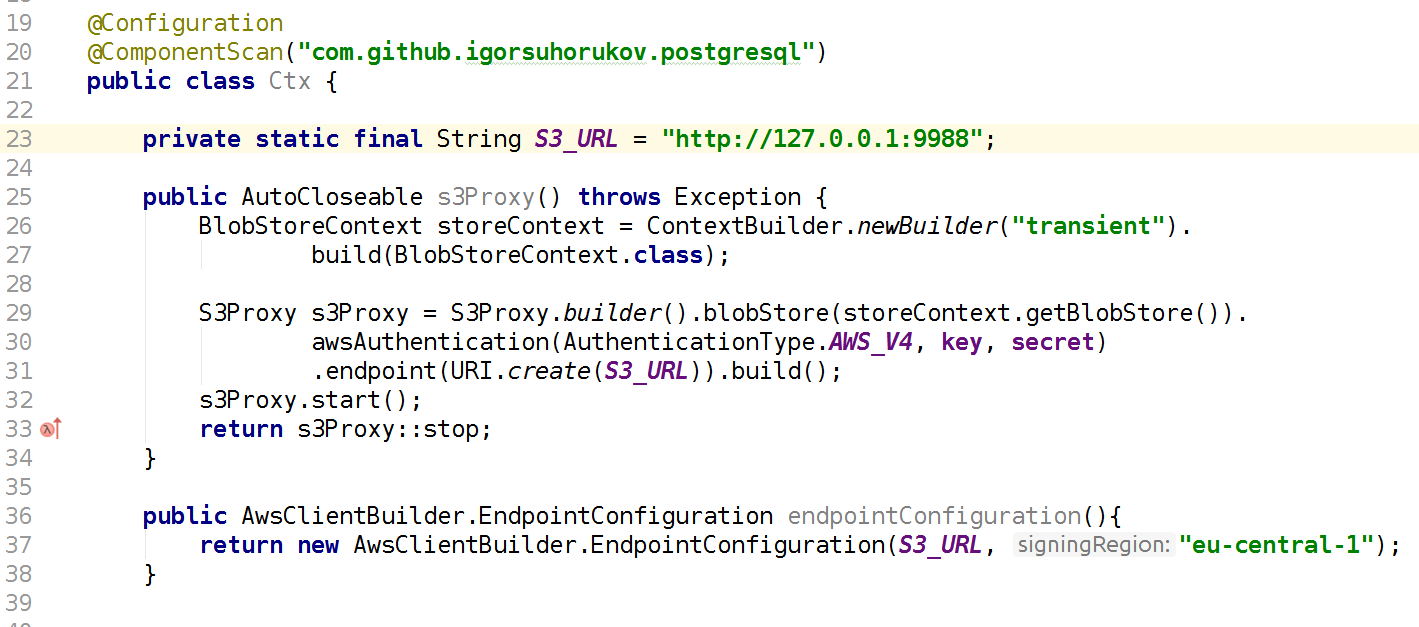
より高速で適切なプロジェクトは、 s3proxy javaライブラリです。 S3 RESTプロトコルをエミュレートし、対応するjcloud API呼び出しに変換し、データの実際の読み取りと保存に多くの実装を使用できるようにします。 Google App Engine API、Microsoft Azure APIへの呼び出しをブロードキャストできますが、テストではRAM内のjcloud一時ストレージを使用する方が便利です。 また、認証プロトコルAWS S3のバージョンを構成し、キーとシークレットの値を指定し、エンドポイント(このS3プロキシがリッスンするポートとインターフェイス)も構成する必要があります。 したがって、AWS SDKクライアントを使用するコードは、AWSリージョンではなく、S3 AWSエンドポイントにテストで接続する必要があります。 繰り返しますが、s3proxyはS3 APIのすべての機能をサポートしているわけではありませんが、使用シナリオはすべて完全にエミュレートしています! s3proxyでは、大きなファイルのマルチパートアップロードもサポートされています。
Amazon Simple Queue Serviceはキューイングサービスです。 scalaで記述されたelasticmqキューサービスがあり、Amazon SQSプロトコルを使用してアプリケーションに提示できます。 プロジェクトでは使用しなかったため、初期化コードを提供し、開発者からの情報を信頼します。

プロジェクトでは、私は別の方法で行ったが、コードはJmsTemplateとJmsListenerのspring-jms抽象化に依存し、プロジェクトの依存関係はSQS com.amazonawsのJMSドライバーを指定します:amazon-sqs-java-messaging-lib。 これは、メインアプリケーションコードに関係するものです。

テストでは、Artemis-jms-serverをテスト用の埋め込みJMSサーバーとして接続し、テストのSpringコンテキストでは、SQS接続ファクトリーの代わりに、Artemis接続ファクトリーを使用します。 Artemisは、テストソリューションだけでなく、本格的な最新のメッセージ指向ミドルウェアであるApache ActiveMQの次のバージョンです。 おそらく、自動テストだけでなく、将来の使用に移行するでしょう。 したがって、JMS抽象化とSpringを組み合わせて使用することで、アプリケーションコードとそれを簡単にテストする機能の両方を簡素化しました。 依存関係org.springframework.boot:spring-boot-starter-artemisおよびorg.apache.activemq:artemis-jms-serverを追加するだけです。

一部のテストでは、PostgreSQLをH2Databaseに置き換えることでエミュレートできます。 これは、テストが受け入れられず、特定のPG機能を使用しない場合に機能します。 同時に、H2はデータ型と関数をサポートせずにPostgreSQLプロトコルワイヤのサブセットをエミュレートできます。 このプロジェクトでは、Foreing Data Wrapperを使用しているため、この方法は機能しません。
実際のPostgreSQLを実行できます。 postgresql-embeddedは、実際のディストリビューションをダウンロードするか、実行しているプラットフォームのバイナリファイルを含むアーカイブをダウンロードし、解凍します。 LinuxのRAMのtempfs、Windowsの%TEMP%で、postgresqlサーバープロセスが起動し、サーバー設定とデータベースパラメーターを構成します。 ディストリビューション配布機能により、PG 11より古いバージョンはLinuxでは動作しません。 私自身は、HTTPサーバーだけでなくmavenリポジトリからもPostgreSQLバイナリアセンブリを取得できるラッパーライブラリを作成しました。 これは、隔離されたネットワークで作業し、インターネットアクセスなしでCIサーバー上に構築するときに非常に役立ちます。 ラッパーを使用する際のもう1つの便利な機能は、CDIコンポーネントの注釈です。これにより、たとえばSpringコンテキストでコンポーネントを簡単に使用できます。 AutoClosableサーバーインターフェイスの実装は、元のプロジェクトよりも早く登場しました。 サーバーを停止することを覚えておく必要はありません。Springコンテキストが自動的に閉じられると停止します。
起動時に、スクリプトに基づいてデータベースを作成し、適切なプロパティでSpringコンテキストを補完できます。 テストでデータベースが作成されるたびに起動されるデータベーススキーマを移行するために、 フライウェイスクリプトを使用してデータベーススキーマを作成しています。
テストの実行後にデータを検証するには、spring-test-dbunitライブラリを使用します。 テストメソッドへの注釈では、どのアンロードでデータベースの状態を比較するかを示します。 これにより、dbunitで動作するコードを記述する必要がなくなり、ライブラリリスナーをテストコードに追加するだけで済みます。 データベースコンテキストがテスト間で再利用される場合、テストメソッドの完了後にテーブルからデータが削除される順序を指定できます。 2019年には、junit5で動作するデータベースライダーに実装されたより現代的なアプローチがあります 。 使用例、たとえばこちらをご覧ください 。
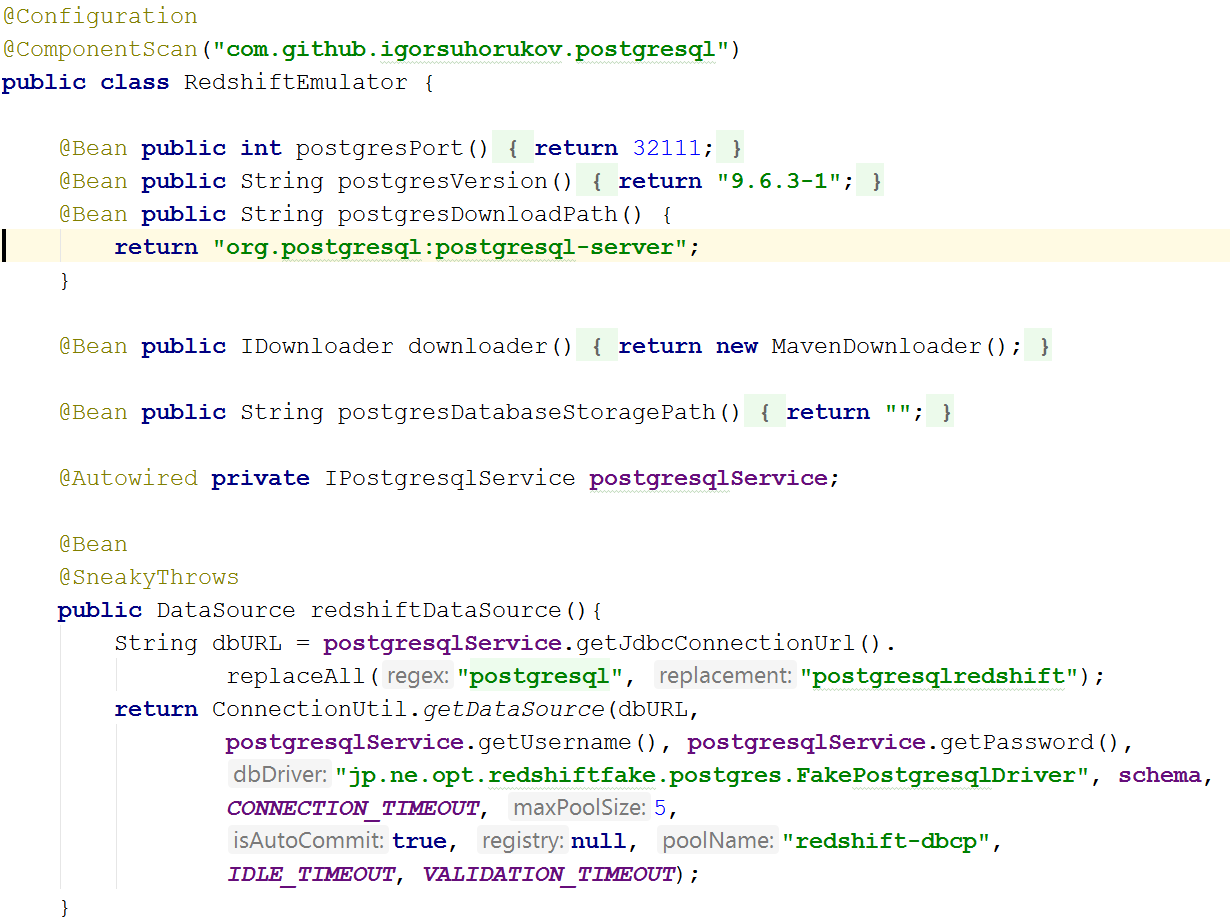
最も難しいのは、Amazon Redshiftをエミュレートすることでした。 redshift-fake-driverプロジェクトがあり、AWSから分析データベースへのバッチデータの読み込みをエミュレートすることに焦点を当てています。 jdbc:postgresqlredshiftプロトコルエミュレーターでは、COPY、UNLOADコマンドが実装され、他のすべてのコマンドは通常のJDBC PostgreSQLドライバーに委任されました。
したがって、テストは更新操作であるRedshiftとは異なり、更新用のデータソースとして異なるテーブルを使用します(RedshiftとPostgreSQL 9+では構文が異なります。これらのデータベース間でSQLコマンドの行引用の解釈が異なることにも気付きました。
実際のRedshiftデータベースのアーキテクチャにより、データの挿入、更新、削除の操作はかなり遅く、I / Oの点で「高価」です。 大きな「パケット」にのみ許容可能なパフォーマンスでデータを挿入することができ、COPYコマンドを使用すると、分散S3ファイルシステムからデータをダウンロードできます。 データベース内のこのコマンドは、AVRO、CSV、JSON、Parquet、ORC、TXTのいくつかのデータ形式をサポートしています。 そして、エミュレータープロジェクトはCSV、TXT、JSONに焦点を当てています。
そのため、テストでRedshiftをエミュレートするには、前述のようにPostgreSQLデータベースを起動し、S3リポジトリのエミュレーションを開始する必要があります。postgresへの接続を作成するときは、クラスパスにredshift-fake-driverを追加し、ドライバークラスjp.ne.opt.redshiftfake.postgresを指定するだけです。 FakePostgresqlDriver。 その後、同じフライウェイを使用してデータベーススキーマを移行できます。dbunitは、テストを実行した後のデータの比較にすでに慣れています。
どのくらいの読者が仕事でAWSとRedshiftを使用しているのだろうか? あなたの経験についてのコメントを書いてください。
チームはオープンソースプロジェクトのみを使用して、AWSサブネットがRoskomnadzorによってブロックされたときにチームの作業を停止することなく、AWS環境での開発を加速し、プロジェクト予算からお金を節約することに成功しました。