
パート1/3はこちら 。
パート2/3はこちら 。
みなさんこんにちは! そして、これがKubernetesベアメタルチュートリアルの3番目のパートです! クラスターの監視とログの収集に注意を払います。また、事前構成されたクラスターコンポーネントを使用するテストアプリケーションを起動します。 次に、いくつかのストレステストを実行し、このクラスタースキームの安定性を確認します。
KubernetesコミュニティがWebベースのインターフェースを提供し、クラスター統計を取得するために提供する最も人気のあるツールはKubernetes Dashboardです。 実際、まだ開発中ですが、現在でも、アプリケーションのトラブルシューティングやクラスターリソースの管理のための追加データを提供できます。
トピックは部分的に物議を醸しています。 クラスタを管理するために何らかのWebインターフェイスが必要なのは本当ですか、 それともkubectlコンソールツールを使用するのに十分ですか? まあ、時にはこれらのオプションは互いに補完します。
Kubernetesダッシュボードを展開して見てみましょう。 標準展開では、このダッシュボードはローカルホストアドレスでのみ開始されます。 したがって、 拡張にはkubectlプロキシコマンドを使用する必要がありますが、ローカルのkubectl制御デバイスでのみ使用可能です。 セキュリティの観点からは悪くありませんが、ブラウザーのクラスター外でアクセスしたいので、いくつかのリスクを負う準備ができています(結局、有効なトークンを持つsslが使用されます)。
私の方法を適用するには、サービスセクションで標準の展開ファイルをわずかに変更する必要があります。 オープンアドレスでこのダッシュボードを開くには、ロードバランサーを使用します。
設定済みのkubectlユーティリティを使用してマシンシステムに入り、以下を作成します。
control# vi kube-dashboard.yaml # Copyright 2017 The Kubernetes Authors. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ------------------- Dashboard Secret ------------------- # apiVersion: v1 kind: Secret metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard-certs namespace: kube-system type: Opaque --- # ------------------- Dashboard Service Account ------------------- # apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Role & Role Binding ------------------- # kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kubernetes-dashboard-minimal namespace: kube-system rules: # Allow Dashboard to create 'kubernetes-dashboard-key-holder' secret. - apiGroups: [""] resources: ["secrets"] verbs: ["create"] # Allow Dashboard to create 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] verbs: ["create"] # Allow Dashboard to get, update and delete Dashboard exclusive secrets. - apiGroups: [""] resources: ["secrets"] resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs"] verbs: ["get", "update", "delete"] # Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] resourceNames: ["kubernetes-dashboard-settings"] verbs: ["get", "update"] # Allow Dashboard to get metrics from heapster. - apiGroups: [""] resources: ["services"] resourceNames: ["heapster"] verbs: ["proxy"] - apiGroups: [""] resources: ["services/proxy"] resourceNames: ["heapster", "http:heapster:", "https:heapster:"] verbs: ["get"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kubernetes-dashboard-minimal namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: kubernetes-dashboard-minimal subjects: - kind: ServiceAccount name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Deployment ------------------- # kind: Deployment apiVersion: apps/v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: k8s-app: kubernetes-dashboard template: metadata: labels: k8s-app: kubernetes-dashboard spec: containers: - name: kubernetes-dashboard image: k8s.gcr.io/kubernetes-dashboard-amd64:v1.10.1 ports: - containerPort: 8443 protocol: TCP args: - --auto-generate-certificates # Uncomment the following line to manually specify Kubernetes API server Host # If not specified, Dashboard will attempt to auto discover the API server and connect # to it. Uncomment only if the default does not work. # - --apiserver-host=http://my-address:port volumeMounts: - name: kubernetes-dashboard-certs mountPath: /certs # Create on-disk volume to store exec logs - mountPath: /tmp name: tmp-volume livenessProbe: httpGet: scheme: HTTPS path: / port: 8443 initialDelaySeconds: 30 timeoutSeconds: 30 volumes: - name: kubernetes-dashboard-certs secret: secretName: kubernetes-dashboard-certs - name: tmp-volume emptyDir: {} serviceAccountName: kubernetes-dashboard # Comment the following tolerations if Dashboard must not be deployed on master tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule --- # ------------------- Dashboard Service ------------------- # kind: Service apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: type: LoadBalancer ports: - port: 443 targetPort: 8443 selector: k8s-app: kubernetes-dashboard
次に実行します:
control# kubectl create -f kube-dashboard.yaml control# kubectl get svc --namespace=kube-system kubernetes-dashboard LoadBalancer 10.96.164.141 192.168.0.240 443:31262/TCP 8h
ご覧のとおり、BNがこのサービスにIP 192.168.0.240を追加しました。 https://192.168.0.240を開いてKubernetesダッシュボードを表示してみてください 。
アクセスするには、2つの方法があります。以前にkubectlをセットアップするときに使用したマスターノードからadmin.conf
ファイルを使用するか、セキュリティトークンで特別なサービスアカウントを作成します。
管理者ユーザーを作成しましょう:
control# vi kube-dashboard-admin.yaml apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kube-system control# kubectl create -f kube-dashboard-admin.yaml serviceaccount/admin-user created clusterrolebinding.rbac.authorization.k8s.io/admin-user created
次に、システムにログインするためのトークンが必要です。
control# kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}') Name: admin-user-token-vfh66 Namespace: kube-system Labels: <none> Annotations: kubernetes.io/service-account.name: admin-user kubernetes.io/service-account.uid: 3775471a-3620-11e9-9800-763fc8adcb06 Type: kubernetes.io/service-account-token Data ==== ca.crt: 1025 bytes namespace: 11 bytes token: erJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwna3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJr dWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VmLXRva2VuLXZmaDY2Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZ XJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIzNzc1NDcxYS0zNjIwLTExZTktOTgwMC03Nj NmYzhhZGNiMDYiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW4tdXNlciJ9.JICASwxAJHFX8mLoSikJU1tbij4Kq2pneqAt6QCcGUizFLeSqr2R5x339ZR8W4 9cIsbZ7hbhFXCATQcVuWnWXe2dgXP5KE8ZdW9uvq96rm_JvsZz0RZO03UFRf8Exsss6GLeRJ5uNJNCAr8No5pmRMJo-_4BKW4OFDFxvSDSS_ZJaLMqJ0LNpwH1Z09SfD8TNW7VZqax4zuTSMX_yVS ts40nzh4-_IxDZ1i7imnNSYPQa_Oq9ieJ56Q-xuOiGu9C3Hs3NmhwV8MNAcniVEzoDyFmx4z9YYcFPCDIoerPfSJIMFIWXcNlUTPSMRA-KfjSb_KYAErVfNctwOVglgCISA
トークンをコピーして、ログイン画面のトークンフィールドに貼り付けます。
システムに入った後、クラスターをもう少し詳しく調べることができます。このツールが気に入っています。
クラスターの監視システムを深めるための次のステップは、 heapsterをインストールすることです 。
Heapsterでは、コンテナクラスタを監視し、 Kubernetes (バージョンv1.0.6以降)のパフォーマンスを分析できます。 適切なプラットフォームを提供します。
このツールは、コンソールを介してクラスターの使用統計を提供し、ノードおよびハースリソースに関する詳細情報をKubernetesダッシュボードに追加します。
ベアメタルにインストールするのはほとんど困難ではなく、調査を行う必要がありました。元のバージョンでツールが機能しない理由ですが、解決策が見つかりました。
それでは、このアドオンを続けて承認しましょう。
control# vi heapster.yaml apiVersion: v1 kind: ServiceAccount metadata: name: heapster namespace: kube-system --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: heapster namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: heapster spec: serviceAccountName: heapster containers: - name: heapster image: gcr.io/google_containers/heapster-amd64:v1.4.2 imagePullPolicy: IfNotPresent command: - /heapster - --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: Heapster name: heapster namespace: kube-system spec: ports: - port: 80 targetPort: 8082 selector: k8s-app: heapster --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: heapster roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:heapster subjects: - kind: ServiceAccount name: heapster namespace: kube-system
これは、Heapsterコミュニティからの最も一般的な標準デプロイファイルです。わずかな違いがあります。クラスターで動作するために、heapsterデプロイの行「 source = 」は次のように変更されます。
--source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true
この説明では、これらのオプションをすべて見つけることができます。 kubeletポートを10250に変更し、SSL証明書の検証を無効にしました(少し問題がありました)。
また、Heapster RBACロールのノード統計を取得するためのアクセス許可を追加する必要があります。 ロールの最後に次の数行を追加します。
control# kubectl edit clusterrole system:heapster ...... ... - apiGroups: - "" resources: - nodes/stats verbs: - get
その結果、RBACの役割は次のようになります。
# Please edit the object below. Lines beginning with a '#' will be ignored, # and an empty file will abort the edit. If an error occurs while saving this file will be # reopened with the relevant failures. # apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" creationTimestamp: "2019-02-22T18:58:32Z" labels: kubernetes.io/bootstrapping: rbac-defaults name: system:heapster resourceVersion: "6799431" selfLink: /apis/rbac.authorization.k8s.io/v1/clusterroles/system%3Aheapster uid: d99065b5-36d3-11e9-a7e6-763fc8adcb06 rules: - apiGroups: - "" resources: - events - namespaces - nodes - pods verbs: - get - list - watch - apiGroups: - extensions resources: - deployments verbs: - get - list - watch - apiGroups: - "" resources: - nodes/stats verbs: - get
OK、コマンドを実行してheapsterデプロイメントが正常に起動することを確認しましょう。
control# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% kube-master1 183m 9% 1161Mi 60% kube-master2 235m 11% 1130Mi 59% kube-worker1 189m 4% 1216Mi 41% kube-worker2 218m 5% 1290Mi 44% kube-worker3 181m 4% 1305Mi 44%
さて、出力に何らかのデータがあれば、すべてが正しく行われています。 ダッシュボードページに戻って、現在利用可能な新しいチャートを確認しましょう。

これからは、クラスターノード、ハースなどのリソースの実際の使用状況も追跡できます。
これで十分でない場合は、InfluxDB + Grafanaを追加して統計をさらに改善できます。 これにより、独自のGrafanaパネルを描画する機能が追加されます。
このバージョンのInfluxDB + GrafanaインストールはHeapster Gitページから使用しますが、通常どおり修正を行います。 すでにヒープスターデプロイを構成しているため、GrafanaとInfluxDBを追加するだけで、既存のヒープスターデプロイを変更して、メトリックもInfluxに配置することができます。
では、InfluxDBとGrafanaの展開を作成しましょう。
control# vi influxdb.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: monitoring-influxdb namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: influxdb spec: containers: - name: influxdb image: k8s.gcr.io/heapster-influxdb-amd64:v1.5.2 volumeMounts: - mountPath: /data name: influxdb-storage volumes: - name: influxdb-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-influxdb name: monitoring-influxdb namespace: kube-system spec: ports: - port: 8086 targetPort: 8086 selector: k8s-app: influxdb
次はGrafanaです。サービス設定を変更して、MetaLBロードバランサーを有効にし、Grafanaサービスの外部IPアドレスを取得することを忘れないでください。
control# vi grafana.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: monitoring-grafana namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: grafana spec: containers: - name: grafana image: k8s.gcr.io/heapster-grafana-amd64:v5.0.4 ports: - containerPort: 3000 protocol: TCP volumeMounts: - mountPath: /etc/ssl/certs name: ca-certificates readOnly: true - mountPath: /var name: grafana-storage env: - name: INFLUXDB_HOST value: monitoring-influxdb - name: GF_SERVER_HTTP_PORT value: "3000" # The following env variables are required to make Grafana accessible via # the kubernetes api-server proxy. On production clusters, we recommend # removing these env variables, setup auth for grafana, and expose the grafana # service using a LoadBalancer or a public IP. - name: GF_AUTH_BASIC_ENABLED value: "false" - name: GF_AUTH_ANONYMOUS_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ORG_ROLE value: Admin - name: GF_SERVER_ROOT_URL # If you're only using the API Server proxy, set this value instead: # value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy value: / volumes: - name: ca-certificates hostPath: path: /etc/ssl/certs - name: grafana-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-grafana name: monitoring-grafana namespace: kube-system spec: # In a production setup, we recommend accessing Grafana through an external Loadbalancer # or through a public IP. # type: LoadBalancer # You could also use NodePort to expose the service at a randomly-generated port # type: NodePort type: LoadBalancer ports: - port: 80 targetPort: 3000 selector: k8s-app: grafana
そしてそれらを作成します。
control# kubectl create -f influxdb.yaml deployment.extensions/monitoring-influxdb created service/monitoring-influxdb created control# kubectl create -f grafana.yaml deployment.extensions/monitoring-grafana created service/monitoring-grafana created
heapsterデプロイメントを変更し、InfluxDB接続を追加します。 1行だけ追加する必要があります。
- --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086
heapsterデプロイを編集します。
control# kubectl get deployments --namespace=kube-system NAME READY UP-TO-DATE AVAILABLE AGE coredns 2/2 2 2 49d heapster 1/1 1 1 2d12h kubernetes-dashboard 1/1 1 1 3d21h monitoring-grafana 1/1 1 1 115s monitoring-influxdb 1/1 1 1 2m18s control# kubectl edit deployment heapster --namespace=kube-system ... beginning bla bla bla spec: containers: - command: - /heapster - --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true - --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086 image: gcr.io/google_containers/heapster-amd64:v1.4.2 imagePullPolicy: IfNotPresent .... end
Grafanaサービスの外部IPアドレスを見つけて、その内部のシステムにログインします。
control# kubectl get svc --namespace=kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ..... some other services here monitoring-grafana LoadBalancer 10.98.111.200 192.168.0.241 80:32148/TCP 18m
ブラウザでhttp://192.168.0.241を開き、初めてadmin / adminの資格情報を使用します。

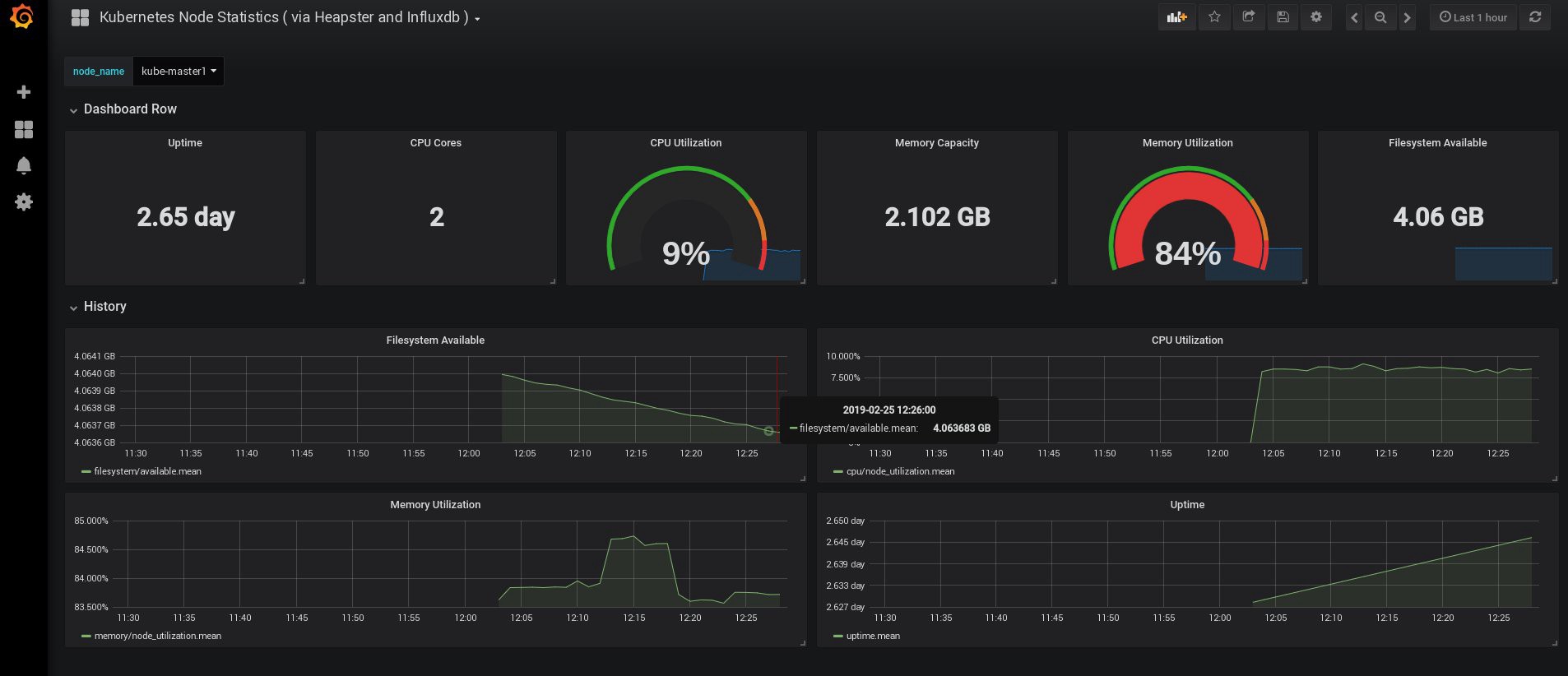
ログインしたとき、Grafanaは空でしたが、幸いなことにgrafana.comから必要なダッシュボードをすべて取得できます。 パネル番号3649および3646をインポートする必要があります。インポート時に、正しいデータソースを選択します。
その後、ノードと炉床のリソースの使用を監視し、もちろん独自のダッシュボードを作成します。
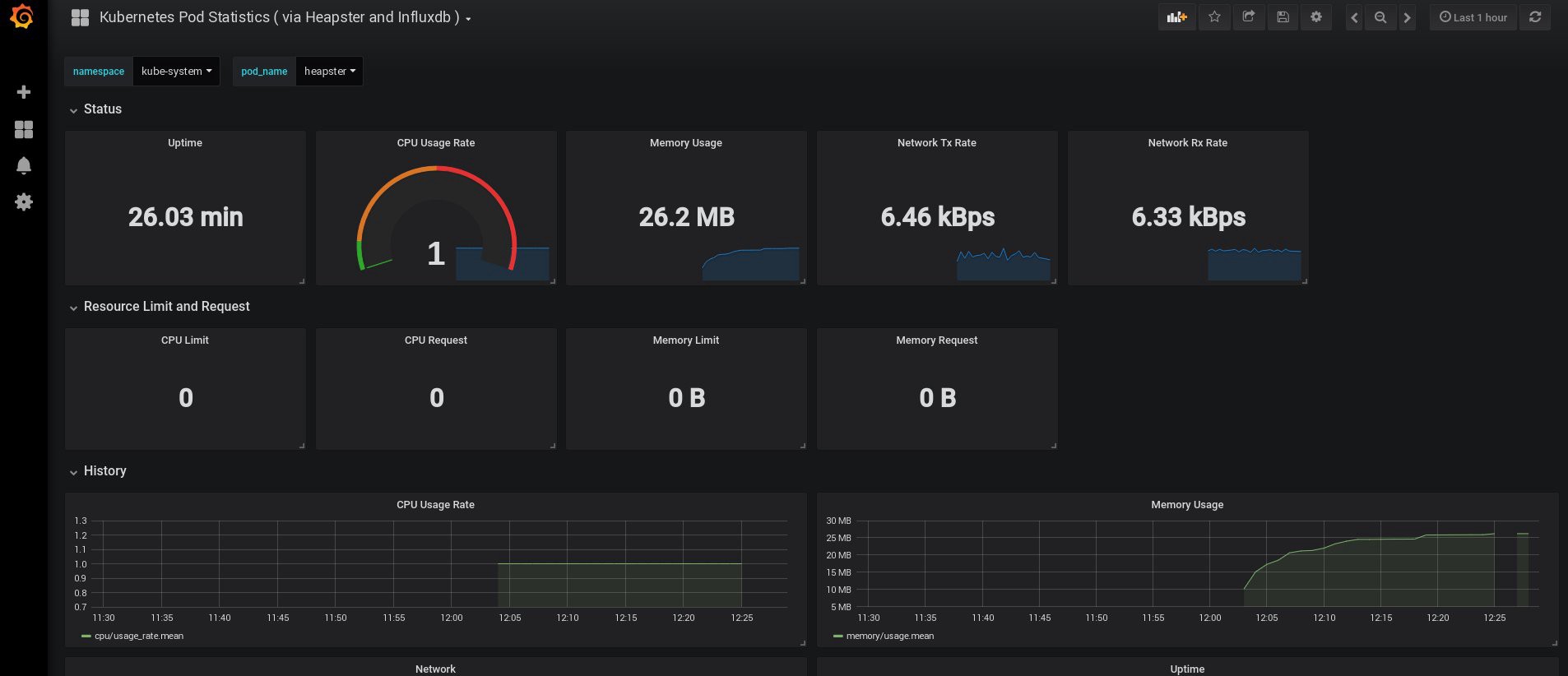
さて、今のところ、監視を終了しましょう。 必要になる可能性がある次の要素は、アプリケーションとクラスターを保存するためのログです。 これを実装するにはいくつかの方法があり、それらはすべてKubernetesのドキュメントで説明されています 。 私自身の経験に基づいて、ElasticsearchおよびKibanaサービスの外部設定、および各Kubernetes作業ノードで実行される登録エージェントのみを使用することを好みます。 これにより、多数のログやその他の問題に関連する過負荷からクラスターが保護され、クラスターが完全に機能しなくなった場合でもログを受信できるようになります。
Kubernetesファンにとって最も人気のあるログコレクションスタックは、Elasticsearch、Fluentd、およびKibana(EFKスタック)です。 この例では、外部ノードでElasticsearchとKibanaを実行し(既存のELKスタックを使用できます)、クラスター内のFluentdをログ収集エージェントとして各ノードのデーモンセットとして実行します。
ElasticsearchとKibanaをインストールしたVMの作成に関する部分はスキップします。 これはかなり人気のあるトピックですので、最適な方法については多くの資料を見つけることができます。 たとえば、私の記事では 。 docker -compose.ymlファイルからlogstash構成フラグメントを削除するだけでなく、 elasticsearchポートセクションから127.0.0.1も削除します。
その後、動作するelasticsearchをVM-IPポート9200に接続する必要があります。 セキュリティを強化するには、fluiddとelasticsearchの間でlogin:passまたはsecurityキーを設定します。 しかし、私はしばしばiptablesルールでそれらを保護します。
あとは、Kubernetesでfluentdデーモンセットを作成し、設定でelasticsearch ノード:ポート外部アドレスを指定するだけです。
ここから yaml設定で公式のKubernetesアドオンを使用しますが 、少し変更します:
control# vi fluentd-es-ds.yaml apiVersion: v1 kind: ServiceAccount metadata: name: fluentd-es namespace: kube-system labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile rules: - apiGroups: - "" resources: - "namespaces" - "pods" verbs: - "get" - "watch" - "list" --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile subjects: - kind: ServiceAccount name: fluentd-es namespace: kube-system apiGroup: "" roleRef: kind: ClusterRole name: fluentd-es apiGroup: "" --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd-es-v2.4.0 namespace: kube-system labels: k8s-app: fluentd-es version: v2.4.0 kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile spec: selector: matchLabels: k8s-app: fluentd-es version: v2.4.0 template: metadata: labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" version: v2.4.0 # This annotation ensures that fluentd does not get evicted if the node # supports critical pod annotation based priority scheme. # Note that this does not guarantee admission on the nodes (#40573). annotations: scheduler.alpha.kubernetes.io/critical-pod: '' seccomp.security.alpha.kubernetes.io/pod: 'docker/default' spec: priorityClassName: system-node-critical serviceAccountName: fluentd-es containers: - name: fluentd-es image: k8s.gcr.io/fluentd-elasticsearch:v2.4.0 env: - name: FLUENTD_ARGS value: --no-supervisor -q resources: limits: memory: 500Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true - name: config-volume mountPath: /etc/fluent/config.d terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: config-volume configMap: name: fluentd-es-config-v0.2.0
次に、特定の構成をfluentdにします。
control# vi fluentd-es-configmap.yaml kind: ConfigMap apiVersion: v1 metadata: name: fluentd-es-config-v0.2.0 namespace: kube-system labels: addonmanager.kubernetes.io/mode: Reconcile data: system.conf: |- <system> root_dir /tmp/fluentd-buffers/ </system> containers.input.conf: |-
@id fluentd-containers.log @type tail path /var/log/containers/*.log pos_file /var/log/es-containers.log.pos tag raw.kubernetes.* read_from_head true <parse> @type multi_format <pattern> format json time_key time time_format %Y-%m-%dT%H:%M:%S.%NZ </pattern> <pattern> format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/ time_format %Y-%m-%dT%H:%M:%S.%N%:z </pattern> </parse>
# Detect exceptions in the log output and forward them as one log entry. <match raw.kubernetes.**> @id raw.kubernetes @type detect_exceptions remove_tag_prefix raw message log stream stream multiline_flush_interval 5 max_bytes 500000 max_lines 1000 </match> # Concatenate multi-line logs <filter **> @id filter_concat @type concat key message multiline_end_regexp /\n$/ separator "" </filter> # Enriches records with Kubernetes metadata <filter kubernetes.**> @id filter_kubernetes_metadata @type kubernetes_metadata </filter> # Fixes json fields in Elasticsearch <filter kubernetes.**> @id filter_parser @type parser key_name log reserve_data true remove_key_name_field true <parse> @type multi_format <pattern> format json </pattern> <pattern> format none </pattern> </parse> </filter> output.conf: |- <match **> @id elasticsearch @type elasticsearch @log_level info type_name _doc include_tag_key true host 192.168.1.253 port 9200 logstash_format true <buffer> @type file path /var/log/fluentd-buffers/kubernetes.system.buffer flush_mode interval retry_type exponential_backoff flush_thread_count 2 flush_interval 5s retry_forever retry_max_interval 30 chunk_limit_size 2M queue_limit_length 8 overflow_action block </buffer> </match>
構成は基本的ですが、クイックスタートには十分です。 システムとアプリケーションのログを収集します。 もっと複雑なものが必要な場合は、fluentdプラグインとKubernetesの構成に関する公式ドキュメントをご覧ください。
それでは、クラスターにfluentdデーモンセットを作成しましょう。
control# kubectl create -f fluentd-es-ds.yaml serviceaccount/fluentd-es created clusterrole.rbac.authorization.k8s.io/fluentd-es created clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created daemonset.apps/fluentd-es-v2.4.0 created control# kubectl create -f fluentd-es-configmap.yaml configmap/fluentd-es-config-v0.2.0 created
流れるすべてのポッドおよびその他のリソースが正常に実行されていることを確認してから、Kibanaを開きます。 Kibanaで、fluentdから新しいインデックスを見つけて追加します。 何かを見つけたら、すべてが正しく行われます。そうでない場合は、前の手順を確認し、daemonsetを再作成するか、configmapを編集します。

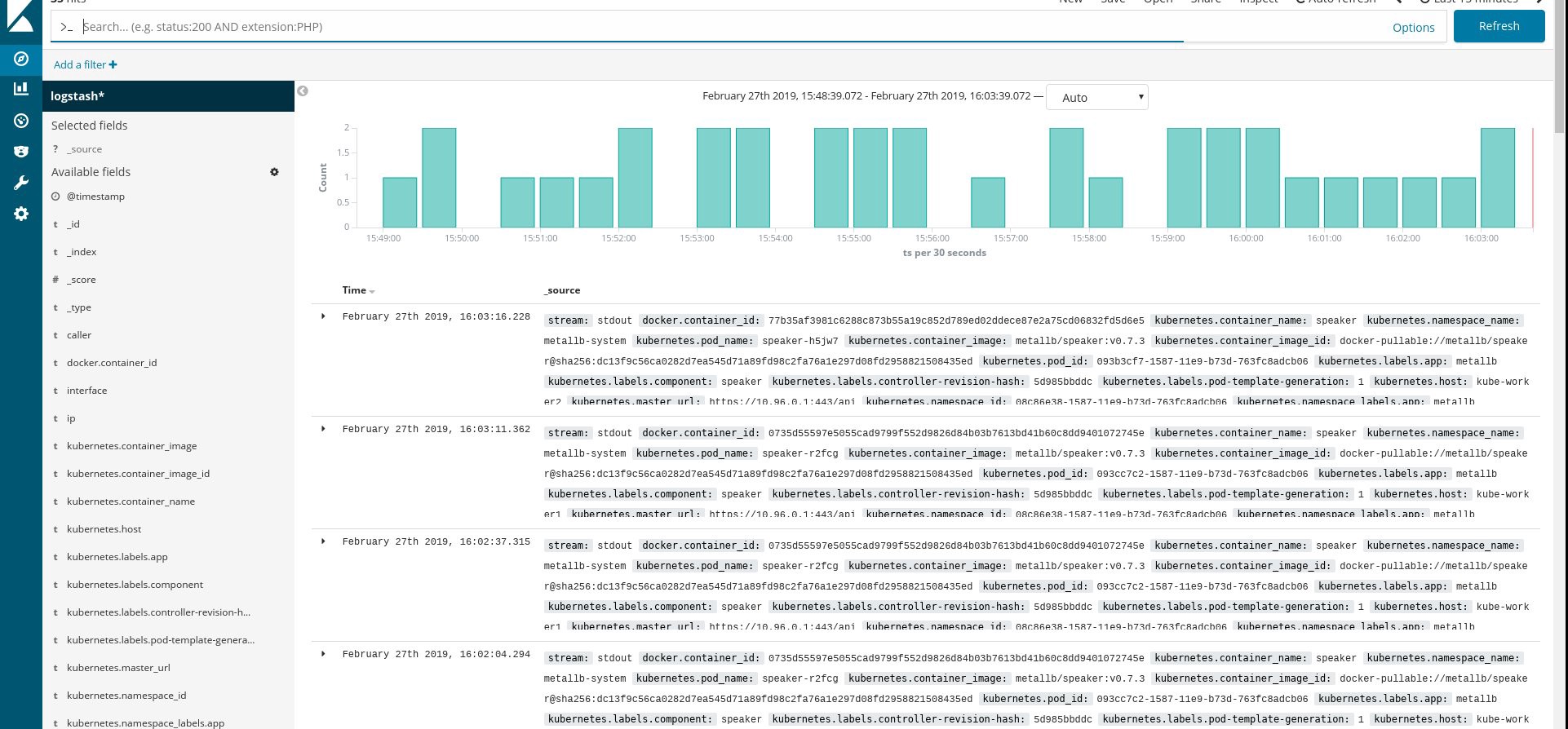
さて、クラスターからログを取得したので、ダッシュボードを作成できます。 もちろん、構成は最も単純なので、おそらく自分で構成を変更する必要があります。 主な目標は、これがどのように行われるかを示すことでした。
これまでのすべての手順を完了すると、すぐに使用できる非常に優れたKubernetesクラスターができました。 テストアプリケーションを埋め込み、何が起こるかを見てみましょう。
この例では、既にDockerコンテナーを持っている小さなPython / Flask Kubykアプリケーションを使用します。そのため、Dockerオープンレジストリから取得します。 次に、このアプリケーションに外部データベースファイルを追加します。これには、構成済みのGlusterFSストレージを使用します。
最初に、このアプリケーション用の新しいpvcボリュームを作成します(永続的なボリューム要求)。ここで、ユーザー資格情報を使用してSQLiteデータベースを保存します。 このガイドのパート2で作成済みのメモリクラスを使用できます。
control# mkdir kubyk && cd kubyk control# vi kubyk-pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: kubyk annotations: volume.beta.kubernetes.io/storage-class: "slow" spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi control# kubectl create -f kubyk-pvc.yaml
アプリケーション用の新しいPVCを作成したら、展開の準備ができました。
control# vi kubyk-deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: name: kubyk-deployment spec: selector: matchLabels: app: kubyk replicas: 1 template: metadata: labels: app: kubyk spec: containers: - name: kubyk image: ratibor78/kubyk ports: - containerPort: 80 volumeMounts: - name: kubyk-db mountPath: /kubyk/sqlite volumes: - name: kubyk-db persistentVolumeClaim: claimName: kubyk control# vi kubyk-service.yaml apiVersion: v1 kind: Service metadata: name: kubyk spec: type: LoadBalancer selector: app: kubyk ports: - port: 80 name: http
デプロイとサービスを作成しましょう:
control# kubectl create -f kubyk-deploy.yaml deployment.apps/kubyk-deployment created control# kubectl create -f kubyk-service.yaml service/kubyk created
サービスに割り当てられた新しいIPアドレスとサブのステータスを確認します。
control# kubectl get po NAME READY STATUS RESTARTS AGE glusterfs-2wxk7 1/1 Running 1 2d1h glusterfs-5dtdj 1/1 Running 1 41d glusterfs-zqxwt 1/1 Running 0 2d1h heketi-b8c5f6554-f92rn 1/1 Running 0 8d kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 11s control# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ... some text.. kubyk LoadBalancer 10.109.105.224 192.168.0.242 80:32384/TCP 10s
したがって、新しいアプリケーションを正常に起動したようです。 ブラウザでIPアドレスhttp://192.168.0.242を開くと、このアプリケーションのログインページが表示されます。 admin / adminの資格情報を使用してログインできますが、この段階でログインしようとすると、まだ使用可能なデータベースがないためエラーが表示されます。
Kubernetesダッシュボードの囲炉裏からのログメッセージの例を次に示します。
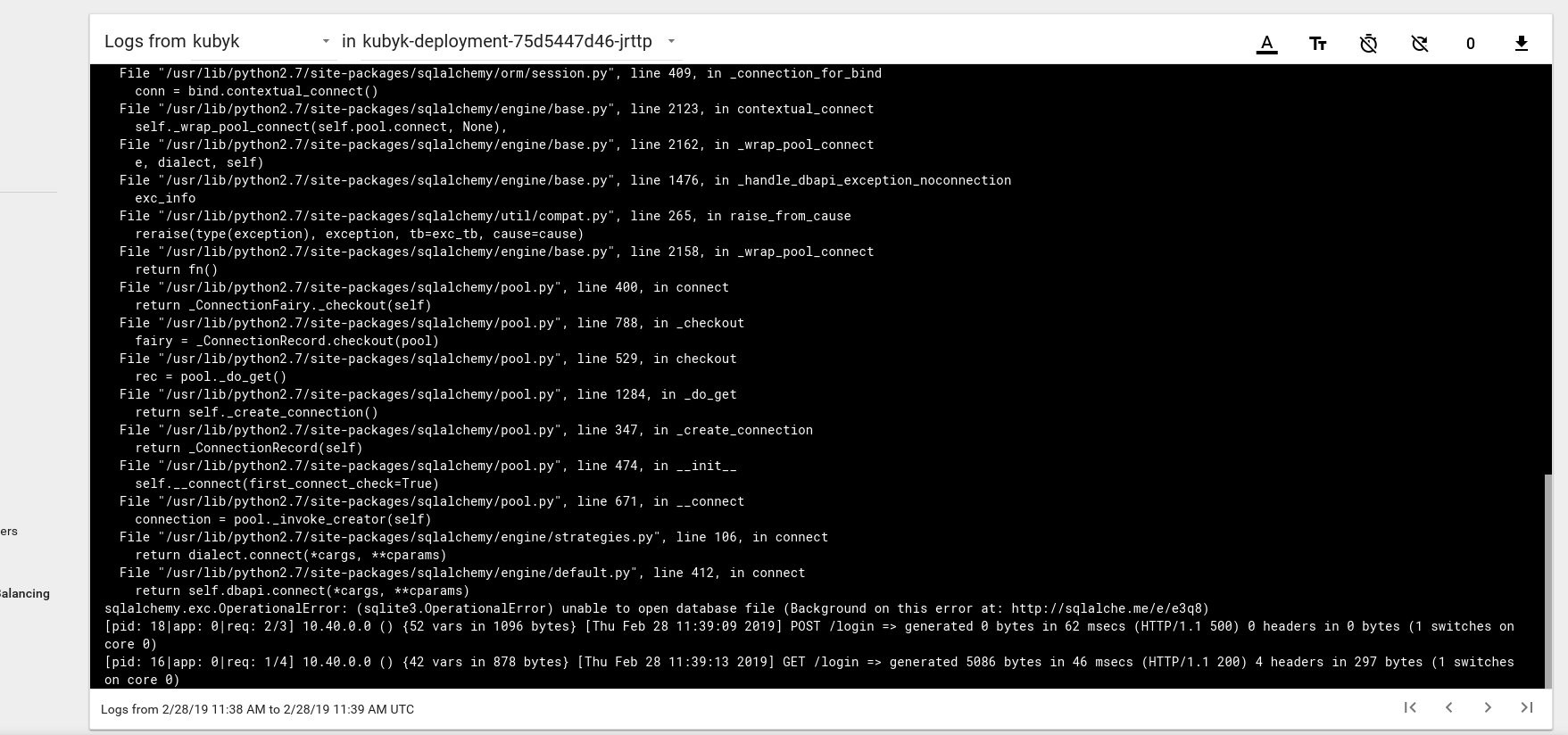
これを修正するには、gitリポジトリから以前に作成したpvcボリュームにSQlite DBファイルをコピーする必要があります。 アプリケーションはこのデータベースの使用を開始します。
control# git pull https://github.com/ratibor78/kubyk.git control# kubectl cp ./kubyk/sqlite/database.db kubyk-deployment-75d5447d46-jrttp:/kubyk/sqlite
このファイルをボリュームにコピーするには、アプリケーションのunderとkubectl cpコマンドを使用します。
また、nginxユーザーにこのディレクトリへの書き込みアクセスを許可する必要があります。 アプリケーションは、 supervisordを使用してnginxユーザーから起動されます。
control# kubectl exec -ti kubyk-deployment-75d5447d46-jrttp -- chown -R nginx:nginx /kubyk/sqlite/
もう一度ログインしてみましょう。
これで、アプリケーションが正常に動作するようになりました。たとえば、1つの作業ノードにアプリケーションのコピーを1つ配置するために、kubykの展開を3つのレプリカに拡張できます。 以前にpvcボリュームを作成したため、アプリケーションレプリカを持つすべてのポッドは同じデータベースを使用するため、サービスはレプリカ間でトラフィックを循環的に分散します。
control# kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE heketi 1/1 1 1 39d kubyk-deployment 1/1 1 1 4h5m control# kubectl scale deployments kubyk-deployment --replicas=3 deployment.extensions/kubyk-deployment scaled control# kubectl get po NAME READY STATUS RESTARTS AGE glusterfs-2wxk7 1/1 Running 1 2d5h glusterfs-5dtdj 1/1 Running 21 41d glusterfs-zqxwt 1/1 Running 0 2d5h heketi-b8c5f6554-f92rn 1/1 Running 0 8d kubyk-deployment-75d5447d46-bdnqx 1/1 Running 0 26s kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 4h7m kubyk-deployment-75d5447d46-wz9xz 1/1 Running 0 26s
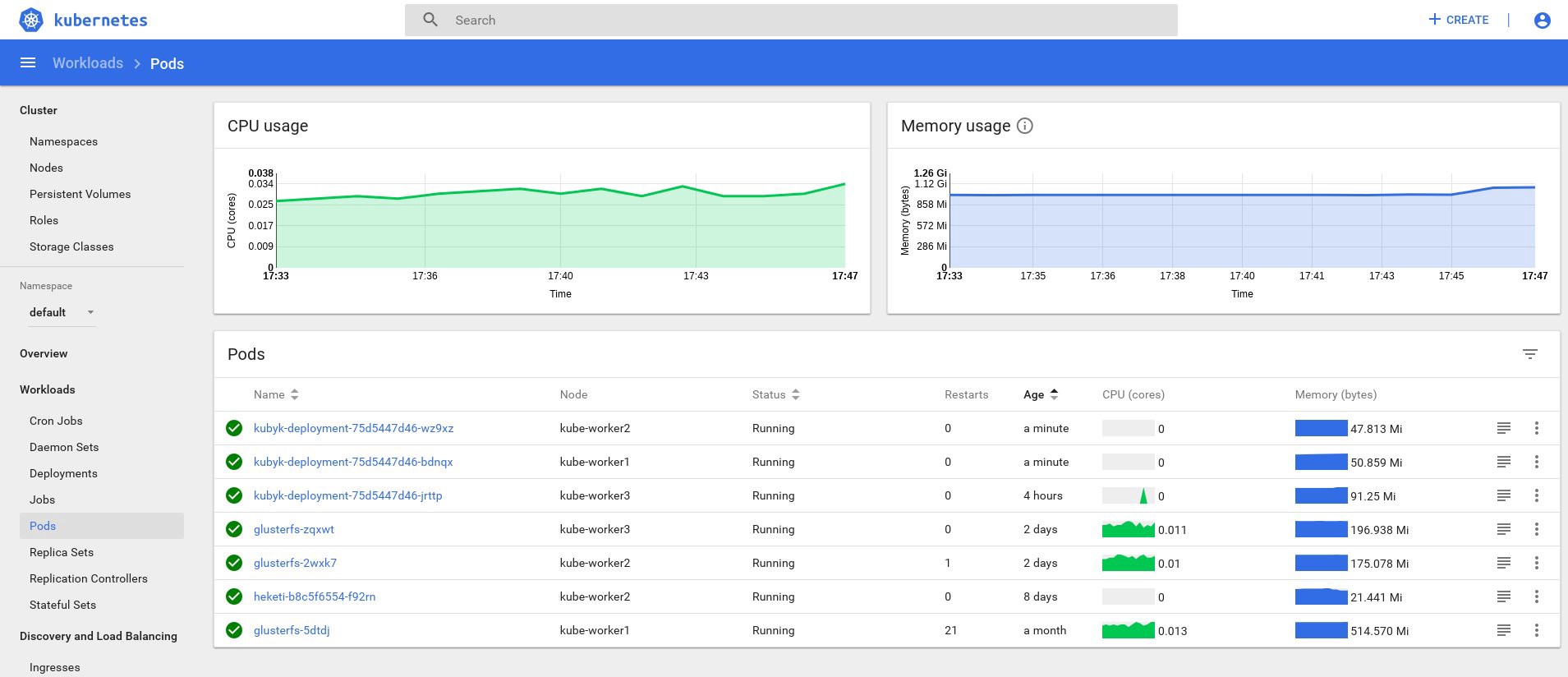
これで、作業ノードごとにアプリケーションのレプリカができたので、ノードが失われてもアプリケーションは動作を停止しません。 さらに、先ほど言ったように、負荷を簡単に分散できます。 始めるのに悪い場所ではありません。
アプリケーションで新しいユーザーを作成しましょう。
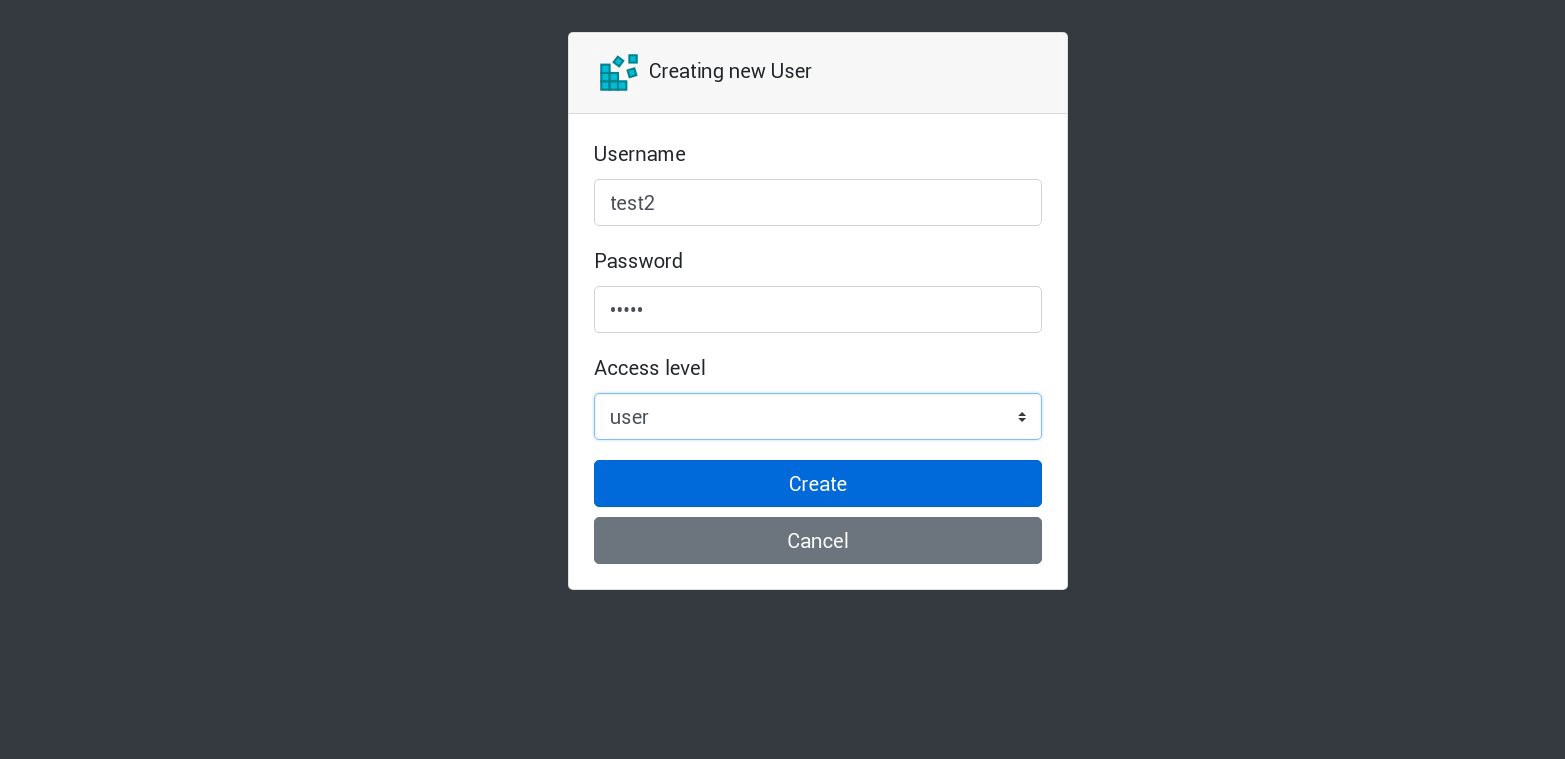
新しいリクエストはすべて、リストの次の囲炉裏で処理されます。 これは、囲炉裏のログで確認できます。 たとえば、1つのサブでアプリケーションによって新しいユーザーが作成された後、次のサブが次のリクエストに応答します。 このアプリケーションは1つの永続的なボリュームを使用してデータベースを保存するため、すべてのレプリカが失われても、すべてのデータは安全です。
大規模で複雑なアプリケーションでは、データベースに指定されたボリュームだけでなく、永続的な情報や他の多くの要素を収容するためのさまざまなボリュームが必要になります。
まあ、ほぼ完了です。 Kubernetesは膨大で動的なトピックであるため、さらに多くの側面を追加できますが、ここで停止します。 この一連の記事の主な目的は、独自のKubernetesクラスターを作成する方法を示すことでした。この情報がお役に立てば幸いです。
PS
もちろん、安定性テストとストレステスト。
この例のクラスター図は、2つの作業ノード、1つのマスターノード、1つのetcdノードなしで機能します。 必要に応じて、それらを無効にし、テストアプリケーションが機能するかどうかを確認します。
これらのガイドをコンパイルする際に、ほぼ同様の方法で、本番用の本番クラスターを準備しました。 クラスターを作成し、そこにアプリケーションをデプロイすると、重大な電源障害が発生しました。 クラスターのすべてのサーバーが完全に切断されました-システム管理者の活発な悪夢。 一部のサーバーが長時間シャットダウンした後、ファイルシステムエラーが発生しました。 しかし、再起動は非常に驚きました。Kubernetesクラスターは完全に回復しました。 すべてのGlusterFSボリュームと展開が開始されました。 私にとって、これはこの技術の大きな可能性を示しています。
よろしくお願いします、またお会いしましょう!